Deep Reinforcement Learning强化学习是一种探索式的学习方法,通过不断 “试错”来得到改进。不同于监督学习的地方是,强化学习本身没有 Label,每做出一个Action之后它无法得到明确的反馈,而监督学习每一步都能与真实Label进行对比。
它有四个要素:Agent,Environment,Actions,Rewards。
对象(Agent):也就是我们的智能主题,比如 AlphaGo。
环境(Environment):Agent 所处的场景。比如下围棋的棋盘,以及其所对应的状态(State)。Agent 需要从 Environment 感知来获取反馈。
动作(Actions):在每个State下可以采取什么行动,针对每一个 Action 分析其影响。
奖励(Rewards):执行 Action 之后,得到的奖励或惩罚,Reward 是通过对环境的观察得到。
通过强化学习,我们得到的输出就是:Next Action。其数学实质是一个马尔可夫决策过程。
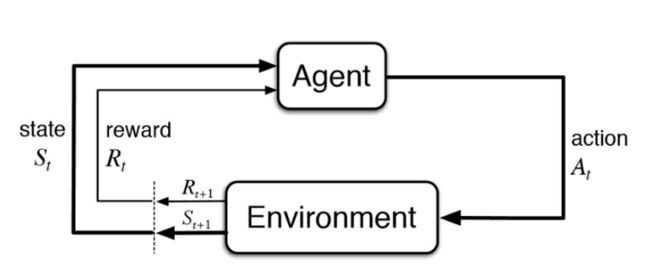
要解决的问题是:让agent学习在一个环境中的做出怎样的行为(action)可获得最大的奖励值总和(reward)。这个奖励值一般与agent定义的任务目标关联。
agent需要的主要学习内容:第一是行为策略(action policy), 第二是规划(planning)。其中,行为策略的学习目标是最优策略, 也就是使用这样的策略,可以让agent在特定环境中的行为获得最大的奖励值,从而实现其任务目标。
行为(action)可以简单分为:
- 连续值:如赛车游戏中的方向盘角度、油门、刹车控制信号,机器人的关节伺服电机控制信号。
- 离散值:如围棋、贪吃蛇游戏。Alpha Go就是一个典型的离散行为agent。
On-policy & Off-policy:
On-Policy Temporal Difference methods learn the value of the policy that is used to make decisions. The value functions are updated using results from executing actions determined by some policy. These policies are usually "soft" and non-deterministic. The meaning of "soft" in this sense, is that it ensures there is always an element of exploration to the policy. The policy is not so strict that it always chooses the action that gives the most reward. Three common policies are used, -soft, -greedy and softmax. .
Off-Policy methods can learn different policies for behaviour and estimation. Again, the behaviour policy is usually "soft" so there is sufficient exploration going on. Off-policy algorithms can update the estimated value functions using hypothetical actions, those which have not actually been tried. This is in contrast to on-policy methods which update value functions based strictly on experience. What this means is off-policy algorithms can separate exploration from control, and on-policy algorithms cannot. In other words, an agent trained using an off-policy method may end up learning tactics that it did not necessarily exhibit during the learning phase.
Q Learning:
它属于Off-policy。
Q Learning选择Q(S,A)用了greedy方法,而计算A(S',A')时用的是max方法,而真正选择的时候又不一定会选择max的行动。
Sarsa:
名字根据Q(s, a, r, s', a')而来。它类似Q Learning但是它有两次Action选择,下一步的Action是基于确定original action的policy得到的。它属于On-policy。

Sarsa Lambda:
[图片上传失败...(image-51f3bd-1555074641848)]
Deep - Q - Network (DQN):
DQN基于Q Learning。在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实。
Experience Replay:
- store all game experiences during the episode inside a "replay memory"
then during training we will take random mini-batches of this memory.
Double DQN:
DQN基于Q Learning,其中Qmax会导致Q现实的overestimate。在实际问题中,如果输出你的 DQN 的 Q 值可能会发现Q 值都超级大,这就是出现了overestimate。DQN的神经网络可以看作一个最新的神经网络+老神经网络,它们有相同的结构但内部的参数更新有时差。
Q现实是这样的:
因为神经网络预测Qmax有误差,每次都是向着最大误差的Q现实改进神经网络,就是因为合格Qmax导致overestimate,所以Double DQN的想法就是引入另一个神经网络来打消最大的误差影响。
所以我们用Q估计的神经网络估计Q现实中的Qmax(s',a')的最大动作值,然后用这个被Q估计估计出来的动作来选择Q现实中的Q(s')。
两个神经网络:Q_eval(Q估计),Q_next(Q现实)
把原来的
Q_next=max(Q_next(s', a_all))更新到Double DQN中的Q_next = Q_next(s', argmax(Q_eval(s', a_all)))。也就是
从TensorBoard看Double DQN和Natural DQN的图可以看到,它们的结构是一模一样的,但在计算 q_target 时,方法是不同的。
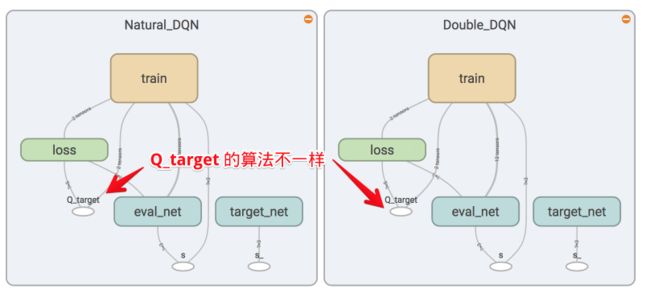
另外还需要记录选择动作时的Q值。
Prioritized Experience Replay:
按照memory样本优先级进行抽样,更有效找到需要学习的样本。
优先级的评定可以使用TD-error,也就是Q现实-Q估计,如果TD-error越大,代表预测精度还有很多上升空间,优先级p越高。
如果每次抽样都要针对p对所有样本排序这样会非常消耗计算能力,所以我们使用一种叫SumTree的方法。
SumTree时一种树形结构,每片树叶存储每个样本的优先级p,每个树枝节点只有两个分叉,节点的值是两个分叉的和,SumTree的根节点是所有p的和。
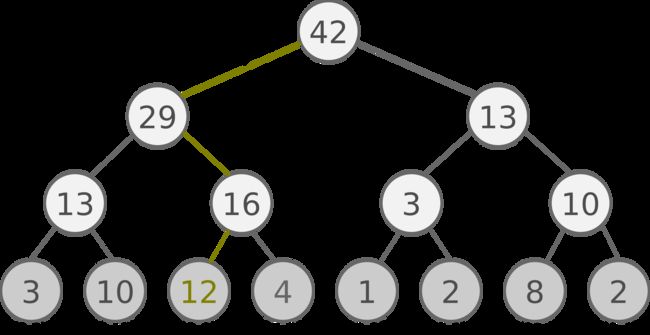
抽样时,我们将p的总和除以batch size,(n=sum(p)/batch_size)。
现在我们假设sum(p)=42,我们抽6个样本,这时区间拥有的 priority 可能是这样:
[0-7], [7-14], [14-21], [21-28], [28-35], [35-42]
在每个区间里随机选取一个数,比如在 [21-28] 里选到了24,就按照这个 24 从最顶上的42开始向下搜索。首先看到最顶上 42 下面有两个 child nodes,拿着手中的24对比左边的 child 29,如果左边的 child 比自己手中的值大,那我们就走左边这条路,接着再对比 29 下面的左边那个点 13,这时手中的 24 比 13 大,那我们就走右边的路,并且将手中的值根据 13 修改一下,变成 24-13 = 11。接着拿着 11 和 13 左下角的 12 比,结果 12 比 11 大,那我们就选 12 当做这次选到的 priority,并且也选择 12 对应的数据。
使用TensorBoard我们会发现DQN with Prioritized replay多了一个 ISWeights (Importance-Sampling Weights),用来恢复被 Prioritized replay 打乱的抽样概率分布。
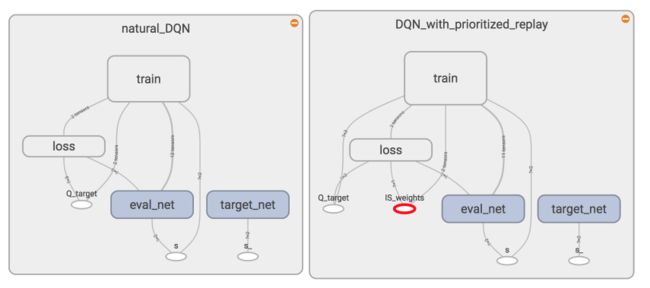
Prioritized replay可以高效利用不常拿到的奖励并好好学习它们,所以 Prioritized replay 会更快结束每个 episode,很快到达目标。
Dueling DQN:
将每个动作的 Q 拆分成了 state 的 Value加上每个动作的Advantage。
DQN 直接输出每个动作的 Q值,而 Dueling DQN每个动作的 Q值由下式确定:
Policy Gradient:
强化学习是一种通过奖惩来学习正确行为的机制。学习高价值行为的有Q Learning和DQN,也有不通过分析奖励值直接输出的Policy Gradient,这样的好处是可以在连续区间挑选动作,而基于值的Q Learning如果在无穷多的动作中计算价值再选择行为会消耗太大。
Policy Gradient不输出action的value,而直接输出具体的action,跳过了value这个阶段。
输出的action可以是连续的值,之前那些value-based的方法输出不连续的值,然后选值最大的action,而Policy Gradient可以在连续分布上选取action。
Policy Gradient是一种基于整条回合数据的更新,也叫Reinforce方法。
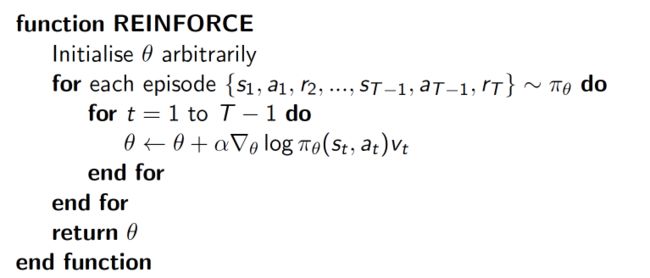
delta(log(Policy(s,a))*V) 表示在 状态 s 对所选动作 a 的吃惊度。如果 Policy(s,a) 概率越小,反向的 log(Policy(s,a)) (即 -log(P)) 反而越大。如果在 Policy(s,a) 很小的情况下,
拿到了一个 大的 R,也就是 大的 V,那 -delta(log(Policy(s, a))*V) 就更大,表示更吃惊。比如选了一个不常选的动作,发现它能得到了一个好的 reward,那么对这次的参数进行一个大幅修改,这就是吃惊度的物理意义。
选行为的时候不是根据Q value而是根据概率。生成action的过程,本质上是一个随机过程。最后学习到的策略,也是一个随机策略(stochastic policy)。
Actor Critic:
结合值和概率的一种算法。
Actor依据Policy Gradient基于概率选行为,Critic依据Q Learning等以值为基础的学习方法。
Critic基于Actor的行为评判行为的得分,Actor根据Critic的评分修改选行为的概率。
Policy Gradient属于回合更新,这样降低了学习效率。Critic学习奖惩机制,使得Actor每一步都能更新,而不是Policy Gradient等到回合结束菜更新。
Actor Critic涉及两个神经网络,而且每次都在连续状态中更新参数,每次参数更新前后都有相关性,导致神经网络只能片面看待问题,甚至学不到东西,于是Google DeepMind改进了这个方法。
Deterministic Policy Gradient (DPG):
确定性的行为策略,每一步的行为通过函数μ直接获得确定的值,不再是一个需要采样的随机策略。
因为PG学到随机策略后每一步行为都对最优策略概率分布进行采样才能获得action具体值,而action通常是高维向量,在高维空间频繁采样影响计算能力。
Deep Deterministic Policy Gradient (DDPG):
Actor-Critic + DQN = Deep Deterministic Policy Gradient
Deterministic 就改变了输出动作的过程,在连续动作上输出一个动作值。
DDPG是针对连续行为的策略学习方法。在RL领域,DDPG主要从:PG -> DPG -> DDPG 发展而来。
Code:
实现强化学习的代码主要分为三个部分:
- 环境脚本 (env.py)
- 强化学习脚本 (rl.py)
- 主循环脚本 (main.py)
根据不同的学习方法,每个环节有一些基本的function和变量:
- rl.py
- rl.choose_action(s)
- rl.store_transition(s, a, r, s_)
- rl.learn()
- check_state_exist(self, state)
- rl.memory_full
- env.py
- env.reset()
- env.render()
- env.step(a)
- env.state_dim
- env.action_dim
- env.action_bound
框架大致如下:
# main.py
# 导入环境和学习方法
from env import Env
from rl import RL
# 设置全局变量
MAX_EPISODES = 500
MAX_EP_STEPS = 200
# 设置环境
env = Env()
s_dim = env.state_dim
a_dim = env.action_dim
a_bound = env.action_bound
# 设置学习方法
rl = RL(a_dim, s_dim, a_bound)
# 开始训练
for i in range(MAX_EPISODES):
s = env.reset() # 初始化回合设置
for j in range(MAX_EP_STEPS):
env.render() # 环境的渲染
a = rl.choose_action(s) # RL选择动作
s_, r, done = env.step(a) # 在环境中进行动作
# 存放记忆库
rl.store_transition(s, a, r, s_)
if rl.memory_full:
rl.learn() # 记忆库满了, 开始学习
s = s_ # 变为下一回合
# env.py
class Env(object):
def __init__(self):
pass
def step(self, action):
pass
def reset(self):
pass
def render(self):
pass
# rl.py
class RL(object):
def __init__(self, a_dim, s_dim, a_bound,):
pass
def choose_action(self, s):
pass
def learn(self):
pass
def store_transition(self, s, a, r, s_):
pass
Reference:
- A Painless Q-Learning Tutorial
- Deep Reinforcement Learning
- Reinforcement Learning
- Deep Q Learning