本文是自己在推荐系统研究中研读的一篇顶会文章的翻译及解读,原文:Adversarial Personalized Ranking for Recommendation
地址:http://staff.ustc.edu.cn/~hexn/papers/sigir18-adversarial-ranking.pdf
- 发表于信息检索顶会SIGIR2018(录用率:20%)
- 第一作者为:推荐领域大佬 何向南,拜读了他很多的论文,论文结构清晰,实验代码完整,非常nice
- 论文所对应的实验代码已开源:https://github.com/hexiangnan/adversarial_personalized_ranking
- 本篇笔记是网上首次翻译注解该论文的文档,如需转载引用,请务必在文中附上原链接及相应说明,包括作者信息(阿瑟)
- 本篇笔记非标准译文,其中包含了笔者自己对问题的部分理解,仅供参考,欢迎学习交流
对抗训练(Adversarial Training)近年来在深度学习及图像应用中广泛应用,真正用到推荐中的案例相对较少,正是如此这篇文章也相对比较容易发表在顶会上,也给笔者提供了一些思路和想法。
目录
- 摘要
- 简介
- 前提知识
- MF
- BPR
- 方法理论介绍
- 实验效果
- 相关工作
- 总结
摘要
物品推荐(item recommendation)是个性化的排序任务(Ranking)。为此,许多推荐系统使用成对排序目标(Pairwise)来优化模型,例如贝叶斯个性化排名(BPR)。
【注】:排序问题,常用的方法有Pointwise,Pairwise:即单个和成对的区别;BPR是成对排序,直观上形式如
文中使用矩阵分解(MF) - 最广泛使用的模型作为演示,我们发现使用BPR对MF进行优化会导致推荐模型不稳健。特别是,我们发现最终的推荐模型很容易受到模型参数上的对抗性扰动(adversarial perturbations)的影响,这意味着这种推荐模型结果中可能存在较大的误差。
为了增强推荐模型的稳健性(robustness)并从而提高其泛化性能,提出了一种新的优化框架,即Adversarial Personalized Ranking(APR)。简而言之,APR通过进行对抗训练来增强成对排序方法BPR。
它可以被解释为在玩一种极小极大(minmax game)游戏,在其中BPR目标函数的最小化的同时要防御对手(adversary),对手会增加了对模型参数的对抗性扰动以最大化BPR目标函数。
【注】:,原始BPR目标函数要达到最小化,已取得最优的模型;而对手就是要增加参数的扰动,让BPR增大
为了说明它是如何工作的,文章通过来在MF上实现APR。 对三个公共现实世界数据集的广泛实验证明了APR的有效性 - 通过优化MF与APR,它优于BPR,平均相对改善11.2%,并实现了物品推荐的最先进性能。(2018年的文章哦)
简介
对抗性机器学习的最新进展表明许多最先进的分类器实际上非常脆弱(fragile)并且容易受到对抗性样本的影响,这些样本是通过对数据集中的输入示例应用小但有意的扰动而形成的。一个典型的例子是,通过向熊猫图像添加小的对抗性扰动,训练有素的分类者将图像错误地分类为具有高置信度的长臂猿,而扰动的影响可以很难被人类所感知。
这说明了仅在静态标记数据上训练模型的固有缺陷。为了解决这一局限性并改进模型推广,研究人员随后开发了对抗训练方法(Adversarial Training),训练模型以正确分类动态生成的对抗性样本。
然而对抗学习的研究进步主要集中在可以直观理解对抗性样本的,但到目前为止,还没有关于信息检索(IR)领域的研究。
尽管IR中的核心任务是排名,但我们指出许多学习排名(L2R)方法基本上是通过优化分类函数来训练的,例如常用的L2R方法贝叶斯个性化排序(BPR)等。
这意味着潜在的IR模型很可能也缺乏稳健性,并且容易受到某些类型的“对抗性样本”的影响。 在这项工作中,我们的目标是通过探索对物品推荐的对抗性学习方法来填补研究空白,这是IR中涉及个性化排名的积极和基础研究课题。
然而,直接嫁接图像领域生成对抗性样本的方式是不可行的,因为推荐者模型的输入主要是离散特征()。显然,将噪声应用于离散特征是没有意义的,这可能会改变它们原本的语义。
为了解决这个问题,我们考虑在更深层次上探索推荐模型的稳健性 - 在其内在模型参数的水平而不是外在输入。 使用以BPR训练的矩阵分解(MF)模型[18,20]作为演示(我们将此实例称为MF-BPR),我们研究了其对嵌入参数扰动的鲁棒性。
【思考】:这种研究实际意义不大,直接对经过处理的嵌入向量生成对抗样本,跟实际推荐场景的真实输入相差甚远。
MF-BPR是一种极具竞争力的物品推荐方法,并且直到最近才被用于许多论文中作为最先进的基线。 我们发现MF-BPR不稳健,容易受到参数的对抗扰动的影响。 这揭示了BPR训练的弱点,并激励我们开发对抗性学习方法,从而产生更好,更强大的推荐模型。
前提知识
首先描述用于推荐的矩阵分解模型(MF)。 接下来简要概括了成对学习方法贝叶斯个性化排名(BPR)。本节的创新贡献是凭经验证明由BPR(也称为MF-BPR)优化的MF模型不稳健并且易受其参数的对抗性扰动的影响。
MF
MF已被公认为推荐的基本但最有效的模型,作为表示学习的方法,MF将每个用户和项目表示为嵌入向量。 MF的核心思想是估计用户对项目的偏好作为其嵌入向量之间的内积。
BPR
BPR是成对的L2R方法,并且已被广泛用于优化推荐模型以实现个性化排序。 针对从隐式反馈中学习,它假设观察到的交互应该排名高于未观察到的交互。 为此,BPR最大化观察到的交互与未观察到的交互之间的差距。 这与逐点方法(Ponitwise)从根本上不同,它们将每个模型预测优化为预定义的基础。 形式上,BPR的目标函数(最小化)是
是sigmoid函数,λΘ是模型特定正则化参数以防止过度拟合,D表示成对训练数据集合,可以表示为:
表示用户之前与之交互过的项目集,表示整个物品集。 由于BPR中的训练样本数量非常巨大,因此BPR的优化通常通过执行随机梯度下降(SGD)来完成。 在获得参数之后,我们可以基于所有物品上的值来获得用户u的个性化排序列表.
由于其合理性和易于优化,BPR已被广泛应用于各种场景,并在优化推荐模型中发挥重要作用。 值得注意的是,BPR的行为可以被解释为分类器 - 给定三元组(u,i,j),它确定(u,i)是否应该具有比(u,j)更高的分数。 根据这种解释,(u,i,j)的正实例意味着yui应尽可能大于yjj以获得+1的正确标签; 反之亦然,负面实例可以看作标签为0。
MF-BPR受对抗噪声的影响
为图像分类器生成对抗性样本的现有方法不适合BPR。由于在输入层添加噪声是不合理的,因此我们考虑在更深层次上探索BPR的稳健性 - 底层推荐模型的参数。很自然地假设一个稳健的模型应该对其参数的小扰动相当不敏感;也就是说,只有在强制执行大扰动时,才能显著改变模型行为。
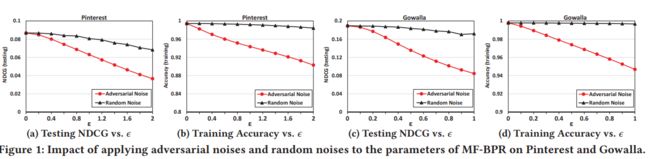
扰动设置。 考虑到MF在推荐中的主导作用,我们选择MF作为推荐者模型并用BPR进行优化。 我们首先训练MF-BPR直到使用SGD收敛。 然后,我们比较添加随机扰动和对抗扰动对MF的嵌入的影响。 对于对抗性扰动,我们将其定义为旨在最大化BPR目标函数的扰动
【注】:在预训练的基础,加入扰动因素。
控制扰动的范围,可以通过求导计算出使得BPR Loss值最大的扰动。
结果。 图1显示了在Pinterest和Gowalla数据集上使用ε的不同设置1对MF-BPR应用对抗和随机扰动的影响。 具体而言,我们展示了NDCG @ 100在测试集上评估的性能以及减少训练集D的分类准确度 ε= 0的设置意味着不使用扰动,表明训练有素的MF-BPR的性能。 观察可以有以下结论:
- 首先,两个数据集都表明,添加对抗性噪声会导致性能下降比添加随机噪声更显著。 例如,在Gowalla上,当ε设置为0.4时,应用随机扰动会使测试NDCG降低1.6%,这对推荐的影响非常小; 相反,应用对抗性扰动使NDCG显着降低21.2% - 比随机扰动大13倍
- 其次,虽然对抗性扰动仅基于部分训练样本得出,但它对推荐性能具有显着的不利影响.
【注】:
方法理论介绍
APR损失函数
我们的目标是设计一个新的目标函数,通过优化它,推荐模型既适用于个性化排名,又适用于对抗性扰动。基于这个目标,设计了APR的损失函数:
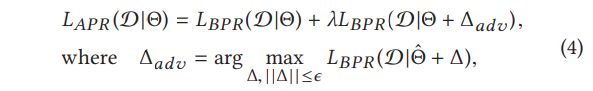
其中是参数扰动项, 损失函数第一项即常规的BPR损失,后半项则为加入扰动后的对抗损失。作为因子项,控制对抗扰动损失的程度。作为一个对抗优化问题,实际即为最大最小问题,求解出最优参数:
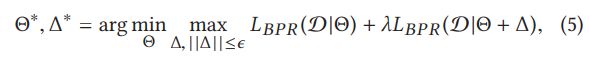
与BPR相似,APR提出了一个独立于模型的通用学习框架。 只要基础模型是可微分的,就可以在我们的APR框架下使用反向传播和基于梯度的优化算法来学习。 除了BPR中的那些之外,在APR中还要指定两个超参数-ε和λ。 在下文中,我们提出了 基于SGD的APR通用解决方案。
APR通用解决方案
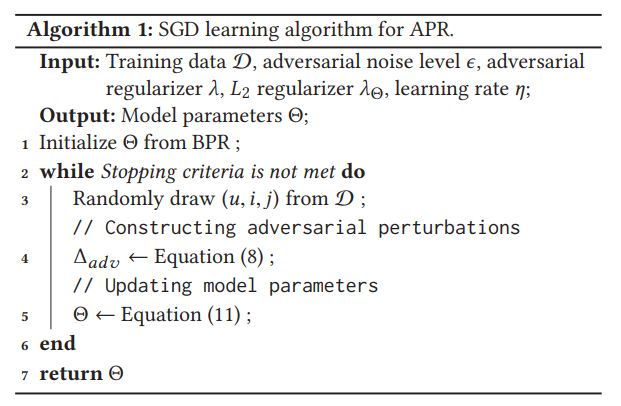
主要分为两个部分: 主体思路是:分步骤计算,先算出最大干扰项,再算在最大干扰项干扰下的最小APRloss.
-
给定训练实例(u,i,j),构造对抗性扰动Δadv的问题可以表示为最大化
注意这个地方的设计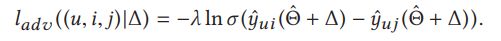 扰动项公式
扰动项公式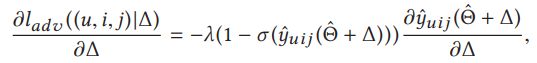 其中具体涉及到的化简推导,在此略过,需指出yuij该项可根据BPR的定义表示成减法形式。
其中具体涉及到的化简推导,在此略过,需指出yuij该项可根据BPR的定义表示成减法形式。 求解推导
求解推导 -
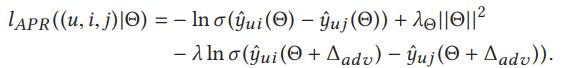
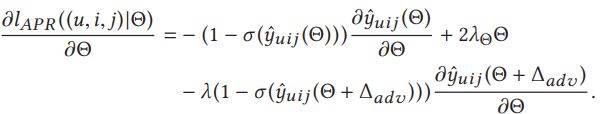
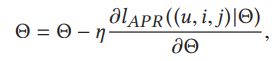 模型参数SGD求导过程
模型参数SGD求导过程
- 模型需要先完成初始化,即预训练,得到初始的MF-BPR模型;在此基础上添加扰动
- 添加扰动时,需要先随机选取一个样本,对该样本添加扰动,与原来常规的训练过程相比,本质相同,只是多了一个计算和添加扰动项的过程。
MF-BPR实例化的APR


实验效果
【注】:何教授团队的论文格式非常统一,在实验效果部分,具有鲜明的特点:即先提出实验要证明/解决的问题,再针对各问题,逐一说明相应的效果。
具体实验数据是该团队常用的几个数据集(看的太多了...):Yelp,Pinterest,Gowalla
- 评价准则 (Leave-One-Out),很常用的方法;具体做法是,对于Yelp和Gowalla中的每个用户,将最新的交互作为测试集并在剩余的交互上训练模型。 由于Pinterest数据没有时间戳信息,随机为每个用户提供交互以形成测试集。
- 评价指标 研究的推荐效果实际上叫做Top-K推荐问题,即给用户推荐K个物品;评价推荐效果关注这个K个物品构成的列表的相关信息,常用的是Hit Ratio & NDCG。
具体的实验效果,我就不一一展示了;顶会论文的实验效果不好,还发啥顶会(狗头
像上图所示,其实反映了APR的有效性,没有红线出现的部分即是初始MF-BPR训练过程,在1000epoch后加入了APR训练,可以看到红线的效果明显优于原来的效果,证明了这种训练方法的有效性。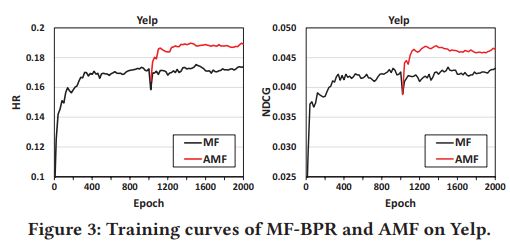 效果展示
效果展示
相关工作
这部分作者提到
这项工作的灵感来自对抗性机器学习技术的最新发展。简而言之,人们发现,正常的监督训练过程使得一个类比较容易受到对抗性例子的影响,这揭示了一般化中不稳定模型的潜在问题。
关于新兴的对抗性学习领域的现有工作主要集中在图像分类领域。关于排名的对抗性学习的研究很少 - 这是IR的核心任务。
具体与该文相关的推荐方面的工作,作者也提及了IRGAN
它还采用对抗性学习,更准确地说是GAN框架来解决匹配问题。 我们的APR方法与IRGAN根本不同,IRGAN旨在统一生成和判别模型的强度。 具体地,在IRGAN的成对公式中,生成器近似相关性分布以生成给定查询(用户)的文档(项)对,并且鉴别器试图区分文档对是来自真实数据还是生成。 不幸的是,直观地难以理解为什么IRGAN-pairwise可以改善项目推荐中的个性化排名(事实上,原始论文和他们发布的代码仅对于推荐任务仅具有IRGAN点)。
作者还耿直地指出了IRGAN原文的问题,鉴于IRGAN该文我还没认真阅读,暂不予评论,后期看完再写关于IRGAN的注解文章
总结
总结下来,APR方法还是有一套东西,在论文研究的大背景下,具有一定的开创性:引入对抗训练,巧妙地添加打扰项,非常深入地将对抗思想融入到推荐中;而不是直接用GAN之类的做个结合。从这点看,本文的工作是很有价值的。但还是跟实际场景有些差别,我一直在思考,什么的环境下,才会出现对MF这种模型参数的对抗攻击或者叫干扰?这个问题当然也有其他人在研究,在2003年前后就有人提出托攻击的概念,但还是存在一些问题的。对这些问题感兴趣或者已有自己的想法/认知的朋友,可以与我交流一下。
学术方面的话,可以把本文的工作拓展到基于神经网络的模型上去,因为较于MF,基于神经网络的推荐模型解释性更差,拟合过程更加不确定,很容易受扰动干扰。或者从根源研究推荐的数据问题/扰动的程度问题。
码字不易,如果觉得本文对你有点帮助,请点个赞,打个赏!