复制自:https://liyuj.gitee.io/confluent/Kafka-ErrorHandlingDeadLetterQueues.html
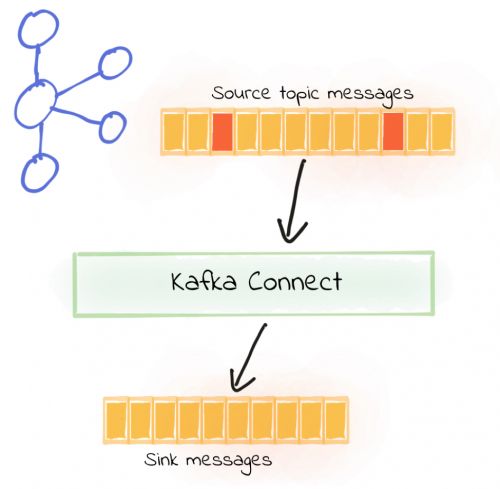
Kafka连接器是Kafka的一部分,是在Kafka和其它技术之间构建流式管道的一个强有力的框架。它可用于将数据从多个地方(包括数据库、消息队列和文本文件)流式注入到Kafka,以及从Kafka将数据流式传输到目标端(如文档存储、NoSQL、数据库、对象存储等)中。
现实世界并不完美,出错是难免的,因此在出错时Kafka的管道能尽可能优雅地处理是最好的。一个常见的场景是获取与特定序列化格式不匹配的主题的消息(比如预期为Avro时实际为JSON,反之亦然)。自从Kafka 2.0版本发布以来,Kafka连接器包含了错误处理选项,即将消息路由到死信队列的功能,这是构建数据管道的常用技术。
在本文中将介绍几种处理问题的常见模式,并说明如何实现。
#失败后立即停止
有时可能希望在发生错误时立即停止处理,可能遇到质量差的数据是由于上游的原因导致的,必须由上游来解决,继续尝试处理其它的消息已经没有意义。

这是Kafka连接器的默认行为,也可以使用下面的配置项显式地指定:
errors.tolerance=none
在本示例中,该连接器配置为从主题中读取JSON格式数据,然后将其写入纯文本文件。注意这里为了演示使用的是FileStreamSinkConnector连接器,不建议在生产中使用。
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_01",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file":"/data/file_sink_01.txt"
}
}'
主题中的某些JSON格式消息是无效的,连接器会立即终止,进入以下的FAILED状态:
$curl-s"http://localhost:8083/connectors/file_sink_01/status"|\jq -c -M'[.name,.tasks[].state]'["file_sink_01","FAILED"]
查看Kafka连接器工作节点的日志,可以看到错误已经记录并且任务已经终止:
org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error handler
at org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execAndHandleError(RetryWithToleranceOperator.java:178)
…
Caused by: org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed due to serialization error:
at org.apache.kafka.connect.json.JsonConverter.toConnectData(JsonConverter.java:334)
…
Caused by: org.apache.kafka.common.errors.SerializationException: com.fasterxml.jackson.core.JsonParseException: Unexpected character ('b' (code 98)): was expecting double-quote to start field name
at [Source: (byte[])"{brokenjson-:"bar 1"}"; line: 1, column: 3]
要修复管道,需要解决源主题上的消息问题。除非事先指定,Kafka连接器是不会简单地“跳过”无效消息的。如果是配置错误(例如指定了错误的序列化转换器),那最好了,改正之后重新启动连接器即可。不过如果确实是该主题的无效消息,那么需要找到一种方式,即不要阻止所有其它有效消息的处理。
#静默忽略无效的消息
如果只是希望处理一直持续下去:
errors.tolerance=all
1
在实际中大概如下:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_05",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file":"/data/file_sink_05.txt",
"errors.tolerance": "all"
}
}'
启动连接器之后(还是原来的源主题,其中既有有效的,也有无效的消息),就可以持续地运行:
$ curl -s "http://localhost:8083/connectors/file_sink_05/status"| \
jq -c -M '[.name,.tasks[].state]'
["file_sink_05","RUNNING"]
这时即使连接器读取的源主题上有无效的消息,也不会有错误写入Kafka连接器工作节点的输出,而有效的消息会按照预期写入输出文件:
$ head data/file_sink_05.txt
{foo=bar 1}
{foo=bar 2}
{foo=bar 3}
…
#是否可以感知数据的丢失?
配置了errors.tolerance = all之后,Kafka连接器就会忽略掉无效的消息,并且默认也不会记录被丢弃的消息。如果确认配置errors.tolerance = all,那么就需要仔细考虑是否以及如何知道实际上发生的消息丢失。在实践中这意味着基于可用指标的监控/报警,和/或失败消息的记录。
确定是否有消息被丢弃的最简单方法,是将源主题上的消息数与写入目标端的数量进行对比:
$ kafkacat -b localhost:9092 -t test_topic_json -o beginning -C -e -q -X enable.partition.eof=true | wc -l
150
$ wc -l data/file_sink_05.txt
100 data/file_sink_05.txt
这个做法虽然不是很优雅,但是确实能看出发生了消息的丢失,并且因为日志中没有记录,所以用户仍然对此一无所知。
一个更加可靠的办法是,使用JMX指标来主动监控和报警错误消息率:
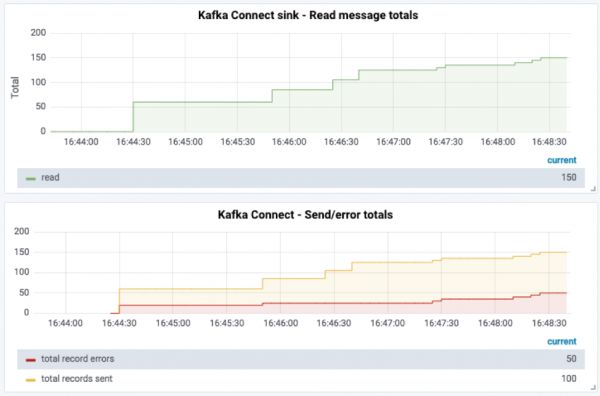
这时可以看到发生了错误,但是并不知道那些消息发生了错误,不过这是用户想要的。其实即使之后这些被丢弃的消息被写入了/dev/null,实际上也是可以知道的,这也正是死信队列概念出现的点。
#将消息路由到死信队列
Kafka连接器可以配置为将无法处理的消息(例如上面提到的反序列化错误)发送到一个单独的Kafka主题,即死信队列。有效消息会正常处理,管道也会继续运行。然后可以从死信队列中检查无效消息,并根据需要忽略或修复并重新处理。
进行如下的配置可以启用死信队列:
errors.tolerance=allerrors.deadletterqueue.topic.name=
如果运行于单节点Kafka集群,还需要配置errors.deadletterqueue.topic.replication.factor = 1,其默认值为3。
具有此配置的连接器配置示例大致如下:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_02",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file": "/data/file_sink_02.txt",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_02",
"errors.deadletterqueue.topic.replication.factor": 1
}
}'
使用和之前相同的源主题,然后处理混合有有效和无效的JSON数据,会看到新的连接器可以稳定运行:
$curl-s"http://localhost:8083/connectors/file_sink_02/status"|\jq -c -M'[.name,.tasks[].state]'["file_sink_02","RUNNING"]
源主题中的有效记录将写入目标文件:
$headdata/file_sink_02.txt{foo=bar1}{foo=bar2}{foo=bar3}[…]
这样管道可以继续正常运行,并且还有了死信队列主题中的数据,这可以从指标数据中看出:
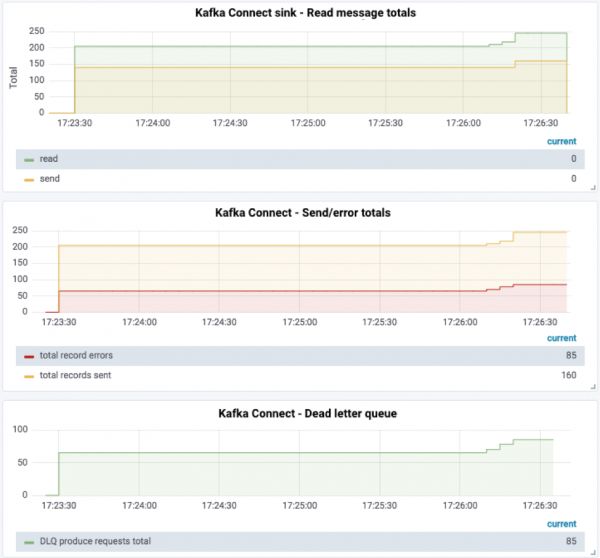
检查主题本身也可以看出来:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
---------------------------------------------------------------------------------------------------
dlq_file_sink_02 | false | 1 | 1 | 0 | 0
test_topic_json | false | 1 | 1 | 1 | 1
---------------------------------------------------------------------------------------------------
ksql> PRINT 'dlq_file_sink_02' FROM BEGINNING;
Format:STRING
1/24/19 5:16:03 PM UTC , NULL , {foo:"bar 1"}
1/24/19 5:16:03 PM UTC , NULL , {foo:"bar 2"}
1/24/19 5:16:03 PM UTC , NULL , {foo:"bar 3"}
…
从输出中可以看出,消息的时间戳为(1/24/19 5:16:03 PM UTC),键为(NULL),然后为值。这时可以看到值是无效的JSON格式{foo:"bar 1"}(foo也应加上引号),因此JsonConverter在处理时会抛出异常,因此最终会输出到死信主题。
但是只有看到消息才能知道它是无效的JSON,即便如此,也只能假设消息被拒绝的原因,要确定Kafka连接器将消息视为无效的实际原因,有两个方法:
死信队列的消息头;
Kafka连接器的工作节点日志。
下面会分别介绍。
#记录消息的失败原因:消息头
消息头是使用Kafka消息的键、值和时间戳存储的附加元数据,是在Kafka 0.11版本中引入的。Kafka连接器可以将有关消息拒绝原因的信息写入消息本身的消息头中。这个做法比写入日志文件更好,因为它将原因直接与消息联系起来。
配置如下的参数,可以在死信队列的消息头中包含拒绝原因:
errors.deadletterqueue.context.headers.enable=true
配置示例大致如下:
curl-X POST http://localhost:8083/connectors -H"Content-Type: application/json"-d'{
"name": "file_sink_03",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file": "/data/file_sink_03.txt",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_03",
"errors.deadletterqueue.topic.replication.factor": 1,
"errors.deadletterqueue.context.headers.enable":true
}
}'
和之前一致,连接器可以正常运行(因为配置了errors.tolerance=all)。
$curl-s"http://localhost:8083/connectors/file_sink_03/status"|\jq -c -M'[.name,.tasks[].state]'["file_sink_03","RUNNING"]
源主题中的有效消息会正常写入目标文件:
$headdata/file_sink_03.txt{foo=bar1}{foo=bar2}{foo=bar3}[…]
可以使用任何消费者工具来检查死信队列上的消息(之前使用了KSQL),不过这里会使用kafkacat,然后马上就会看到原因,最简单的操作大致如下:
kafkacat -b localhost:9092 -t dlq_file_sink_03% Auto-selecting Consumer mode(use -P or -C to override){foo:"bar 1"}{foo:"bar 2"}…
不过kafkacat有更强大的功能,可以看到比消息本身更多的信息:
kafkacat -b localhost:9092 -t dlq_file_sink_03 -C -o-1 -c1\-f'\nKey (%K bytes): %k Value (%S bytes): %s Timestamp: %T Partition: %p Offset: %o Headers: %h\n'
这个命令将获取最后一条消息(-o-1,针对偏移量,使用最后一条消息),只读取一条消息(-c1),并且通过-f参数对其进行格式化,以更易于理解:
Key (-1 bytes):
Value (13 bytes): {foo:"bar 5"}
Timestamp: 1548350164096
Partition: 0
Offset: 34
Headers: __connect.errors.topic=test_topic_json,__connect.errors.partition=0,__connect.errors.offset=94,__connect.errors.connector.name=file_sink_03,__connect.errors.task.id=0,__connect.errors.stage=VALU
E_CONVERTER,__connect.errors.class.name=org.apache.kafka.connect.json.JsonConverter,__connect.errors.exception.class.name=org.apache.kafka.connect.errors.DataException,__connect.errors.exception.message=Co
nverting byte[] to Kafka Connect data failed due to serialization error: ,__connect.errors.exception.stacktrace=org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed
due to serialization error:
[…]
也可以只显示消息头,并使用一些简单的技巧将其拆分,这样可以更清楚地看到该问题的更多信息:
$ kafkacat -b localhost:9092 -t dlq_file_sink_03 -C -o-1 -c1 -f '%h'|tr ',' '\n'
__connect.errors.topic=test_topic_json
__connect.errors.partition=0
__connect.errors.offset=94
__connect.errors.connector.name=file_sink_03
__connect.errors.task.id=0
__connect.errors.stage=VALUE_CONVERTER
__connect.errors.class.name=org.apache.kafka.connect.json.JsonConverter
__connect.errors.exception.class.name=org.apache.kafka.connect.errors.DataException
__connect.errors.exception.message=Converting byte[] to Kafka Connect data failed due to serialization error:
Kafka连接器处理的每条消息都来自源主题和该主题中的特定点(偏移量),消息头已经准确地说明了这一点。因此可以使用它来回到原始主题并在需要时检查原始消息,由于死信队列已经有一个消息的副本,这个检查更像是一个保险的做法。
根据从上面的消息头中获取的详细信息,可以再检查一下源消息:
__connect.errors.topic=test_topic_json
__connect.errors.offset=94
将这些值分别插入到kafkacat的代表主题和偏移的-t和-o参数中,可以得到:
$ kafkacat -b localhost:9092 -C\-t test_topic_json -o94\-f'\nKey (%K bytes): %k Value (%S bytes): %s Timestamp: %T Partition: %p Offset: %o Topic: %t\n'
Key (-1 bytes):
Value (13 bytes): {foo:"bar 5"}
Timestamp: 1548350164096
Partition: 0
Offset: 94
Topic: test_topic_json
与死信队列中的上述消息相比,可以看到完全相同,甚至包括时间戳,唯一的区别是主题、偏移量和消息头。
#记录消息的失败原因:日志
记录消息的拒绝原因的第二个选项是将其写入日志。根据安装方式不同,Kafka连接器会将其写入标准输出或日志文件。无论哪种方式都会为每个失败的消息生成一堆详细输出。进行如下配置可启用此功能:
errors.log.enable=true
通过配置errors.log.include.messages = true,还可以在输出中包含有关消息本身的元数据。此元数据中包括一些和上面提到的消息头中一样的项目,包括源消息的主题和偏移量。注意它不包括消息键或值本身。
这时的连接器配置如下:
curl-X POST http://localhost:8083/connectors -H"Content-Type: application/json"-d'{
"name": "file_sink_04",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file": "/data/file_sink_04.txt",
"errors.tolerance": "all",
"errors.log.enable":true,
"errors.log.include.messages":true
}
}'
连接器是可以成功运行的:
$curl-s"http://localhost:8083/connectors/file_sink_04/status"|\jq -c -M'[.name,.tasks[].state]'["file_sink_04","RUNNING"]Valid records from thesourcetopic get written to the target file:$headdata/file_sink_04.txt{foo=bar1}{foo=bar2}{foo=bar3}[…]
这时去看Kafka连接器的工作节点日志,会发现每个失败的消息都有错误记录:
ERROR Error encountered in task file_sink_04-0. Executing stage 'VALUE_CONVERTER' with class 'org.apache.kafka.connect.json.JsonConverter', where consumed record is {topic='test_topic_json', partition=0, offset=94, timestamp=1548350164096, timestampType=CreateTime}. (org.apache.kafka.connect.runtime.errors.LogReporter)
org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed due to serialization error:
at org.apache.kafka.connect.json.JsonConverter.toConnectData(JsonConverter.java:334)
[…]
Caused by: org.apache.kafka.common.errors.SerializationException: com.fasterxml.jackson.core.JsonParseException: Unexpected character ('f' (code 102)): was expecting double-quote to start field name
at [Source: (byte[])"{foo:"bar 5"}"; line: 1, column: 3]
可以看到错误本身,还有就是和错误有关的信息:
{topic='test_topic_json', partition=0, offset=94, timestamp=1548350164096, timestampType=CreateTime}
如上所示,可以在kafkacat等工具中使用该主题和偏移量来检查源主题上的消息。根据抛出的异常也可能会看到记录的源消息:
Caused by: org.apache.kafka.common.errors.SerializationException:
…
at [Source: (byte[])"{foo:"bar 5"}"; line: 1, column: 3]
#处理死信队列的消息
虽然设置了一个死信队列,但是如何处理那些“死信”呢?因为它只是一个Kafka主题,所以可以像使用任何其它主题一样使用标准的Kafka工具。上面已经看到了,比如可以使用kafkacat来检查消息头,并且对于消息的内容及其元数据的一般检查kafkacat也可以做。当然根据被拒绝的原因,也可以选择对消息进行重播。
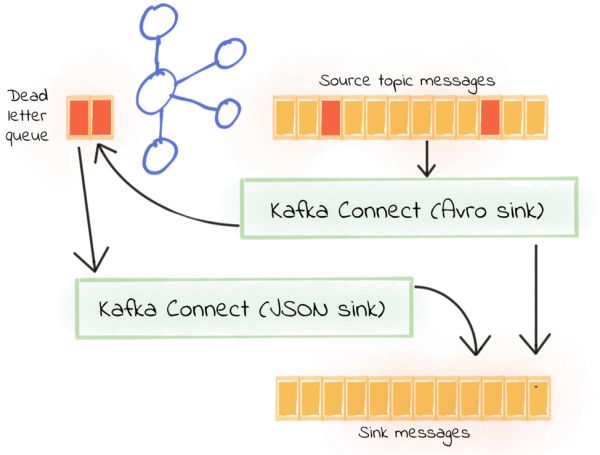
一个场景是连接器正在使用Avro转换器,但是主题上的却是JSON格式消息(因此被写入死信队列)。可能由于遗留原因JSON和Avro格式的生产者都在写入源主题,这个问题得解决,但是目前只需要将管道流中的数据写入接收器即可。
首先,从初始的接收器读取源主题开始,使用Avro反序列化并路由到死信队列:
curl-X POST http://localhost:8083/connectors -H"Content-Type: application/json"-d'{
"name": "file_sink_06__01-avro",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_avro",
"file":"/data/file_sink_06.txt",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"errors.tolerance":"all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_06__01",
"errors.deadletterqueue.topic.replication.factor":1,
"errors.deadletterqueue.context.headers.enable":true,
"errors.retry.delay.max.ms": 60000,
"errors.retry.timeout": 300000
}
}'
另外再创建第二个接收器,将第一个接收器的死信队列作为源主题,并尝试将记录反序列化为JSON,在这里要更改的是value.converter、key.converter、源主题名和死信队列名(如果此连接器需要将任何消息路由到死信队列,要避免递归)。
curl-X POST http://localhost:8083/connectors -H"Content-Type: application/json"-d'{
"name": "file_sink_06__02-json",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"dlq_file_sink_06__01",
"file":"/data/file_sink_06.txt",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"errors.tolerance":"all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_06__02",
"errors.deadletterqueue.topic.replication.factor":1,
"errors.deadletterqueue.context.headers.enable":true,
"errors.retry.delay.max.ms": 60000,
"errors.retry.timeout": 300000
}
}'
现在可以验证一下。
首先,源主题收到20条Avro消息,之后可以看到20条消息被读取并被原始Avro接收器接收:
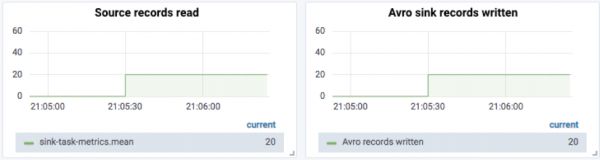
然后发送8条JSON消息,这时8条消息被发送到死信队列,然后被JSON接收器接收:

现在再发送5条格式错误的JSON消息,之后可以看到两者都有失败的消息,有2点可以确认:
从Avro接收器发送到死信队列的消息数与成功发送的JSON消息数之间有差异;
消息被发送到JSON接收器的死信队列。
#通过KSQL监控死信队列
除了使用JMX监控死信队列之外,还可以利用KSQL的聚合能力编写一个简单的流应用来监控消息写入队列的速率:
-- 为每个死信队列主题注册流。CREATESTREAM dlq_file_sink_06__01(MSGVARCHAR)WITH(KAFKA_TOPIC='dlq_file_sink_06__01',VALUE_FORMAT='DELIMITED');CREATESTREAM dlq_file_sink_06__02(MSGVARCHAR)WITH(KAFKA_TOPIC='dlq_file_sink_06__02',VALUE_FORMAT='DELIMITED');-- 从主题的开头消费数据SET'auto.offset.reset'='earliest';-- 使用其它列创建监控流,可用于后续聚合查询CREATESTREAM DLQ_MONITORWITH(VALUE_FORMAT='AVRO')AS\SELECT'dlq_file_sink_06__01'ASSINK_NAME,\'Records: 'ASGROUP_COL,\ MSG \FROMdlq_file_sink_06__01;-- 使用来自第二个死信队列的消息注入相同的监控流INSERTINTODLQ_MONITOR \SELECT'dlq_file_sink_06__02'ASSINK_NAME,\'Records: 'ASGROUP_COL,\ MSG \FROMdlq_file_sink_06__02;-- 在每个死信队列每分钟的时间窗口内,创建消息的聚合视图CREATETABLEDLQ_MESSAGE_COUNT_PER_MINAS\SELECTTIMESTAMPTOSTRING(WINDOWSTART(),'yyyy-MM-dd HH:mm:ss')ASSTART_TS,\ SINK_NAME,\ GROUP_COL,\COUNT(*)ASDLQ_MESSAGE_COUNT \FROMDLQ_MONITOR \ WINDOW TUMBLING(SIZE1MINUTE)\GROUPBYSINK_NAME,\ GROUP_COL;
这个聚合表可以以交互式的方式进行查询,下面显示了一分钟内每个死信队列中的消息数量:
ksql> SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT FROM DLQ_MESSAGE_COUNT_PER_MIN;
2019-02-01 02:56:00 | dlq_file_sink_06__01 | 9
2019-02-01 03:10:00 | dlq_file_sink_06__01 | 8
2019-02-01 03:12:00 | dlq_file_sink_06__01 | 5
2019-02-01 02:56:00 | dlq_file_sink_06__02 | 5
2019-02-01 03:12:00 | dlq_file_sink_06__02 | 5
因为这个表的下面是Kafka主题,所以可以将其路由到期望的任何监控仪表盘,还可以用于驱动告警。假定有几条错误消息是可以接受的,但是一分钟内超过5条消息就是个大问题需要关注:
CREATETABLEDLQ_BREACHAS\SELECTSTART_TS,SINK_NAME,DLQ_MESSAGE_COUNT \FROMDLQ_MESSAGE_COUNT_PER_MIN \WHEREDLQ_MESSAGE_COUNT>5;
现在又有了一个报警服务可以订阅的DLQ_BREACH主题,当收到任何消息时,可以触发适当的操作(例如通知)。
ksql> SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT FROM DLQ_BREACH;
2019-02-01 02:56:00 | dlq_file_sink_06__01 | 9
2019-02-01 03:10:00 | dlq_file_sink_06__01 | 8
#Kafka连接器哪里没有提供错误处理?
Kafka连接器的错误处理方式,如下表所示:
连接器生命周期阶段描述是否处理错误?
开始首次启动连接器时,其将执行必要的初始化,例如连接到数据存储无
拉取(针对源连接器)从源数据存储读取消息无
格式转换从Kafka主题读写数据并对JSON/Avro格式进行序列化/反序列化有
单消息转换应用任何已配置的单消息转换有
接收(针对接收连接器)将消息写入目标数据存储无
注意源连接器没有死信队列。
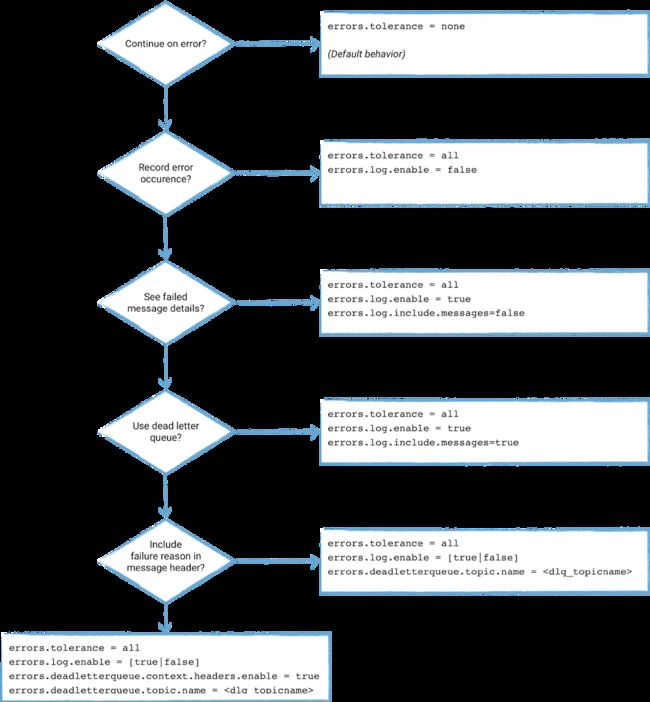
#错误处理配置流程
关于连接器错误处理的配置,可以按照如下的流程一步步进阶:
#总结
处理错误是任何稳定可靠的数据管道的重要组成部分,根据数据的使用方式,可以有两个选项。如果管道任何错误的消息都不能接受,表明上游存在严重的问题,那么就应该立即停止处理(这是Kafka连接器的默认行为)。
另一方面,如果只是想将数据流式传输到存储以进行分析或非关键性处理,那么只要不传播错误,保持管道稳定运行则更为重要。这时就可以定义错误的处理方式,推荐的方式是使用死信队列并密切监视来自Kafka连接器的可用JMX指标。