原文链接,介绍如何在Linux系统中确保随机数生成器具有良好的随机性。Linux系统本身是确定性的,如何生成不确定的随机数呢?请看下文。如发现错误,请留言或者发送邮件到[email protected]。未经授权,请勿转载。

在构建安全系统时,一个随机数的来源是必备品。缺少它们,大多数加密系统都会奔溃,双方通讯得私密性和真实性也会被颠覆。比如,你在浏览https://blog.cloudflare.com这个链接,那么你使用的SSL连接就需要随机数来确保安全(它们被用于建立安全连接)。
我们已经在上篇博客中写过为什么安全系统需要随机数,但是从计算机中获取随机数真的很难。这篇博客探寻Linux内部的随机数生成器,看看它是如何克服在一个完全不随机的机器上生成随机数的难题。
CloudFlare的服务器需要优质的随机数来源以完成身份验证和确保SSL中的完美向前完全性。但是,从内在层面来看,我们所使用的计算机都是确定性的机器,它们服从指令而且被要求按照可预测的方式来执行那些指令。完全没有内置不确定性和不可预测性:没有简单的方法让计算机去掷硬币或者骰子。想在计算机中获取随机性,你必须寻求外部世界的帮助。
消费者计算机和移动设备都有很多传感器,它们可以提供不可预测的输入。如果足够仔细的测量,用户键盘敲击时间和鼠标移动轨迹都具有一定程度的随机性。麦克风和摄像头的噪声也可以提供很多的随机性。移动设备甚至有更多的随机源,包括无线信号的波动、运动传感器和GPS信息。
最需要随机数的服务器上并没有这些传感器。特别是有些服务器还是运行在虚拟环境中,连精确的系统时钟可能都不能访问。对于CloudFlare的服务器,我们目前依赖Linux操作系统内置的随机数生成器。
Linux是世界上最受欢迎的操作系统之一。从世界上许多最大型的网站(Google,Facebook,Amazon和Apple等等)的web服务器和数据中心,到台式机(Ubuntu,Chrome OS等等),再到嵌入式设备(智能电视,安卓等等),Linux都可以成为它们的操作系统。CloudFlare的软件也构建在Linux操作系统内核的坚实基础之上。
Linux本身提供一个随机数服务,这样任何程序都可以在任意时间获取随机数。很幸运,Linux是开源软件,我们可以通过阅读代码了解其工作原理。并且验证它可以为我们的加密提供合适的随机数来源。
熵和随机性
并不是所有的随机性都是相同的。随机性有两种:均匀性和不可预测性。如果运行足够长的时间后,所有的数字出现得很均匀,那么这个随机数生成器提供了‘均匀的’输出。那对于随机过程建模很有用,但是对于安全来说不够好。
对于计算机安全,随机数需要很难被猜出:它们需要是不可预测的。数字可预测性被量化为熵。
一个公正的掷硬币提供一位熵值:硬币正面或反面着地的概率一样(可以被想成0和1)。因为概率相等,所以硬币的‘输出’不存在可预测性。我们称它提供一位熵值。
一个不公正的掷硬币提供不足一位熵值,因为如果你知道偏向性会更加容易猜到结果。掷一个两面都是正面的硬币不提供任何熵,因为结果可以被百分百猜出来。
熵和统计随机性不同。数字流的统计特性不能保证该流中包含任何熵。比如,常量pi的数字在任何统计测量中看起来都是随机的,但是其不包含任何熵,因为有总所周知的公式可以计算出它们从而完美地预测下一个值是什么(另外,pi是一个正规数:所有数字出现得概率一样)。

此外,大数字也不总是含有大量的熵。你可以获取一个小的随机数,然后把它变成大的随机数同时保持熵不变。比如,获取一个介于1到16的随机数,然后用类似SHA-1的算法计算其加密散列值。获得的160位数字看起来非常随机,但是这些数字只会有仅仅16中可能性。获取随机数的池子容量的大小确定随机性的强弱。
对于加密密钥,用于创建它们的熵的多少和其猜测难度有关。一个从熵值是20的源产生的128位密钥并不比20位的密钥更安全(译者语:熵一样大)。要创建安全的密钥必须要有一个优异的熵源。
畅游池中
在Linux中,所有随机性的源头都是一个被称为内核熵池(译者语:原文是kernel entropy pool)的东西。这是一个私密保存在内核内存中的大数字(4096位)。这个数字有可能性。所以它可以包含4096位熵。有一点需要注意:内核需要能够从一个拥有4096位熵的源填满该内存。那就是难点:寻找大量的随机性。
熵池有两种使用方式:从其中生成随机数和内核再向其填充熵。当从池中生成随机数时,池子的熵值会降低(因为获取到随机数的人就有了一些池子的信息)。因此随着随机数被发放出去,池子的熵值也在降低,必须为其重新填充。
重新填充池子的过程被称为搅拌(stirring):多个新的熵源被搅拌混合成池中的数位。
这就是随机数生成如何在Linux上执行的关键。如果需要随机性,从熵池中获取。当可用的时候,其他随机源会被用于搅拌填充熵池,减少其可预测性。具体细节设计一些数学知识,但是了解Linux随机数生成器的工作原理很有趣,因为其原理和所用技术也适用于其他软件和系统中的随机数生成。
内核对池中熵的位数维护了一个粗略估算值。你可以使用下面的命令检查这个估算值:
cat /proc/sys/kernel/random/entropy_avail
拥有大量可用熵的健康Linux系统会返回接近完整的4096位熵。如果返回值小于200,那么系统运行在低熵状态。
内核在监视你
我说过系统会获取其他源的随机性,并将它们搅拌填充到熵池中。这是通过被称为时间戳的东西来完成。
大多数系统都有精确的内部时钟。每次用户和系统进行交互,那个时间的时钟值都会被记录成时间戳。即使年、月、日很容易猜,但是毫秒和微妙不好猜,因此时间戳包含一些熵值。从用户鼠标和键盘获取的时间戳以及来自网络和磁盘的时长信息各自具有不同的熵值。
在时间戳中找到的熵怎么传递到熵池中呢?简单,用数学把它们混合在一起。好吧,如果你喜欢数学的话是挺简单的。
把它混合起来
熵的一个基本属性是有良好的混合性。如果你有两个不相关的随机流,然后把它们合并在一起,新的流不会拥有更少的熵。合并一些低熵的源会得到一个高熵的源。
你所需要的是一个正确的合并函数:可以用来把两个熵源合并的函数。这样的函数中最简单的就是逻辑异或(XOR)。下面的真值表展示了XOR函数如何合并两个不同随机流的位x和y。

即使其中一个源的数位没有足够的熵,在其和另一个源进行异或时也不会有任何危害。熵值一直保持增加。在Linux内核中,使用异或合并时间戳到主熵池中。
生成随机数
加密应用需要非常高的熵。如果128位密钥是由仅仅64位熵生成,那么只需要次就可以猜出,而不是次。这之间的区别是用一千台计算机运行几年就可以暴力破解和用全世界的计算机运行比宇宙历史还长的时间才能完成。
加密系统需要尽可能每位都有一个熵值(译者语:密钥的每位都有一个熵,1024位的密钥的熵值要是1024)。如果系统熵池中没有4096位熵,那怎么才能让系统返回一个完全的随机数呢?一种方法就是使用加密散列函数。
加密散列函数输入任意长度的数据,输出一个固定长度的数字。修改输入的一位数据会导致输出完全改变。散列函数擅长把多个事物混合在一起。这个混合属性使得来自输入的熵均匀的分布在输出中。如果输入熵的位数比输出的位数还多,那么输出将会十分随机。这就是从熵池中获取高熵值随机数的原理。
Linux内核使用的散列函数是标准的SHA-1加密散列。通过散列整个熵池和应用一些其他算数,会生成160位的随机数给系统使用。在此以后,系统会相应地降低熵池的估算熵值。
正如上面说过的,如果熵池中没有足够的熵,那对其使用类似SHA-1这样的散列函数会是危险的。这也是为什么我们要一直紧盯着可用的系统熵值:如果它降得太低,那么随机数生成的输出的熵值就会比其本身应该有要低。
耗尽熵
耗尽熵对系统来说很危险。当系统的熵值估算低于160位,即SHA-1散列的长度,事情会变得复杂。对于程序和性能的影响取决于你使用两种Linux随机数生成器的哪一个。
Linux为随机数据暴露两个接口,它们在熵值水平低的时候表现大相径庭。它们分别是/dev/random和/dev/urandom。当熵池的熵值低到可以被预测,两个请求随机数的接口都会有问题。
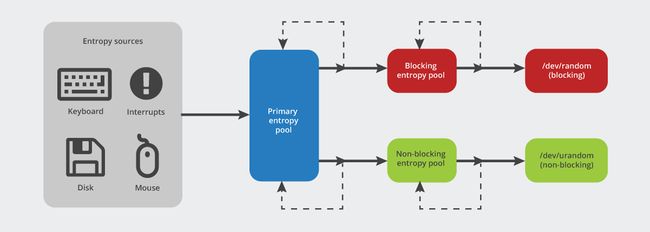
当熵值过低,/dev/random会阻塞调用者直到系统的熵值恢复到足够高的水平。这保证产生的随机数的熵很高。如果在一个时间要求严格的服务中使用/dev/random,然后系统的熵值低于安全的最低值,那么延迟(译者语:因为/dev/random在系统熵值过低时,会阻塞调用者)会损害服务质量。
另一方面,/dev/urandom不会阻塞。它仍然返回熵池的散列值,即使其中已经几乎没有熵。这个数据不一定是低熵。只要熵池中还有足够的熵,使用它并没什么害处。然而,如果熵池没有被补充,那这个数据不适合加密用途。
解决这个问题的办法就是为系统加入更多的熵。
硬件随机数生成的拯救?
Intel的Ivy Bridge系列处理器有个被称为“安全密钥”的有趣特性。这些处理内部包含一块特殊的硬件来生成随机数。一个RDRAND汇编指令返回据称源于芯片的熵值很高的随机数据。
有人宣称Intel的硬件数字生成器可能不是完全随机的。因为它被烧制在硅芯片中,所以那个断言很难验证。事实证明,即使生成得数字有一些偏向性,只要它不是系统随机性的唯一来源,它仍然可以提供帮助。即使随机数生成器有后门,随机性的混合特性也证明它不会降低池中的熵。
在Linux中,如果存在硬件随机数生成器,Linux内核会使用XOR函数把RDRAND的输出混入熵池的散列值中。这位于Linux源代码的这里(C语言的XOR操作符是^)。
第三方熵生成器
硬件数字生成器并不是哪里都有,Linux内核自身获取随机性的来源也有限。针对这种情况,出现了一些第三方随机数生成工具。其中就有依赖处理器缓存时间的havedeg,还有从外部音频或视频输入设备采集噪音的audio-entropyd和video-entropyd。通过把这些从额外来源收集得熵混入到Linux熵池中,系统的熵值肯定会增加。
来源的多样性
主要需要理解得是更好的随机性来源于多样性。从不同的来源获取随机数,然后把它们一起混合会得到更好的随机数。对于服务器,这应该包含机器本地数据(硬件随机数生成器,网络耗时)和位于安全地点的外部获取来源。
展望未来
除了上述说到的来源,还有很多随机数来源可以获取。这些包括火山灯,太空噪音和光的量子属性。通过增加新的源到Linux中的方法,CloudFlare正在开发一个系统用以确保所有服务器都能有高质量的随机数。这些系统会在未来几个月上线,到时候我们会和社区分享其中的细节。v