https://www.jianshu.com/p/a854b6acfa23
1、正则表达式在Python中有个专门的库叫re模块,首先进行导入模块。再定义一个字符串str,然后定义一个正则表达式匹配规则regex。
2、“^d”代表的意思是以d元素开头的任意一个字符串,也就是说只要是以d开头的字符串,后面的元素不论是什么,都是符合规则的,总之必须要以d开头。
3、“.” 较为常用,其代表的意思是任意字符,其表示的范围非常广,可以接任意字符,不论是中英文,还是下划线之类的特殊字符,都是可以代表的。举个栗子,正则表达式“^d.”就是代表以d开头的字符串,b后边接任意字符都可以。
4、“*” 也十分常用,其代表的意思是前面的字符可以重复任意多遍,可以是0次,1次,2次等任意多次。
5、了解好这几个特殊字符的用法之后,接下来通过代码简单的感受一下。如下图所示,如果匹配成功,则返回yes;如果没有匹配成功,则不返回任何东西
1、特殊字符“$”代表的意思是结尾字符。举个栗子,正则表达式“3$”,表示匹配以3为结尾的字符串。代码演示如下图所示。

正则表达式匹配模式“.*3$”代表以3结尾的任意字符的字符串,很显然匹配的结果和原始字符串是一致的,所以有返回结果。
2、如果将正则表达式匹配模式改为“.*4$”,则表示以4结尾的任意字符的字符串,此时是没有任何的输入结果的,如下图所示。

3、正则表达式特殊字符“?”比较常用,其代表的意思是非贪婪匹配模式。默认情况下,匹配字符串是一种贪婪的匹配,换句话说,默认情况下字符串会根据匹配模式,去匹配最大的长度。
4、下图是一个实例。其中括号代表的是提取字符串的子串,正则表达式会把满足匹配条件的字符串放到括号里边。匹配模式“.*(p.*p).*”代表的意思是:左边的“.* ”的意思是任意字符串,可以是空,也可以是非空的字符串,之后是字符p,中间的“.* ” 的意思也是任意字符串,之后再是一个p,尔后右边的“.* ” 的意思也是任意字符串。目前的逻辑就是将两个p中间的字符串连同p一块取出。

但是其输出的结果却为“pp”,并不是我们想要的“pccccccccccp”结果。原因是正则表达式的贪婪匹配所致,实际上它是反向匹配的,所以从字符串来看,匹配到的结果是“pp”。
5、如果我们使用非贪婪模式,即将匹配模式“.*(p.*p).*”改为模式“.*?(p.*p).*”,在第一“p”之前加个特殊字符“?”,则运行的结果就如下图所示。

可以看到匹配模式已经开始从左边开始进行匹配,答案趋向于我们想要的结果。但是在后面却出现了两个p。原因是后面的那个p未指定其为非贪婪模式,所以后面的那个p仍然是从右边开始反向取值的。
6、接下来,我们继续使用非贪婪模式,即将匹配模式“.*(p.*p).*”改为模式“.*?(p.*?p).*”,在第二“p”之前也加个特殊字符“?”,则运行的结果就如下图所示。

此时可以看到匹配的结果就是我们想要的结果了,原因是此时两个p均采用了非贪婪模式,所以匹配模式,从左到右顺序进行。
7、理解非贪婪模式之后,对于正则表达式的匹配就很好理解了,如下图的结果将返回“pcccp”,非贪婪模式下。
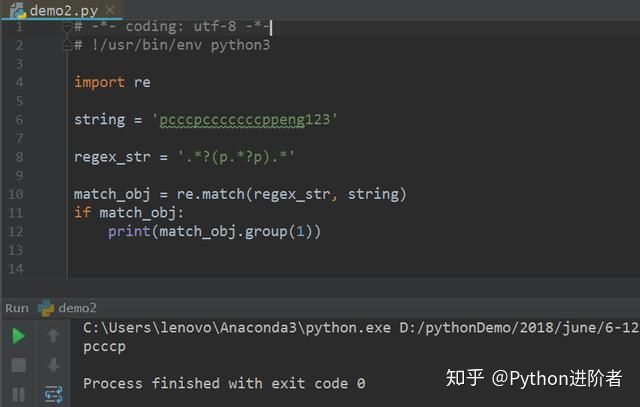
8、下图的结果将返回“pcccpcccccccpppp”,非贪婪模式和贪婪模式共存的情况下。

非贪婪模式在网络爬虫的过程中对于字符串的提取非常重要,务必要理解和掌握。小伙伴们,关于正则表达式的特殊字符“$”和“?”的用法,你们get到了吗?
、正则表达式特殊字符“+”,其代表的意思“+”号前面的任意字符必须至少出现一次,才能匹配成功。如下图所示,如果没有加特殊字符“+”,则按照前面介绍的贪婪模式从右边进行匹配,输出的结果为“pp”。

2、现在将匹配模式由之前的“.*(p.*p).*”改为“.*(p.+p).*”,即将特殊字符“*”改为特殊字符“+”,用特殊字符“+”来限定前面的字符出现的次数,至少出现一次。运行程序,得到的结果为“ppp”,如下图所示。

简单的来理解一下,首先贪婪模式不在赘述,然后匹配到第一个字符p,之后碰到特殊字符“+”,表示匹配任意字符,但该字符至少出现一次,然后再匹配到第二个字符p,才会提取到匹配的字符串。
3、再次来感受一下,将之前的三个ppp改为现在的php,之后再运行程序,如下图所示,得到的结果是php。

4、如果将之前的三个ppp改为现在的phhp,会有什么样的结果呢?如下图所示,毋庸置疑,答案肯定是phhp。

因为特殊字符“+”号表示只要任意字符至少出现一次,都会被提取出来。
5、简单的来总结一下,特殊字符“*”和特殊字符“+”都是用来表示字符出现次数的限定词,用于限定前面的任意字符出现的次数。不同的地方在于特殊字符“*”模式下,字符出现的次数可以是0次或者任意多次,而特殊字符“+”模式下,字符出现的次数至少是1次。

特殊字符“{}”实质上也是一个限定词的用法,其限定前面字符所出现的次数,其常用的模式有三种,分别是“{数字}”、“{数字,}”和“{数字1, 数字2}”。举个例子,如“{1}”、“{1,}”和“{1, 3}”。到这里可能大家还不是很清楚,下面依次通过实例来演示一下,加深对特殊字符“{}”的理解。
1、如下图所示,限定字符p前面的字符出现1次,则根据贪婪匹配模式,pap成功匹配到。

2、如果将匹配模式更改为“.*(p.{2}p).*”,则无任何的输出,如下图所示,因为此时并没有任何的字字符串符合匹配条件。

3、相应的,我们将原始字符串做一下更改,如下图所示,此时“.*(p.{2}p).*”匹配模式有对应的结果,如下图所示。

4、特殊字符“{1,}”代表的是前面的字符出现1次及以上;特殊字符“{2,}”代表的是前面的字符出现2次及以上;特殊字符“{3,}”代表的是前面的字符出现3次及以上;以此类推。举个栗子,如下图所示。

我们要匹配出现p字符前面出现3次及以上的次数,此时子字符串phhhhp被提取出来,但是pap和paap都没有提取到,因为其不满足匹配条件。
5、特殊字符“{1, 3}” 代表的是前面的字符至少出现1次,最多出现3次;特殊字符“{2, 5}” 代表的是前面的字符至少出现2次,最多出现5次;以此类推。举个栗子,如下图所示。
当使用特殊字符“{1, 3}”的时候,如下图所示:
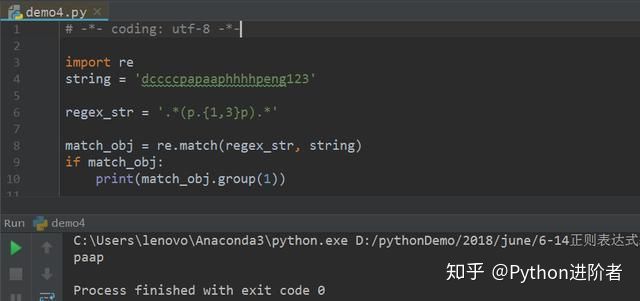
贪婪模式下,字符串从右边开始往左取,首先遇到相对满足条件的子字符串是phhhhp,但是并不符合规则,因为该子字符串出现的次数为4次,而限定条件为1次到3次,所以这个子字符串不符合匹配条件,尔后继续往前匹配,得到匹配结果paap,满足匹配条件。
6、同理,当使用特殊字符“{3, 5}”的时候,如下图所示:

根据上一步的分析可以得知,该匹配结果为phhhhp。
1、直接上代码演示,比方说我们需要匹配一个字符串“dcpeng123”,匹配模式为 “(dcpeng|dcpeng123)”,记得匹配模式中要有括号,否则后面的group方法会报错。

如上图所示,匹配模式“(dcpeng|dcpeng123)”的意思是只要匹配“dcpeng”或者“dcpeng123”中的任意一个,就说明提取成功。“|”实质上是一个“或”的关系,匹配的结果为“dcpeng”可以满足匹配条件,匹配的结果为“dcpeng123”也可以满足匹配条件。所以在这里,正则表达式首先匹配了字符串“dcpeng”,所以打印出来的结果就是“dcpeng”。
2、当我们把匹配模式中两个字符串的顺序调整一下,如下图所示。

根据第一步的分析步骤,其匹配结果为“dcpeng123”,在此就不再赘述了。
3、如果我们将原始字符串做一下更改,更改为“dcpeng”,而保持匹配模式不变,如下图所示。

此时的匹配结果为“dcpeng”。原因是匹配模式首先是“dcpeng123”,与原始字符串匹配不上,之后通过特殊字符“|”再定位到“dcpeng”,发现可以与原始字符串匹配上,所以匹配成功,输出匹配结果。
4、如果我们只是想匹配字符串中的一部分,那应该如何做呢?如下图所示,只需要将匹配模式用括号括起来就可以了,而括号外面的部分保持与原始字符串一致即可。

此时可以看到输出的结果为“dcpeng”。这里容易犯错,很多小伙伴很可能以为结果是“dcpeng123”,只需要记住我们匹配的内容只是在括号中,外边的世界与我们无关。
同样的,如果我们将原始字符串改为“dccpeng123”,保存匹配模式不变,此时的匹配结果为“dccpeng”,如下图所示。

5、如果真想匹配到外边的结果,就应该再加一层括号,将外边的内容与括进来,入下图所示。当程序运行之后,我们得到的匹配结果是“dccpeng123”。

当程序运行之后,实际上是以最外层的这个括号为顺序的,然后依次向内进行匹配。当group方法中取第一个括号的内容时,匹配到的结果是最外层括号中的内容,所以是“dccpeng123”。可以看到“123”也被提取出来了。
同理,当group方法中取第二个括号的内容时,匹配到的结果是最二层括号中的内容,所以是“dccpeng”,如下图所示。

此时可以看到“123”并没有被提取出来,因为此时匹配的内容是“(dcpeng|dccpeng)”。1、“\s”代表的意思是匹配空格,匹配模式“加\s油”代表的是字符“加”和“油”之间有空格的意思,如下图所示。

可以看到原始字符串中“加”和“油”之间有空格,与匹配条件相符合,所以匹配成功。
2、为了加强理解,现在将原始字符串改为“加加油”,字符中间不为空格,保持匹配模式不变,如下图所示。

可以看到无任何输出,说明匹配不成功。
3、如果“加”和“油”之间有多个空格的话,则只需要在匹配模式中将“加\s油”改为“加\s+油”即可,如下图所示。

4、“\S”代表的意思与“\s”代表的意思刚刚相反,也就是说匹配的那个字符只要不是空格,都可以匹配。如下图所示,继续用第二步那个例子,只要将匹配模式中的“\s”改为“\S”,其他的保持不变,如下图所示。

可以看到此时就可以匹配成功。
5、而将原始字符串改为“加 油”,两个字符中间有个空格,匹配模式不变,如下图所示。
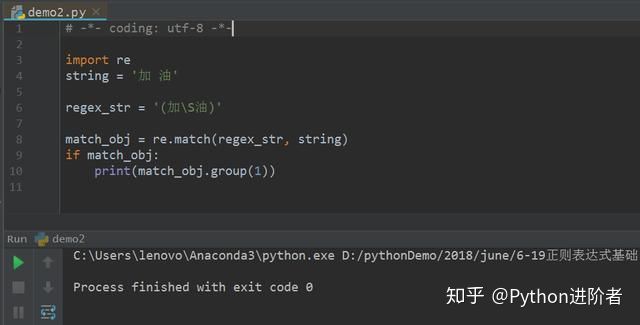
可以看到此时无任何输出,说明匹配不成功。
6、同样的,如果要匹配多个非空白字符的话,只需要将“\S”改为“\S+”即可,如下图所示。

关于大“S”和小“s”的介绍就到这里了,小伙伴们get到了吗?
作者:Python进阶学习交流
链接:https://www.jianshu.com/p/a854b6acfa23
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。