MyBatis面试题总结
啃下MyBatis源码系列目录
啃下MyBatis源码 - 为什么要看MyBatis源码及源码结构
啃下MyBatis源码 - org.apache.ibatis.logging包源码分析
啃下MyBatis源码 - org.apache.ibatis.datasource包源码分析
啃下MyBatis源码 - org.apache.ibatis.cache包源码分析
啃下MyBatis源码 - MyBatis核心流程三大阶段之初始化阶段
啃下MyBatis源码 - MyBatis核心流程三大阶段之代理阶段(binding模块分析)
啃下MyBatis源码 - MyBatis核心流程三大阶段之数据读写阶段
啃下MyBatis源码 - MyBatis面试题总结
--------------------------------------------------------------------------------------------------------------------------
目录
1.概念/使用方法向的问题
1.1 什么是Mybatis?
1.2 为什么说Mybatis是半ORM框架?/与Hibernate有哪些不同?
1.3 Mybaits的优点?
1.4 MyBatis框架的缺点?
1.5 #{}和${}的区别?
1.6 怎么解决实体类中的属性名和表中的字段名不一样的问题?
1.7 如何在mapper中传递多个参数?
1.8 MyBatis的接口绑定有哪些实现方式?
1.9 使用MyBatis Mapper接口开发时有哪些要求?
2.源码向的问题
2.1 解释下MyBatis面向Mapper编程工作原理?
2.2 为什么MyBatis Mapper接口中的方法不支持重载?
2.3 Mybatis动态sql执行原理?
2.4 Mybatis的一级、二级缓存实现原理?
2.5 Mybatis是如何进行分页的?
2.6 Mybatis的插件运行原理?
2.7 Mybatis都有哪些Executor执行器?它们之间的区别是什么?
2.8 Mybatis中如何指定使用哪一种Executor执行器?
2.9 Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
2.10 Mybatis中用到了哪些设计模式?
1.概念/使用方法向的问题
1.1 什么是Mybatis?
(1)Mybatis是一个半ORM框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。
(2)MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
(3)通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。
1.2 为什么说Mybatis是半ORM框架?/与Hibernate有哪些不同?
ORM是对象和关系之间的映射,包括对象->关系和关系->对象两方面。Hibernate是个完整的ORM框架,而MyBatis只完成了关系->对象,准确地说MyBatis是SQL映射框架而不是ORM框架,因为其仅有字段映射,对象数据以及对象实际关系仍然需要通过手写SQL来实现和管理。
(1)Hibernate为完整的ORM框架,Mybatis为半ORM框架。
(2)Mybatis程序员直接编写原生sql,可严格控制sql执行性能,灵活度高,适用于对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等;Hibernate只能通过编写hql实现数据库查询(hql好难用哦)。
(3)Hibernate对象/关系映射能力强,数据库无关性好,适用于对关系模型要求高的软件; Mybatis的数据库无关性较差,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件。
1.3 Mybaits的优点?
(1)基于SQL语句编程,不会对应用程序或者数据库的现有设计造成任何影响,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,重用性高。
(2)与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接;
(3)很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)。
(4)能够与Spring很好的集成;
(5)提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
1.4 MyBatis框架的缺点?
(1)SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
(2)SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
1.5 #{}和${}的区别?
(1)${}是properties文件中的变量占位符,它可以用于标签属性值和sql内部,属于静态文本替换。
(2)#{}是sql的参数占位符,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值。
${param}传递的参数会被当成sql语句中的一部分,举例:
order by ${param},则解析成的sql为:
order by id
#{parm}传入的数据都当成一个字符串,会对自动传入的数据加一个双引号,举例:
select * from table where name = #{param},则解析成的sql为:
select * from table where name = "id"1.6 怎么解决实体类中的属性名和表中的字段名不一样的问题?
(1)通过在查询的sql语句中定义字段名的别名,使字段名的别名和实体类的属性名一致
(2)Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句。
1.7 如何在mapper中传递多个参数?
(1)使用 @param 注解:
user selectUser(@param("username") string username,@param("password") string password);(2)Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;
Map map = new HashMap();
map.put("start", start);
map.put("end", end);
sqlSession.selectList("student.selectUser", map); 1.8 MyBatis的接口绑定有哪些实现方式?
接口绑定有两种实现方式:
(1)一种是通过注解绑定,就是在接口的方法上面加上@Select@Update等注解里面包含Sql语句来绑定
@Select("select ID,CODE,NAME from T_SYS_DICT_TYPE ")
@Results(id = "distTypeMap",value ={@Result(id =true,property="id",column="ID")
,@Result(property="code",column="CODE")
,@Result(property="name",column="NAME")
,@Result(property = "dictDtos" ,column = "ID",many = @Many(select="com.santbbd.ams.sysconfig.mapper.SysInitMapper.findByDistTypeId",fetchType = FetchType.EAGER))
})
List getAllDist(); (2)另外一种就是通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名.
1.9 使用MyBatis Mapper接口开发时有哪些要求?
(1)Mapper接口方法名和mapper.xml中定义的每个sql的id相同;
(2)Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;
(3)Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;
(4)Mapper.xml文件中的namespace即是mapper接口的类路径;
2.源码向的问题
2.1 解释下MyBatis面向Mapper编程工作原理?
Mapper接口是没有实现类的,当调用接口方法时,采用了JDK的动态代理,先从Configuration配置类MapperRegistry对象中获取mapper接口和对应的代理对象工厂信息(MapperProxyFactory),然后利用代理对象工厂MapperProxyFactory创建实际代理类(MapperProxy),最后在MapperProxy类中通过MapperMethod类对象内保存的中对应方法的信息,以及对应的sql语句的信息进行分析,最终确定对应的增强方法进行调用。
2.2 为什么MyBatis Mapper接口中的方法不支持重载?
在MyBatis源码中有这么几行代码,我们可以看到在解析XML文件创建mapper接口对应方法的时候,采用了接口全限名+方法名的方式作为StrictMap(MappedStatement数据存放的Map集合)的key值,而源码对于StrictMap的put方法进行了判断,如果存入的数据key已重复则抛出异常,所以Mapper接口中的方法不支持重载。
id = applyCurrentNamespace(id, false);
public String applyCurrentNamespace(String base, boolean isReference) {
...
//返回值为mapper的全限名(xml中namespace的值)+方法名(xml中Statement id的值)
return currentNamespace + "." + base;
}

2.3 Mybatis动态sql执行原理?
(1)初始化阶段:通过XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder解析XML文件中的信息存储到Configuration类中;
(2)代理阶段:先从Configuration配置类MapperRegistry对象中获取mapper接口和对应的代理对象工厂信息,再利用代理对象工厂MapperProxyFactory创建实际代理类,最后在MapperProxy类中通过MapperMethod类对象内保存的中对应方法的信息,以及对应的sql语句的信息进行分析,最终确定对应的增强方法进行调用。
(3)数据读写阶段:通过四种Executor调用四种Handler进行查询和封装数据;
2.4 Mybatis的一级、二级缓存实现原理?
(1)一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,Mybatis默认打开一级缓存,一级缓存存放在BaseExecutor的localCache变量中:
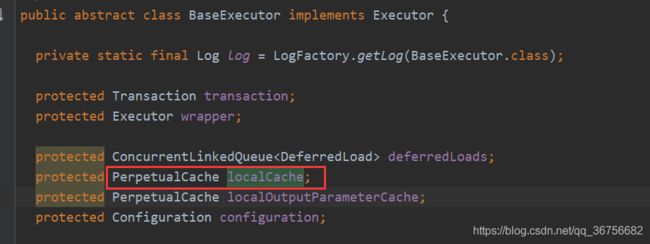
(2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace)级别。Mybatis默认不打开二级缓存,可以在config文件中xml

(3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被清除并重新更新,如果开启了二级缓存,则只根据配置判断是否刷新。
2.5 Mybatis是如何进行分页的?
(1)SQL分页(物理分页):
(2)使用RowBounds实现分页(逻辑分页):
Service:
publicList queryRolesByPage(String roleName,intstart,int limit) {
returnroleDao.queryRolesByPage(roleName,new RowBounds(start, limit));
}
Dao:
public List queryUsersByPage(String userName, RowBounds rowBounds);(3)使用分页插件PageHelper:
public Json queryByPage(User userParam,Integer pageNum,Integer pageSize) {
PageHelper.startPage(pageNum, pageSize);
List userList = userMapper.queryByPage(userParam);
Json json = new Json();
return json;
} 2.6 Mybatis的插件运行原理?
编写插件的步骤:
(1)实现Interceptor接口方法
(2)确定拦截的签名
(3)在配置文件中配置插件
在创建三个重要的Handler(StatementHandler、ParameterHandler、ResultSetHandler)时通过插件数组包装了三大Handler:
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);获取到所有的Interceptor(拦截器)(插件需要实现的接口),调用:
interceptor.plugin(target);返回target包装后的对象,最后回调回自定义插件的intercept方法执行插件内的代码逻辑。可拦截的接口和方法一览:
Executor(update、query 、 flushStatment 、 commit 、 rollback 、 getTransaction 、 close 、 isClose)
StatementHandler(prepare 、 paramterize 、 batch 、 update 、 query)
ParameterHandler( getParameterObject 、 setParameters )
ResultSetHandler( handleResultSets 、 handleCursorResultSets 、 handleOutputParameters )
2.7 Mybatis都有哪些Executor执行器?它们之间的区别是什么?

BaseExecutor:基础抽象类,实现了executor接口的大部分方法,主要提供了缓存管理和事务管理的能力,使用了模板模式,doUpdate,doQuery,doQueryCursor 等方法的具体实现交给不同的子类进行实现
CachingExecutor:直接实现Executor接口,使用装饰器模式提供二级缓存能力。先从二级缓存查,缓存没有命中再从数据库查,最后将结果添加到缓存中。如果在xml文件中配置了cache节点,则会创建CachingExecutor。
BatchExecutor:BaseExecutor具体子类实现,在doUpdate方法中,提供批量执行多条SQL语句的能力;
SimpleExecutor:BaseExecutor具体子类实现且为默认配置,在doQuery方法中使用PrepareStatement对象访问数据库, 每次访问都要创建新的 PrepareStatement对象;
ReuseExecutor:BaseExecutor具体子类实现,与SimpleExecutor不同的是,在doQuery方法中,使用预编译PrepareStatement对象访问数据库,访问时,会重用缓存中的statement对象,而不是每次都创建新的PrepareStatement。
2.8 Mybatis中如何指定使用哪一种Executor执行器?
在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
![]()

2.9 Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?

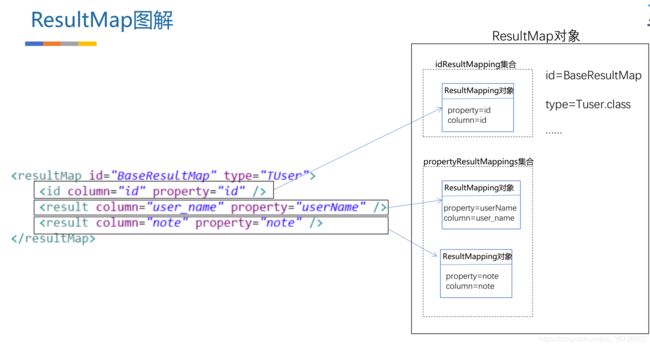
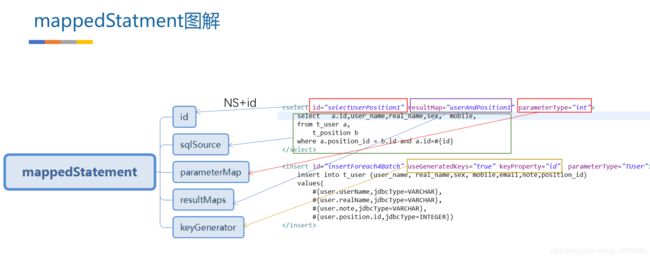
Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在Xml映射文件中,
2.10 Mybatis中用到了哪些设计模式?
日志模块:代理模式、适配器模式
数据源模块:代理模式、工厂模式
缓存模块:装饰器模式
初始化阶段:建造者模式
代理阶段:策略模式
数据读写阶段:模板模式
插件化开发:责任链模式