引入
在分布式的系统中,很多时候的所谓的性能优化,其实就是一个如何使用缓存的过程。缓存这个东西,说起来简单,但是真用起来需要考虑的面却多种多样,本文将由浅入深讲述缓存使用中遇到的各种问题,它们是如何出现的,并且提供解决办法。
为什么要缓存
很多时候我们进行一个复杂处理,这个复杂的处理可能需要耗费比较长的时间,并且这个结果可能并不会经常地发生改变,如果我们每次请求过来,都去执行一次这样复杂的计算,对于系统性能的耗费是极其昂贵的,一个好的做法是记录下上一次计算的值,然后下一次请求来的时候直接返回上次记录的值,这样就可以极大地避免复杂计算,并提升系统响应性能。
缓存的状态
我们学习缓存的使用,经常会有什么缓存击穿,缓存预热等概念,这些概念本质上都是不同场景下大量缓存处于失效状态导致的。严格来说,缓存只有两个状态 有效 和 失效 。有效状态就是指:缓存中有值可以用的状态。失效状态指的是缓存中无值可用的状态。失效状态很重要,因为使用缓存的核心就是处理缓存的失效状态。
缓存主动失效的必要性
我们缓存的数据源,根据是否会随着时间改变发生变化,分为如下两种 case
数据变化的场景
假设当前我们缓存了数据库中的数据,但是数据库的数据不会一成不变,他们是会自己变更的,但是数据库变更操作一般来说是不会通知到缓存的(当然你也可以在变更数据库的时候更新缓存),所以这个时候如果你的缓存没有主动失效的机制,那么用户看到的数据永远不会得到更新,这是无法接受的。
数据不变的场景
假设我们的后端方法是一个 pure function 函数,也就是说任何时间对于同一个输入只有唯一返回结果的时候,那么我们缓存基本上是可以是没有过期时间的。但是这里也是有区别的,如果 pure function 需要缓存的计算结果很多的时候,那么缓存过多的结果,会耗费过多的缓存空间,所以我们还是需要设定缓存的上限,当缓存值超过一定上限的时候,我们还是需要主动失效一些缓存的,具体如何失效,一般有如下算法
- FIFO 算法:先进先出算法。
- LFU 算法:最少使用算法
- LRU 算法:最近最少使用算法。
具体算法的内容,本文不赘述,大家可以自行学习。接下来我们思考返回结果可以穷举,并且数量不大的情况,如果是这种情况,那么这个问题退化成一个固定配置。一般来说,我们不认为这是一个缓存的问题。
综上所述,无论是后端数据不可变,还是可变的场景,让缓存能主动失效是十分有必要的。
缓存失效问题
在上文中,我已经提到,大部分缓存问题都是由于大量请求过来,而缓存却处于失效状态导致的,而缓存失效的目的是为了能让缓存得到更新。所以我们先从缓存更新说起
缓存更新使用方法
一般来说,更新缓存有两种方法,一种是写更新,一种读更新
写更新
写更新,一般用于我们有权限处理后端数据情况,比如操作数据库的情况,当我们更新数据的值成功的时候,我们可以主动的将数据库中的新值写入。伪代码如下
update(userInfo);
cache.put(userInfo.getId(),userInfo);
在这段伪代码中,我们的缓存是一个 Map 结构,key 为用户的 id,value 为用户信息。当我们执行 put 之后,其余读请求就能立马读取到最新缓存的数据。(这里的 cache 一般是需要使用 volatile 的,为了能保证数据的立即可见性,这个内容见 《java 并发编程》本文不赘述) 写更新的好处是,数据一更新缓存就更新了,不过写更新要求你能获知原始数据的更新状态。但是如果数据源你无法直接获知后端数据的变更状态,便无法使用该方案。
读更新
读更新是使用最多的方案,在读更新方案中,缓存数据一般会有一个新鲜度,如果新鲜度过低,则会触发去后端获取数据的操作,否则直接使用缓存的值。(这个新鲜度根据需求自己定义就好,一般设置为一个过期时间。)伪代码如下
cahceValue = cache.get(key);
if(cahceValue.isFresh()){
return cahceValue.getValue();
} else {
originValue = getData(key);
cache.put(key,originValue);
return originValue;
}
这样方案使用范围广,当业务场景对数据新鲜度不敏感的时候推荐使用这种方法。事实上及时可以使用写缓存的操作,大部分情况下依旧会使用读更新的方式,这样有助于当写更新失败的时候,读更新还能在一段时间之后自行更新数据,提升系统的稳定性。
高并发状态下的缓存(缓存并发)
在高并发的情况下,我们可能会遇到这么情况,就是现在有一批请求过来请求同一个缓存的值,但是不巧这个时候缓存处于失效状态,根据读更新策略,这个时候每个请求都会尝试去获取最新的数据,这个时候如果后端是数据库的话,很容易就把数据库给读挂了!导致整个系统不可用。
大量请求请求数据的情况
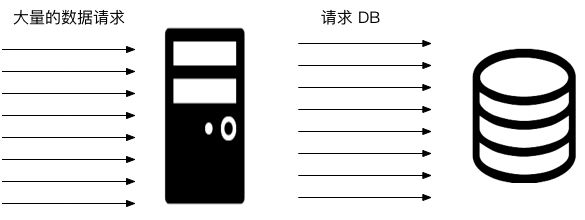
控制对后端数据的请求线程数
我们知道这个时候虽然有很多请求,但是每个请求拿到的数据基本上一定一样的,所以根本没必要创造这么多的请求,所以这个时候合适的做法是做并发控制,当缓存失效的时候,只有唯一的一个线程去向数据获取数据,而其它线程在等待结果。方案如下
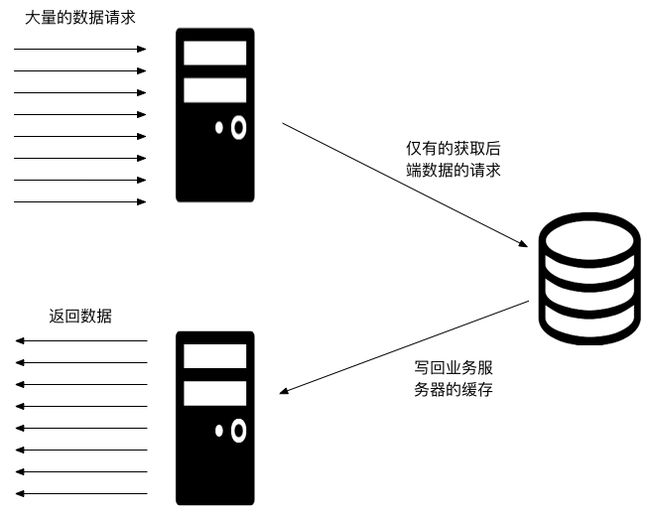
图中,我们只画了线程,但是其实应该根据实际情况去控制线程的数理和粒度。粒度细的,比如一个 key 最多只有一个线程。粒度粗一点,可以考虑整个缓存只有一个线程用于更新数据。这个根据实际业务量进行调整。
缓存击穿(缓存穿透)
在上一个议题中,我们谈了高并发的情况下,通过控制实际去获取数据的线程的方法去保证后端的安全。但是如果后端没有数据呢?这个时候不停地向服务器请求指定 key 对应的数据,依旧会不停地触发服务器向后端服务发起请求。这样虽然只有一个线程,但是依旧会不断地给后端施加压力!
空对象
这种场景的解决办法,是创建一个空对象。然后下次请求来的时候,直接返回这个空对象,防止请求击穿到后端服务。
originValue = getData(key);
if(originValue == null){
cache.put(key,new Object());
}
缓存预热
一般系统启动的时候,缓存会由读更新的方法,逐步写入到系统中。但是如果这个过程特别快,一瞬间有大量的请求过来,但是这个时候大部分缓存还没有 ready ,这依旧会导致大量请求击穿缓存,直接访问到后端服务,压垮后端服务。
提前加载缓存数据
这种问题的解决方案是在应用提供服务前,先把数据的一部分写入缓存,然后再提供服务,这就叫缓存预热.
优化并发缓存响应性能的一种思路
在刚刚缓存并发的时候,我们提到可以通过控制向后端请求的线程的方式来保护我们的后端服务,但是回过头来看我们自身,如果这个时候后端服务性能较差,那么会导致大量请求线程被阻塞,这样有可能后端服务还没有挂,我们的服务先挂了,即使没有挂也会让大量的用户请求超时。
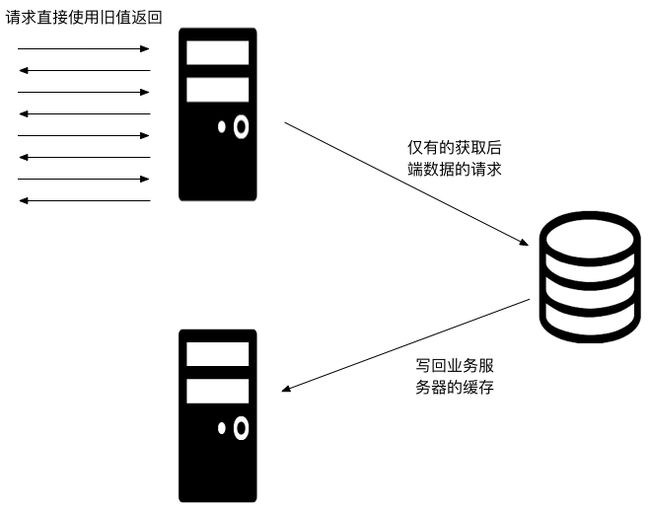
我们重新思考我们的业务场景,一般来说能使用读缓存的业务场景,对缓存的时效性都不会有太高的要求,如果当缓存到达失效期的时候,我们还能拿到旧值,这个时候如果已经有线程在向后端发起请求,这个时候我们不去等待线程的返回结果,而是直接使用旧的数据返回,这样系统的响应性就能获得极大的提高,因为对于用户请求来说,他们总是立即就获得值了。
总结
任何时候技术和业务都是要相互平衡的,很多缓存策略能否执行,一部分还要看业务是否能接受数据暂时使用旧值而不是最新的值,另一部分才是系统设计。我们设计系统的时候,要有两个视角,一个是发送请求者,我们要注意不要压垮我们的依赖方,另一方面我们也是服务提供方,要思考如何自身不被拖垮。