借用HBase官网对其的介绍来初步认识一下HBase,当你需要对大量的数据进行随机,实时的读/写访问时,请使用Apache HBase™。这个项目的目标是在非常大的表中,存储管理亿级别的行和百万级别的列。Apache HBase是一个开源的、分布式的、版本化的、非关系数据库。在此借鉴网络,来去帮助自己再去理解理解HBase是什么?在此记录下来,便于自己后期翻看。
HBase特性
- 海量存储:单表可以存储百亿级别的量级,不用担心读取的性能下降;
- 面向列:数据在表中是按某列的数据聚集存储,数据即索引,只访问查询涉及的列时,可以降低系统的I/O;
- 稀疏性:传统行式存储的数据存在大量的空值的列,需要占用存储空间,造成存储空间的浪费,而HBase为空的列并不占用空间,因此表可以设计的很稀疏;
- 扩展性:HBase底层基于HDFS,支持快速扩展,可以随时添加或者减少节点数;
- 高可靠:基于Zookeeper的协调服务,能够保证服务的高可用。HBase使用WAL和replication机制,前者保证数据写入是不会因为集群异常而导致写入数据的丢失,后者保证集群出现严重的问题时,数据不会发生丢失和损坏;
- 高性能:底层的LSM数据结构,使得HBase具备非常高的写入性能。RowKey有序排列,主键索引和缓存机制使得HBase具备一定的随机读写性能。
HBase数据模型
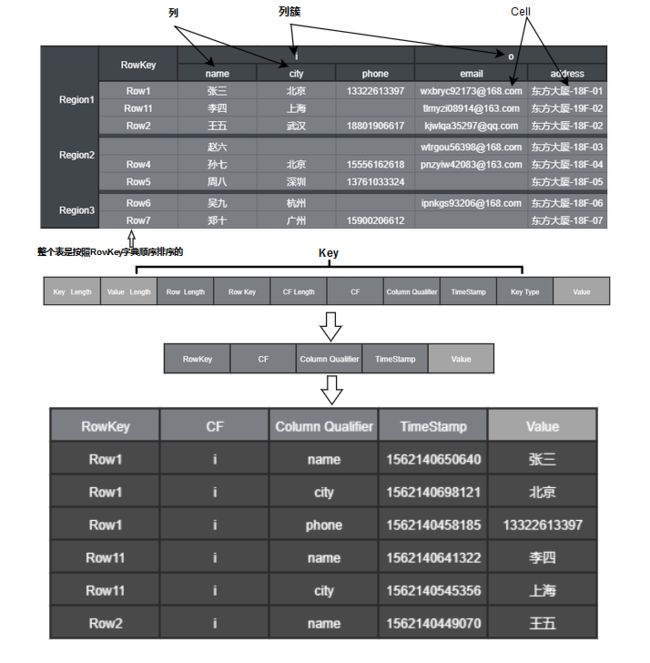
-
Table(表)
类似于传统数据库中的表的概念,用于组织存放数据在HBase中。
-
Row Key
HBase中的数据是以行的形式进行存储,每一行数据都会被一个唯一行健(Row Key)进行标识。Row Key在存储的过程中是按照字典的顺序排序的。其只能存储64k的字节数据。
-
Column Family (列簇) & qualifier(列)
HBase表中的每个列都归属于某个列簇,列簇在我们定义表的时候指定。列名以列簇作为前缀,每个列簇都可以有多个列成员(column),新的列可以随后按需,动态加入;权限控制,存储以及调优都是在列簇层面进行的。
-
Cell(单元格)
Cell是由行,列簇和列的坐标交叉决定的,其是有版本号的,每个Cell的内容是未解析的字节数组。由{row key, column( =
-
Timestamp(时间戳)
在HBase中每个Cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
HBase物理存储
-
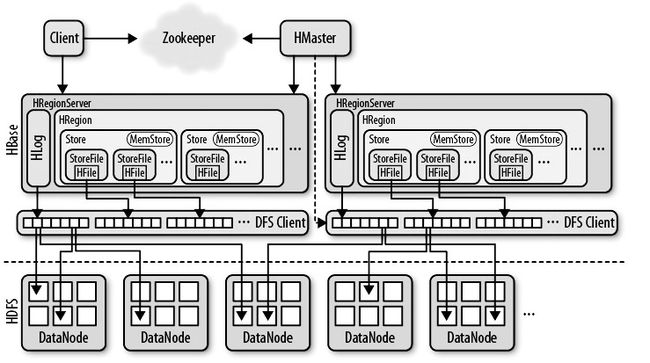
HRegion
HBase表中的数据按照行键的字典顺序排序,HBase表中的数据会按照行的方向切分为多个HRegion。最开始只有一个HRegion,但是随着数据量的不断增加,HRegion会产生分裂,这个过程不停的进行。一个表可能对应一个或者多个HRegion。HRegion是HBase表分布式存储和负载均衡的基本单元,一个表的多个HRegion可能分布在多台HRegionServer上。HRegion和Region是同一个意思,只是叫法不同。
-
Store
HRegion是分布式存储的基本单元,但不是存储的基本单元。其内部结构为,一个HRegion由多个Store来组成。有几个Store取决于建表的时候设置的列簇的数量,一个列簇对应一个Store。之所以这么设计,是因为一个列簇中的数据往往数据很类似,方便进行压缩,节省存储空间。
-
MemStore
表的一个列簇对应一个Store,Store的数量由表的列簇的数量来决定。一个Store由一个MemStore和零个或者多个StoreFile组成。MemStore作为内存缓存区,数据的写操作会先写到MemStore中,当MemStore中的数据增长到一定阀值后,RegionServer会将其中的数据flush到StoreFile中,每次写入行成一个单独的StoreFile。
-
StoreFile
当StoreFile数量增长到一定阀值后,系统会进行合并(minor compaction和major compaction),合并过程会进行版本的合并和删除工作,形成更大的StoreFile。
-
HFile
HFile和StoreFile是同一个东西,只不过是站在HDFS的角度称这个文件时HFile,在HBase的角度叫做StoreFile。
-
HLog(WAL log)
WAL(Write ahead log),类似MySQL中的Binlog,用来做灾难恢复用的,HLog记录数据的所有变更,一旦数据修改,就可以从HLog中进行恢复。
每个HRegionServer维护一个HLog。HLog文件就是一个普通的Hadoop Sequence File,Sequence File的Key是HLogKey对象,HLogKey中记录了写入数据的归属馨馨,除了Table和Region名字外,同事还包括Sequence number和timestamp,timestamp是写入时间,sequence number的起始值是0。HLog Sequence File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
HBase读写流程
HBase读流程

1.Client先访问Zookeeper,从meta表读取Region的位置,然后读取meta表中的数据。meta中又存储了用户表的Region信息;
2.根据namespace,表名和RowKey在meta表中找到对应的Region信息;
3.找到这个Region对应的RegionServer;
4.查找对应的Region;
5.先从BlockCache找数据,如果没有,再到MemStore里面读;
6.MemStore如果没有,再到StoreFile上读(为了读取的效率);
7.如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache里,再返回给客户端。
HBase写流程
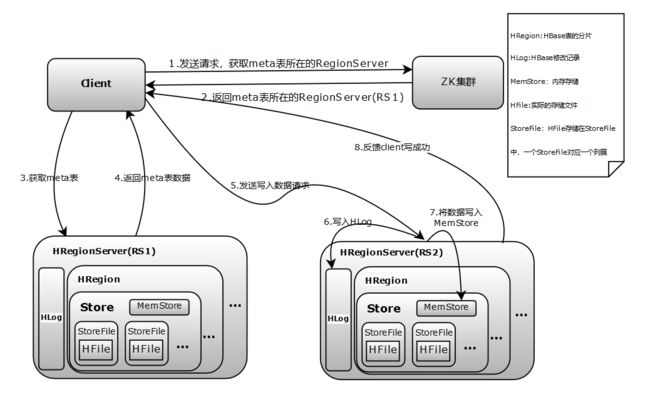
1.客户端向ZK发送请求,获取meta表所在的RegionServer;
2.客户端通过RegionServer获取到meta表的数据;
3.然后客户端向集群中的RegionServer发送写入数据的请求;
4.RegionServer收到写数据的请求后,将数据写到HLog中,这一步是为了数据的持久化和恢复;
5.RegionServer将数据写入内存(MemStore);
6.然后通知客户端数据写入成功。
HBase Region Flush
MemStore中的数据Flush到HDFS上的触发条件有哪些呢?HBase会在如下几种情况下触发flush操作,需要注意的是MemStore的最小flush单元是HRegion而不是单个MemStore。可想而知,如果一个HRegion中MemStore过多,每次flush的开销必然会很大,因此建议进行表设计的时候尽量减少ColumnFamily的个数。下面设置的参数可以移步官网,在HBase Default Configuration这个小节里查找☞☞☞
MemStore级别限制:当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发MemStore刷新;
Region级别限制:当Region中所有MemStore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 4* 128M = 512M),会触发MemStore刷新;
RegionServer 级别限制:当一个RegionServer中所有MemStore的大小总和达到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认40%的JVM内存使用量),会触发部分MemStore刷新。Flush顺序是按照MemStore由大道小执行,先Flush MemStore最大的Region,再执行次大的,直至总体MemStore内存使用量低于阀值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM内存使用量);
当一个RegionServer中HLog数量达到上限(可以通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个HLog对应的一个或者多个Region进行flush;
HBase定期刷新MemStore:默认周期为1小时,确保MemStore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致有问题,定期的flush操作有20000左右的随机延迟;
手动执行flush:用户可以通过shell命令flush 'tablename' 或者 flush 'region name'分别对一个表或者一个Region进行flush。

HBase文件合并
MemStore每次Flush会创建新的HFile,而过多的HFile会引起读的性能问题,那么如果解决这个问题呢?HBase采用Compaction机制来解决这个问题,在HBase中Compaction分为两种:Minor Compaction和Major Compaction。

- Minor Compaction
Minor Compaction是指选取一些小的,相邻的StoreFile将它们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted和Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。 - Major Compaction
Major Compaction是指将所有的StoreFile合并成一个StoreFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经TTL(time-to-live)的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在。Major Compaction可以手动或自动触发,然而由于它会引起很多的I/O操作而引起性能问题,因而它一般会被安排在比较闲的时间进行。
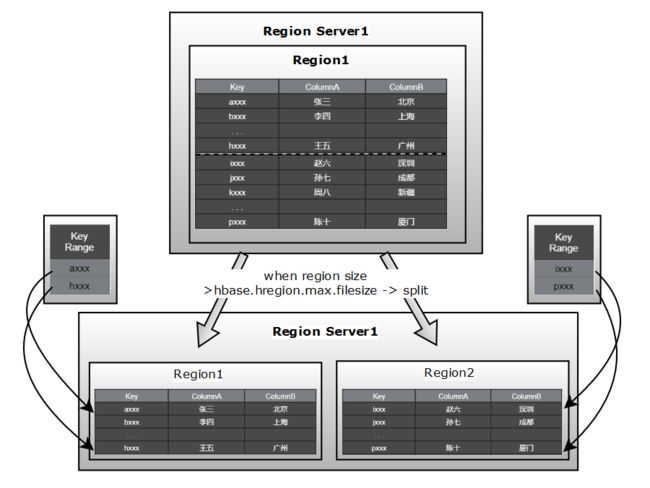
HBase Region 的分裂
刚开始的时候每个表只有一个Region,当Region变的特别大的时候,它会被分割成两个Region。分隔的Region各自持有原Region一部分数据,当然分裂会报告给HMaster。然后有时候,HMaster会将新分裂的Region移动到其它的RegionServer上面。