首先感谢这些博主:我这里只是学习和摘抄
七秒记忆的鱼儿 -- 2017年iOS面试题总结
就叫yang -- # iOS基础 # iOS面试题一
iOS-Interview -- 有条理性
iOS 系统层次架构

继承和多态的区别
1、属性关键字
#默认值:
1.数据类型
atomic assign readwrite
2.对象类型
atomic strong readwrite
1). readwrite 是可读可写特性;需要生成getter方法和setter方法时
2). readonly 是只读特性 只会生成getter方法 不会生成setter方法 ;不希望属性在类外改变
3). assign 是赋值特性,setter方法将传入参数赋值给实例变量;仅设置变量时;
assign 主要用于修饰基本数据类型,如NSInteger和CGFloat,这些数值主要存在于栈上。
4). weak表示指向但不拥有该对象。其修饰的对象引用计数不会增加。无需手动设置,该对象会自行在内存中销毁。
5). copy 表示赋值特性,setter方法将传入对象复制一份;需要完全一份新的变量时。
6). nonatomic 非原子操作,决定编译器生成的setter getter是否是原子操作,atomic表示多线程安全,一般使用nonatomic
7). strong 表示指向并拥有该对象。其修饰的对象引用计数会增加1。该对象只要引用计数不为0则不会被销毁。
8). retain 表示持有特性,setter方法将传入参数先保留,再赋值,传入参数的retaincount会+1;
iOS9的几个新关键字: nonnull、nullable、null_resettable、__null_unspecified
1. nonnull:字面意思就能知道:不能为空(用来修饰属性,或者方法的参数,方法的返回值)
//三种使用方式都可以
@property (nonatomic, copy, nonnull) NSString *name;
@property (nonatomic, copy) NSString * _Nonnull name;
@property (nonatomic, copy) NSString * __nonnull name;
//不适用于assign属性,因为它是专门用来修饰指针的
@property (nonatomic, assign) NSUInteger age;
//用下面宏包裹起来的属性全部都具nonnull特征,当然,如果其中某个属性你不希望有这个特征,也可以自己定义,比如加个nullable
//在NS_ASSUME_NONNULL_BEGIN和NS_ASSUME_NONNULL_END之间,定义的所有对象属性和方法默认都是nonnull
//也可以在定义方法的时候使用
//返回值和参数都不能为空
- (nonnull NSString *)test:(nonnull NSString *)name;
//同上
- (NSString * _Nonnull)test1:(NSString * _Nonnull)name;
2. nullable 表示可以为空。
//三种使用方式
@property (nonatomic, copy, nullable) NSString *name;
@property (nonatomic, copy) NSString *_Nullable name;
@property (nonatomic, copy) NSString *__nullable name;
3、null_resettable: get:不能返回空, set可以为空(注意:如果使用null_resettable,
必须重写get方法或者set方法,处理传递的值为空的情况)
// 书写方式:
@property (nonatomic, copy, null_resettable) NSString *name;
设置一下set或get方法
- (void)setName:(NSString *)name
{
if (name == nil) {
name = @"Jone";
}
_name = name;
}
- (NSString *)name
{
if (_name == nil) {
_name = @"Jone";
}
return _name;
}
4、_Null_unspecified:不确定是否为空
使用方式只有这两种:
@property (nonatomic, strong) NSString *_Null_unspecified name;
@property (nonatomic, strong) NSString *__null_unspecified name;
1.1深拷贝和浅拷贝?
浅拷贝:浅拷贝并不拷贝对象本身,只是对指向对象的指针进行拷贝
深拷贝:直接拷贝对象到内存中一块区域,然后把新对象的指针指向这块内存(生成新对象)
#在非集合类对象中:
[immutableObject copy] // 浅复制
[immutableObject mutableCopy] //深复制
[mutableObject copy] //深复制
[mutableObject mutableCopy] //深复制
#在集合对象中:
对 immutable 对象进行 copy,是指针复制【浅拷贝】, mutableCopy 是内容复制【深拷贝】;对 mutable 对象进行 copy 和 mutableCopy 都是内容复制。
#但是:集合对象的内容复制仅限于对象本身,对象里面的每个元素仍然是指针复制。
[immutableObject copy] // 浅复制
[immutableObject mutableCopy] //单层深复制
[mutableObject copy] //单层深复制
[mutableObject mutableCopy] //单层深复制
#iOS 中集合对象的“深拷贝”只拷贝了一个壳,对于壳内的每个元素是浅拷贝。
1.2.0 如何让自己的类用copy修饰符?
若想令自己所写的对象具有拷贝功能,则需实现 NSCopying 协议。如果自定义的对象分为可变版本与不可变版本,
那么就要同时实现 NSCopying 与 NSMutableCopying 协议。
具体步骤:
1)需声明该类遵从 NSCopying 协议
2)实现 NSCopying 协议。该协议只有一个方法:
- (id)copyWithZone:(NSZone *)zone;
1.2 写一个setter方法用于完成@property (nonatomic,retain)NSString *name,写一个setter方法用于完成@property(nonatomic,copy)NSString *name
- (void)setName:(NSString*)str
{
[str retain];
[name release];
name = str;
}
- (void)setName:(NSString *)str
{
id t = [str copy];
[name release];
name = t;
}
1.3 用@property声明的 NSString / NSArray / NSDictionary 经常使用 copy 关键字,为什么?如果改用strong关键字,可能造成什么问题?
用 @property 声明 NSString、NSArray、NSDictionary 经常使用 copy 关键字,
是因为他们有对应的可变类型:NSMutableString、NSMutableArray、NSMutableDictionary,
他们之间可能进行赋值操作(就是把可变的赋值给不可变的),为确保对象中的字符串值不会无意间变动,
应该在设置新属性值时拷贝一份。
1. 因为父类指针可以指向子类对象,使用 copy 的目的是为了让本对象的属性不受外界影响,
使用 copy 无论给我传入是一个可变对象还是不可对象,我本身持有的就是一个不可变的副本。
2. 如果我们使用是 strong ,那么这个属性就有可能指向一个可变对象,
如果这个可变对象在外部被修改了,那么会影响该属性。
#总结:使用copy的目的是,防止把可变类型的对象赋值给不可变类型的对象时,
# 可变类型对象的值发送变化会无意间篡改不可变类型对象原来的值。
1.4.请解释以下keywords的区别: assign vs weak, __block vs __weak
它们都是是一个弱引用。
assign适用于基本数据类型,weak是适用于NSObject对象,
assign其实也可以用来修饰对象,那么我们为什么不用它呢?因为被assign修饰的对象在释放之后,
指针的地址还是存在的,也就是说指针并没有被置为nil。
如果在后续的内存分配中,刚好分到了这块地址,程序就会崩溃掉。
#而weak修饰的对象在释放之后,指针地址会被置为nil。所以现在一般弱引用就是用weak。
首先__block是用来修饰一个变量,这个变量就可以在block中被修改(参考block实现原理)
__block:使用__block修饰的变量在block代码快中会被retain(ARC下,MRC下不会retain)
__weak:使用__weak修饰的变量不会在block代码块中被retain
同时,在ARC下,要避免block出现循环引用 __weak
1.5 synthesize和dynamic分别有什么作用
@synthesize的作用:
为Property指定生成要生成的成员变量名,并生成getter和setter方法。
用途:对于只读属性,如果同时重新setter和getter方法,就需要使用synthesize来手动合成成员变量
@dynamic的作用:
告诉编译器,不用为指定的Property生成getter和setter。使用方式:当我们在分类中使用Property为类扩展属性时,
编译器默认不会为此property生成getter和setter,这时就需要用dynamic告诉编译器,自己合成了
2、说一下appdelegate的几个方法?从后台到前台调用了哪些方法?第一次启动调用了哪些方法?从前台到后台调用了哪些方法?iOS应用程序生命周期(前后台切换,应用的各种状态)详解
 image
image
3.ViewController生命周期
按照执行顺序排列:
1. initWithCoder:通过nib文件初始化时触发。
2. awakeFromNib:nib文件被加载的时候,会发生一个awakeFromNib的消息到nib文件中的每个对象。
//如果不是nib初始化 上面两个换成 initWithNibName:bundle:
3. loadView:开始加载视图控制器自带的view。
4. viewDidLoad:视图控制器的view被加载完成。
5. viewWillAppear:视图控制器的view将要显示在window上。
6. updateViewConstraints:视图控制器的view开始更新AutoLayout约束。
7. viewWillLayoutSubviews:视图控制器的view将要更新内容视图的位置。
8. viewDidLayoutSubviews:视图控制器的view已经更新视图的位置。
9. viewDidAppear:视图控制器的view已经展示到window上。
10.viewWillDisappear:视图控制器的view将要从window上消失。
11.viewDidDisappear:视图控制器的view已经从window上消失。
3.1 layoutsubviews是在什么时机调用的?
1.init初始化不会触发。
2.addSubview时。
3.设置frame且前后值变化,frame为zero且不添加到指定视图不会触发。
(ps: 当view的size的值为0的时候,addSubview也不会调用layoutSubviews。
当要给这个view添加子控件的时候不管他的size有没有值都会调用)
4.旋转Screen会触发父视图的layoutSubviews。
5.滚动UIScrollView引起View重新布局时会触发layoutSubviews。
3.2 什么是异步渲染?
异步渲染就是在子线程进行绘制,然后拿到主线程显示。
UIView的显示是通过CALayer实现的,CALayer的显示则是通过contents进行的。
异步渲染的实现原理是当我们改变UIView的frame时,会调用layer的setNeedsDisplay,然后调用layer的display方法。
我们不能在非主线程将内容绘制到layer的context上,但我们单独开一个子线程通过CGBitmapContextCreateImage()绘制内容,
绘制完成之后切回主线程,将内容赋值到contents上。
3.3 frame和Bounds 以及frame和bounds区别
1.frame不管对于位置还是大小,改变的都是自己本身
2、frame的位置是以父视图的坐标系为参照,从而确定当前视图在父视图中的位置
3、frame的大小改变时,当前视图的左上角位置不会发生改变,只是大小发生改变
4、bounds改变位置时,改变的是子视图的位置,自身没有影响;
其实就是改变了本身的坐标系原点,默认本身坐标系的原点是左上角
5、bounds的大小改变时,当前视图的中心点不会发生改变,
当前视图的大小发生改变,看起来效果就想缩放一样
3.4 UIView和CALayer是啥关系?
一、UIView 负责响应事件,CALayer 负责绘制 UI
1.首先从继承关系来分析两者:UIView : UIResponder,CALayer : NSObject。
2.UIView 对 CALayer 封装属性
UIView 中持有一个 layer 对象,同时是这个 layer 对象 delegate,UIView 和 CALayer 协同工作。
平时我们对 UIView 设置 frame、center、bounds 等位置信息,其实都是 UIView 对 CALayer 进一层封装,
使得我们可以很方便地设置控件的位置;例如圆角、阴影等属性, UIView 就没有进一步封装,
所以我们还是需要去设置 Layer 的属性来实现功能。
Frame 属性主要是依赖:bounds、anchorPoint、transform、和position。
3.UIView 是 CALayer 的代理
UIView 持有一个 CALayer 的属性,并且是该属性的代理,用来提供一些 CALayer 行的数据,例如动画和绘制。
//绘制相关
- (void)drawLayer:(CALayer *)layer inContext:(CGContextRef)ctx;
//动画相关
- (nullable id)actionForLayer:(CALayer *)layer forKey:(NSString *)event;
4.self 和 super
self 是类的隐藏参数,指向当前调用方法的这个类的实例。
super是一个Magic Keyword,它本质是一个编译器标示符,和self是指向的同一个消息接收者。
不同的是:super会告诉编译器,调用class这个方法时,要去父类的方法,而不是本类里的。
NSArray与NSSet的区别?
1.
NSArray内存中存储地址连续,而NSSet不连续
NSSet效率高,内部使用hash查找;NSArray查找需要遍历
NSSet通过anyObject访问元素,NSArray通过下标访问
2、NSHashTable与NSMapTable?
NSHashTable是NSSet的通用版本,对元素弱引用,可变类型;可以在访问成员时copy
NSMapTable是NSDictionary的通用版本,对元素弱引用,可变类型;可以在访问成员时copy
(注:NSHashTable与NSSet的区别:NSHashTable可以通过option设置元素弱引用/copyin,只有可变类型。但是添加对象的时候NSHashTable耗费时间是NSSet的两倍。
NSMapTable与NSDictionary的区别:同上)
3.说说NSCache优于NSDictionary的几点
1.NSCache是可以自动释放内存的。
2. NSCache是线程安全的,我们可以在不同的线程中添加,删除和查询缓存中的对象。
3.NSCache可以设置缓存上限,限制对象个数和总缓存开销。定义了删除缓存对象的时机。这个机制只对NSCache起到指导作用,不会一定执行。
4.一个缓存对象不会拷贝key对象。
5.事件传递和响应者链条
#响应者链条
1.如果view的控制器存在,就传递给控制器;如果控制器不存在,则将其传递给它的父视图
2.在视图层次结构的最顶级视图,如果也不能处理收到的事件或消息,
则其将事件或消息传递给window对象进行处理
3.如果window对象也不处理,则其将事件或消息传递给UIApplication对象
4.如果UIApplication也不能处理该事件或消息,则将其丢弃
#点击屏幕时是如何互动的?
1.iOS系统检测到手指触摸(Touch)操作时会将其打包成一个UIEvent对象,
2.并放入当前活动Application的事件队列中,
3.单例的UIApplication会从事件队列中取出触摸事件并传递给单例的UIWindow来处理,
4.UIWindow对象首先会使用hitTest:withEvent:方法寻找此次Touch操作初始点所在的视图(View),
即需要将触摸事件传递给其处理的视图,这个过程称之为hit-test view。
UIWindow实例对象会首先在它的内容视图上调用hitTest:withEvent:,
此方法会在其视图层级结构中的每个视图上调用pointInside:withEvent:
(该方法用来判断点击事件发生的位置是否处于当前视图范围内,以确定用户是不是点击了当前视图),
如果pointInside:withEvent:返回YES,否则继续逐级调用,直到找到touch操作发生的位置,
这个视图也就是要找的hit-test view。
#hitTest:withEvent:方法的处理流程如下:
1、首先调用当前视图的pointInside:withEvent:方法判断触摸点是否在当前视图内;
2。若返回NO,则hitTest:withEvent:返回nil;
3.若返回YES,则向当前视图的所有子视图(subviews)发送hitTest:withEvent:消息,
所有子视图的遍历顺序是从最顶层视图一直到到最底层视图,
即从subviews数组的末尾向前遍历,直到有子视图返回非空对象或者全部子视图遍历完毕;
4.若第一次有子视图返回非空对象,则hitTest:withEvent:方法返回此对象,处理结束;
如所有子视图都返回非,则hitTest:withEvent:方法返回自身(self)。
#事件的传递和响应分两个链:
#传递链:由系统向离用户最近的view传递。
UIKit –> active app’s event queue –> window –> root view –>……–>lowest view
#响应链:由离用户最近的view向系统传递。
initial view –> super view –> …..–> view controller –> window –> Application
6.category 的作用?它为什么会覆盖掉原来的方法?
美团--深入理解Objective-C:Category
一、什么是分类:利用Objective-C的动态运行时分配机制,可以为现有的类添加新方法
我们添加的实例方法,会被动态的添加到类结构里面的methodList列表里面。
1).Category 的实现原理?
* Category 实际上是 Category_t的结构体,在运行时,新添加的方法,都被以倒序插入到原有方法列表的最前面,所以不同的Category,添加了同一个方法,执行的实际上是最后一个。
* Category 在刚刚编译完的时候,和原来的类是分开的,只有在程序运行起来后,通过 Runtime ,Category 和原来的类才会合并到一起。
二、主要作用:
1. 将类的实现分开到不同的文件中
2. 对私有方法的前向引用
3. 向对象添加非正式协议
三、它为什么会覆盖掉原来的方法?
category的方法被放到了新方法列表的前面,而原来类的方法被放到了新方法列表的后面,
这也就是我们平常所说的category的方法会“覆盖”掉原来类的同名方法,这是因为运行时在查找方法的时候是顺着方法列表的顺序查找的,
它只要一找到对应名字的方法,就会罢休^_^,殊不知后面可能还有一样名字的方法。
所以我们只要顺着方法列表找到最后一个对应名字的方法,就可以调用原来类的方法
四、类别和类扩展的区别。
答:category和extensions的不同在于 后者可以添加属性。另外后者添加的方法是必须要实现的。
6.1.category为什么不能添加属性?
category 它是在运行期决议的,因为在运行期,对象的内存布局已经确定,如果添加实例变量就会破坏类的内部布局,
这对编译型语言来说是灾难性的。
extension看起来很像一个匿名的category,但是extension和有名字的category几乎完全是两个东西。
extension在编译期决议,它就是类的一部分,在编译期和头文件里的@interface以及实现文件里的
@implement一起形成一个完整的类,它伴随类的产生而产生,亦随之一起消亡。extension一般用来隐藏类的私有信息,
你必须有一个类的源码才能为一个类添加extension,所以你无法为系统的类比如NSString添加extension。
但是category则完全不一样,它是在运行期决议的。
就category和extension的区别来看,我们可以推导出一个明显的事实,
extension可以添加实例变量,而category是无法添加实例变量的。
6.2. 那为什么 使用Runtime技术中的关联对象可以为类别添加属性。
1.其原因是:关联对象都由AssociationsManager管理,
AssociationsManager里面是由一个静态AssociationsHashMap来存储所有的关联对象的。
这相当于把所有对象的关联对象都存在一个全局map里面。
而map的的key是这个对象的指针地址(任意两个不同对象的指针地址一定是不同的),
而这个map的value又是另外一个AssociationsHashMap,里面保存了关联对象的kv对。
2.如合清理关联对象?
runtime的销毁对象函数objc_destructInstance里面会判断这个对象有没有关联对象,
如果有,会调用_object_remove_assocations做关联对象的清理工作。
Objective-C Associated Objects 的实现原理
7.Block --Block的本质
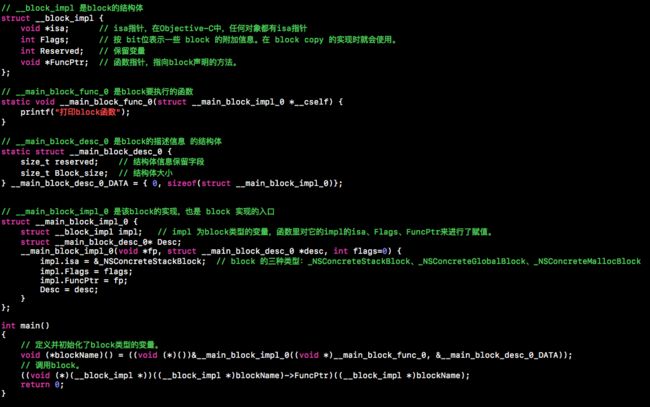
1) 什么是Block和它的本质是什么(block 是带自动变量的匿名函数)
block本质上也是一个OC对象,它内部也有个isa指针
block是封装了函数调用以及函数调用环境的OC对象
block是封装函数及其上下文的OC对象
2) Block 的类型:
__NSGlobalBlock:不使用外部变量的block是全局block
__NSStackBlock: 使用外部变量并且未进行copy操作的block是栈block
__NSMallocBlock:对栈block进行copy操作,就是堆block,而对全局block进行copy,仍是全局block
Block访问外界变量
MRC 环境下:访问外界变量的 Block 默认存储栈中。
ARC 环境下:访问外界变量的 Block 默认存储在堆中(实际是放在栈区,然后ARC情况下自动又拷贝到堆区),自动释放。
3) 在ARC环境下,编译器会根据情况自动将栈上的block复制到堆上的几种情况?
1.block作为函数返回值时
2.将block赋值给__strong指针时
3.block作为Cocoa API中方法名含有usingBlock的方法参数时
4.block作为GCD API的方法参数时
4) block 为什么用copy 修饰?
block在创建的时候,它的内存是分配在栈上的,而不是在堆上。他本身的作于域是属于创建时候的作用域,一旦在创建时候的作用域外面调用block将导致程序崩溃。
因为栈区的特点就是创建的对象随时可能被销毁,一旦被销毁后续再次调用空对象就可能会造成程序崩溃,在对block进行copy后,block存放在堆区.
ps) swift中 closure 与OC中block的区别?
1、closure是匿名函数、block是一个结构体对象
2、closure通过逃逸闭包来在内部修改变量,block 通过 __block 修饰符
Block原理、Block变量截获、Block的三种形式、__block
8.消息的传递方式
KVC&KVO的实现原理
#1.KVC也叫键值编码
KVC是基于runtime机制实现的,运用 isa 指针,通过 key 间接对对象的属性进行操作
程序优先调用setKey属性值方法-->_key -->_isKey-->如果上面列出的方法或者成员变量都不存在, 系统将会执行该对象的setValue:forUndefinedKey:方法,默认是抛出异常。
#2.KVO也叫键值监听
当某个类的属性第一次被观察时,系统就会在运行期动态地创建该类的一个派生类,
在这个派生类中重写基类中任何被观察属性的setter 方法。
并修改当前 isa 指针指向这个类,从而在给被监控属性赋值时执行的是派生类的setter方法
苹果还重写了class 方法,返回原来的类
#深入 如何手动调用KVO?
子类setter方法剖析:KVO的键值观察通知依赖于
NSObject 的两个方法:willChangeValueForKey:和 didChangevlueForKey:,
在存取数值的前后分别调用2个方法: 被观察属性发生改变之前,willChangeValueForKey:被调用,
通知系统该 keyPath?的属性值即将变更;
当改变发生后, didChangeValueForKey: 被调用,
通知系统该 keyPath 的属性值已经变更;
之后,observeValueForKeyPath:ofObject:change:context: 也会被调用。
且重写观察属性的setter方法这种继承方式的注入是在运行时而不是编译时实现的。
#通知和代理有什么区别
通知是观察者模式,适合一对多的场景
代理模式适合一对一的反向传值
通知耦合度低,代理的耦合度高
#block和delegate的区别
1.delegate运行成本低,block的运行成本高
block出栈需要将使用的数据从栈内存拷贝到堆内存,当然对象的话就是加计数,
使用完或者block置nil后才消除。delegate只是保存了一个对象指针,直接回调,没有额外消耗。
就像C的函数指针,只多做了一个查表动作。
2.delegate更适用于多个回调方法(3个以上),block则适用于1,2个回调时。
9.设计模式
1. 单例模式
单例模式:
简单的来说,一个单例类,在整个程序中只有一个实例,并且提供一个类方法供全局调用,
在编译时初始化这个类,然后一直保存在内存中,到程序(APP)退出时由系统自动释放这部分内存。
优点:
(1)、在整个程序中只会实例化一次,所以在程序如果出了问题,可以快速的定位问题所在;
(2)、由于在整个程序中只存在一个对象,节省了系统内存资源,提高了程序的运行效率;
缺点:
(1)、不能被继承,不能有子类;
(2)、不易被重写或扩展(可以使用分类);
(3)、同时,由于单例对象只要程序在运行中就会一直占用系统内存,该对象在闲置时并不能销毁,在闲置时也消耗了系统内存资源;
Q: 如果单例的静态变量被置为nil了,是否内存会得到释放?
A1: 静态变量修饰的指针保存在了全局区域,不会被释放。但是指针保存的首地址关联的对象是保存在堆区的,是会被释放的。
A2:不会被释放的,如果想要释放的话 需要重写attempDelloc方法,在里面讲onceToke置为nil,instance置为nil
2.代理模式
代理模式:
一种一对一的消息传递方式,由代理对象、委托者、协议三部分组成。
Q:代理用weak还是assign ?
A:assign是指针赋值,不对引用计数操作,使用之后如果没有置为nil,可能就会产生野指针;而weak一旦不进行使用后,永远不会使用了,就不会产生野指针。
3.观察者模式
观察者模式:
一种一对多的消息传递方式,当一个物体发生变化时,会通知所有观察这个物体的观察者让其做出反应
10. 内存管理
10.1 iOS内存分区情况
1. 栈区(Stack)
由编译器自动分配释放,存放函数的参数,局部变量的值等
栈是向低地址扩展的数据结构,是一块连续的内存区域
2.堆区(Heap)
由程序员分配释放
是向高地址扩展的数据结构,是不连续的内存区域
3.全局区
全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,
未初始化的全局变量和未初始化的静态变量在相邻的另一块区域
程序结束后由系统释放
4.常量区
常量字符串就是放在这里的
程序结束后由系统释放
5.代码区
存放函数体的二进制代码
注:
在 iOS 中,堆区的内存是应用程序共享的,堆中的内存分配是系统负责的
系统使用一个链表来维护所有已经分配的内存空间(系统仅仅记录,并不管理具体的内容)
变量使用结束后,需要释放内存,OC 中是判断引用计数是否为 0,如果是就说明没有任何变量使用该空间,那么系统将其回收
当一个 app 启动后,代码区、常量区、全局区大小就已经固定,因此指向这些区的指针不会产生崩溃性的错误。
而堆区和栈区是时时刻刻变化的(堆的创建销毁,栈的弹入弹出),所以当使用一个指针指向这个区里面的内存时,
一定要注意内存是否已经被释放,否则会产生程序崩溃(也即是野指针报错)
Q1:递归调用中栈溢出原因?
函数调用的参数是通过栈空间来传递的,在调用过程中会占用线程的栈资源。
而递归调用,只有走到最后的结束点后函数才能依次退出,而未到达最后的
结束点之前,占用的栈空间一直没有释放,如果递归调用次数过多,就可能
导致占用的栈资源超过线程的最大值,从而导致栈溢出,
导致程序的异常退出。
Q2: 无限长的字符串作为函数参数传参时,会不会有内存问题?
不会,字符串在常量区
iOS内存管理(MRC、ARC)深入浅出
1) 什么是 ARC?
ARC全称是 Automatic Reference Counting,是Objective-C的内存管理机制。
简单地来说,就是代码中自动加入了retain/release,原先需要手动添加的
用来处理内存管理的引用计数的代码,可以自动地由编译器完成了。
#ARC的使用是为了解决:对象retain和release匹配的问题。
以前手动管理造成内存泄漏或者重复释放的问题将不复存在。
2) 什么是 MRC?
以前需要手动的通过retain去为对象获取内存,
并用release释放内存。所以以前的操作称为MRC (Manual Reference Counting)。
#内存管理的原则
1.自己生成的对象,自己持有
// 使用了alloc分配了内存,obj指向了对象,该对象本身引用计数为1,不需要retain
id obj = [[NSObject alloc] init];
// 使用了new分配了内存,objc指向了对象,该对象本身引用计数为1,不需要retain
id obj = [NSObject new];
2.也可持有非自己生成的对象
// NSMutableArray通过类方法array产生了对象(并没有使用alloc、new、copy、mutableCopt来产生对象),因此该对象不属于obj自身产生的
// 因此,需要使用retain方法让对象计数器+1,从而obj可以持有该对象(尽管该对象不是他产生的)
id obj = [NSMutableArray array];
[obj retain];
3.不再需要自己持有对象时释放
id obj = [NSMutableArray array];
[obj retain];
// 当obj不在需要持有的对象,那么,obj应该发送release消息
[obj release];
// 释放了对象还进行释放,会导致奔溃
[obj release];
4.非自己持有的对象无法释放
// 释放一个不属于自己的对象
id obj = [NSMutableArray array];
// obj没有进行retain操作而进行release操作,然后autoreleasePool也会对其进行一次release操作,导致奔溃。
[obj release];
# 针对[NSMutableArray array]方法取得的对象存在,自己却不持有对象,底层大致实现:
+ (id)object {
//自己持有对象
id obj = [[NSObject alloc]init];
[obj autorelease];
//取得的对象存在,但自己不持有对象
return obj;
}
#注意这些原则里的一些关键词与方法的对应关系:
『生成』- alloc\new\copy\mutableCopy
『持有』- retain
『释放』- release
『废弃』- dealloc
10.2 AutoreleasePool底层实现原理
Objective-C Autorelease Pool 的实现原理
使用场景:1、降低内存使用峰值(当你使用类似for循环这样的逻辑需要产生大量的中间变量时,Autorelease Pool无意是最佳的一种解决方案)
Autorelease Pool作用:缓存池,可以避免我们经常写relase的一种方式。其实就是延迟release,
将创建的对象,添加到最近的autoreleasePool中,
等到autoreleasePool作用域结束的时候,会将里面所有的对象的引用计数器-1.
#autorelease何时释放
1.在没有使用@autoreleasepool的情况,autorelease对象是在当前的runloop迭代结束时释放。
每个runloop中都会创建一个 autoreleasepool 并在runloop迭代结束进行释放。
2.如果是手动创建autoreleasepool,自己创建Pool并释放:
指针常量和常量指针的区别?
1. 指针常量就是指针本身是常量,换句话说,就是指针里面所存储的内容(内存地址)是常量,不能改变。
但是,内存地址所对应的内容是可以通过指针改变的。
/*指针常量的例子*/
int a,b;
int * const p;
p = &a;//错误
p = &b;//错误
*p = 20;//正确
2.
常量指针就是指向常量的指针,换句话说,就是指针指向的是常量,
它指向的内容不能发生改变,不能通过指针来修改它指向的内容。
但是,指针自身不是常量,它自身的值可以改变,从而指向另一个常量。
/*常量指针的例子*/
int a,b;
int const *p;
p = &a;//正确
p = &b;//正确
*p = 20;//错误
ps: 关于区分指针常量的一个小技巧:const后的内容为不能修改的
数组和链表的区别
数组:数组元素在内存上连续存放,可以通过下标查找元素;
插入、删除需要移动大量元素,比较适用于元素很少变化的情况
链表:链表中的元素在内存中不是顺序存储的,
查找慢,插入、删除只需要对元素指针重新赋值,效率高
11.UITableview的优化方法 YYKit 作者--iOS 保持界面流畅的技巧
1、减少所有对主线程有影响的无意义操作
2、避免cell的过多重新布局,差别太大的cell之间不要选择重用。
3、尽量减少动态添加View的操作
4、简化cell 的层次结构
4、缓存cell的高度,内容
5、cell中的图片加载用异步加载,缓存等
6、按需加载,局部更新cell
7、减少离屏渲染
会触发离屏渲染的操作
(ps:--shouldRasterize(光栅化)
--masks(遮罩)
--shadows(阴影)
--edge antialiasing(抗锯齿)
--group opacity(不透明)
--复杂形状设置圆角等
--渐变)
13.网络
1. post 和 get 的区别
1.GET在浏览器回退时是无害的,而POST会再次提交请求。
2.GET产生的URL地址可以被Bookmark,而POST不可以。
3.GET请求会被浏览器主动cache,而POST不会,除非手动设置。
4.GET请求只能进行url编码,而POST支持多种编码方式。
5.GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
6.GET请求在URL中传送的参数是有长度限制的,而POST么有。
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
7.GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
8.GET参数通过URL传递,POST放在Request body中。
iOS开发之HTTP与HTTPS网络请求
https三次握手
2. iOS即时通讯,从入门到“放弃”?
3.IM消息送达保证机制实现
14.多线程
1.并行 和 并发 有什么区别?
2.GCD 和 NSOperation 区别及各自应用场景
14.1进程和线程的区别?同步异步的区别?并行和并发的区别?
1.进程:是具有一定独立功能的程序关于某个数据集合上的一次运行活动,
进程是系统进行资源分配和调度的一个独立单位.
2.线程:是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.
线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),
但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
3.同步:阻塞当前线程操作,不能开辟线程。
4.异步:不阻碍线程继续操作,可以开辟线程来执行任务。
5.并发:当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,
它只能把CPU运行时间划分成若干个时间段,再将时间 段分配给各个线程执行,在一个时间段的线程代码运行时,
其它线程处于挂起状。.这种方式我们称之为并发(Concurrent)。
5.并行:当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,
另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
6.区别:并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻发生;
而并发是指两个或多个事件在同一时间间隔内发生。在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,
但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。
倘若在计算机系统中有多个处理机,则这些可以并发执行的程序便可被分配到多个处理机上,实现并行执行,
即利用每个处理机来处理一个可并发执行的程序,这样,多个程序便可以同时执行。
15.Runtime
关于 Runtime 的一些问题解答
1.isa指针的理解,对象的isa指针指向哪里?isa指针有哪两种类型?
* isa 等价于 is kind of
1)实例对象的 isa 指向类对象
2)类对象的 isa 指向元类对象
3)元类对象的 isa 指向元类的基类
* isa 有两种类型
1)纯指针,指向内存地址
2)NON_POINTER_ISA,除了内存地址,还存有一些其他信息
2.能否向编译后得到的类中增加实例变量?能否向运行时创建的类中添加实例变量?为什么?
不能向编译后得到的类中增加实例变量;
能向运行时创建的类中添加实例变量;
1.因为编译后的类已经注册在 runtime 中,类结构体中的 objc_ivar_list 实例变量的链表和
instance_size 实例变量的内存大小已经确定,同时runtime会调用 class_setvarlayout 或
class_setWeaklvarLayout 来处理strong weak 引用.所以不能向存在的类中添加实例变量。
2.运行时创建的类是可以添加实例变量,调用class_addIvar函数. 但是的在调用
objc_allocateClassPair 之后,objc_registerClassPair 之前,原因同上.
3.runtime如何实现weak变量的自动置nil?
runtime 对注册的类, 会进行布局,
对于 weak 修饰的对象会放入一个 hash 表中。 用 weak 指向的对象内存地址作为 key,
当此对象的引用计数为0的时候会 dealloc,假如 weak 指向的对象内存地址是a,
那么就会以a为键, 在这个 weak 表中搜索,找到所有以a为键的 weak 对象,从而设置为 nil。
4.runtime如何通过selector找到对应的IMP地址?
每一个类对象中都一个方法列表,方法列表中记录着方法的名称,方法实现,以及参数类型,
其实selector本质就是方法名称,通过这个方法名称就可以在方法列表中找到对应的方法实现.
5.objc在向一个对象发送消息时,发生了什么?
1.根据对象的isa指针找到类对象id,
2.在查询类对象里面的methodLists方法函数列表,
3.如果没有找到,再沿着superClass,寻找父类,
4.再在父类methodLists方法列表里面查询,
5.最终找到SEL,根据id和SEL确认IMP(指针函数),在发送消息;
6.当最终查询不到的时候我们会报unrecognized selector错误
6.objc中向一个nil对象发送消息将会发生什么?(返回值是对象,是标量,结构体)
1. 如果一个方法返回值是一个对象,那么发送给nil的消息将返回0(nil)。
例如:Person * motherInlaw = [ aPerson spouse] mother];
如果spouse对象为nil,那么发送给nil的消息mother也将返回nil。
2. 如果方法返回值为指针类型,
其指针大小为小于或者等于sizeof(void*),float,double,long double
或者long long的整型标量,
发送给nil的消息将返回0。
3. 如果方法返回值为结构体,发送给nil的消息将返回0。
结构体中各个字段的值将都是0。其他的结构体数据类型将不是用0填充的。
4. 如果方法的返回值不是上述提到的几种情况,那么发送给nil的消息的返回值将是未定义的。
7.什么时候会报unrecognized selector错误?iOS有哪些机制来避免走到这一步?
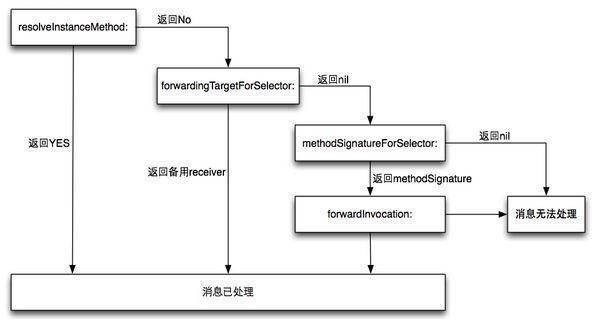
答:
objc在向一个对象发送消息时,runtime库会根据对象的isa指针找到该对象实际所属的类,然后在该
类中的方法列表以及其父类方法列表中寻找方法运行,如果,在最顶层的父类中依然找不到相应的方
法时,会进入消息转发阶段,如果消息三次转发流程仍未实现,则程序在运行时会挂掉并抛出异常
unrecognized selector sent to XXX
#原因:
当发送消息的时候,我们会根据类里面的methodLists列表去查询我们要动用的SEL,
当查询不到的时候,我们会一直沿着父类查询,
当最终查询不到的时候我们会报unrecognized selector错误
#处理机制:会有三次机会处理
#第一次机会:
当系统查询不到方法的时候,会调用+(BOOL)resolveInstanceMethod:(SEL)sel
动态添加一个新方法并执行的机会。
#第二次机会:
或者我们可以再次使用-(id)forwardingTargetForSelector:(SEL)aSelector
这个方法是系统提供的一个将 SEL 转给其他对象的机会
#第三次机会:
这一步是Runtime最后一次给你挽救的机会。
1.首先它会发送-methodSignatureForSelector:消息获得函数的参数和返回值类型。
2.如果-methodSignatureForSelector:返回nil,
Runtime则会发出-doesNotRecognizeSelector:消息,程序这时也就挂掉了。
3.如果返回了一个函数签名,Runtime就会创建一个NSInvocation对象
并发送-forwardInvocation:消息给目标对象。
16.RunLoop -- YYKit 大神对RunLoop的理解 和 sunnyxx 大神对RunLoop 的理解 -- 视频
1.runloop是来做什么的?runloop和线程有什么关系?主线程默认开启了runloop么?子线程呢?
RunLoop:RunLoop 实际上就是一个对象,这个对象管理了其需要处理的事件和消息。
一般来说:一个线程一次只能执行一个任务,执行完成后线程就会退出。RunLoop是让线程能随时处理事件但并不退出一种机制。
runloop和线程的关系:线程和 RunLoop 之间是一一对应的,其关系是保存在一个全局的 Dictionary 里
主线程默认是开启一个runloop。也就是这个runloop才能保证我们程序正常的运行。
子线程是默认没有开始runloop的
2.runloop的mode是用来做什么的?有几种mode?
model:是runloop里面的模式,不同的模式下的runloop处理的事件和消息有一定的差别。
系统默认注册了5个Mode:
(1)kCFRunLoopDefaultMode: App的默认 Mode,通常主线程是在这个 Mode 下运行的。
(2)UITrackingRunLoopMode: 界面跟踪 Mode,用于 ScrollView 追踪触摸滑动,保证界面滑动时不受其他 Mode 影响。
(3)UIInitializationRunLoopMode: 在刚启动 App 时第进入的第一个 Mode,启动完成后就不再使用。
(4)GSEventReceiveRunLoopMode: 接受系统事件的内部 Mode,通常用不到。
(5)kCFRunLoopCommonModes: 这是一个占位的 Mode,没有实际作用。
注意iOS 对以上5中model进行了封装
NSDefaultRunLoopMode;
NSRunLoopCommonModes
3.为什么把NSTimer对象以NSDefaultRunLoopMode(kCFRunLoopDefaultMode)添加到主运行循环以后,滑动scrollview的时候NSTimer却不动了?
NSTimer 对象是在 `NSDefaultRunLoopMode`下面调用消息的,
但是当我们滑动scrollview的时候,`NSDefaultRunLoopMode`模式就自动切换到`UITrackingRunLoopMode`模式下面,
却不可以继续响应nstime发送的消息。所以如果想在滑动scrollview的情况下面还调用NSTimer的消息,
我们可以把nsrunloop的模式更改为`NSRunLoopCommonModes`
4.AFNetworking 中如何运用 Runloop?
AFURLConnectionOperation 这个类是基于 NSURLConnection 构建的,其希望能在后台线程接收
Delegate 回调。为此 AFNetworking 单独创建了一个线程,并在这个线程中启动了一个 RunLoop:
+ (void)networkRequestThreadEntryPoint:(id)__unused object {
@autoreleasepool {
[[NSThread currentThread] setName:@"AFNetworking"];
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
[runLoop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
[runLoop run];
}
}
+ (NSThread *)networkRequestThread {
static NSThread *_networkRequestThread = nil;
static dispatch_once_t oncePredicate;
dispatch_once(&oncePredicate, ^{
_networkRequestThread = [[NSThread alloc] initWithTarget:self selector:@selector(networkRequestThreadEntryPoint:) object:nil];
[_networkRequestThread start];
});
return _networkRequestThread;
}
RunLoop 启动前内部必须要有至少一个 Timer/Observer/Source,所以 AFNetworking 在 [runLoop run] 之前先创建了一个新的 NSMachPort 添加进去了。通常情况下,调用者需要持有这个 NSMachPort (mach_port) 并在外部线程通过这个 port 发送消息到 loop 内;但此处添加 port 只是为了让 RunLoop 不至于退出,并没有用于实际的发送消息。
- (void)start {
[self.lock lock];
if ([self isCancelled]) {
[self performSelector:@selector(cancelConnection) onThread:[[self class] networkRequestThread] withObject:nil waitUntilDone:NO modes:[self.runLoopModes allObjects]];
} else if ([self isReady]) {
self.state = AFOperationExecutingState;
[self performSelector:@selector(operationDidStart) onThread:[[self class] networkRequestThread] withObject:nil waitUntilDone:NO modes:[self.runLoopModes allObjects]];
}
[self.lock unlock];
}
当需要这个后台线程执行任务时,AFNetworking 通过调用 [NSObject performSelector:onThread:..] 将这个任务扔到了后台线程的 RunLoop 中。
说一下你对架构的理解? 技术架构如何搭建?
对于iOS架构的认识过程
iOS 从0到1搭建高可用App框架
MVVM
总结:在MVVM的框架下视图和模型是不能直接通信的。它们通过
ViewModel来通信,ViewModel通常要实现一个observer观察者,当数据发
生变化,ViewModel能够监听到数据的这种变化,然后通知到对应的视图做
自动更新,而当用户操作视图,ViewModel也能监听到视图的变化,然后通
知数据做改动,这实际上就实现了数据的双向绑定。并且MVVM中的View 和
ViewModel可以互相通信。