https://hunch.net/~beygel/deep_rl_tutorial.pdf
https://icml.cc/2016/tutorials/deep_rl_tutorial.pdf
Tutorial: Deep Reinforcement Learning
David Silver, Google DeepMind
教程:深度强化学习
Reinforcement Learning in a nutshell
RL is a general-purpose framework for decision-making
RL is for an agent with the capacity to act
Each action influences the agent’s future state
Success is measured by a scalar reward signal
Goal: select actions to maximise future reward
简而言之,强化学习
强化学习是做出决策的通用框架
强化学习适用于具有行动能力的代理
每个动作都会影响代理的未来状态
成功由标量奖励信号衡量
目标:选择行动以最大化未来的回报
Deep Learning in a nutshell
DL is a general-purpose framework for representation learning
Given an objective
Learn representation that is required to achieve objective
Directly from raw inputs
Using minimal domain knowledge
简而言之,深度学习
深度学习是用于表示学习的通用框架
给定一个目标
学习为了实现目标所需要的表达
直接从原始输入
使用最少的领域知识
Deep Reinforcement Learning: AI = RL + DL
We seek a single agent which can solve any human-level task
RL defines the objective
DL gives the mechanism
RL + DL = general intelligence
深度强化学习:人工智能 = 强化学习 + 深度学习
我们寻找一个单一的代理,它可以解决任何人类级别的任务
强化学习定义了目标
深度学习给出了机制
强化学习 + 深度学习 = 一般智力
Examples of Deep RL @DeepMind
Play games: Atari, poker, Go, ...
Navigate worlds: 3D worlds, Labyrinth, ...
Control physical systems: manipulate, walk, swim, ...
Interact with users: recommend, optimise, personalise, ...
深度强化学习的示例 @DeepMind
玩游戏:Atari,扑克,Go,...
导航世界:3D世界,迷宫,...
控制物理系统:操纵,行走,游泳,...
与用户互动:推荐,优化,个性化,...
Introduction to Deep Learning 深度学习介绍
Deep Representations
A deep representation is a composition of many functions
深度表示是许多函数的组合

Its gradient can be backpropagated by the chain rule
它的梯度可以用链式法则反向传播

Deep Neural Network 深度神经网络
A deep neural network is typically composed of:
Linear transformations
Non-linear activation functions
A loss function on the output, e.g.
Mean-squared error
Log likelihood
深度神经网络通常包括:
线性变换
非线性激活函数
在输出的损失函数
均方误差
对数似然
通过随机梯度下降训练神经网络
Sample gradient of expected loss
预期损失的样本梯度
~
Adjust w down the sampled gradient
调整w向下的采样梯度
沿采样梯度向下调整w
Weight Sharing 权重共享
Recurrent neural network shares weights between time-steps
循环神经网络在时间步长之间共享权重

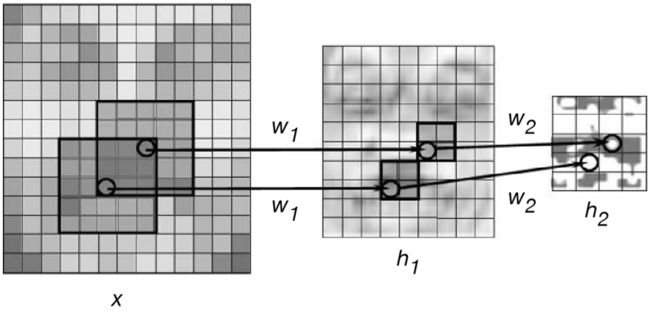
Convolutional neural network shares weights between local regions
卷积神经网络在局部区域之间共享权重
Introduction to Reinforcement Learning 强化学习介绍
Many Faces of Reinforcement Learning
强化学习的许多方面

Agent and Environment 代理与环境

At each step
the agent:
Executes action
Receives observation
Receives scalar reward
The environment:
Receives action
Emits observation
Emits scalar reward
State 状态
Experience is a sequence of observations, actions, rewards
The state is a summary of experience
In a fully observed environment
Major Components of an RL Agent 强化学习代理的主要组件
An RL agent may include one or more of these components:
Policy: agent’s behaviour function
Value function: how good is each state and/or action
Model: agent’s representation of the environment
强化学习代理可以包括以下一个或多个组件:
policy:代理的行为函数
价值函数:每个状态和/或动作有多好
模型:代理对环境的表示
Policy
A policy is the agent’s behaviour
It is a map from state to action:
Deterministic policy:
Stochastic policy:
policy是代理的行为
这是从状态到行动的映射:
确定的policy:
随机的policy:
Value Function
A value function is a prediction of future reward
“How much reward will I get from action a in state s?”
Q-value function gives expected total reward
价值函数是对未来奖励的预测
“在状态s下,代理将从行动a中获得多少奖励?”
Q值函数给出预期的总回报
from state s and action
under policy
with discount factor
Value functions decompose into a Bellman equation
价值函数分解为Bellman方程
Optimal Value Functions
An optimal value function is the maximum achievable value
最佳价值函数是最大可实现值
Once we have we can act optimally,
一旦有了,我们就可以采取最佳行动,
Optimal value maximises over all decisions. Informally:
最优价值使所有决策最大化。 Informally:
Formally, optimal values decompose into a Bellman equation
Formally,最优值分解为Bellman方程
Model
Model is learnt from experience
Acts as proxy for environment
Planner interacts with model
e.g. using lookahead search
模型是从经验中学习得到的
作为环境的代理
计划者与模型交互
例如,使用前瞻性搜索
Approaches To Reinforcement Learning
强化学习的方法
Value-based Reinforcement Learning
Estimate the optimal value function
This is the maximum value achievable under any policy
Policy-based Reinforcement Learning
Search directly for the optimal policy
This is the policy achieving maximum future reward
Model-based Reinforcement Learning
Build a model of the environment
Plan (e.g. by lookahead) using model
基于value的强化学习
估计最优value函数
这是任何policy下可实现的最大value
基于policy的强化学习
直接搜索最优policy
这是实现最大未来奖励的policy
基于模型的强化学习
建立环境模型
使用模型计划(例如,by lookahead)
Deep Reinforcement Learning
Use deep neural networks to represent
使用深度神经网络来表示
Value function
Policy
Model
Optimise loss function by stochastic gradient descent
利用随机梯度下降优化损失函数
model-free 不理解环境
从环境中得到反馈然后从中学习
Q learning, Sarsa, Policy Gradients
model-based 理解环境
为真实世界建模,多出了一个虚拟环境

Policy-Based 基于策略
通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动
能选取连续的动作
Policy Gradients
Value-Based 基于价值
输出是所有动作的价值, 选择价值最高的动作
不能选取连续的动作
Q learning
Sarsa
Actor-Critic结合这两类方法的优势
actor 会基于概率做出动作
critic 会对做出的动作给出动作的价值
在原有的Policy Gradients上加速了学习过程.

回合更新 monte carlo
游戏开始后, 要等待游戏结束, 然后再总结这一回合中的所有转折点, 再更新行为准则
Monte-carlo learning 和基础版的Policy Gradients等
单步更新 temporal difference 时间差分
在游戏进行中每一步都在更新, 不用等待游戏的结束, 这样就能边玩边学习了
Q learning, Sarsa , 升级版的Policy Gradients等
在线学习 on policy 同策略
代理和环境交互过程中所选择的动作=计算评估函数的过程中选择的动作
必须本人在场, 并且一定是本人边玩边学习
Sarsa 、Sarsa lambda
离线学习 off policy 异策略
代理和环境交互过程中所选择的动作≠计算评估函数的过程中选择的动作
可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则
同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习.
不必要边玩边学习, 可以白天先存储下来玩耍时的记忆, 然后晚上通过离线学习来学习白天的记忆
Q learning、Deep-Q-Network
monte carlo model free
强化学习入门 第三讲 monte carlo
机器学习 强化学习 北京理工大学
不清楚markov决策过程的真实状态转移概率或即时奖励
在现实的强化学习任务中,环境的转移概率、奖励函数往往很难得知, 甚至很难得知环境中有多少状态。
免模型学习:学习算法不再依赖于环境建模
通常情况下某个状态的价值=在多个episode中以该状态算得到的所有奖励的平均
每条episode:一条从起始状态到结束状态的经历
使用多次采样,然后求取平均累计奖赏作为期望累计奖赏的近似。
First-visit
在计算状态s处的值函数时,只利用每个episode中第一次访问到状态s时返回的值
Every-visit
在计算状态s处的值函数时,利用所有访问到状态s时的奖励返回
每进入一个episode
每碰到一次,可以计算平均价值
每个episode结束才能更新
需要大量episode才比较准确
需要采样一个完整的轨迹来更新值函数,效率较 低,此外该算法没有充分利用强化学习任务的序贯决策结构。
直接对状态动作值函数Q(s,a)进行估计,每采样一条轨迹,就根据轨迹中的所有“状态-动作”利用下面的公式对来对值函数进行更新。
(,)=((,) ∗(,) + ) / ((,) + 1)
temporal difference 时间差分 model free
强化学习入门 第四讲 时间差分
机器学习 强化学习 北京理工大学
当n=1时,temporal difference
当n=正无穷时,monte carlo
n步temporal difference
当=0时,temporal difference


Value-Based 深度强化学习
Q-Networks
Represent value function by Q-network with weights w
用权重为w的Q网络表示value函数

Q-Learning
Optimal Q-values should obey Bellman equation
最优Q值应遵循Bellman方程
把右手边作为一个目标
Minimise MSE loss by stochastic gradient descent
通过随机梯度下降,最小化均方误差损失
Converges to using table lookup representation
使用表查找表示形式收敛到
But diverges using neural networks due to:
- Correlations between samples
- Non-stationary targets
但是由于以下原因,使用神经网络不收敛:
- 样本之间的相关性
- 非平稳目标
Q-Learning
ε贪心
如果0
(,) = 随机从中选取动作, 以概率
Q值表
state为行,action为列,reward为元素
学习率*(Q的真实值 - Q的估计值)
如果学习率越大,那么新估计值代替旧估计值的程度也越大
任意初始化Q(s,a)
for 每个episode
初始化s
重复 episode中的每一步
从s中选择a,使用从Q中得到的策略,比如ε贪心
采取动作a,观察到R和s_
Q(s,a)←Q(s,a)+alpha*[R+gamma*max(Q(s_, a_))-Q(s,a)]
s←s_
直到s终止
endfor

off policy 异策略
在选择动作执行的时候采取的策略 ≠ 在更新Q表的时候采取的策略
行动策略是ε-greedy策略
更新Q表的策略是贪婪策略
sarsa state-action-reward-state'-action'
任意初始化Q(s,a)
for 每个episode
初始化s
从s中选择a,使用从Q中得到的策略,比如ε贪心
重复 episode中的每一步
采取动作a,观察到R和s_
从s_中选择a_,使用从Q中得到的策略,比如ε贪心
Q(s,a)←Q(s,a)+alpha*[R+gamma*Q(s_, a_)-Q(s,a)]
s←s_; a←a_
直到s终止
endfor
on policy 同策略
在选择动作执行的时候采取的策略 = 在更新Q表的时候采取的策略
行动策略是ε-greedy策略
评估策略是ε-greedy策略
Deep Q-Networks (DQN): Experience Replay
机器学习 强化学习 北京理工大学
利用神经网络近似模拟函数Q(s,a),输入是问题的状态,输出是每个动作a对应的Q值,然后依据Q值大小选择对应状态执行的动作,以完成控制。
学习流程:
- 状态s输入,获得所有动作对应的Q值Q(s,a);
- 选择对应Q值最大的动作a′并执行;
- 执行后环境发生改变,并能够获得环境的奖励r;
- 利用奖励r更新Q(s,a′)--强化学习
利用新的Q(s,a′)更新网络参数—监督学习


初始化回放记忆D,容量N。用于存放采集的(s_t,a_t,r_t,s_{t+1})状态 转移过程,用于网络参数 的训练
初始化动作值函数Q,随机权重θ。随机初始化神经网络的参数
初始化target动作值函数Q_,权重θ_=θ
for episode=1~M
初始化序列s_1={x_1}和预处理序列φ_1=φ(s_1)
获取环境的初始状态(x是采集的图像,使用图像作为agent的状态;预处理过程是使用几张图像代表当前状态,这里可以先忽略掉)
for t=1~T
ε贪心选择a_t(使用ε概率随机选取动作或使用1- ε的概率根据神经网络的输出选择动作a_t=max_a Q(s_t,a; θ_i))
采取动作a_t,观察到r_t和x_{t+1}
设置s_{t+1}=s_t,a_t,x_{t+1}和预处理φ_{t+1}=φ(s_{t+1})
保存transition(φ_t,a_t,r_t,φ_{t+1})在D中
从D中采样transition(φ_j,a_j,r_j,φ_{j+1})的随机minibatch
更新状态值函数的值
如果episode在j+1步终止,那么设置y_j=r_j
如果episode在j+1步不终止,那么设置y_j=r_j+gamma*max(Q_(φ_{j+1},a_;θ_))
使用监督学习方法更新网络的参数。执行一个梯度下降步在(y_j - Q_(φ_j,a_j;θ))^2,关于网络参数θ
每C步重置Q_=Q
endfor
endfor

DQN计算每个操作的期望值,然后选择可以获得最大期望值的操作。它吸收了深度学习网络的特征,因此可以作为深度自然网络进行训练,并提高了Q学习的学习能力。
To remove correlations, build data-set from agent’s own experience
要消除相关性,根据代理自身的经验构建数据集

Sample experiences from data-set and apply update
从数据集中采样经验并应用更新
To deal with non-stationarity, target parameters w− are held fixed
为了处理非平稳性,将目标参数固定
深度强化学习 in Atari

End-to-end learning of values from pixels s
Input state s is stack of raw pixels from last 4 frames
Output is for 18 joystick/button positions
Reward is change in score for that step
从像素s端到端学习值
输入状态s是最近4帧的原始像素的堆栈
输出为18个操纵杆/按钮位置的
奖励是该步骤得分的变化
Network architecture and hyperparameters fixed across all games
固定在所有游戏中的网络体系结构和超参数


Deep Q-Networks Atari Demo
Deep Q-Networks paper 论文
www.nature.com/articles/nature14236
[1312.5602] Playing Atari with Deep Reinforcement Learning
Deep Q-Networks source code 源代码
sites.google.com/a/deepmind.com/dqn/
Improvements since Nature DQN
自 Nature DQN 以来的改进
尽管DQN,DDQN,决斗DQN 和 Prioritised replay DQN在离散动作问题中具有出色的性能,但它们具有相同的缺点,不适合处理连续动作空间。由于连续动作的动作空间很大,因此无法计算每个动作的Q值然后做出动作选择。 当环境变得复杂而惩罚变得严厉时,他们将花费大量的训练步骤来获得最佳解决方案。
Double Deep Q-Networks
[1509.06461] Deep Reinforcement Learning with Double Q-learning
Q-Learning 中有 Qmax,Qmax 会导致 Q现实 当中的过估计 (overestimate)。在实际问题中,可能会发现DQN 的Q 值都超级大。这就是出现了 overestimate。
Double DQN对每个变量使用两个估计网络来解决DQN的过估计问题。而且可以加快“Q”网络的融合。 在某些离散问题上,它确实具有出色的性能。
一个Q网络用于选择动作,另一个Q网络用于评估动作,交替工作,解决upward-bias问题。
工作中如果有double-check,犯错的概率就能平方级别下降。
Remove upward bias caused by
Current Q-network w is used to select actions
Older Q-network w− is used to evaluate actions
消除由引起的向上偏差
当前的Q网络w用于选择动作
旧的Q网络w−用于评估动作
莫烦
两个网络有相同的结构,但内部的参数更新却有时差
因为神经网络预测Qmax本来就有误差,每次也向着最大误差的Q现实改进神经网络,就是因为这个Qmax导致了overestimate。
Double DQN的想法:引入另一个神经网络来抵消一些最大误差的影响
DQN中有两个神经网络,所以用Q估计的神经网络估计Q现实中Qmax(s',a')的最大动作值。然后用这个被Q估计估计出来的动作来选择Q现实中的Q(s')
有两个神经网络: Q_eval (Q估计中的), Q_next (Q现实中的)
DQN:Q_next = max(Q_next(s', a_all))
Double DQN:Q_next = Q_next(s', argmax(Q_eval(s', a_all)))
Prioritised replay
[1511.05952] Prioritized Experience Replay
具有Prioritised replay 记忆池,可以有效地学习有效信息。
Weight experience according to surprise
Store experience in priority queue according to DQN error
根据惊喜来对经验确定权重
根据DQN错误将经验存储在优先级队列中
Double Learning and Prioritized Experience Replay
replay加速训练过程,变相增加样本,并且能独立于当前训练过程中状态的影响
莫烦

batch 抽样的时候并不是随机抽样, 而是按照 Memory 中的样本优先级来抽
用到 TD-error, 也就是 Q现实 - Q估计 来规定优先学习的程度
如果 TD-error 越大, 就代表我们的预测精度还有很多上升空间, 那么这个样本就越需要被学习, 也就是优先级 p 越高

每个树枝节点只有两个分叉
每片树叶存储每个样本的优先级 p
节点的值是两个分叉的和
SumTree 的顶端就是所有 p 的和
抽样时将 p 的总和 除以 batch size, 分成(n=sum(p)/batch_size)那么多区间,
然后在每个区间里随机选取一个数。比如在第区间[21-28]里选到了24,然后从最顶上的42开始向下搜索。
左边的child 29>24,那么左边
左边的child 13<24,那么右边,并且把24变成变成 24-左边的child 13=11
左边的child 12>11,那么左边,即12当做这次选到的priority,并且也选择12对应的数据。
Duelling network 决斗网络
[1511.06581] Dueling Network Architectures for Deep Reinforcement Learning
决斗DQN可以加速Q网络的收敛。 而且,与DQN相比,它提高了优化的稳定性,并且在实践中效果更好。
Split Q-network into two channels
Action-independent value function
Action-dependent advantage function
将Q网络分成两个通道
与action无关的价值函数
与action有关的优势函数
Combined algorithm: 3x mean Atari score vs Nature DQN
组合算法:3x mean Atari score vs Nature DQN
莫烦
将每个动作的 Q 拆分成了 state 的 Value 加上 每个动作的 Advantage
因为有时候在某种 state, 无论做什么action, 对下一个 state 都没有多大影响,任何策略都不影响回报,显然需要剔除
DQN 神经网络输出的是每种动作的 Q值
Dueling DQN 神经网络输出的是每个动作的 Q值
V(s)与动作无关,A(s, a)与动作相关,是a相对s平均回报的相对好坏,是优势,解决reward-bias问题。
强化学习中真正关心的还是策略的好坏,更关系的是优势
General Reinforcement Learning Architecture (Gorila) 通用强化学习架构
10x faster than Nature DQN on 38 out of 49 Atari games
Applied to recommender systems within Google
在49个Atari游戏中,有38个比Nature DQN快10倍
应用于Google内的推荐系统
Asynchronous Reinforcement Learning 异步强化学习
Exploits multithreading of standard CPU
Execute many instances of agent in parallel
Network parameters shared between threads
Parallelism decorrelates data
Viable alternative to experience replay
Similar speedup to Gorila - on a single machine!
利用标准CPU的多线程
并行执行多个代理实例
线程之间共享的网络参数
并行去相关数据
经验回放的可行替代方案
类似于Gorila的加速,在单台机器上!
Policy-Based 深度强化学习
DQN虽然在Atari游戏问题中取得了巨大的成功,但适用范围还是在低维、离散动作空间。
- 如果把连续动作空间离散化,动作空间则会过大,极难收敛。划分本身也带来了信息损失。
- DQN只能给出一个确定性的action,无法给出概率值。
Deep Policy Networks
Represent policy by deep network with weights
通过具有权重的深度网络来表示policy
or
Define objective function as total discounted reward
将目标函数定义为总折扣奖励
Optimise objective end-to-end by SGD
i.e. Adjust policy parameters u to achieve more reward
通过随机梯度下降端到端优化目标
即调整policy参数以获得更多奖励
Policy Gradients
How to make high-value actions more likely:
如何更可能采取高价值的行动:
The gradient of a stochastic policy is given by
随机的策略的梯度 is given by
Deterministic Policy Gradient Algorithms
The gradient of a deterministic policy is given by
确定的策略的梯度 is given by
if a is continuous and Q is differentiable
如果a是连续的并且Q是可导的
莫烦
靠奖励来影响神经网络反向传递
观测信息让神经网络选择了左边的行为,进行反向传递,使左边的行为下次被选的可能性增加,但是奖惩信息表明这次的行为是不好的,那反向传递的时候减小力度,动作可能性增加的幅度减小。
观测信息让神经网络选择了右边的行为,进行反向传递,使右边的行为下次被选的可能性增加,但是奖惩信息表明这次的行为是好的,那反向传递的时候加大力度,动作可能性增加的幅度增加
policy gradient要输出不是 action 的 value, 而是具体的那一个 action,跳过了 value 这个阶段。输出的这个 action 可以是一个连续的值
在 状态 s 对所选动作 a 的吃惊度:delta(log(Policy(s,a)) * V)
如果Policy(s,a)概率越小,反向的log(Policy(s,a))(即-log(P))反而越大
如果Policy(s,a)很小的情况下,拿到了的R大,也就是大的V,那-delta(log(Policy(s,a)) * V)就更大,表示更吃惊。(选了一个不常选的动作,却发现原来它能得到了一个好的reward,那这次就得对参数进行一个大幅修改)
使用loss=-log(prob)*vt当做loss
上面提到了两种形式来计算neg_log_prob
第二个是第一个的展开形式
第一个形式是在神经网络分类问题中的cross-entropy
使用softmax和神经网络的最后一层logits输出和真实标签(self.tf_acts)对比的误差。并将神经网络的参数按照这个真实标签改进。
这显然和一个分类问题没有太多区别。
能将这个neg_log_prob理解成cross-entropy的分类误差。
分类问题中的标签是真实x对应的y
Policy gradient中,x是state,y就是它按照这个x所做的动作号码。所以也可以理解成它按照x做的动作永远是对的(出来的动作永远是正确标签),它也永远会按照这个“正确标签”修改自己的参数。
可是事实是他的动作不一定都是“正确标签”
这就是强化学习(Policy gradient)和监督学习(classification)的不同
为了确保这个动作真的是 “正确标签”, loss 在原本的 cross-entropy 形式上乘以 vt(用来表明这个 cross-entropy 算出来的梯度的值得信任的程度)
如果 vt 是负的, 或很小, 那么梯度不值得信任,应该向着另一个方向更新参数
如果 vt 是正的, 或很大, 那么梯度值得信任
Actor-Critic Algorithm (AC) 演员评论家算法
演员评论家有演员网络和评论家网络。
演员使用策略梯度函数,该函数负责生成动作并与环境交互。
评论家使用价值函数,该函数负责评估演员的表现并在下一阶段指导演员的行为。
它可以加速策略梯度函数的收敛,但这还不足以解决复杂的问题。
Estimate value function
Update policy parameters u by stochastic gradient ascent
通过随机梯度上升更新策略参数u
Asynchronous Advantage Actor-Critic (A3C)
异步优势演员评论家(A3C)
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning
不同于经验回放,异步优势演员评论家在环境的多个实例上异步地并行执行多个代理。这种并行性还decorrelate代理的数据,变成一个更加平稳的过程中,因为在任何给定的时间步,并行代理都会经历各种不同的状态。
Estimate state-value function
Q-value estimated by an n-step sample
通过n步样本估算的Q值
Actor is updated towards target
Critic is updated to minimise MSE with respect to target
评论家已更新,以最小化关于目标的均方误差
4x mean Atari score vs Nature DQN
Asynchronous Advantage Actor-Critic (A3C) in Labyrinth
迷宫中的异步优势演员评论家(A3C)

End-to-end learning of softmax policy from pixels
Observations are raw pixels from current frame
State is a recurrent neural network (LSTM)
Outputs both value and softmax over actions
Task is to collect apples (+1 reward)
从像素端到端学习softmax policy
观察值是来自当前帧的原始像素
状态是循环神经网络(LSTM)
输出动作的值和softmax
任务是收集苹果(+1奖励)
Demo:
www.youtube.com/watch?v=nMR5mjCFZCw&feature=youtu.be
Labyrinth source code (coming soon):
迷宫源代码(即将推出):
sites.google.com/a/deepmind.com/labyrinth/
Deep Reinforcement Learning with Continuous Actions
具有连续动作的深度强化学习
[1509.02971] Continuous control with deep reinforcement learning
How can we deal with high-dimensional continuous action spaces?
Can’t easily compute
Actor-critic algorithms learn without max
Q-values are differentiable with respect to a
Deterministic policy gradients exploit knowledge of
我们如何处理高维连续动作空间?
无法轻松计算
演员评论家算法无需max学习
Q值关于a是可导的
确定的policy梯度利用的知识
Deep DPG
深度确定性策略梯度(DDPG)可以使用与演员评论家相同的超参数和网络结构,通过低维观测(例如 cartesian coordinates or joint angles)来学习所有任务的竞争策略。
深度确定性策略梯度是一种off-policy算法,其 replay buffer 可能很大,从而使该算法可从一组不相关的过渡学习中受益。
DPG is the continuous analogue of DQN
Experience replay: build data-set from agent’s experience
Critic estimates value of current policy by DQN
DPG是DQN的连续类似物
经验回放:根据代理的经验建立数据集
评论家通过DQN估算当前policy的价值
To deal with non-stationarity, targets u−,w− are held fixed
Actor updates policy in direction that improves Q
为了处理非平稳性,将目标u−,w−固定
演员更新policy以改善Q
In other words critic provides loss function for actor
换句话说,评论家为演员提供损失函数
DPG in Simulated Physics
Physics domains are simulated in MuJoCo
End-to-end learning of control policy from raw pixels s
Input state s is stack of raw pixels from last 4 frames
Two separate convnets are used for Q and π
Policy π is adjusted in direction that most improves Q
在MuJoCo中模拟物理域
从原始像素s开始对控制策略进行端到端学习
输入状态s是最近4帧的原始像素堆栈
两个单独的卷积用于和
policy被调整,朝着最能改善Q的方向

Asynchronous Advantage Actor-Critic (A3C) in Simulated Physics Demo
模拟物理演示中的异步优势演员评论家(A3C)
Asynchronous RL is viable alternative to experience replay
Train a hierarchical, recurrent locomotion controller
Retrain controller on more challenging tasks
异步强化学习是经验回放的可行替代方案
训练一个分层的循环运动控制器
在更具挑战性的任务上对控制器进行再次训练

Fictitious Self-Play (FSP)
Can deep RL find Nash equilibria in multi-agent games?
Q-network learns “best response” to opponent policies
By applying DQN with experience replay
c.f. fictitious play
深度强化学习能在多代理游戏中找到Nash均衡吗?
Q-Network学习对对手policy的“最佳反应”
通过将DQN与经验回放一起应用
c.f. 虚拟play
Policy network learns an average of best responses
policy网络学习最佳响应的平均
Actions a sample mix of policy network and best response
Actions policy网络和最佳响应的样本组合
Neural FSP in Texas Hold’em Poker
Heads-up limit Texas Hold’em
NFSP with raw inputs only (no prior knowledge of Poker)
vs SmooCT (3x medal winner 2015, handcrafted knowlege)
德州扑克中的神经虚拟Self-Play
Heads-up 限制德州扑克
神经虚拟Self-Play仅具有原始输入(之前没有扑克知识)
vs SmooCT(2015年获得3枚奖牌,手工知识)

总结
强化学习的策略梯度方法可以很好地解决连续动作问题。
深度确定性策略梯度(DDPG)和异步优势演员评论家(A3C)源自演员评论家(AC)网络。
深度确定性策略梯度(DDPG)和异步优势演员评论家(A3C)切断了数据相关性并加速了收敛,解决了演员评论家(AC)的最大问题。
[1811.02073] QUOTA: The Quantile Option Architecture for Reinforcement Learning
Model-Based 深度强化学习
markov 决策过程(MDP)
机器学习 强化学习 北京理工大学
强化学习入门 第一讲 MDP
markov property
系统的下一个状态仅与当前状态有关,而与以前的状态无关。
markov 过程
是一个二元组(S,P),S是有限状态集合, P是状态转移概率
状态转移概率矩阵:
markov 决策过程(MDP)
元组
S为有限的状态集
A为有限的动作集
P为状态转移概率
R为回报函数
为折扣因子,用来计算累积回报。
注意,跟markov 过程不同的是,markov 决策过程的状态转移概率是包含动作的,即:
s∈S:有限状态state集合,s表示某个特定状态
a∈A:有限动作action集合,a表示某个特定动作
T(S, a, S’)~Pr(s’|s,a):状态转移模型, 根据当前状态s和动作a预测下一个状态s,这里的Pr表示从s采取行动a转移到s’的概率
R(s,a):表示agent采取某个动作后的即时奖励,它还有R(s,a,s’), R(s)等表现形式
Policy π(s)→a:根据当前state来产生action,可表现为a=π(s)或 π(a|s) = P(a|s),后者表示某种状态下执行某个动作的概率
强化学习的目标:给定一个markov 决策过程,寻找最优策略,即总回报最大
策略:状态到动作的映射。给定状态时,动作集上的一个分布,即
折扣累积回报:
状态值函数:
状态值函数V表示执行策略π能得到的累计折扣奖励:
状态动作值函数:
状态动作值函数Q(s,a)表示在状态s下执行动作a能得到的累计折扣奖励:
状态值函数的Bellman方程:
最后一个等号的补充证明:
状态动作值函数的Bellman方程:
策略迭代
策略评估:
在当前的策略中更新各状态的值函数,如果达到迭代次数或者值函数收敛就不再迭代
策略更新:
基于当前值函数得到最优策略
策略迭代是累计平均的计算方式
策略迭代更接近于样本的真实分布
状态动作值函数
值迭代
每次值迭代都找到让当前值函数最大的更新方式,并且用这种方式更新值函数。直到值函数不再变化。
值迭代是单步最好的方式
值迭代速度更快,尤其是在策略空间较大的时候
最优状态值函数的Bellman最优方程:
最优状态动作值函数的Bellman最优方程:
在得到最优值函数之后,可以通过值函数的值得到状态s时应该采取的动作a:
探索和利用
探索:做你以前从来没有做过的事情,以期望获得更高的回报。 Demo: generative model of Atari What if we have a perfect model? General, stable and scalable RL is now possible
利用:做你当前知道的能产生最大回报的事情
ε贪心
如果0Learning Models of the Environment
Challenging to plan due to compounding errors
Errors in the transition model compound over the trajectory
Planning trajectories differ from executed trajectories
At end of long, unusual trajectory, rewards are totally wrong
环境的学习模型
演示:Atari的生成模型
由于组合错误,计划具有挑战性
过渡模型的误差在轨迹上组合
规划轨迹不同于执行轨迹
在漫长而不寻常的发展轨迹的尽头,奖励是完全错误的Deep Reinforcement Learning in Go
e.g. game rules are known
如果我们有一个完美的模型怎么办?
例如 游戏规则是已知的
AlphaGo paper:
www.nature.com/articles/nature16961
AlphaGo resources:
deepmind.com/alphago/Conclusion
Using deep networks to represent value, policy, model
Successful in Atari, Labyrinth, Physics, Poker, Go
Using a variety of deep RL paradigms
通用,稳定和可扩展的强化学习现在成为可能
使用深层网络表示价值,policy,模型
在Atari,迷宫,物理,扑克,围棋中获得成功
使用多种深度强化学习范例