一、平台架构
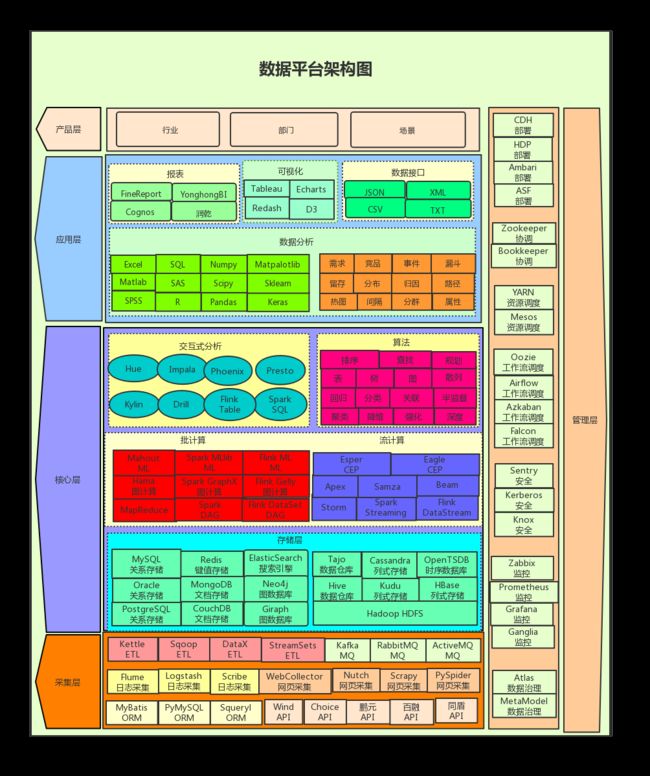
1.1 接入层
1.1.1 设备采集(IoT)
数据采集(DAQ),是指从传感器和其它待测设备等模拟和数字被测单元中自动采集非电量或者电量信号,送到上位机中进行分析,处理。数据采集系统是结合基于计算机或者其他专用测试平台的测量软硬件产品来实现灵活的、用户自定义的测量系统。
1.1.2 网页采集(Web)
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
1.1.3 日志采集(Log)
日志采集,是将服务器中的应用程序产生的各类日志数据,收集起来并送到指定的地方去,例如HDFS。
1.1.4 应用采集(ORM)
应用采集,是指利用JDBC、或ORM框架,将应用程序在内存中的数据,持久化到数据库或者磁盘。
1.1.5 数据接入(API)
数据接入,是通过第三方公司开放的数据接口,把数据保存到本地存储。
1.1.6 数据集成(ETL)
数据集成、或数据清洗(ETL),是指从其他异构或同构数据库,将数据抽取到数据仓库。
1.1.7 数据分发(MQ)
数据分发,是指通过消息中间件,把数据转发到其他数据系统。
1.2 核心层
1.2.1 数据存储(Storage)
数据存储对象包括数据流在加工过程中产生的临时文件或加工过程中需要查找的信息。数据以某种格式记录在计算机内部或外部存储介质上
1.2.2 数据计算(Computing)
数据计算是对数据依某种模式而建立起来的关系进行处理的过程。
1.2.3 数据算法(Algorithms)
数据挖掘算法是根据数据创建数据挖掘模型的一组试探法和计算。 为了创建模型,算法将首先分析您提供的数据,并查找特定类型的模式和趋势。
1.3 管理层
1.3.1 部署(Deployment)
统一的大数据平台部署工具
1.3.2 协调(Coordination)
分布式协调技术 主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的后果。
1.3.3 调度(Sheduler)
资源调度、工作流调度
1.3.4 授权(Authorization)
用户、权限、角色管理
1.3.5 监控(Monitor)
集群状态监控
1.3.6 数据治理(Governance)
数据治理是指从使用零散数据变为使用统一主数据、从具有很少或没有组织和流程治理到企业范围内的综合数据治理、从尝试处理主数据混乱状况到主数据井井有条的一个过程。
1.4 应用层
1.4.1 数据分析(Data Analysis,DA)
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
1.4.2 商业智能(Business Intelligence,BI)
商业智能(Business Intelligence,简称:BI),又称商业智慧或商务智能,指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
1.4.3 数据可视化(Data Visualization,DV)
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
1.4.4 数据接口(RESTful API)
数据导出、供给第三方使用的数据接口
1.5 产品层
1.5.1 行业产品
电商、互金、企业服务、零售、文娱、教育、投资、证券、银行
1.5.2 部门产品
产品、运营、营销、运维、风控、广告、画像、决策、交易
1.5.3 场景产品
ELK、推荐、广告、风控、反欺诈、决策、预测、识别
二、技术架构
2.1 数据采集

2.1.1 设备采集(IoT)
- 数据采集仪
- AstroNova
- Measurement Computing
- NI
- 熠新科技
- 腾晟桥康科技
- 电信探针
- RFID
- IoT
2.1.2 网页采集(Web)
2.1.2.1 Java 爬虫
- Apache Nutch
Open Source Web Search Software
开源网络搜索软件
Apache Nutch is a well matured, production ready Web crawler.
Apache Nutch是一个成熟的、可用于生产的Web爬虫程序。- Crawler4j
- WebMagic
- WebCollector
WebCollector 是一个无须配置、便于二次开发的 JAVA 爬虫框架(内核),提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。- Heritrix
- Spiderman
- SeimiCrawler
- Java Selenium
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
2.1.2.2 Python 爬虫
- Scrapy
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。- Crawley
Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。- Portia
Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。- PySpider
pyspider是一款国人编写、开源的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。- Newspaper
Newspaper可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。作者从requests库的简洁与强大得到灵感,使用python开发的可用于提取文章内容的程序。
支持10多种语言并且所有的都是unicode编码。- Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。- Grab
Grab是一个用于构建Web刮板的Python框架。借助Grab,您可以构建各种复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网络请求和处理接收到的内容,例如与HTML文档的DOM树进行交互。- Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。- Python Selenium
Selenium 是自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果在这些浏览器里面安装一个 Selenium 的插件,可以方便地实现Web界面的测试. Selenium 支持浏览器驱动。Selenium支持多种语言开发,比如 Java,C,Ruby等等,PhantomJS 用来渲染解析JS,Selenium 用来驱动以及与 Python 的对接,Python 进行后期的处理。
2.1.3 日志收集(Log)
- Apache Flume
A reliable service for efficiently collecting,aggregating, and moving larrge amounts of log data
用于有效收集、聚合和移动大量日志数据的可靠服务
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
Apache Flume是一种分布式、可靠且可用的服务,用于有效地收集、聚合和移动大量日志数据。- ELK
"ELK" is the acronym for three open source projects: Elasticsearch, Logstash, and Kibana. Elasticsearch is a search and analytics engine. Logstash is a server‑side data processing pipeline that ingests data from multiple sources simultaneously, transforms it, and then sends it to a "stash" like Elasticsearch. Kibana lets users visualize data with charts and graphs in Elasticsearch.
“ELK”是三个开源项目的缩写:Elasticsearch、Logstash和Kibana。Elasticsearch是一个搜索和分析引擎。Logstash是一个服务器端数据处理管道,它同时从多个源接收数据,转换数据,然后将其发送到Elasticsearch之类的“隐藏”。Kibana让用户可以用图表和图形在Elasticsearch中可视化数据。- ElasticSearch
Elasticsearch is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected.
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。- Logstash
Collect, Parse, Transform Logs | Elastic
收集、解析、转换日志
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite “stash.” (Ours is Elasticsearch, naturally.)
Logstash是一个开放源码的服务器端数据处理管道,它可以同时从多个数据源接收数据,对其进行转换,然后将其发送到您最喜欢的“stash”。(当然,我们是弹性搜索。)- Kibana
探索,可视化,发现数据
Kibana lets you visualize your Elasticsearch data and navigate the Elastic Stack, so you can do anything from learning why you're getting paged at 2:00 a.m. to understanding the impact rain might have on your quarterly numbers.
Kibana允许您可视化您的Elasticsearch数据,并在Elastic堆栈中导航,因此您可以做任何事情,从了解为什么您在凌晨2点被呼叫到了解降雨可能对您的季度数据产生的影响。- Apache Chukwa
- Splunk
Splunk 是机器数据的引擎。使用 Splunk 可收集、索引和利用所有应用程序、服务器和设备生成的快速移动型计算机数据 。 使用 Splunking 处理计算机数据,可让您在几分钟内解决问题和调查安全事件。- Scribe
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,scribe会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe会将转存的日志重新传输给中央存储系统。- Filebeat
- Fluentd
2.1.4 应用采集(ORM)
2.1.4.1 Java
- JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。- MyBatis
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。- Hibernate
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。- Structs
Struts2是一个基于MVC设计模式的Web应用框架,它本质上相当于一个servlet,在MVC设计模式中,Struts2作为控制器(Controller)来建立模型与视图的数据交互。- Spring Boot
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。- Spring Data
Spring Data是一个用于简化数据库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷- Spark SQL
Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。它提供了一个称为DataFrame的编程抽象,并且可以充当分布式SQL查询引擎。
2.1.4.2 Python
- PyMySQL
- SQLAlchemy
- JayDeBeApi
- PySpark
2.1.4.3 Scala
- JDBC
- Squeryl
Squeryl是一种强类型的声明性SQL,类似于DSL,用于从Scala语言中操作数据库对象- slick
2.1.5 数据接口(API)
2.1.5.1 风控
- 同盾
- 百融
- 鹏元
- 乐融
- 前海
- 聚信立
- 天眼查
2.1.5.2 量化
- Pandas
- Wind
- Choice
- JQData
- 聚合
- 量亿
2.1.6 数据集成(ETL)
- Kettle
Kettle是一款国外开源的ETL工具,纯java编写,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。- Apache Sqoop
Bulk Data Transer for Apache Hadoop and Structured Datastores
用于Apache Hadoop和结构化数据存储的批量数据转换器
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Apache Sqoop是一个工具,用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效地传输大量数据。- DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。- StreamSets
StreamSets is a data integration engine for flowing data from myriad batch and streaming sources to your modern analytics platforms.The industry's first data operations platform for full life-cycle management of data in motion.
streamset是一个数据集成引擎,用于将大量批处理和流数据流到您的现代分析平台。业界首个全生命周期动态数据管理的数据运营平台。- Canal
Canal is a high performance data synchronization system based on MySQL binary log. Canal is widely used in Alibaba group to provide reliable low latency incremental data pipeline.
基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql- Informatica
Informatica(纳斯达克代码:INFA)是全球领先的独立企业数据集成软件提供商。- Datastage
IBM® InfoSphere™ Information Server 是一种数据集成软件平台,能够帮助企业从散布在各个系统中的复杂异构信息获得更多价值。
2.1.7 数据解析(Parser)
2.1.7.1 解析语言
- Java
- Python
- Scala
- PHP
- Go
2.1.7.2 数据格式
- text
- csv
- jpg
- html
- xml
- json
- yaml
- SequenceFile
- Avro
- parquet
- Orc
2.1.8 数据分发(MQ)
- Apache Kafka
Distributed publish-subscribe messaging system
分布式发布-订阅消息系统
Apache Kafka is a distributed streaming platform.
Apache Kafka是一个分布式流媒体平台。- Apache ActiveMQ
Distributed Messaging System
分布式消息队列
Apache ActiveMQ is the most popular open source, multi-protocol, Java-based messaging server.
Apache ActiveMQ是最流行的开源、多协议、基于java的消息服务器。- Apache Pulsar
highly scalable,low latency messaging platform running on commodity hardware
在普通硬件上运行的高度可伸缩、低延迟的消息传递平台
Apache Pulsar is an open-source distributed pub-sub messaging system originally created at Yahoo and now part of the Apache Software Foundation
Apache Pulsar是一个开源的分布式发布-订阅消息系统,最初由Yahoo创建,现在是Apache软件基金会的一部分- Apache RocketMQ
a fast,low latency,reliable,scalable,distributeed,easy to use message-oriented middleware,especially for processing large amounts of streaming data.
一种快速、低延迟、可靠、可伸缩、分布式、易于使用的面向消息的中间件,尤其适用于处理大量流数据。
Apache RocketMQ is an open source distributed messaging and streaming data platform.
Apache RocketMQ是一个开源的分布式消息传递和流数据平台。- RabbitMQ
RabbitMQ is the most widely deployed open source message broker.
RabbitMQ是部署最广泛的开源消息代理。- Apache Camel
Spring based Integration Framework which implements the Enterprise Integration Patterns
基于Spring的集成框架,实现企业集成模式
Apache Camel is a powerful open source integration framework based on known Enterprise Integration Patterns with powerful bean integration.
Apache Camel是一个强大的开源集成框架,它基于已知的企业集成模式和强大的bean集成。
2.2 数据存储
2.2.1 存储
2.2.1.1 接口协议
- 概念
RAID(Redundant Arrays of Independent Drives,磁盘阵列)
LVM(Logical Volume Manager,逻辑卷管理)
- 接口协议
- 低端存储
IDE(Integrated Drive Electronics,,电子集成驱动器)
PATA(Parallel Advanced Technology Attachment,并行高级技术附件)
SATA(Serial Advanced Technology Attachment,串行高级技术附件)- 中端存储
SCSI(Small Computer System Interface,小型计算机系统接口)- 高端存储
SAS(Serial Attached SCSI,串行小型计算机系统接口)
NVMe (Non-Volatile Memory express,非易失性内存主机控制器接口规范)
SSD(Solid State Drive,固态驱动器)
FC(Fibre Channel,光纤通道)
iSCSI(Internet Small Computer System Interface,互联网小型计算机系统接口)
- 性能指标
IOPS(Input/Output Operations Per Second,每秒读写操作次数)
SR(Sequential Read,顺序读)
SATA Jobs: 1 (f=1): [R] [16.4% done] [124.1M/0K /s] [31.3K/0 iops] [eta 00m:51s]
SAS Jobs: 1 (f=1): [R] [16.4% done] [190M/0K /s] [41.3K/0 iops] [eta 00m:51s]
SSD Jobs: 1 (f=1): [R] [100.0% done] [404M/0K /s] [103K /0 iops] [eta 00m:00s]
RR(Random Read,随机读)
SATA Jobs: 1 (f=1): [r] [41.0% done] [466K/0K /s] [114 /0 iops] [eta 00m:36s]
SAS Jobs: 1 (f=1): [r] [41.0% done] [1784K/0K /s] [456 /0 iops] [eta 00m:36s]
SSD Jobs: 1 (f=1): [R] [100.0% done] [505M/0K /s] [129K /0 iops] [eta 00m:00s]
SW(Sequential Write,顺序写)
SATA Jobs: 1 (f=1): [W] [21.3% done] [0K/124.9M /s] [0 /31.3K iops] [eta 00m:48s]
SAS Jobs: 1 (f=1): [W] [21.3% done] [0K/190M /s] [0 /36.3K iops] [eta 00m:48s]
SSD Jobs: 1 (f=1): [W] [100.0% done] [0K/592M /s] [0 /152K iops] [eta 00m:00s]
RW(Random Write,随机写)
SATA Jobs: 1 (f=1): [w] [100.0% done] [0K/548K /s] [0 /134 iops] [eta 00m:00s]
SAS Jobs: 1 (f=1): [w] [100.0% done] [0K/2000K /s] [0 /512 iops] [eta 00m:00s]
SSD Jobs: 1 (f=1): [W] [100.0% done] [0K/549M /s] [0 /140K iops] [eta 00m:00s]
2.2.1.2 文件系统
- 本地文件系统
Windows FS
FAT(File Allocation Table,文件配置表)
NTFS(New Technology File System,新技术文件系统)
Linux FS
EXT(Extended File System,延申文件系统)
XFS(eXtensible File System,可扩展文件系统)- 网络文件系统
NFS(Network File System,网络文件系统)
CIFS(Common Internet File System,通用互联网文件系统)- 分布式文件系统
Hadoop HDFS
CephFS
Amazon EFS
GlusterFS
2.2.1.3 企业存储
- 低端存储(X86 PC Server 双控制器)
IBM DS4800/DS5000
EMC Clariion CX/CX3/CX4
HP MSA2000
NetAPP FAS2050/FAS3050/FAS6000/FAS6070
HDS AMS2000
Infortrend ESDS3000(国产)
- 中端存储
HP EVA4000/EVA6000/EVA8000
Infortrend ESVA
- 高端存储
富士通ETERNUS DX8000(X86 PC Server 多控制器)
IBM DS8000(小型机)
HDS USP1100(大型机)
EMC Clariion CX700(大型机)
EMC Symmetrix DMX3/DMX4(大型机)
- 集群存储
- 块集群存储
EMC Symmetrix V-MAX
IBM XIV
3PAR INSERV-T800- NAS集群存储
HP IBRIX
Panasas ActiveStor
2.2.1.4 存储分类
- 集中式存储
- DAS(Direct Attached Storage,直连存储)
- NAS(Network Attached Storage,网络附加存储)
NetApp Filter
BlueArc Titan
Infortrend EonNAS3000- SAN(Storage Area Network,存储区域网络)
Dell Equalogic
HP P4000
Infortrend ESVA
EMC Symmtrix DMX
HDS USP
- 分布式存储
- DBS(Distributed Block Storage,分布式块存储)
OpenStack Cinder
Ceph RBD
Amazon EBS
TFS
GlusterFS- DFS(Distributed File Storage,分布式文件存储)
Hadoop HDFS- Apache Hadoop
Distributed computing platform
分布式计算平台
Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Apache Hadoop软件库是一个框架,它允许使用简单的编程模型跨计算机集群分布式处理大型数据集。它被设计成从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。
CephFS
Amazon EFS
GlusterFS
GPFS
MooseFS
iRODS
Lustre- DOS(Distributed Object Storage,分布式对象存储)
OpenStack Swift
Ceph RADOS
Amazon S3
GlusterFS
2.2.2 关系(Relational,R)
- Oracle
Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。到目前仍在数据库市场上占有主要份额。 劳伦斯·埃里森和他的朋友,之前的同事Bob Miner和Ed Oates在1977年创建了软件开发实验室咨询公司。SDL开发了Oracle软件最初版本。- MySQL
MySQL原本是一个开放源代码的关系数据库管理系统,原开发者为瑞典的MySQL AB公司,该公司于2008年被Sun公司收购。2009年,甲骨文公司收购Sun公司,MySQL成为Oracle旗下产品。- SQL Server
Microsoft SQL Server是由美国微软公司所推出的关系数据库解决方案,最新的版本是SQL Server 2017,已在美国时间2017年10月2日发布。 数据库的内置语言原本是采用美国标准局和国际标准组织所定义的SQL语言,但是微软公司对它进行了部分扩充而成为作业用SQL- PostgreSQL
PostgreSQL是自由的对象-关系型数据库服务器,在灵活的BSD许可证下发行。它在其他开放源代码数据库系统,和专有系统之外,为用户又提供了一种选择。- DB2
IBM DB2企业服务器版本,是美国IBM公司发展的一套关系型数据库管理系统。它主要的运行环境为UNIX、Linux、IBM i、Z/OS,以及Windows服务器版本。DB2也提供性能强大的各称IBM InfoSphere Warehouse版本。- MariaDB
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可。开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险。 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。- Apache Hive
Data warehouse infrastructure using the Apache Hadoop Database
使用Apache Hadoop数据库的数据仓库基础设施
Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Apache Hive数据仓库软件支持使用SQL读取、写入和管理驻留在分布式存储中的大型数据集。结构可以投影到已经存储的数据上。提供了一个命令行工具和JDBC驱动程序来将用户连接到Hive。- Apache Tajo
Big data warehouse system on Apache Hadoop
Apache Hadoop上的大数据仓库系统
Apache Tajo is a robust big data relational and distributed data warehouse system for Apache Hadoop. Tajo is designed for low-latency and scalable ad-hoc queries, online aggregation, and ETL (extract-transform-load process) on large-data sets stored on HDFS (Hadoop Distributed File System) and other data sources. By supporting SQL standards and leveraging advanced database techniques, Tajo allows direct control of distributed execution and data flow across a variety of query evaluation strategies and optimization opportunities.
Apache Tajo是Apache Hadoop的一个健壮的大数据关系分布式数据仓库系统。Tajo是为存储在HDFS (Hadoop分布式文件系统)和其他数据源上的大数据集上的低延迟和可伸缩的特别查询、在线聚合和ETL (extract-transform-load process)而设计的。通过支持SQL标准和利用先进的数据库技术,Tajo允许直接控制跨各种查询评估策略和优化机会的分布式执行和数据流。
2.2.3 键值(Key-value,KV)
- Redis
Redis(Remote Dictionary Server)是一个使用ANSI C编写的开源(BSD许可)、支持网络、基于内存、可选持久性、键值对存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。- memcached
memcached是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用。这是一套开放源代码软件,以BSD license授权发布。 memcached缺乏认证以及安全管制,这代表应该将memcached服务器放置在防火墙后。- Hazelcast
Hazelcast IMDG是一个基于Java的开源内存数据网格。它也是开发产品的公司的名称。 Hazelcast公司由风险投资公司资助,总部位于帕洛阿尔托。 在Hazelcast网格中,数据均匀分布在计算机集群的节点之间,允许水平扩展处理和可用存储。备份也分布在节点之间,以防止任何单个节点发生故障。- Ehcache
Ehcache是一种开源的、基于标准的缓存,可以提高性能、卸载数据库并简化可伸缩性。它是最广泛使用的基于java的缓存,因为它健壮、可靠、功能齐全,并与其他流行的库和框架集成。Ehcache可以从进程内缓存扩展到进程内/进程外部署和tb大小的缓存。
2.2.4 文档(Document,D)
- MongoDB
MongoDB是一个免费、开源、跨平台、面向文档的数据库。- Apache CouchDB
RESTful document database
RESTful 文档数据库
Apache CouchDB is a database that completely embraces the web. Store your data with JSON documents. Access your documents with your web browser, via HTTP. Query, combine, and transform your documents with JavaScript.
Apache CouchDB是一个完全拥抱web的数据库。它使用JSON文档存储数据,使用web浏览器通过HTTP访问文档,使用JavaScript查询、组合和转换文档。
Apache CouchDB是一个开源数据库,专注于易用性和成为"完全拥抱web的数据库"。它是一个使用JSON作为存储格式,JavaScript作为查询语言,MapReduce和HTTP作为API的NoSQL数据库。其中一个显著的功能就是多主复制。- Couchbase
Couchbase Server,最初称为Membase,是一个开源的,分布式多模型NoSQL面向文档的数据库软件包,针对交互式应用程序进行了优化。这些应用程序可以通过创建,存储,检索,聚合,操纵和呈现数据来为许多并发用户服务。
2.2.5 列(Column,C)
- Apache Cassandra
Highly scalable second-generation distributed database
高度可伸缩的第二代分布式数据库
Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance.
当您需要可伸缩性和高可用性而不影响性能时,Apache Cassandra数据库是正确的选择。- Apache HBase
Apache Hadoop Database
Apache Hadoop数据库
Apache HBase is the Hadoop database, a distributed, scalable, big data store.This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable.
Apache HBase是Hadoop数据库,一个分布式、可伸缩的大数据存储。这个项目的目标是在商品硬件集群上托管非常大的表(数十亿行X数百万列)。Apache HBase是一个基于谷歌Bigtable的开源、分布式、版本化的非关系数据库。- Apache Accumulo
Sorted,distributed key/value sotre
有序的键值存储
Apache Accumulo is a sorted, distributed key/value store that provides robust, scalable data storage and retrieval.
Apache Accumulo是一个有序的分布式键/值存储,提供健壮的、可伸缩的数据存储和检索。- Apache Avro
A serialization System
序列化系统
Apache Avro is a data serialization system.
Apache Avro是一个数据序列化系统。- Apache CarbonData
Indexed columnar data format for fast analytics on big data platform.
索引柱状数据格式,用于大数据平台上的快速分析。
Apache CarbonData is an indexed columnar data format for fast analytics on big data platform, e.g. Apache Hadoop, Apache Spark, etc.
Apache CarbonData是Apache Hadoop、Apache Spark等大数据平台上用于快速分析的索引柱状数据格式。- Apache Ignite
High-performance,integrated and distributed in-memory platform for computing and transacting on large-scale data sets in real time
高性能、集成和分布式内存平台,实时处理大规模数据集
Apache Ignite is a memory-centric distributed database, caching, and processing platform for transactional, analytical, and streaming workloads delivering in-memory speeds at petabyte scale.
Apache Ignite是一个以内存为中心的分布式数据库、缓存和处理平台,用于事务、分析和流工作负载,以pb级的速度交付内存速度。- Apache Kudu
A distributed columnar storage engine built for the Apache Hadoop ecosystem
为Apache Hadoop生态系统构建的分布式列存储引擎
Apache Kudu is a columnar storage manager developed for the Apache Hadoop platform. Kudu completes Hadoop's storage layer to enable fast analytics on fast data.
Apache Kudu是为Apache Hadoop平台开发的一个列存储管理器。Kudu完成Hadoop的存储层,支持对快速数据进行快速分析。- Apache ORC
the smallest,fastest columnar storage for Hadoop workloads
用于Hadoop工作负载的最小、最快的列存储
Apache ORC is the smallest, fastest columnar storage for Hadoop workloads.
Apache ORC是Hadoop工作负载中最小、最快的列存储。- Apache Parquet
columnar storagge format available to any project in the Apache Hadoop ecosystem
柱状存储格式适用于Apache Hadoop生态系统中的任何项目
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
Apache Parquet是Hadoop生态系统中任何项目都可以使用的柱状存储格式,无论选择哪种数据处理框架、数据模型或编程语言。
2.2.6 时序(Time Series,TS)
- InfluxDB
InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。- Graphite
Graphite 专注于两个最简单的任务: 作为一个便捷且Scalable的Network Service,以精度随时间递减的方式存储Metrics数据,并支持以丰富的函数获取它们,以图片或者JSON的格式。
石墨是一种企业级的监控工具,在廉价的硬件上运行良好。它最初是由克里斯·戴维斯(Chris Davis)于2006年在Orbitz设计并编写的,作为一个最终发展成为基本监控工具的副项目。2008年,Orbitz允许按照开源Apache 2.0许可协议发布石墨版本。从那以后,克里斯继续在石墨上工作,并将其部署到包括西尔斯在内的其他公司,在那里石墨是电子商务监控系统的支柱。如今许多大公司都在使用它。- RRDtool
RRDtool是一种开源的行业标准、高性能数据记录和时间序列数据绘图系统。RRDtool可以很容易地集成到shell脚本、perl、python、ruby、lua或tcl应用程序中。- OpenTSDB
OpenTSDB(Open time series data base),开放时间序列数据库。DB这个词很有误导性,其实并不是一个db,单独一个OpenTSDB无法存储任何数据,它只是一层数据读写的服务,更准确的说它只是建立在Hbase上的一层数据读写服务。- Prometheus
Prometheus是一个开源系统监测和警报工具包,最初是在SoundCloud开发的。自2012年成立以来,许多公司和组织都采用了Prometheus项目,该项目拥有一个非常活跃的开发者和用户社区。它现在是一个独立的开源项目,独立于任何公司进行维护。为了强调这一点,并阐明项目的治理结构,Prometheus在2016年加入了云计算基金会,成为继Kubernetes之后的第二个托管项目。- Druid
Druid是Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能。Druid的核心设计结合了来自OLAP/ analysis数据库、timeseries数据库和搜索系统的思想,创建了一个统一的操作分析系统。
2.2.7 图(Graph,G)
- Neo4j
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。- Apache Giraph
Apache Giraph是为高可伸缩性而构建的迭代图形处理系统。例如,Facebook目前使用它来分析用户和他们的联系形成的社交图。Giraph最初是与Pregel相对应的开源软件,是在谷歌开发的图形处理架构,并在2010年的一篇论文中进行了描述。这两个系统都受到Leslie Valiant引入的分布式计算批量同步并行模型的启发。Giraph除了基本的预凝胶模型之外还增加了一些特性,包括主计算、分片聚合器、面向边缘的输入、核外计算等等。随着世界范围内稳定的开发周期和不断增长的用户群体,Giraph是释放大规模结构化数据集潜力的自然选择。- JanusGraph
JanusGraph是一个分布式、可扩展、事务性的图形数据库,用于存储和查询包含分布在多机器集群中的数千亿顶点和边的图形。JanusGraph是一个事务性数据库,可以支持数千个并发用户实时执行复杂的图形遍历。- Dgraph
Dgraph是一个开源、可扩展、分布式、高可用性、快速的图形数据库,从底层设计到生产运行。- TigerGraph
TigerGraph是快速、可扩展的图数据库、图分析平台。TigerGraph代表了图数据库演进的下一个阶段,它是第一个能够在互联网规模数据上进行实时分析的系统。TigerGraph的原生并行图(NPG)的设计着眼于存储和计算,支持实时图更新并实现内置并行计算。TigerGraph的类SQL图查询语言(GSQL)为大数据的即时浏览和交互式分析提供支持。借助GSQL的表达能力和原生并行图的运行速度,您可以进行深度链接分析:揭示以往因其他系统性能问题或表达能力限制而无法获得的数据价值。- InfiniteGraph
InfiniteGraph是一个高度专业化的图形数据库。它的功能正在被迁移到ThingSpan。不过,客观性将继续支持授权用户,并将其推荐给希望在Spark环境之外使用graph analytics的Java开发人员。特定的特性,例如寻路,已经被合并到底层数据库-客观性/DB中。这将简化我们产品的开发、质量保证、维护和支持。
2.3 数据计算
2.3.1 计算概论
- 并行计算(Parallel Computing)
- 概念
并行计算,又称平行计算,和串行计算是相对的。并行计算同时使用多种计算资源解决计算问题,可以提高计算速度,及通过扩大问题求解规模,解决大型而复杂的计算问题。- 分类
时空分类
时间并行:流水线技术
空间并行:用多个处理器并发的执行计算。(重点)
算法分类
数据并行:将一个大任务化解成相同的各个子任务。(更容易实现)
任务并行- 硬件模型
- 指令模型(处理器)
串行机
单指令流单数据流(SISD)
并行机
单指令流多数据流(SIMD)
多指令流多数据流(MIMD)
并行向量处理机(PVP)
对称多处理机(SMP)
大规模并行处理机(MPP)
工作站机群(COW)
分布式共享存储处理机(DSM)- 访问模型(内存)
均匀访存模型(UMA)
非均匀访存模型(NUMA)
全高速缓存访存模型(COMA)
一致性高速缓存非均匀存储访问模型(CC-NUMA)
非远程存储访问模型(NORMA)- 计算模型
PRAM(Parallel Random Access Machine,随机存取并行机器)
BSP(Bulk Synchronous Parallel,整体同步并行计算)
LogP(Latency/overhead/gap/Processor)
C3
BDM(Block Distributed Model,块分布存储模型)
- 分布式计算(Distributed Computing)
分布式计算是一种计算方法,和集中式计算是相对的。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。- 网格计算(Grid Computing)
网格计算是分布式计算的一种,是一门计算机科学。它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终结果。- 高性能计算(High performance computing,HPC)
高性能计算是使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计 算资源操作)的计算系统和环境。- 边缘计算(Edge Computing)
边缘计算是指在靠近物或数据源头的一侧,采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务。- 云计算(Cloud Computing)
云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件、服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。
2.3.2 计算框架
2.3.2.1 批计算
2.3.2.1.1 MapReduce计算框架
- Apache Crunch
Simple and Efficient MapReduce Pipelines
简单而高效的MapReduce管道
Apache Crunch Java library provides a framework for writing, testing, and running MapReduce pipelines. Its goal is to make pipelines that are composed of many user-defined functions simple to write, easy to test, and efficient to run.
Apache Crunch Java库为编写、测试和运行MapReduce管道提供了一个框架。它的目标是使由许多用户定义函数组成的管道易于编写、易于测试和高效运行。
2.3.2.1.2 DAG计算框架
- Apache Spark
Fast and generral engine for large-scale data processing
用于大规模数据处理的快速通用引擎
Apache Spark is a unified analytics engine for large-scale data processing.Spark is a fast and general processing engine compatible with Hadoop data. It can run in Hadoop clusters through YARN or Spark's standalone mode, and it can process data in HDFS, HBase, Cassandra, Hive, and any Hadoop InputFormat. It is designed to perform both batch processing (similar to MapReduce) and new workloads like streaming, interactive queries, and machine learning.
Apache Spark是一个用于大规模数据处理的统一分析引擎。Spark是一个与Hadoop数据兼容的快速通用处理引擎。它可以通过YARN或Spark的独立模式在Hadoop集群中运行,并且可以处理HDFS、HBase、Cassandra、Hive和任何Hadoop InputFormat中的数据。它被设计用来执行批处理(类似于MapReduce)和新的工作负载,如流、交互式查询和机器学习。
Spark Core(非结构数据)
Spark SQL(结构化数据)
Spark Streaming(实时流计算)
Spark MLlib(机器学习)
Spark GraphX(图计算)- Apache Tez
High-performance and scalable distributed data processing framework.
高性能和可伸缩的分布式数据处理框架。
The Apache TEZ project is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop Apache Hadoop YARN.
Apache TEZ项目的目标是构建一个应用程序框架,该框架允许处理数据的任务的复杂的定向无周期图。它目前构建在Apache Hadoop YARN之上。- Apache TinkerPop
Apache TinkerPop is a graph computing framework for both graph databases (OLTP) and graph analytic systems (OLAP).
Apache TinkerPop是一个图形数据库(OLTP)和图形分析系统(OLAP)的图形计算框架。
Apache Trafodion
webscale SQL-on-Hadoop solution enabling transactional or operational workloads
支持事务或操作工作负载的webscale SQL-on-Hadoop解决方案
Apache Trafodion is a webscale SQL-on-Hadoop solution enabling transactional or operational workloads on Apache Hadoop.
Apache Trafodion是一个支持Apache Hadoop上事务或操作工作负载的webscale SQL-on-Hadoop解决方案。
2.3.2.1.3 图计算框架
- Apache Giraph
Iterative graph processing system built for high scalability
为高可伸缩性而构建的迭代图处理系统
Apache Giraph is an iterative graph processing system built for high scalability.
Apache Giraph是一个迭代的图形处理系统,用于高可伸缩性。- Apache Griffin
Apache Griffin is an open source Data Quality solution for Big Data, which supports both batch and streaming mode. It offers an unified process to measure your data quality from different perspectives, helping you build trusted data assets, therefore boost your confidence for your business.
Apache Griffin是一个面向大数据的开源数据质量解决方案,支持批处理和流媒体模式。它提供了一个统一的流程来从不同的角度度量数据质量,帮助您构建可信的数据资产,从而增强您对业务的信心。- Apache Hama
a Bulk Synchronous Parallel computing framework
批量同步并行(BSP)计算框架
Apache Hama is a framework for Big Data analytics which uses the Bulk Synchronous Parallel (BSP) computing model.
Apache Hama是一个大数据分析框架,它使用了批量同步并行(BSP)计算模型。
2.3.2.2 流计算
- Apache Flink
platform for scalable batch and stream data processing
可伸缩的批处理和流数据处理平台
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。
Flink DataSet(离线批计算)
Flink DataStream(实时流计算)
Flink Table(结构化数据)
Flink ML(机器学习)
Flink Gelly(图计算)- Apache Apex
Enterprise-grade unified stream and batch processing engine
企业级统一流、批处理引擎
Apache Apex is an enterprise grade native YARN big data-in-motion platform that unifies stream processing as well as batch processing.
Apache Apex是一个企业级的原生YARN大数据移动平台,它统一了流处理和批处理。- Apache Beam
Programming model,SDKs,and runners for defining and executing data processing pipelines
用于定义和执行数据处理管道的编程模型、sdk和运行程序
Apache Beam is an advanced unified programming model ,which implement batch and streaming data processing jobs that run on any execution engine.
Apache Beam是一个高级的统一编程模型,它实现了在任何执行引擎上运行的批处理和流数据处理作业。- Apache Samza
distributed stream processing framework
分布式流处理框架
Apache Samza is a distributed stream processing framework.Samza allows you to build stateful applications that process data in real-time from multiple sources including Apache Kafka.
Apache Samza是一个分布式流处理框架。Samza允许您构建实时处理来自多个数据源(包括Apache Kafka)的数据的有状态应用程序。- Apache Storm
Distributed,real-time computation system
分布式、实时计算系统
Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing.
Apache Storm是一个免费的开源分布式实时计算系统。Storm使可靠地处理无界数据流变得很容易,就像Hadoop处理批处理一样,它可以进行实时处理。
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Storm有很多用例:实时分析、在线机器学习、连续计算、分布式RPC、ETL等等。Storm速度很快:一个基准测试将其记录为每秒处理每个节点超过100万个元组。它是可伸缩的,容错,保证您的数据将被处理,并易于设置和操作。
Storm integrates with the queueing and database technologies you already use. A Storm topology consumes streams of data and processes those streams in arbitrarily complex ways, repartitioning the streams between each stage of the computation however needed.
Storm集成了您已经使用的队列和数据库技术。Storm拓扑使用数据流,并以任意复杂的方式处理这些数据流,根据需要在计算的每个阶段之间重新分区这些数据流。- Apache Calcite
Dynamic data management framework
动态数据管理框架
Apache Calcite is a dynamic data management framework.
Apache Calcite是一个动态数据管理框架。
2.3.2.3 交互式分析
- Apache Impala
a high-performance distributed SQL engine
高性能分布式SQL引擎
Apache Impala is a modern, open source, distributed SQL query engine for Apache Hadoop.
Apache Impala是一个用于Apache Hadoop的现代、开源、分布式SQL查询引擎。- Apache Kylin
Extreme OLAP Engine for Big Data
超级OLAP大数据引擎
Apache Kylin is an open source Distributed Analytics Engine designed to provide SQL interface and multi-dimensional analysis (OLAP) on Hadoop/Spark supporting extremely large datasets, original contributed from eBay Inc.
Apache Kylin是一个开源的分布式分析引擎,设计用于在Hadoop/Spark上提供SQL接口和多维分析(OLAP),支持非常大的数据集,最初由eBay Inc.提供。- Apache Drill
Schema-free SQL Query Engine for Apache Hadoop,NoSQL and Cloud Storage.
适用于Apache Hadoop、NoSQL和云存储的无模式SQL查询引擎。
Apache Drill is a Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage.
Apache Drill是一个用于Hadoop、NoSQL和云存储的无模式SQL查询引擎。- Apache Druid
Interactive Analytics at Scale
大规模交互分析
Apache Druid is designed for rapid, ad-hoc analytics on both real-time and historical data.
Apache Druid旨在对实时和历史数据进行快速、特别的分析。
Apache Druid (incubating) is a high performance real-time analytics database.
Apache Druid(孵化)是一个高性能的实时分析数据库。- Apache Fluo
Storage and incremental processing of large data sets
大型数据集的存储和增量处理
Apache Fluo is a distributed processing system that lets users make incremental updates to large data sets.Apache Fluo is built on Apache Accumulo.Large-scale Incremental Processing.
Apache Fluo是一个分布式处理系统,允许用户对大型数据集进行增量更新,它构建在Apache Accumulo之上,用于大规模的增量处理。- Apache Lens
Unified analytics platform
统一的分析平台
Apache Lens provides an Unified Analytics interface. Lens aims to cut the Data Analytics silos by providing a single view of data across multiple tiered data stores and optimal execution environment for the analytical query. It seamlessly integrates Hadoop with traditional data warehouses to appear like one.
Apache Lens提供了一个统一的分析界面。Lens的目标是通过为分析查询提供跨多层数据存储的数据视图和最佳执行环境,从而减少数据分析瓶颈。它无缝地将Hadoop与传统数据仓库集成在一起,看起来就像一个数据仓库。- Apache Lucene
Search engine library
搜索引擎库
Apache Lucene project develops open-source search software.
Apache Lucene项目开发开源搜索软件。- Apache Phoenix
High performance relational database layer over Apache HBase for low latency applications
基于Apache HBase的高性能关系数据库层,用于低延迟应用程序
Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the power of standard SQL and JDBC APIs with full ACID transaction capabilities and the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store.Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce.
Apache Phoenix将标准SQL和JDBC api的强大功能与完整的ACID事务功能结合起来,并利用HBase作为支持存储,支持NoSQL世界的延迟绑定、模式读取功能的灵活性,从而在Hadoop中为低延迟应用程序启用OLTP和操作分析。Apache Phoenix完全集成了其他Hadoop产品,如Spark、Hive、Pig、Flume和Map Reduce。- Apache Pig
Platform for analyzing large data sets
分析大型数据集的平台
Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
Apache Pig是一个分析大型数据集的平台,这些数据集由表示数据分析程序的高级语言和评估这些程序的基础设施组成。Pig程序的显著特性是,它们的结构能够进行大量的并行化,从而使它们能够处理非常大的数据集。- Apache VXQuery
A parallel XQuery processor
并行XQuery处理器
Apache VXQuery will be a standards compliant XML Query processor implemented in Java. The focus is on the evaluation of queries on large amounts of XML data. Specifically the goal is to evaluate queries on large collections of relatively small XML documents. To achieve this queries will be evaluated on a cluster of shared nothing machines.
Apache VXQuery将是一个用Java实现的符合标准的XML查询处理器。重点是评估对大量XML数据的查询。具体来说,目标是评估对相对较小的XML文档的大型集合的查询。为了实现这个查询,将在一个无共享机器集群上进行评估。- Apache Zeppelin
A web-based notebook that enables interactive data analytics
一个基于web的笔记本,支持交互式数据分析
Apache Zeppelin is a web-based notebook that enables data-driven,interactive data analytics and collaborative documents with SQL, Scala and more.
Apache Zeppelin是一个基于web的笔记本,它支持数据驱动、交互式数据分析和使用SQL、Scala等协作文档。- Sphinx
Open Source Search Engine
开源搜索引擎- Presto
Distributed SQL Query Engine for Big Data
分布式大数据SQL查询引擎
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto是一个开源分布式SQL查询引擎,用于对从gb到pb的各种大小的数据源运行交互式分析查询。
2.3.3 数据架构
2.3.3.1 Batch架构
概念:以ETL为核心,ETL+DW+BI
举例:Hadoop
2.3.3.2 Stream架构
概念:以Stream为核心,流式架构非常激进,直接拔掉了批处理,数据全程以流的形式处理,所以在数据接入端没有了ETL,转而替换为数据通道。
举例:Kafka+Storm
2.3.3.3 Lambda架构
概念:引擎层统一批处理、流处理。
举例:Kafka+Storm+Hadoop
2.3.3.4 Kappa架构
概念:以流处理为核心,使用Samza实现重复reprocessing来处理批数据,实现流和批处理的统一。
举例:Kafka+Samza
2.3.3.5 Unifield架构
概念:API层面统一批处理、流处理,统一的API再对接底层多个引擎。
举例:
批流融合API
Function API:Beam=(B)atch+Str(eam)
SQL API: Calcite
批流融合处理引擎
Spark Databricks
Flink Data Artisan
2.4 数据算法
2.4.1 算法
2.4.1.1 排序(Sort)
- 内部排序(Internal Sort)
- 插入排序
- 直接插入排序(Insertion Sort)
- 折半插入排序
- 希尔排序(Shell Sort)
- 选择排序
- 简单选择排序(Selection Sort)
- 堆排序(Heap Sort)
- 交换排序
- 冒泡排序(Bubble Sort)
- 快速排序(Quick Sort)
- 归并排序(Merge Sort)
- 计数排序(Counting Sort)
- 桶排序(Bucket Sort)
- 基数排序(Radix Sort)
- 外部排序(External Sort)
- 多路归并排序(Multiplex Merge Sorting)
2.4.1.2 查找(Search)
2.4.1.2.1 表(List)
- 顺序查找(Sequential Search)
- 二分查找(Binary Search)
- 插值查找(Interpolation Search)
- 斐波那契查找(Fibonacci Search)
- 分块查找/索引顺序查找(Blocking Search/Indexed Sequential Search)
2.4.1.2.2 树(Tree)
- 树表查找(Tree Search)
- 二叉排序树(Binary Search Tree,BST)
- 平衡查找树(Balanced Binary Search Tree)
- 平衡二叉树(Adelson-Velskii and Landis,AVL)
- 2-3树(2-3 tree)
- 红黑树(Red-black tree,RBT)
- 平衡多路查找树
- B树(B Tree)
- B+树(B+ Tree)
- 日志结构合并树(Log Structured Merge Tree,LSM)
- 哈夫曼树(Huffman Tree)
2.4.1.2.3 图(Graph)
- 深度优先遍历(Depth First Search,DFS)
- 广度优先遍历(Breadth First Search,BFS)
- A*寻址
- 最短路径(Shortest Path)
- Dijkstra
- Bellman-Ford
- Floyd-Warshall
- 最小生成树(Minimum Spanning Tree,MST)
- Prim
- Kruskal
- 图匹配(Graph Match)
- 匈牙利算法
- 强连通图(Strong Graph)
- Ford-Fulkerson
2.4.1.2.4 散列(Hash)
- 哈希查找(Hash Search)
2.4.2 数据结构
2.4.2.1 表(List)
- 线性表(List)
顺序存储
顺序表
链式存储
单链表
双链表
循环链表
静态链表
- 受限线性表
- 栈(Stack)
后进后出(Last In First Out,LIFO)
顺序存储
顺序栈
共享栈
链式存储
链栈
- 队列(Queue)
先进后出(First In First Out,FIFO)
顺序存储
顺序队列
循环队列
链式存储
链式队列
双端队列- 串(String)
- 线性表推广
- 数组(Array)
一维数组
多维数组
压缩矩阵
特殊矩阵- 广义表(Generalized List)
2.4.2.2 树(Tree)
- 一般树(General Tree)
森林(Forest)- 二叉树(Binary Tree)
- 二叉排序树(Binary Search Tree,BST)
平衡查找树(Balanced Binary Search Tree)- 平衡二叉树(Adelson-Velskii and Landis,AVL)
2-3树(2-3 tree,2-3)
红黑树(Red-black tree,RBT)- 平衡多路查找树
B树(B Tree,B)
B+树(B+ Tree,B+)
日志结构合并树(Log Structured Merge Tree,LSM)
哈夫曼树(Huffman Tree)
2.4.2.3 图(Graph)
- 概念
有向图(Directed Graph)
无向图(Undirected Graph)
有向无环图(Directed Acyclic Graph,DAG)- 存储
邻接矩阵法(Adjacency Matrix)
邻接表法(Adjacency List)
邻接多重表(Adjacency Multilist)
十字链表(Orthogonal List)- 遍历
深度优先遍历(Depth First Search,DFS)
广度优先遍历(Breadth First Search,BFS)- 应用
最小生成树(Minimum Spanning Tree,MST)
最短路径(Shortest Path)
Dijkstra算法
FLoyd算法
拓扑排序(Topological Sort)
有向无环图(Directed Acyclic Graph,DAG)
顶点活动网(Activity On Vertex Network,AOV)
关键路径(Critical Path)
顶点活动网(Activity On Vertex Network,AOV)
2.4.2.4 散列(Hash)
- 散列表(Hash Table)
- 散列函数
直接定址法
除留余数法
数字分析法
平方取中法
折叠法
- 冲突处理
开放定址法
线性探测法
平方探测法
再散列法
伪随机序列法
拉链法
- 哈希查找(Hash Search)
2.4.3 机器学习
2.4.3.1 监督(Supervised)
2.4.3.1.1 回归(Regression)
- OLS(Ordinary Least Square,最小二乘法)
- LR(Linear Regression,线性回归)
- LR(Logistic Regression,逻辑回归)
- GLR(Generalized Linear Regression,广义线性回归)
2.4.3.1.2 分类(Classification)
- SVM(Support Vector Machine,支持向量机)
- LDA、QDA(Linear and Quadratic Discriminant Analysis,线性和二次判别分析)
- DT(Decision Tree,决策树)
- ID3(Iterative Dichotomiser 3,迭代二叉树三代)
- C4.5
- CART(Classification and Regression Tree,分类与回归树)
- KNN(K-Nearest Neighbors,K最近邻)
贝叶斯方法(Bayes Method)
朴素贝叶斯(Naive Bayes,NB)
人工神经网络(Artificial Neural Network)
集成方法(Ensemble Method)
核近似(Kernel Approximation)
自适应增强(Adaboosting)
2.4.3.1.3 关联(Association)
- 先验(Apriori)
- FPT(Frequent Pattern Tree,频繁模式树)
2.4.3.2 无监督(Unsupervised)
2.4.3.2.1 聚类(Clustering)
- KM(K-Means,K均值聚类)
GMM(Gaussian Mixture Models,高斯混合模型)- EM(Expectation Maximization,最大期望)
谱聚类(Spectral Clustering)
流形学习(Manifold Learning)
层次聚类(Hierachical Clustering)
2.4.3.2.2 降维(Dimensionality Reduction)
- PCA(Principal Component Analysis,主成分分析)
LDA(Linear Discriminant Analysis,线性判别分析)
LLE(Locally Linear Embedding,局部线性嵌入)
2.4.3.3 半监督(Semi-supervised Learning)
- 生成模型(Generative Models)
图论推理(Graph Inference)
2.4.3.4 强化(Reinforcement Learning)
- MDP(Markov Decision Processes,马尔科夫决策过程)
TDL(Temporal Difference Learning,时序差分学习)
Q-Learning
SARSA
A-Learning
2.4.3.5 深度(Deep Learning)
- DBN(Deep Belief Network,深度信念网络)
- CNN(Convolutional Neural Network,卷积神经网络)
- RNN(Recurrent Neural Network,循环神经网络)
RNN(Recursive Neural Network,递归神经网络)
GAN(Generative Adversarial Network,生成对抗网络)
HTM(Hierarchical Temporal Memory,分层时间记忆)
RBM(Restricted Boltzmann Machine,受限玻尔兹曼机 )
- SAE(Stacked Auto-encoders,堆栈式自动编码器)
- Apache MADlib
Scalable,Big Data,SQL-driven machine learning framework forr Data Scientists.
可伸缩、大数据、sql驱动的机器学习框架,供数据科学家使用。
Big Data Machine Learning in SQL For PostgreSQL and Greenplum Database.Powerful machine learning, graph, statistics and analytics for data scientists
用于PostgreSQL和Greenplum数据库的SQL大数据机器学习。强大的机器学习,图表,统计和数据科学家分析- Apache Mahout
Scalable machine learning library
可伸缩机器学习库
Apache Mahout is a distributed linear algebra framework and mathematically expressive Scala DSL designed to let mathematicians, statisticians, and data scientists quickly implement their own algorithms. Apache Spark is the recommended out-of-the-box distributed back-end, or can be extended to other distributed backends.
Apache Mahout是一个分布式线性代数框架和数学表达Scala DSL,旨在让数学家、统计学家和数据科学家快速实现自己的算法。Apache Spark是推荐的开箱即用分布式后端,或者可以扩展到其他分布式后端。
- Apache PredictionIO
Apache PredictionIO is an open source Machine Learning Server built on top of a state-of-the-art open source stack for developers and data scientists to create predictive engines for any machine learning task.
Apache PredictionIO是一个开源机器学习服务器,构建在最先进的开源堆栈之上,供开发人员和数据科学家为任何机器学习任务创建预测引擎。
2.5 数据管理

2.5.1 部署(Deployment)
- CDH
Cloudera Enterprise Data Hub
Cloudera企业数据中心
One platform. Many applications.
一个平台。许多应用程序。
Imagine the possibilities if you could tackle your data warehouse, data science, data engineering, search, and streaming and real-time analytics disciplines with a unified platform. Cloudera Enterprise Data Hub makes that possible, empowering you to solve the most valuable questions by marrying multi-disciplinary analytics with one source of truth.
想象一下,如果您可以使用一个统一的平台来处理您的数据仓库、数据科学、数据工程、搜索、流媒体和实时分析学科,那么将会出现怎样的可能性。Cloudera企业数据中心使这成为可能,通过将多学科分析与一个真理来源结合起来,使您能够解决最有价值的问题。
- HDP
Hortonworks Data Platform
Hortonworks数据平台
Hortonworks Data Platform (HDP) helps enterprises gain insights from structured and unstructured data. It is an open source framework for distributed storage and processing of large, multi-source data sets. HDP modernizes your IT infrastructure and keeps your data secure—in the cloud or on-premises—while helping you drive new revenue streams, improve customer experience, and control costs.
Hortonworks数据平台(HDP)帮助企业从结构化和非结构化数据中获得洞见。它是一个用于分布式存储和处理大型多源数据集的开源框架。HDP使您的IT基础设施现代化,并在云计算或on- premismiss上保持数据的安全性,同时帮助您驱动新的收入流、改进客户体验和控制成本。
HDP enables agile application deployment, machine learning and deep learning workloads, real-time data warehousing, and security and governance. It is a key component of a modern data architecture for data at rest.
HDP支持敏捷应用程序部署、机器学习和深度学习工作负载、实时数据仓库、安全和治理。它是用于静态数据的现代数据体系结构的一个关键组件。- Apache Ambari
Hadoop cluster management
Hadoop集群管理
Apache Ambari is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Apache Ambari旨在通过开发用于配置、管理和监视Apache Hadoop集群的软件,简化Hadoop管理。Ambari提供了一个直观、易于使用的Hadoop管理web UI,该UI由其RESTful api支持。
2.5.2 协调(Coordination)
- Apache ZooKeeper
Centralized service for maintaining configuration information
用于维护配置信息的集中服务
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications.
ZooKeeper是一个集中的服务,用于维护配置信息、命名、提供分布式同步和提供组服务。所有这些服务都以某种形式由分布式应用程序使用。- Apache BookKeeper
Replicated log service which can be used to build replicated state machines
可用于构建复制状态机的复制日志服务
Apache BookKeeper is scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads.
Apache BookKeeper是可伸缩的、容错的、低延迟的存储服务,针对实时工作负载进行了优化。
2.5.3 调度(Sheduler)
2.5.3.1 资源调度(Resource Sheduler)
- Apache Mesos
a cluster manager that provides efficient resource isolation and sharing across distributed applications
提供跨分布式应用程序的高效资源隔离和共享的集群管理器
Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.Mesos is built using the same principles as the Linux kernel, only at a different level of abstraction. The Mesos kernel runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elasticsearch) with API’s for resource management and scheduling across entire datacenter and cloud environments.
Apache Mesos将CPU、内存、存储和其他计算资源从机器(物理的或虚拟的)中抽象出来,从而能够轻松地构建和有效地运行容错和弹性分布式系统。Mesos使用与Linux内核相同的原则构建,只是在不同的抽象级别。Mesos内核运行在每台机器上,并为应用程序(例如Hadoop、Spark、Kafka、Elasticsearch)提供跨整个数据中心和云环境的资源管理和调度API。- Apache Helix
A cluster management framework for partitioned and replicated distributed resources
用于分区和复制分布式资源的集群管理框架
Apache Helix is a generic cluster management framework used for the automatic management of partitioned, replicated and distributed resources hosted on a cluster of nodes. Helix automates reassignment of resources in the face of node failure and recovery, cluster expansion, and reconfiguration.
Apache Helix是一个通用集群管理框架,用于自动管理托管在节点集群上的分区、复制和分布式资源。在节点故障和恢复、集群扩展和重新配置时,Helix自动重新分配资源。
2.5.3.2 工作流调度(Workflow Sheduler)
- Apache Airavata
Workflow and Computational Job Management Middleware
工作流和计算性作业管理中间件
Apache Airavata is a software framework that enables you to compose, manage, execute, and monitor large scale applications and workflows on distributed computing resources such as local clusters, supercomputers,computational grids, and computing clouds.
Apache Airavata是一个软件框架,允许您在分布式计算资源(如本地集群、超级计算机、计算网格和计算云)上组合、管理、执行和监视大型应用程序和工作流。- Apache Airflow
Workflow automation and sheduling that can be used to author and manage data pipelines
工作流自动化和调度,可用于创建和管理数据管道
Airflow is a platform to programmatically author, schedule and monitor workflows.
Apache Airavata是一个以编程方式编写、调度和监视工作流的平台。- Apache Oozie
A workflow scheduler system to manage Apache Hadoop jobs.
管理Apache Hadoop作业的工作流调度程序系统。
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
Oozie是一个管理Apache Hadoop作业的工作流调度程序系统。
Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions.
Oozie工作流作业是一系列操作的有向无环图(DAGs)。
Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availability.
Oozie协调器作业是由时间(频率)和数据可用性触发的周期性Oozie工作流作业。
Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).
Oozie与Hadoop堆栈的其他部分集成在一起,支持几种类型的Hadoop开箱即用作业(如Java map-reduce、map-reduce、Pig、Hive、Sqoop和Distcp),以及系统特定的作业(如Java程序和shell脚本)。
Oozie is a scalable, reliable and extensible system.
Oozie是一个可伸缩、可靠和可扩展的系统。- Azkaban
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
Azkaban是一个批处理工作流作业调度程序,在LinkedIn上创建,用于运行Hadoop作业。Azkaban通过作业依赖项解决排序问题,并提供一个易于使用的web用户界面来维护和跟踪工作流。- Apache Falcon
Data management and processing platform
数据管理与处理平台
Apache Falcon is a feed processing and feed management system aimed at making it easier for end consumers to onboard their feed processing and feed management on hadoop clusters.
Apache Falcon是一个数据源处理和数据源管理系统,旨在使终端用户更容易地在hadoop集群上装载数据源处理和数据源管理。
2.5.4 授权(Authorization)
- Apache Sentry
Fine grained authorization to data and metadata in Apache Hadoop
对Apache Hadoop中的数据和元数据的细粒度授权
Apache Sentry is a system for enforcing fine grained role based authorization to data and metadata stored on a Hadoop cluster.
Apache Sentry是一个系统,用于对存储在Hadoop集群上的数据和元数据执行基于细粒度角色的授权。- Apache Knox
Simplify and normalize the deployment and implementattion of secure Hadoop clusters
简化和规范安全Hadoop集群的部署和实现
Apache Knox Gateway is an Application Gateway for interacting with the REST APIs and UIs of Apache Hadoop deployments.The Knox Gateway provides a single access point for all REST and HTTP interactions with Apache Hadoop clusters.
Apache Knox网关是一个应用程序网关,用于与Apache Hadoop部署的REST api和ui进行交互。Knox网关为所有与Apache Hadoop集群的REST和HTTP交互提供了一个单一的访问点。
2.5.5 监控(Monitor)
- Zabbix
zabbix是一个基于WEB界面提供分布式系统监视以及网络监视功能的企业级的开源解决方案。- Ganglia
Ganglia is a scalable distributed monitoring system for high-performance computing systems such as clusters and Grids. It is based on a hierarchical design targeted at federations of clusters. It leverages widely used technologies such as XML for data representation, XDR for compact, portable data transport, and RRDtool for data storage and visualization.
Ganglia是一个可伸缩的分布式监控系统,适用于集群和网格等高性能计算系统。它基于针对集群联合的分层设计。它利用了广泛使用的技术,如用于数据表示的XML、用于紧凑的、可移植的数据传输的XDR和用于数据存储和可视化的RRDtool。- Prometheus
Monitoring system & time series database
监控系统、、时序数据库- Grafana
The open platform for analytics and monitoring
分析和监控的开放平台- Apache Kibble
an interactive project activity analyzer and aggregator
交互式项目活动分析器和聚合器
Apache Kibble is a suite of tools for collecting, aggregating and visualizing activity in software projects.
Apache Kibble是一套用于收集、聚合和可视化软件项目中的活动的工具。
2.5.6 数据治理(Governance)
- Apache Atlas
Data Governance and Metadata framework for Hadoop
Hadoop的数据治理和元数据框架
Atlas is a scalable and extensible set of core foundational governance services – enabling enterprises to effectively and efficiently meet their compliance requirements within Hadoop and allows integration with the whole enterprise data ecosystem.
Atlas是一组可伸缩和可扩展的核心基础治理服务——使企业能够有效地满足Hadoop中的遵从性需求,并允许与整个企业数据生态系统集成。
Apache Atlas provides open metadata management and governance capabilities for organizations to build a catalog of their data assets, classify and govern these assets and provide collaboration capabilities around these data assets for data scientists, analysts and the data governance team.
Apache Atlas为组织提供了开放的元数据管理和治理功能,以构建数据资产目录,对这些资产进行分类和治理,并为数据科学家、分析师和数据治理团队提供围绕这些数据资产的协作功能。- Apache MetaModel
common interface for discovery,exploration of metadata and querying of differrent types of data sources
用于发现、探索元数据和查询不同类型数据源的通用接口
Apache MetaModel is a library that encapsulates the differences and enhances the capabilities of different datastores. Rich querying abilities are offered to datastores that do not otherwise support advanced querying and a unified view of the datastore structure is offered through a single model of the schemas, tables, columns and relationships.
Apache元模型是一个库,它封装了差异,并增强了不同数据存储的功能。为不支持高级查询的数据存储提供了丰富的查询功能,并通过模式、表、列和关系的单个模型提供了数据存储结构的统一视图。- Apache OODT
Object Oriented Data Techonology(middleware metadata)
面向对象的数据技术(中间件元数据)
Apache Object Oriented Data Technology (OODT) is the smart way to integrate and archive your processes, your data, and its metadata.
Apache面向对象数据技术(OODT)是集成和归档流程、数据及其元数据的智能方法。- Apache Bigtop
Apache Hadoop ecosystem integration and distribution project
Apache Hadoop生态系统集成与分发项目
Apache Bigtop is an Apache Foundation project for Infrastructure Engineers and Data Scientists looking for comprehensive packaging, testing, and configuration of the leading open source big data components.
Apache Bigtop是一个面向基础设施工程师和数据科学家的Apache Foundation项目,旨在全面打包、测试和配置领先的开源大数据组件。
2.6 数据分析
2.6.1 工具
- SQL
Excel- Python
Pandas
Numpy
Scipy
Matpalotlib
Sklearn
Keras- MATLAB
- SAS
- SPSS
- R
2.6.2 业务
2.6.2.1 需求分析
- BRD(商业需求文档)
BRD为“商业需求描述”的英语缩写,全称为:Business Requirement Document。是基于商业目标或价值所描述的产品需求内容文档(报告)。其核心的用途就是用于产品在投入研发之前,由企业高层作为决策评估的重要依据。其内容涉及市场分析,销售策略,盈利预测等,通常是供决策层们讨论的演示文档,一般比较短小精炼,没有产品细节。- MRD(市场需求文档)
市场需求文档,简称为MRD。(英文全称Market Requirement Document,MRD)。该文档在产品项目过程中属于“过程性”文档。是市场部门的产品经理1)或者市场经理(编写的一个产品的说明需求的文档。该文档在产品项目过程中属于“过程性”文档。该文档是产品项目由“准备”阶段进入到“实施”阶段的第一文档,其作用就是“对年度产品中规划的某个产品进行市场层面的说明”,这个文档的质量好坏直接影响到产品项目的开展,并直接影响到公司产品战略意图的实现。该文档在产品项目中是一个“承上启下”的作用,“向上”是对不断积累的市场数据的一种整合和记录,“向下”是对后续工作的方向说明和工作指导。- PRD(产品需求文档)
产品需求文档(Product Requirement Document,PRD)的英文简称。是将商业需求文档BRD(和市场需求文档(MRD)用更加专业的语言进行描述。
2.6.2.2 竞品分析
- 竞品分析的内容可以由两方面构成:客观和主观。客观即从竞争对手或市场相关产品中,圈定一些需要考察的角度,得出真实的情况;此时,不需要加入任何个人的判断,应该用事实说话。主观是一种接近于用户流程模拟的结论,比如可以根据事实(或者个人情感),列出竞品或者自己产品的优势与不足。其实你在分析别人的产品的同时,实际上是走了一遍用户流程。
2.6.2.3 用户行为分析
- 事件分析
事件分析法是一种实证研究方法,最早运用于金融领域,借助金融市场数据分析某一特定事件对该公司价值的影响。行为事件分析法来研究某行为事件的发生对企业组织价值的影响以及影响程度。企业借此来追踪或记录的用户行为或业务过程,如用户注册、浏览产品详情页、成功投资、提现等,通过研究与事件发生关联的所有因素来挖掘用户行为事件背后的原因、交互影响等。- 漏斗分析
漏斗分析是一套流程分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型。- 留存分析
留存分析是一种用来分析用户参与情况/活跃程度的分析模型,考察进行初始行为的用户中,有多少人会进行后续行为。这是用来衡量产品对用户价值高低的重要方法。- 分布分析
分布分析是用户在特定指标下的频次、总额等的归类展现。它可以展现出单用户对产品的依赖程度,分析客户在不同地区、不同时段所购买的不同类型的产品数量、购买频次等,帮助运营人员了解当前的客户状态,以及客户的运转情况。- 归因分析
- 路径分析
用户路径分析,顾名思义,用户在APP或网站中的访问行为路径。为了衡量网站优化的效果或营销推广的效果,以及了解用户行为偏好,时常要对访问路径的转换数据进行分析。- 热图分析
即应用一种特殊高亮的颜色形式,显示页面或页面组(结构相同的页面,如商品详情页、官网博客等)区域中不同元素点击密度的图示。- 间隔分析
2.6.2.4 用户分析
- 用户分群
用户分群即用户信息标签化,通过用户的历史行为路径、行为特征、偏好等属性,将具有相同属性的用户划分为一个群体,并进行后续分析。- 属性分析
根据用户自身属性对用户进行分类与统计分析,比如查看用户数量在注册时间上的变化趋势、查看用户按省份的分布情况。
2.7 数据报表
- FineReport
- YonghongBI
- Cognos
- 润乾
2.8 数据可视化
- Tabluea
- Echarts
- Redash
- D3
2.9 数据接口
- JSON
- XML
- CSV
- TXT
- Apache Thrift
Framework for scalable cross-language services development
可伸缩的跨语言服务开发框架
The Apache Thrift software framework, for scalable cross-language services development, combines a software stack with a code generation engine to build services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml and Delphi and other languages.
Apache Thrift软件框架用于可伸缩的跨语言服务开发,它结合了一个软件栈和一个代码生成引擎来构建在c++、Java、Python、PHP、Ruby、Erlang、Perl、Haskell、c#、Cocoa、JavaScript和Node之间高效无缝地工作的服务。js、Smalltalk、OCaml和Delphi等语言。
2.10 数据产品与服务
2.10.1 行业产品
- 电商
- 互金
- 企业服务
- 零售
- 文娱
- 教育
- 证券
- 银行
- 投资
2.10.2 部门产品
- 销售
- 运营
- 风控
- 运维
- 市场
- 决策
2.10.3 场景产品
- ELK
- 广告
- 推荐
- 风控
- 反欺诈
三、团队文化
专攻
每人选择一个技术方向专攻。
共享
每人关于所选方向,定期做文档总结、部门培训、和技术交流。
评审
主攻方向打通,通过技术评审,可转至其他方向。