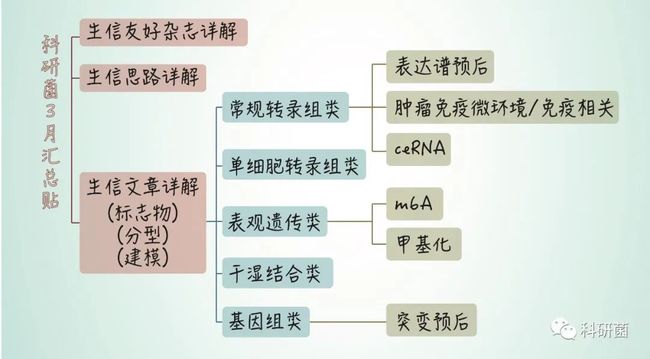
今天跟大家分享的是2020年1月发表在Genome Biol.(IF:14.028)杂志上的一篇文章A benchmark of batch-effect correction methods for single-cell RNA sequencing data.在文章中作者基于10个人和鼠的dataset,使用t-SNE和UMAP可视化技术,结合kBET、LISI、ASW、ARI和DEG等基准度量,来评估对14种去批次效应算法的批次效应校正结果。
A benchmark of batch-effect correction methods for single-cell RNA sequencing data
对单细胞RNA测序数据的批次效应校正算法基准
(因为视频是白天录的,住所附近小孩比较活泼,视频有些地方可能会有些许杂音,望读者朋友们海涵(T ^ T) )
一.研究背景
使用不同技术生成的大规模单细胞转录组dataset,批次效应特殊的系统变化对批次效应效果的去除和dataset成提出了挑战。随着scRNA-seq数据的持续增长,实现计算器资源的有效批次集成是至关重要的。在这里,作者对批次效应校正算法的基准进行了深入的研究,以确定最适合去除批次效应的算法。
二.分析流程
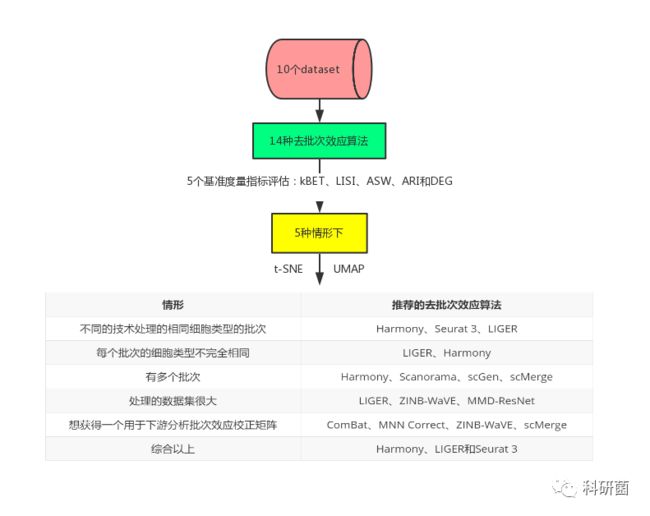
三.结果解读
1.使用五个评估指标对十个dataset的14种方法进行全面测试
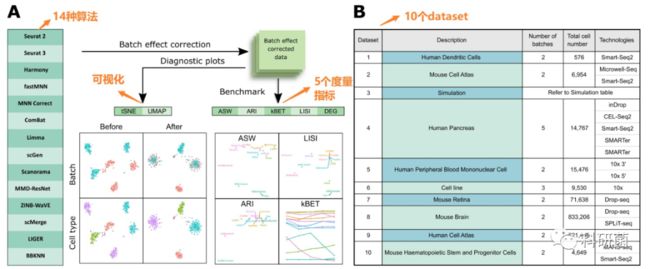
图1.基于10个使用5个评估指标的dataset的14个算法进行基准测试
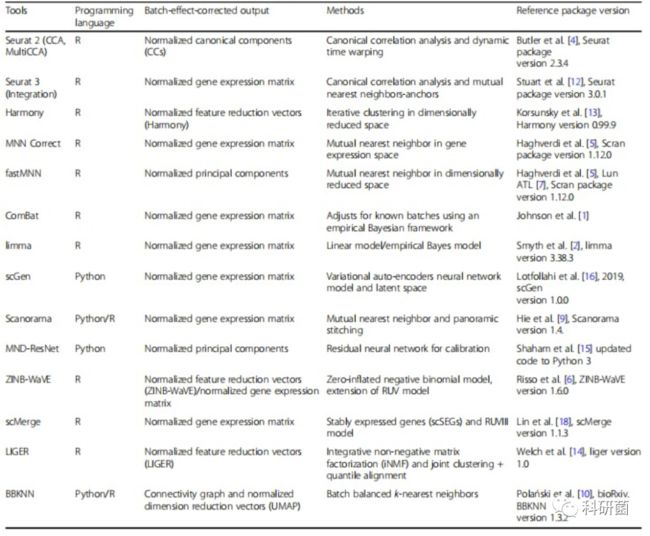
表1.十四种批次效应校正算法描述
图1A:展示了基准测试的流程。
评估了14种批次效应校正算法的性能,评估了它们在保持细胞亚群分离准确性的同时进行批次集成的能力。作者使用t-SNE和UMAP可视化技术,结合kBET、LISI、ASW、ARI和DEG等基准度量来评估批次效应校正结果。
图2B:批次效应校正算法测试的十个dataset。
涵盖了不同类型的细胞,如树突状细胞、胰腺细胞、视网膜细胞和外周血单核细胞(PBMCs),dataset来自人类和小鼠。所使用的技术范围也很广,包括10x、SMART-seq、Drop-seq和SMARTer等。
表1:总结了14种批次效应校正算法的关键特性。
2.不同情形下对矫正方法进行评估
2.1情形一:不同的技术处理的相同细胞类型的批次
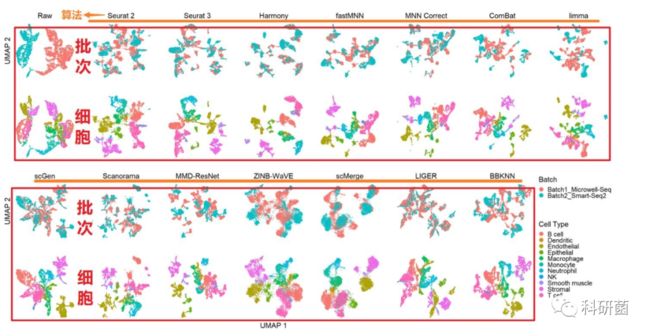
图2.使用UMAP可视化技术对“dataset2(鼠细胞谱)”进行的14种批次效应校正算法进行定性评价
图2:每种算法下有两行图,第一行是依据细胞批次来着色,在第二行中是按细胞类型来着色。在第一行中按批次效应着色,在第二行中按细胞类型着色(下文后续的操作类似)。
Seurat 2, Seurat 3, Harmony,fastMNN,等降维后亚群聚类情况较好 。
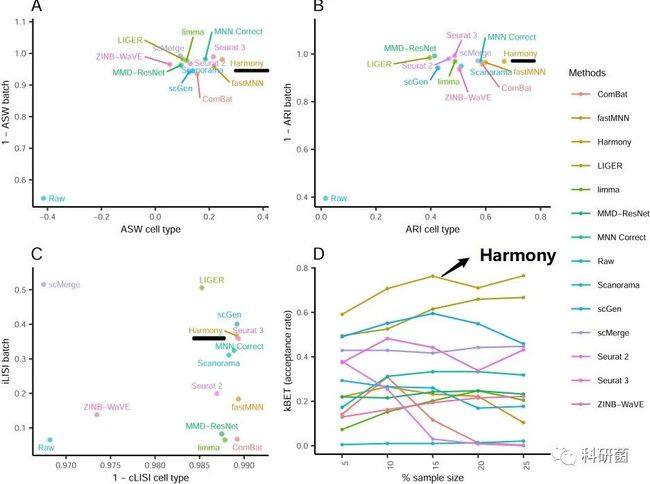
图3.使用ASW、ARI、LISI和kBET等四个评估指标对“dataset2”14种批次效应效应校正算法进行定量评估 图3:综合对批次集成和细胞亚群纯度的四项指标评估结果中,Harmony算法的排名都比较靠前(图中用“黑色下划线”和“橙色方框”标注综合socre较高的几个算法,下文其余指标评估的图示除特殊说明外,也是如此)。
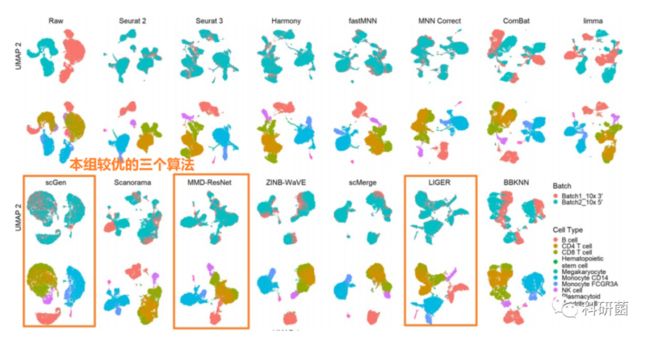
图4.14种批次效应校正算法的定性评价:使用UMAP可视化技术对“dataset5”(人外周血单个核细胞)进行校正
图4:scGen、MMD-ResNet和LIGER的降维后亚群聚类情况较好。
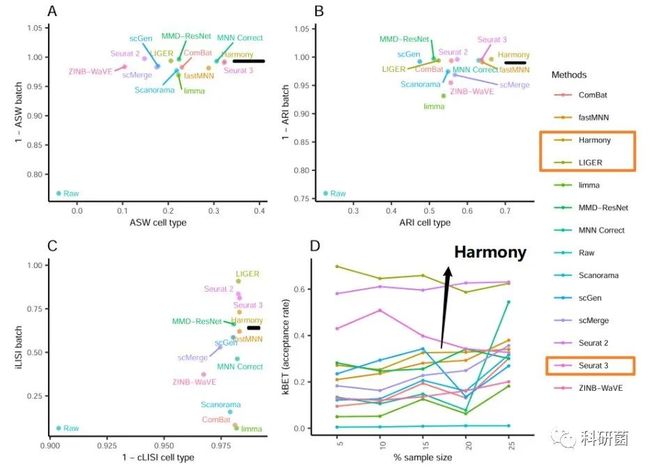
图5.使用4个评估指标对“dataset5”的14种批次效应校正算法进行定量评估
图5.结果显示Harmony、Seurat 3、LIGER去批次效应结果较好。
小结:对于这两个dataset(人PBMCs和鼠细胞图谱),Harmony、Seurat 3和LIGER是首选的三种算法。
2.2情形二:每个批次的细胞类型不完全相同
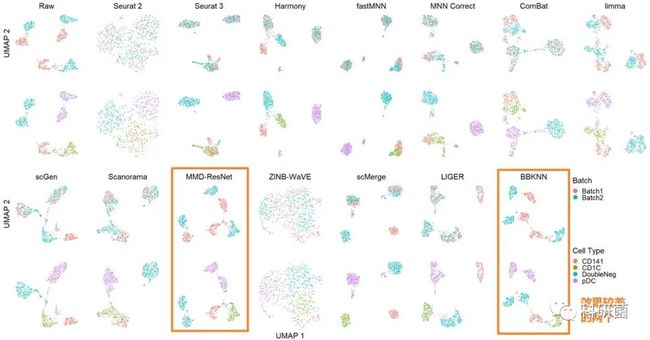
图6.利用UMAP可视化技术对”dataset1(人树突状细胞)“的14种批次效应校正算法进行评估
图6:dataset1在不同的批次中存在两个高度相似的细胞类型。
对可视化图的检验表明,大多数算法可以将两个批次的细胞混合在一起(图6)。不过,limma使两个批次的细胞簇接近,但没有实现混合,而MMD-ResNet和BBKNN无法混合常见类型的细胞簇。
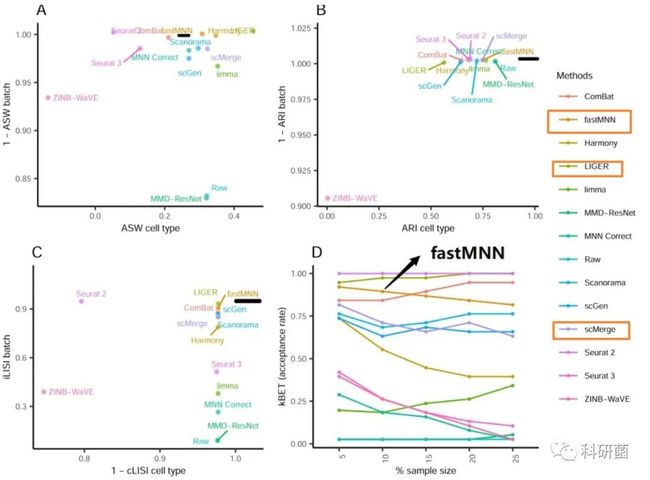
图7.使用4个评估指标对dataset1的14种批次效应效应校正算法进行定量评估
图7:对于dataset1,综合四项指标,fastMNN是最优的算法,LIGER和scMerge分别排在第二位和第三位。
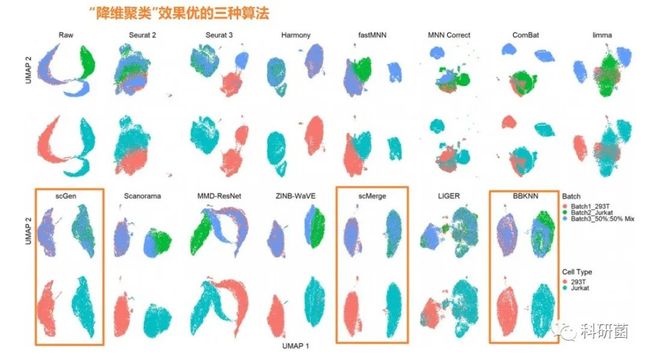
图8.使用UMAP可视化技术对dataset6的14种批次效应校正算法进行评估
图8:dataset6只包含两个细胞类型。
scGen、scMerge和BBKNN的降维聚类效果较好。
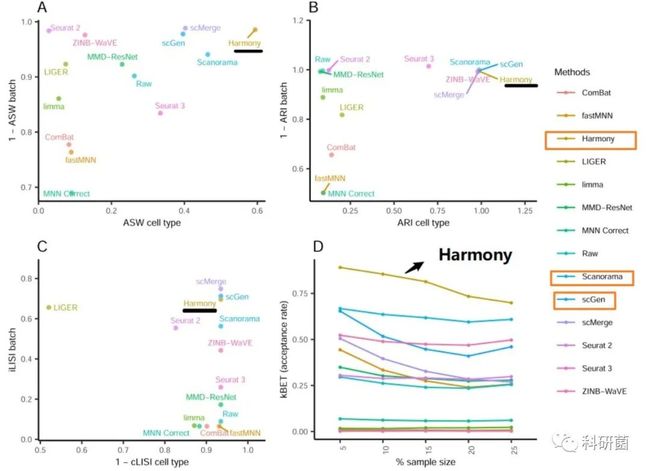
图9.使用4个评估指标对dataset6的14种批次效应效果校正算法进行定量评估
图9:综合4个评价指标来看,Harmony是最优算法,其次是Scanorama和scGen。
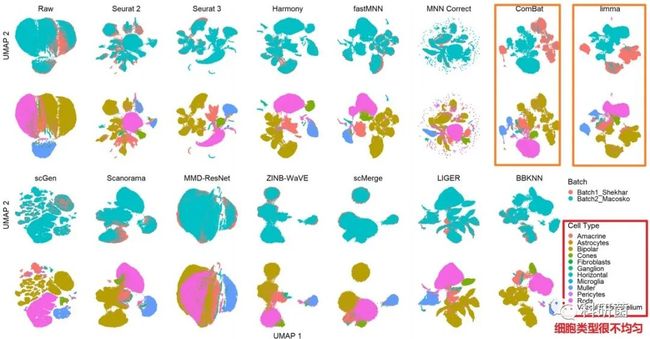
图10.利用UMAP可视化技术对dataset7(小鼠视网膜细胞)的14种批次效应校正算法进行定量评价 图10:dataset7的不同批次中,细胞类型很不均匀。
此次处理结果显示,ComBat和limma处理后的降维聚类效果较优。
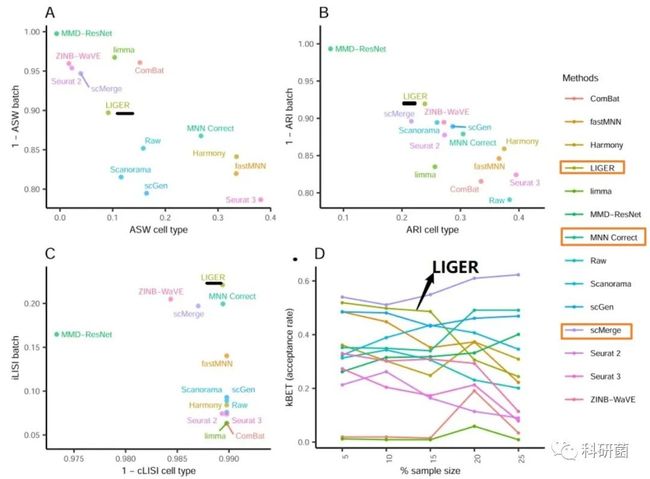
图11.使用ASW、ARI、LISI和kBET四个评估指标对dataset7的14种批次效应评估
图11:LIGER是此次最优的算法,接着是MNN Correct和scMerge。
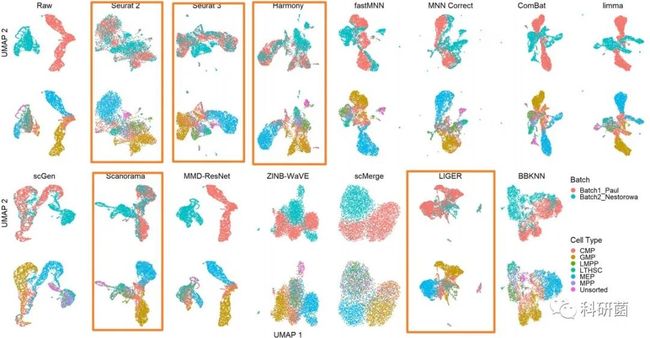
图12.利用UMAP可视化技术对dataset10(小鼠造血干细胞和祖细胞)的14种批次效应校正算法进行定量评价
图12:Seurat 2、Seurat 3、Harmony、Scanorama和LIGER处理的降维聚类效果较优。
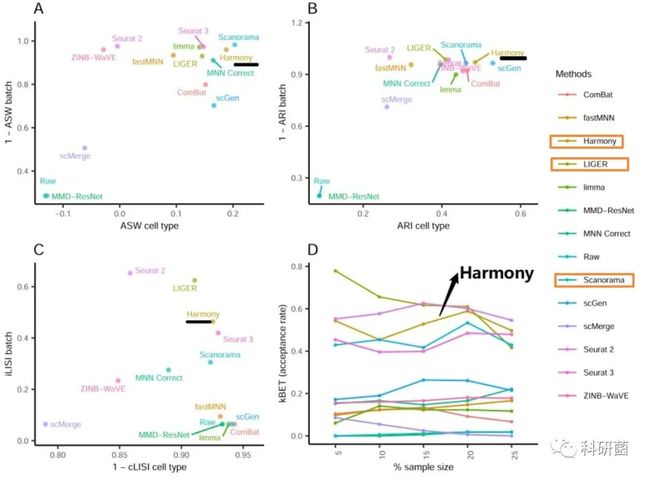
图13.使用ASW、ARILISI和kBET四个评估指标对dataset10的14种批次效应校正算法进行定量评估
图13:综合四个指标来看,Harmony、Scanorama和LIGER是该dataset的较优算法。
小结:
在情形二中,作者在四个不同的dataset上评估了14种批次效应校正算法。
虽然没有一种算法对所有dataset都是最优的,但LIGER是dataset1,7,10的较优算法,而scMerge在dataset1,6,7中排名第三。Harmony在dataset6和10中排名第一,而Scanorama在dataset6和10中排名第二。
基于这些结果,LIGER是这个情形的较优算法。
2.3情形三:有多个批次
这个情形测试了多个批次下的批次效应校正能力。
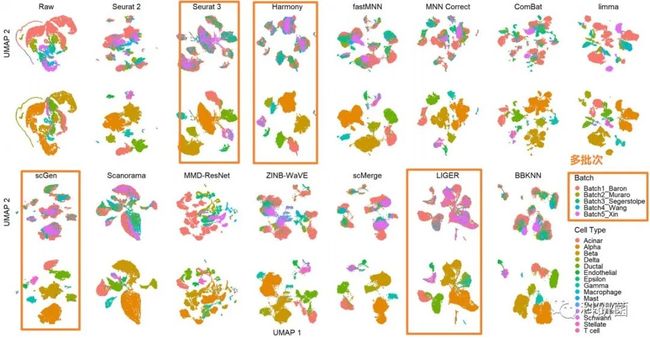
图14.使用UMAP可视化技术对dataset4(人胰腺细胞)的14种批次效应校正算法进行定性评价
图14:dataset4的人胰腺细胞包括五个批次。
t-SNE和UMAP图显示,Seurat 3、Harmony、scGen和LIGER处理后的降维聚类效果更优。
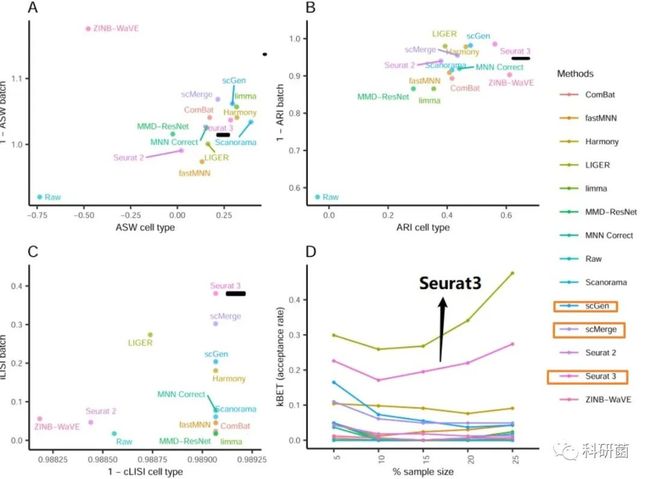
图15.使用ASW、ARI、LISI和kBET四个评估指标对dataset4的14种批次效应效应校正算法进行定量评估
图15:综合四项指标,Seurat 3是较优的算法,其次是scGen和scMerge。
前面情形2中分析的dataset6(也包括了两个以上的批次)前三名分别是Harmony、Scanorama和scGen, scMerge排在第四。
所以综合dataset4、6的评估情况来看,作者给出的建议是:
对于已标记细胞类型的dataset,建议使用scGen;
对于未标记细胞类型的dataset,推荐使用Seurat 3和Harmony。
2.4情形四:处理的数据集很大
在这个情形中,作者在两个大dataset(8、9)上测试了这些算法。
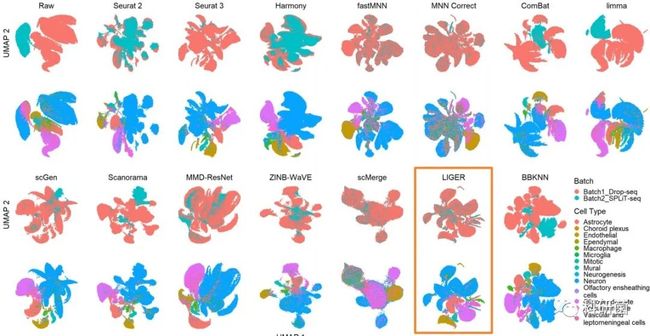
图16.用UMAP可视化技术对dataset8(小鼠大脑)的14种批次效应校正算法进行定量评价
图16:只有LIGER在实现分批混合的同时,保持了较好的细胞类型分离。
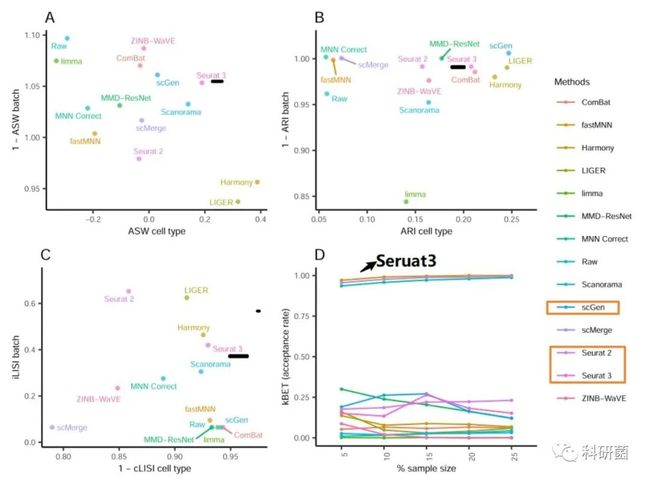
图17.使用ASW、ARI、iLISI和kBET四个评估指标对dataset8的14种批次效应效应校正算法进行定量评估
图17:综合四项指标,Seurat 3排名第一,紧随其后的是scGen和Seurat 2。
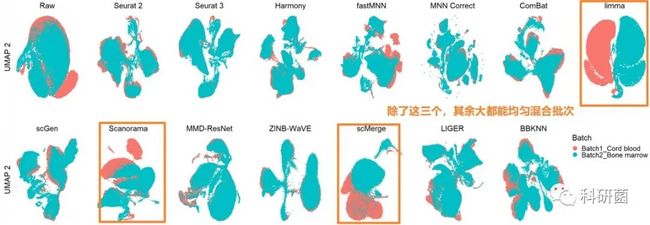
图18.使用UMAP可视化技术对dataset9(人类细胞图谱)的14种批次效应校正算法进行定量评价
图18:dataset9由两个数据批次组成,每个数据批次来自不同的组织。由于缺乏细胞类型信息,只能评估批次混合能力。
除了scMerge、limma和Scanorama,大多数算法都能够均匀混合批次。
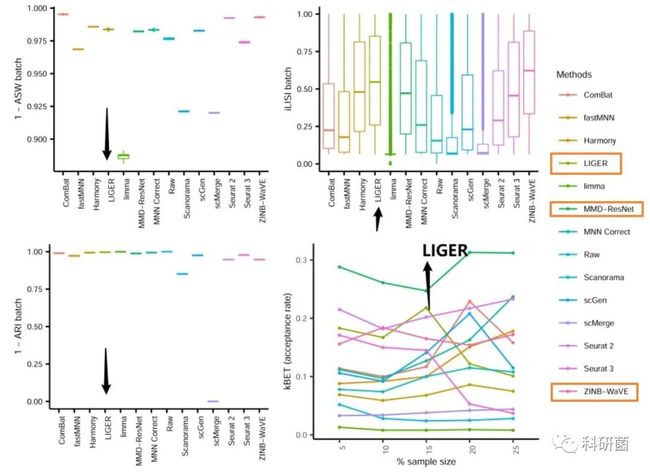
图19.使用ASW、ARI、LISI和kBET四种评估指标对dataset9的14种批次效应效应校正算法进行定量评估
图19:综合四项指标,LIGER、ZINB-WaVE、MMD-ResNet是依次排名前三的算法。
因此这三种算法都被推荐用于大型的dataset。
2.5情形五:DEG评估
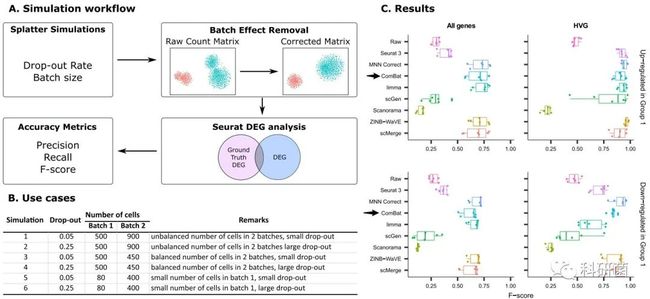
图20.利用模拟dataset和差异基因表达分析评价八种批次效应校正算法 图20A:作者按所示的DEG分析工作流程,对8个算法进行了评估。
使用Splatter包生成6组具有预定义批次效应效果和差异基因表达谱的模拟数据。
使用Seurat包对校正后的数据进行差异基因表达分析。
批次效应校正的矩阵中识别的差异表达基因(DEGs)与ground truth DEGs进行比较,并计算精度、Recall和F-score等指标。
图20B:为图20A中用到的6个模拟dataset,并对drop-out值和批次的情况作了展示。
图20C:计算了上调和下调基因的F-score。根据F-score,MNN Correct,ZINB-WaVE,ComBat和scMerge是表现最好的方法。
简单来说,若想获得一个用于下游分析批次效应校正矩阵的话,ComBat、MNN Correct、ZINB-WaVE和scMerge是作者推荐的算法。
3.整合上述分析结果
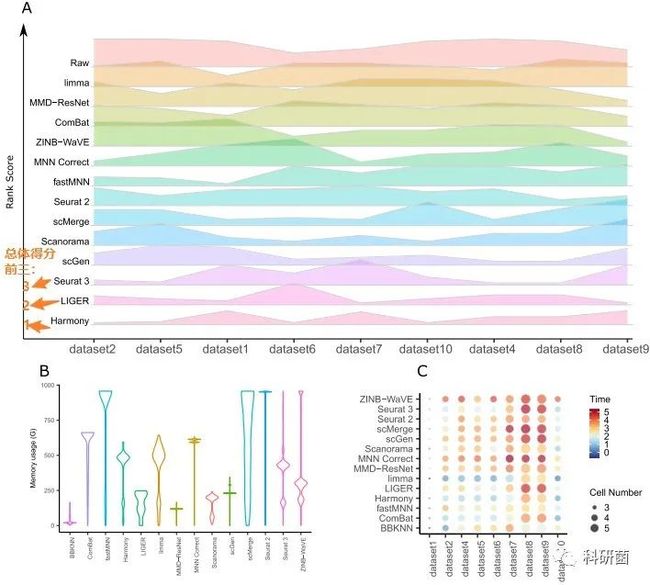
图21.十四种批次效应校正算法的有效性和效率
图21A:根据ASW、ARI、LISI和kBET指标对算法进行评估,然后使用秩和算法对所有指标进行排序。
山脊线的高度表示不同dataset的rank和score,rank和score越低表示性能越好。即出现在底部的Harmony、LIGER和Seurat 3是总体得分最高的前三算法。
图21B:作者举例了对于dataset8的十四种算法的内存使用情况。
图21C:展示了14种算法处理时需要的时间。
▼▼是否遗漏了往期精彩生信解析没看呢?▼▼
还没发论文?2020年医学生信分析有这些!
关注科研菌回复"1"即可获取"28G全网最全科研绘图素材"、"谷歌上网助手"(梯子)和"科研常用软件合集"、“肿瘤/消化内科指南”、"考研复试大礼包";回复2020,可获得2020年生信套路合集;回复“单细胞文献”,可获得单细胞文献合集(均无需转发/集赞)