iOS 底层原理 文章汇总
本文是队列创建、同步/异步函数、单例、信号量以及调度组的底层原理分析
队列创建
在上一篇文章iOS-底层原理 26:GCD 之 函数与队列中,我们理解了队列与函数,知道队列的创建时通过GCD中的dispatch_queue_create方法,下面我们在libdispatch.dylib去探索队列是如何创建的(下载链接)
底层源码分析
- 在源码中搜索
dispatch_queue_create
dispatch_queue_t
dispatch_queue_create(const char *label, dispatch_queue_attr_t attr)
{
return _dispatch_lane_create_with_target(label, attr, DISPATCH_TARGET_QUEUE_DEFAULT, true);
}
- 进入
_dispatch_lane_create_with_target(
DISPATCH_NOINLINE
static dispatch_queue_t
_dispatch_lane_create_with_target(const char *label, dispatch_queue_attr_t dqa,
dispatch_queue_t tq, bool legacy)
{
// dqai 创建 -
dispatch_queue_attr_info_t dqai = _dispatch_queue_attr_to_info(dqa);
//第一步:规范化参数,例如qos, overcommit, tq
...
//拼接队列名称
const void *vtable;
dispatch_queue_flags_t dqf = legacy ? DQF_MUTABLE : 0;
if (dqai.dqai_concurrent) { //vtable表示类的类型
// OS_dispatch_queue_concurrent
vtable = DISPATCH_VTABLE(queue_concurrent);
} else {
vtable = DISPATCH_VTABLE(queue_serial);
}
....
//创建队列,并初始化
dispatch_lane_t dq = _dispatch_object_alloc(vtable,
sizeof(struct dispatch_lane_s)); // alloc
//根据dqai.dqai_concurrent的值,就能判断队列 是 串行 还是并发
_dispatch_queue_init(dq, dqf, dqai.dqai_concurrent ?
DISPATCH_QUEUE_WIDTH_MAX : 1, DISPATCH_QUEUE_ROLE_INNER |
(dqai.dqai_inactive ? DISPATCH_QUEUE_INACTIVE : 0)); // init
//设置队列label标识符
dq->dq_label = label;//label赋值
dq->dq_priority = _dispatch_priority_make((dispatch_qos_t)dqai.dqai_qos, dqai.dqai_relpri);//优先级处理
...
//类似于类与元类的绑定,不是直接的继承关系,而是类似于模型与模板的关系
dq->do_targetq = tq;
_dispatch_object_debug(dq, "%s", __func__);
return _dispatch_trace_queue_create(dq)._dq;//研究dq
}
_dispatch_lane_create_with_target 分析
-
【第一步】通过
_dispatch_queue_attr_to_info方法传入dqa(即队列类型,串行、并发等)创建dispatch_queue_attr_info_t类型的对象dqai,用于存储队列的相关属性信息
 dispatch_queue_create底层分析-1
dispatch_queue_create底层分析-1 【第二步】设置队列相关联的属性,例如服务质量qos等
-
【第三步】通过
DISPATCH_VTABLE拼接队列名称,即vtable,其中DISPATCH_VTABLE是宏定义,如下所示,所以队列的类型是通过OS_dispatch_+队列类型queue_concurrent拼接而成的-
串行队列类型:OS_dispatch_queue_serial,验证如下
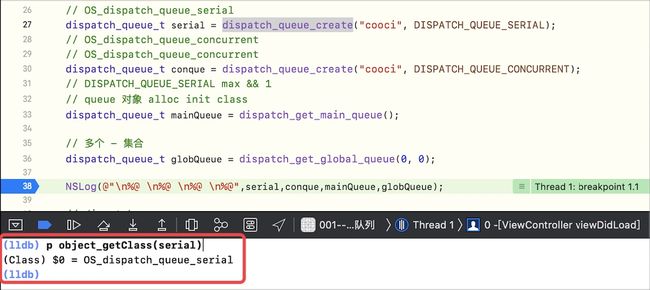 dispatch_queue_create底层分析-2
dispatch_queue_create底层分析-2 -
并发队列类型:OS_dispatch_queue_concurrent,验证如下
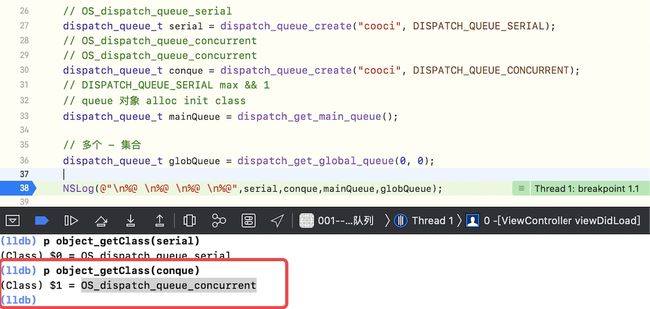 dispatch_queue_create底层分析-3
dispatch_queue_create底层分析-3
-
#define DISPATCH_VTABLE(name) DISPATCH_OBJC_CLASS(name)
#define DISPATCH_OBJC_CLASS(name) (&DISPATCH_CLASS_SYMBOL(name))
#define DISPATCH_CLASS(name) OS_dispatch_##name
-
【第四步】通过
alloc+init初始化队列,即dq,其中在_dispatch_queue_init传参中根据dqai.dqai_concurrent的布尔值,就能判断队列 是串行还是并发,而vtable表示队列的类型,说明队列也是对象-
进入
_dispatch_object_alloc -> _os_object_alloc_realized方法中设置了isa的指向,从这里可以验证队列也是对象的说法
 dispatch_queue_create底层分析-4
dispatch_queue_create底层分析-4 -
进入
_dispatch_queue_init方法,队列类型是dispatch_queue_t,并设置队列的相关属性
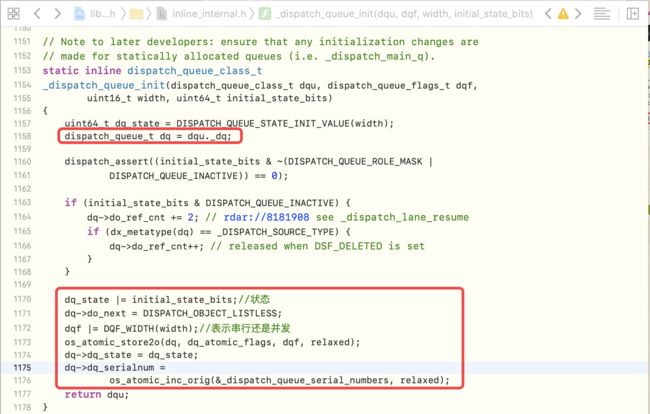 dispatch_queue_create底层分析-5
dispatch_queue_create底层分析-5
-
-
【第五步】通过
_dispatch_trace_queue_create对创建的队列进行处理,其中_dispatch_trace_queue_create是_dispatch_introspection_queue_create封装的宏定义,最后会返回处理过的_dq
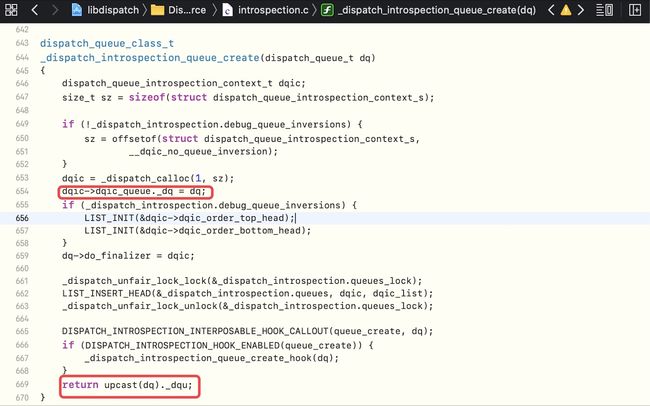 dispatch_queue_create底层分析-6
dispatch_queue_create底层分析-6- 进入
_dispatch_introspection_queue_create_hook -> dispatch_introspection_queue_get_info -> _dispatch_introspection_lane_get_info中可以看出,与我们自定义的类还是有所区别的,创建队列在底层的实现是通过模板创建的
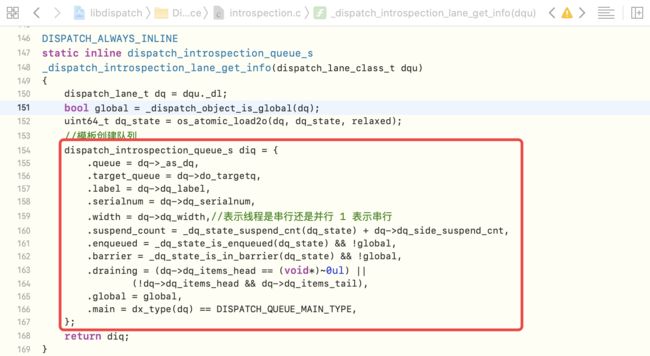 dispatch_queue_create底层分析-7
dispatch_queue_create底层分析-7
- 进入
总结
队列创建方法
dispatch_queue_create中的参数二(即队列类型),决定了下层中max & 1(用于区分是 串行 还是 并发),其中1表示串行queue也是一个对象,也需要底层通过alloc + init 创建,并且在alloc中也有一个class,这个class是通过宏定义拼接而成,并且同时会指定isa的指向创建队列在底层的处理是通过模板创建的,其类型是dispatch_introspection_queue_s结构体
dispatch_queue_create底层分析流程如下图所示
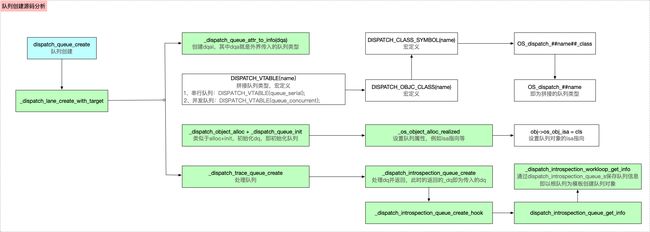
函数 底层原理分析
主要是分析 异步函数dispatch_async 和 同步函数dispatch_sync
异步函数
进入dispatch_async的源码实现,主要分析两个函数
_dispatch_continuation_init:任务包装函数_dispatch_continuation_async:并发处理函数
void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)//work 任务
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME;
dispatch_qos_t qos;
// 任务包装器(work在这里才有使用) - 接受work - 保存work - 并函数式编程
// 保存 block
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
//并发处理
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);
}
_dispatch_continuation_init 任务包装器
进入_dispatch_continuation_init源码实现,主要是包装任务,并设置线程的回程函数,相当于初始化
DISPATCH_ALWAYS_INLINE
static inline dispatch_qos_t
_dispatch_continuation_init(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, dispatch_block_t work,
dispatch_block_flags_t flags, uintptr_t dc_flags)
{
void *ctxt = _dispatch_Block_copy(work);//拷贝任务
dc_flags |= DC_FLAG_BLOCK | DC_FLAG_ALLOCATED;
if (unlikely(_dispatch_block_has_private_data(work))) {
dc->dc_flags = dc_flags;
dc->dc_ctxt = ctxt;//赋值
// will initialize all fields but requires dc_flags & dc_ctxt to be set
return _dispatch_continuation_init_slow(dc, dqu, flags);
}
dispatch_function_t func = _dispatch_Block_invoke(work);//封装work - 异步回调
if (dc_flags & DC_FLAG_CONSUME) {
func = _dispatch_call_block_and_release;//回调函数赋值 - 同步回调
}
return _dispatch_continuation_init_f(dc, dqu, ctxt, func, flags, dc_flags);
}
主要有以下几步
通过
_dispatch_Block_copy拷贝任务通过
_dispatch_Block_invoke封装任务,其中_dispatch_Block_invoke是个宏定义,根据以上分析得知是异步回调
#define _dispatch_Block_invoke(bb) \
((dispatch_function_t)((struct Block_layout *)bb)->invoke)
如果是
同步的,则回调函数赋值为_dispatch_call_block_and_release-
通过
_dispatch_continuation_init_f方法将回调函数赋值,即f就是func,将其保存在属性中
 dispatch_async底层分析-1
dispatch_async底层分析-1
_dispatch_continuation_async 并发处理
这个函数中,主要是执行block回调
- 进入
_dispatch_continuation_async的源码实现
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc);//跟踪日志
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos);//与dx_invoke一样,都是宏
}
- 其中的关键代码是
dx_push(dqu._dq, dc, qos),dx_push是宏定义,如下所示
#define dx_push(x, y, z) dx_vtable(x)->dq_push(x, y, z)
- 而其中的
dq_push需要根据队列的类型,执行不同的函数
dispatch_async底层分析-2
符号断点调试执行函数
- 运行demo,通过
符号断点,来判断执行的是哪个函数,由于是并发队列,通过增加_dispatch_lane_concurrent_push符号断点,看看是否会走到这里
dispatch_queue_t conque = dispatch_queue_create("com.CJL.Queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(conque, ^{
NSLog(@"异步函数");
});
-
运行发现,走的确实是
_dispatch_lane_concurrent_push
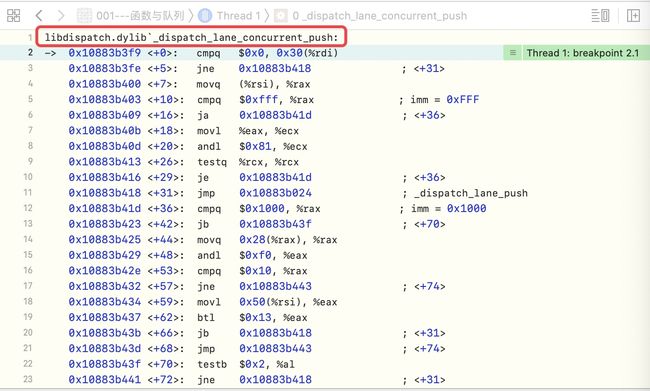 dispatch_async底层分析-3
dispatch_async底层分析-3 -
进入
_dispatch_lane_concurrent_push源码,发现有两步,继续通过符号断点_dispatch_continuation_redirect_push和_dispatch_lane_push调试,发现走的是_dispatch_continuation_redirect_push
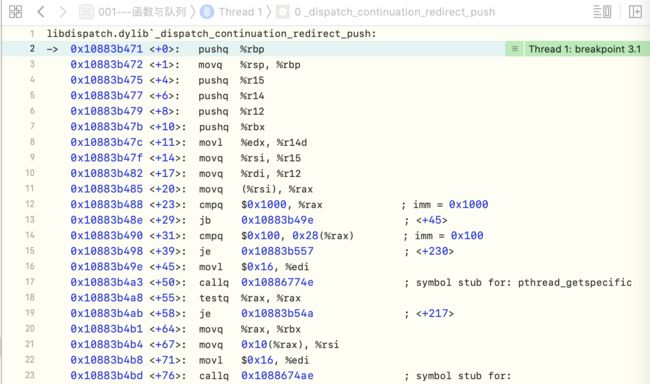 dispatch_async底层分析-4
dispatch_async底层分析-4 -
进入
_dispatch_continuation_redirect_push源码,发现又走到了dx_push,即递归了,综合前面队列创建时可知,队列也是一个对象,有父类、根类,所以会递归执行到根类的方法
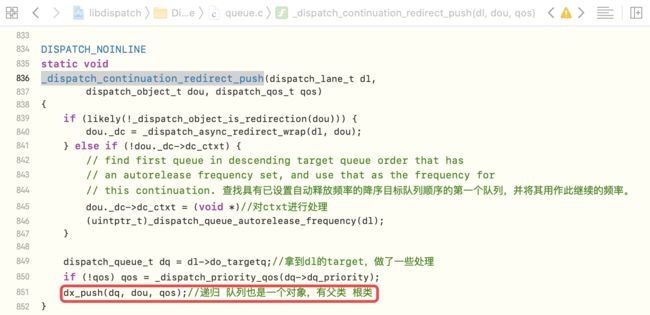 dispatch_async底层分析-5
dispatch_async底层分析-5 -
接下来,通过根类的
_dispatch_root_queue_push符号断点,来验证猜想是否正确,从运行结果看出,完全是正确的
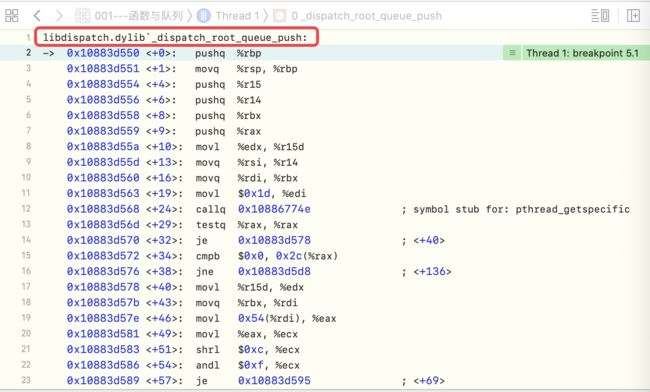 dispatch_async底层分析-6
dispatch_async底层分析-6 -
进入
_dispatch_root_queue_push -> _dispatch_root_queue_push_inline ->_dispatch_root_queue_poke -> _dispatch_root_queue_poke_slow源码,经过符号断点验证,确实是走的这里,查看该方法的源码实现,主要有两步操作通过
_dispatch_root_queues_init方法注册回调通过do-while循环创建线程,使用
pthread_create方法
DISPATCH_NOINLINE
static void
_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor)
{
int remaining = n;
int r = ENOSYS;
_dispatch_root_queues_init();//重点
...
//do-while循环创建线程
do {
_dispatch_retain(dq); // released in _dispatch_worker_thread
while ((r = pthread_create(pthr, attr, _dispatch_worker_thread, dq))) {
if (r != EAGAIN) {
(void)dispatch_assume_zero(r);
}
_dispatch_temporary_resource_shortage();
}
} while (--remaining);
...
}
_dispatch_root_queues_init
- 进入
_dispatch_root_queues_init源码实现,发现是一个dispatch_once_f单例(请查看后续单例的底层分析们,这里不作说明),其中传入的func是_dispatch_root_queues_init_once。
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_root_queues_init(void)
{
dispatch_once_f(&_dispatch_root_queues_pred, NULL, _dispatch_root_queues_init_once);
}
- 进入
_dispatch_root_queues_init_once的源码,其内部不同事务的调用句柄都是_dispatch_worker_thread2
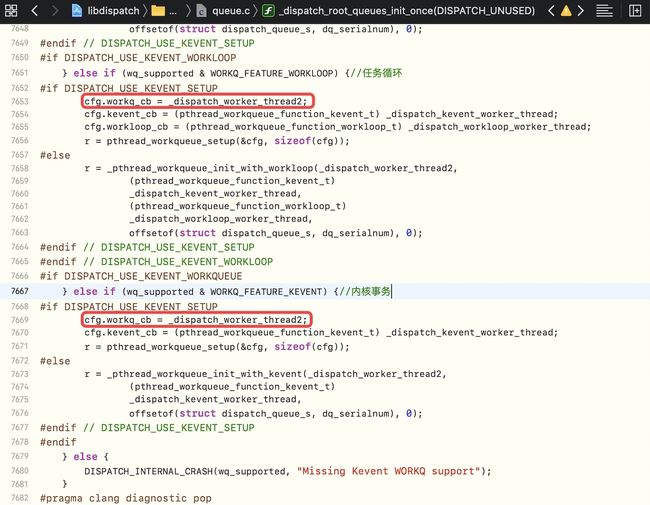 dispatch_async底层分析-7
dispatch_async底层分析-7
其block回调执行的调用路径为:_dispatch_root_queues_init_once ->_dispatch_worker_thread2 -> _dispatch_root_queue_drain -> _dispatch_root_queue_drain -> _dispatch_continuation_pop_inline -> _dispatch_continuation_invoke_inline -> _dispatch_client_callout -> dispatch_call_block_and_release
这个路径可以通过断点,bt打印堆栈信息得出
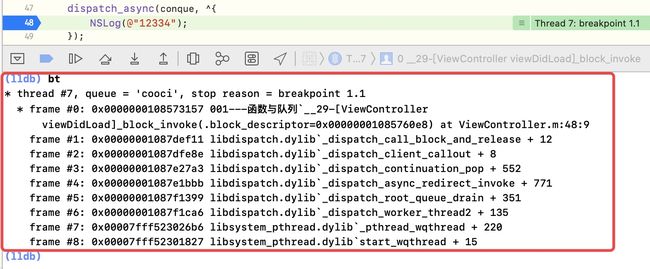
说明
在这里需要说明一点的是,单例的block回调和异步函数的block回调是不同的
单例中,block回调中的
func是_dispatch_Block_invoke(block)而
异步函数中,block回调中的func是dispatch_call_block_and_release
总结
所以,综上所述,异步函数的底层分析如下
【准备工作】:首先,将异步任务拷贝并封装,并设置回调函数
func【block回调】:底层通过
dx_push递归,会重定向到根队列,然后通过pthread_creat创建线程,最后通过dx_invoke执行block回调(注意dx_push和dx_invoke是成对的)
异步函数的底层分析流程如图所示

同步函数
进入dispatch_sync源码实现,其底层的实现是通过栅栏函数实现的(栅栏函数的底层分析见后文)
DISPATCH_NOINLINE
void
dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
-
进入
_dispatch_sync_f源码
 dispatch_sync底层分析-1
dispatch_sync底层分析-1 -
查看
_dispatch_sync_f_inline源码,其中width = 1表示是串行队列,其中有两个重点:栅栏:
_dispatch_barrier_sync_f(可以通过后文的栅栏函数底层分析解释),可以得出同步函数的底层实现其实是同步栅栏函数死锁:
_dispatch_sync_f_slow,如果存在相互等待的情况,就会造成死锁
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
if (likely(dq->dq_width == 1)) {//表示是串行队列
return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);//栅栏
}
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// Global concurrent queues and queues bound to non-dispatch threads
// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {
return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);//死锁
}
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);
}
_dispatch_introspection_sync_begin(dl);//处理当前信息
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));//block执行并释放
}
_dispatch_sync_f_slow 死锁
-
进入
_dispatch_sync_f_slow,当前的主队列是挂起、阻塞的
 _dispatch_sync_f_slow底层分析-1
_dispatch_sync_f_slow底层分析-1 -
往一个队列中 加入任务,会push加入主队列,进入
_dispatch_trace_item_push
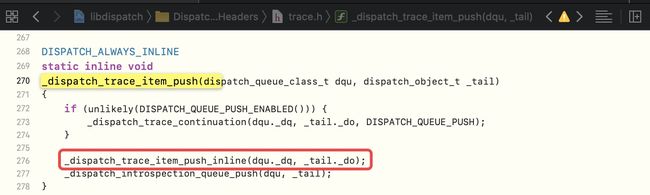 _dispatch_sync_f_slow底层分析-2
_dispatch_sync_f_slow底层分析-2 -
进入
__DISPATCH_WAIT_FOR_QUEUE__,判断dq是否为正在等待的队列,然后给出一个状态state,然后将dq的状态和当前任务依赖的队列进行匹配
 _dispatch_sync_f_slow底层分析-3
_dispatch_sync_f_slow底层分析-3 进入
_dq_state_drain_locked_by -> _dispatch_lock_is_locked_by源码
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
//异或操作:相同为0,不同为1,如果相同,则为0,0 &任何数都为0
//即判断 当前要等待的任务 和 正在执行的任务是否一样,通俗的解释就是 执行和等待的是否在同一队列
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}
如果当前等待的和正在执行的是同一个队列,即判断线程ID是否相乘,如果相等,则会造成死锁
同步函数 + 并发队列 顺序执行的原因
在_dispatch_sync_invoke_and_complete -> _dispatch_sync_function_invoke_inline源码中,主要有三个步骤:
- 将任务压入队列:
_dispatch_thread_frame_push - 执行任务的block回调:
_dispatch_client_callout - 将任务出队:
_dispatch_thread_frame_pop
从实现中可以看出,是先将任务push队列中,然后执行block回调,在将任务pop,所以任务是顺序执行的。
总结
同步函数的底层实现如下:
同步函数的底层实现实际是同步栅栏函数同步函数中如果
当前正在执行的队列和等待的是同一个队列,形成相互等待的局面,则会造成死锁
所以,综上所述,同步函数的底层实现流程如图所示
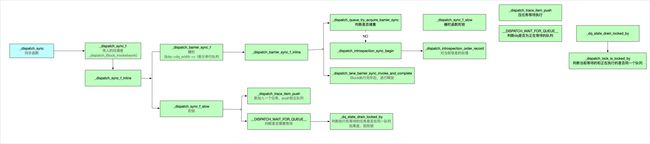
单例
在日常开发中,我们一般使用GCD的dispatch_once来创建单例,如下所示
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
NSLog(@"单例应用");
});
首先对于单例,我们需要了解两点
-
【执行一次的原因】单例的流程只执行一次,底层是如何控制的,即为什么只能执行一次? -
【block调用时机】单例的block是在什么时候进行调用的?
下面带着以下两点疑问,我们来针对单例的底层进行分析
- 进入
dispatch_once源码实现,底层是通过dispatch_once_f实现的参数1:
onceToken,它是一个静态变量,由于不同位置定义的静态变量是不同的,所以静态变量具有唯一性参数2:
block回调
void
dispatch_once(dispatch_once_t *val, dispatch_block_t block)
{
dispatch_once_f(val, block, _dispatch_Block_invoke(block));
}
- 进入
dispatch_once_f源码,其中的val是外界传入的onceToken静态变量,而func是_dispatch_Block_invoke(block),其中单例的底层主要分为以下几步将
val,也就是静态变量转换为dispatch_once_gate_t类型的变量l-
通过
os_atomic_load获取此时的任务的标识符v如果
v等于DLOCK_ONCE_DONE,表示任务已经执行过了,直接return如果 任务执行后,
加锁失败了,则走到_dispatch_once_mark_done_if_quiesced函数,再次进行存储,将标识符置为DLOCK_ONCE_DONE反之,则通过
_dispatch_once_gate_tryenter尝试进入任务,即解锁,然后执行_dispatch_once_callout执行block回调
如果此时有任务正在执行,再次进来一个任务2,则通过
_dispatch_once_wait函数让任务2进入无限次等待
DISPATCH_NOINLINE
void
dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
dispatch_once_gate_t l = (dispatch_once_gate_t)val;
#if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTER
uintptr_t v = os_atomic_load(&l->dgo_once, acquire);//load
if (likely(v == DLOCK_ONCE_DONE)) {//已经执行过了,直接返回
return;
}
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
if (likely(DISPATCH_ONCE_IS_GEN(v))) {
return _dispatch_once_mark_done_if_quiesced(l, v);
}
#endif
#endif
if (_dispatch_once_gate_tryenter(l)) {//尝试进入
return _dispatch_once_callout(l, ctxt, func);
}
return _dispatch_once_wait(l);//无限次等待
}
_dispatch_once_gate_tryenter 解锁
查看其源码,主要是通过底层os_atomic_cmpxchg方法进行对比,如果比较没有问题,则进行加锁,即任务的标识符置为DLOCK_ONCE_UNLOCKED
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_once_gate_tryenter(dispatch_once_gate_t l)
{
return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,
(uintptr_t)_dispatch_lock_value_for_self(), relaxed);//首先对比,然后进行改变
}
_dispatch_once_callout 回调
进入_dispatch_once_callout源码,主要就两步
_dispatch_client_callout:block回调执行_dispatch_once_gate_broadcast:进行广播
DISPATCH_NOINLINE
static void
_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,
dispatch_function_t func)
{
_dispatch_client_callout(ctxt, func);//block调用执行
_dispatch_once_gate_broadcast(l);//进行广播:告诉别人有了归属,不要找我了
- 进入
_dispatch_client_callout源码,主要就是执行block回调,其中的f等于_dispatch_Block_invoke(block),即异步回调
#undef _dispatch_client_callout
void
_dispatch_client_callout(void *ctxt, dispatch_function_t f)
{
@try {
return f(ctxt);
}
@catch (...) {
objc_terminate();
}
}
- 进入
_dispatch_once_gate_broadcast -> _dispatch_once_mark_done源码,主要就是给dgo->dgo_once一个值,然后将任务的标识符为DLOCK_ONCE_DONE,即解锁
DISPATCH_ALWAYS_INLINE
static inline uintptr_t
_dispatch_once_mark_done(dispatch_once_gate_t dgo)
{
//如果不相同,直接改为相同,然后上锁 -- DLOCK_ONCE_DONE
return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release);
}
总结
针对单例的底层实现,主要说明如下:
【单例只执行一次的原理】:GCD单例中,有两个重要参数,
onceToken和block,其中onceToken是静态变量,具有唯一性,在底层被封装成了dispatch_once_gate_t类型的变量l,l主要是用来获取底层原子封装性的关联,即变量v,通过v来查询任务的状态,如果此时v等于DLOCK_ONCE_DONE,说明任务已经处理过一次了,直接return【block调用时机】:如果此时任务没有执行过,则会在底层通过C++函数的比较,将
任务进行加锁,即任务状态置为DLOCK_ONCE_UNLOCK,目的是为了保证当前任务执行的唯一性,防止在其他地方有多次定义。加锁之后进行block回调函数的执行,执行完成后,将当前任务解锁,将当前的任务状态置为DLOCK_ONCE_DONE,在下次进来时,就不会在执行,会直接返回【多线程影响】:如果在当前任务执行期间,有其他任务进来,会进入无限次等待,原因是当前任务已经获取了锁,进行了加锁,其他任务是无法获取锁的
单例的底层流程分析如下如所示
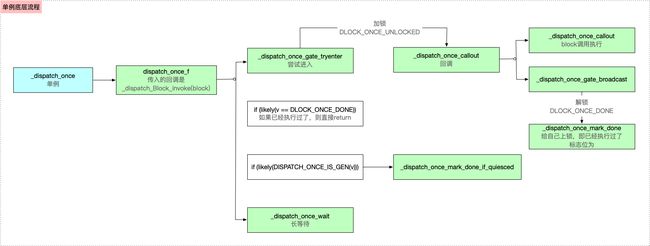
栅栏函数
GCD中常用的栅栏函数,主要有两种
同步栅栏函数dispatch_barrier_sync(在主线程中执行):前面的任务执行完毕才会来到这里,但是同步栅栏函数会堵塞线程,影响后面的任务执行异步栅栏函数dispatch_barrier_async:前面的任务执行完毕才会来到这里
栅栏函数最直接的作用就是 控制任务执行顺序,使同步执行。
同时,栅栏函数需要注意一下几点
- 栅栏函数
只能控制同一并发队列
同步栅栏添加进入队列的时候,当前线程会被锁死,直到同步栅栏之前的任务和同步栅栏任务本身执行完毕时,当前线程才会打开然后继续执行下一句代码。
在使用栅栏函数时.使用自定义队列才有意义,如果用的是串行队列或者系统提供的全局并发队列,这个栅栏函数的作用等同于一个同步函数的作用,没有任何意义
代码调试
总共有4个任务,其中前2个任务有依赖关系,即任务1执行完,执行任务2,此时可以使用栅栏函数
-
异步栅栏函数 不会阻塞主线程 ,异步
堵塞 的是队列
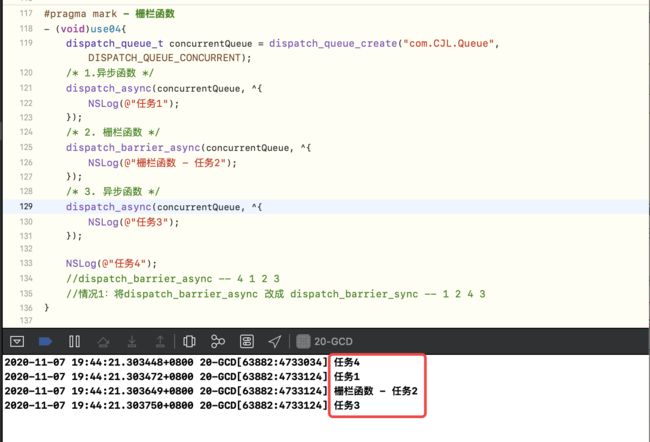 栅栏调试-1
栅栏调试-1 -
同步栅栏函数 会
堵塞主线程,同步 堵塞 是当前的线程
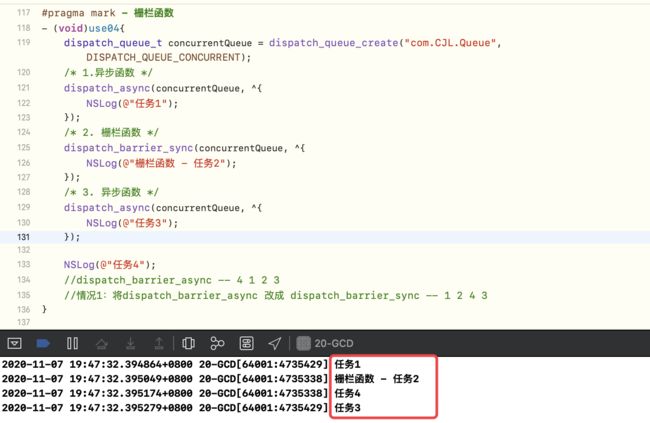 栅栏调试-2
栅栏调试-2
总结
异步栅栏函数阻塞的是队列,而且必须是自定义的并发队列,不影响主线程任务的执行同步栅栏函数阻塞的是线程,且是主线程,会影响主线程其他任务的执行
使用场景
栅栏函数除了用于任务有依赖关系时,同时还可以用于数据安全
像下面这样操作,会崩溃
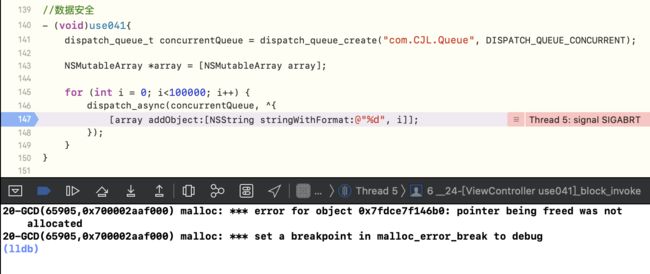
崩溃的原因是:数据在不断的retain 和 release,在数据还没有retain完毕时,已经开始了release,相当于加了一个空数据,进行release
修改
- 通过加栅栏函数
- (void)use041{
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.CJL.Queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i<100000; i++) {
dispatch_async(concurrentQueue, ^{
dispatch_barrier_async(concurrentQueue, ^{
[array addObject:[NSString stringWithFormat:@"%d", i]];
});
});
}
}
- 使用互斥锁
@synchronized (self) {}
- (void)use041{
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.CJL.Queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i<100000; i++) {
dispatch_async(concurrentQueue, ^{
@synchronized (self) {
[array addObject:[NSString stringWithFormat:@"%d", i]];
};
});
}
}
注意
如果栅栏函数中使用
全局队列, 运行会崩溃,原因是系统也在用全局并发队列,使用栅栏同时会拦截系统的,所以会崩溃如果将
自定义并发队列改为串行队列,即serial ,串行队列本身就是有序同步此时加栅栏,会浪费性能栅栏函数
只会阻塞一次
异步栅栏函数 底层分析
进入dispatch_barrier_async源码实现,其底层的实现与dispatch_async类似,这里就不再做分析了,有兴趣的可以自行探索下
#ifdef __BLOCKS__
void
dispatch_barrier_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_BARRIER;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
_dispatch_continuation_async(dq, dc, qos, dc_flags);
}
#endif
同步栅栏函数 底层分析
进入dispatch_barrier_sync源码,实现如下
void
dispatch_barrier_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BARRIER | DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_barrier_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
_dispatch_barrier_sync_f_inline
进入_dispatch_barrier_sync_f -> _dispatch_barrier_sync_f_inline源码
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
dispatch_tid tid = _dispatch_tid_self();//获取线程的id,即线程的唯一标识
...
//判断线程状态,需不需要等待,是否回收
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {//栅栏函数也会死锁
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,//没有回收
DC_FLAG_BARRIER | dc_flags);
}
//验证target是否存在,如果存在,加入栅栏函数的递归查找 是否等待
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));//执行
}
源码主要有分为以下几部分
通过
_dispatch_tid_self获取线程ID-
通过
_dispatch_queue_try_acquire_barrier_sync判断线程状态
 dispatch_barrier_sync底层分析-1
dispatch_barrier_sync底层分析-1- 进入
_dispatch_queue_try_acquire_barrier_sync_and_suspend,在这里进行释放
 dispatch_barrier_sync底层分析-2
dispatch_barrier_sync底层分析-2
- 进入
通过
_dispatch_sync_recurse递归查找栅栏函数的target-
通过
_dispatch_introspection_sync_begin对向前信息进行处理
 dispatch_barrier_sync底层分析-3
dispatch_barrier_sync底层分析-3 -
通过
_dispatch_lane_barrier_sync_invoke_and_complete执行block并释放
 dispatch_barrier_sync底层分析-4
dispatch_barrier_sync底层分析-4
信号量
信号量的作用一般是用来使任务同步执行,类似于互斥锁,用户可以根据需要控制GCD最大并发数,一般是这样使用的
//信号量
dispatch_semaphore_t sem = dispatch_semaphore_create(1);
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
dispatch_semaphore_signal(sem);
下面我们来分析其底层原理
dispatch_semaphore_create 创建
该函数的底层实现如下,主要是初始化信号量,并设置GCD的最大并发数,其最大并发数必须大于0
dispatch_semaphore_t
dispatch_semaphore_create(long value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
if (value < 0) {
return DISPATCH_BAD_INPUT;
}
dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),
sizeof(struct dispatch_semaphore_s));
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_default_queue(false);
dsema->dsema_value = value;
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
dsema->dsema_orig = value;
return dsema;
}
dispatch_semaphore_wait 加锁
该函数的源码实现如下,其主要作用是对信号量dsema通过os_atomic_dec2o进行了--操作,其内部是执行的C++的atomic_fetch_sub_explicit方法
如果value 大于等于0,表示操作无效,即
执行成功如果value 等于
LONG_MIN,系统会抛出一个crash如果value 小于0,则进入
长等待
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
// dsema_value 进行 -- 操作
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) {//表示执行操作无效,即执行成功
return 0;
}
return _dispatch_semaphore_wait_slow(dsema, timeout);//长等待
}
其中os_atomic_dec2o的宏定义转换如下
os_atomic_inc2o(p, f, m)
os_atomic_sub2o(p, f, 1, m)
_os_atomic_c11_op((p), (v), m, sub, -)
_os_atomic_c11_op((p), (v), m, add, +)
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
将具体的值代入为
os_atomic_dec2o(dsema, dsema_value, acquire);
os_atomic_sub2o(dsema, dsema_value, 1, m)
os_atomic_sub(dsema->dsema_value, 1, m)
_os_atomic_c11_op(dsema->dsema_value, 1, m, sub, -)
_r = atomic_fetch_sub_explicit(dsema->dsema_value, 1),
等价于 dsema->dsema_value - 1
- 进入
_dispatch_semaphore_wait_slow的源码实现,当value小于0时,根据等待事件timeout做出不同操作
 dispatch_semaphore_wait底层分析-1
dispatch_semaphore_wait底层分析-1
dispatch_semaphore_signal 解锁
该函数的源码实现如下,其核心也是通过os_atomic_inc2o函数对value进行了++操作,os_atomic_inc2o内部是通过C++的atomic_fetch_add_explicit
如果value 大于 0,表示操作无效,即
执行成功如果value 等于0,则进入
长等待
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
//signal 对 value是 ++
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) {//返回0,表示当前的执行操作无效,相当于执行成功
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);//进入长等待
}
其中os_atomic_dec2o的宏定义转换如下
os_atomic_inc2o(p, f, m)
os_atomic_add2o(p, f, 1, m)
os_atomic_add(&(p)->f, (v), m)
_os_atomic_c11_op((p), (v), m, add, +)
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
将具体的值代入为
os_atomic_inc2o(dsema, dsema_value, release);
os_atomic_add2o(dsema, dsema_value, 1, m)
os_atomic_add(&(dsema)->dsema_value, (1), m)
_os_atomic_c11_op((dsema->dsema_value), (1), m, add, +)
_r = atomic_fetch_add_explicit(dsema->dsema_value, 1),
等价于 dsema->dsema_value + 1
总结
dispatch_semaphore_create主要就是初始化限号量dispatch_semaphore_wait是对信号量的value进行--,即加锁操作dispatch_semaphore_signal是对信号量的value进行++,即解锁操作
所以,综上所述,信号量相关函数的底层操作如图所示
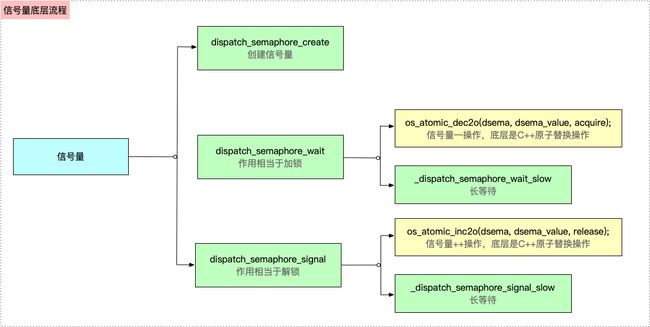
调度组
调度组的最直接作用是控制任务执行顺序,常见方式如下
dispatch_group_create 创建组
dispatch_group_async 进组任务
dispatch_group_notify 进组任务执行完毕通知 dispatch_group_wait 进组任务执行等待时间
//进组和出组一般是成对使用的
dispatch_group_enter 进组
dispatch_group_leave 出组
使用
假设目前有两个任务,需要等待这两个任务都执行完毕,才会更新UI,可以使用调度组

- 【修改一】如果将
dispatch_group_notify移动到最前面,能否执行?
 修改1
修改1
能执行,但是是只要有enter-leave成对匹配,notify就会执行,不会等两个组都执行完。意思就是只要enter-leave成对就可以执行
- 【修改二】再加一个enter,即
enter:wait 是 3:2,能否执行notify?
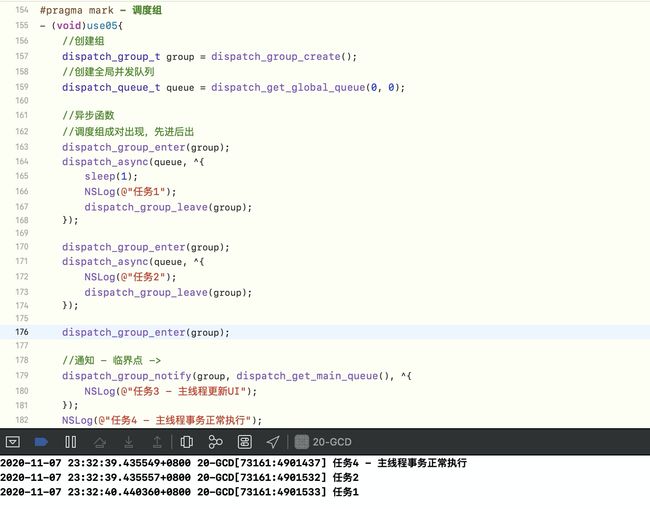 修改2
修改2
不能,会一直等待,等一个leave,才会执行notify
-
【修改三】如果是 enter:wait 是 2:3,能否执行notify?
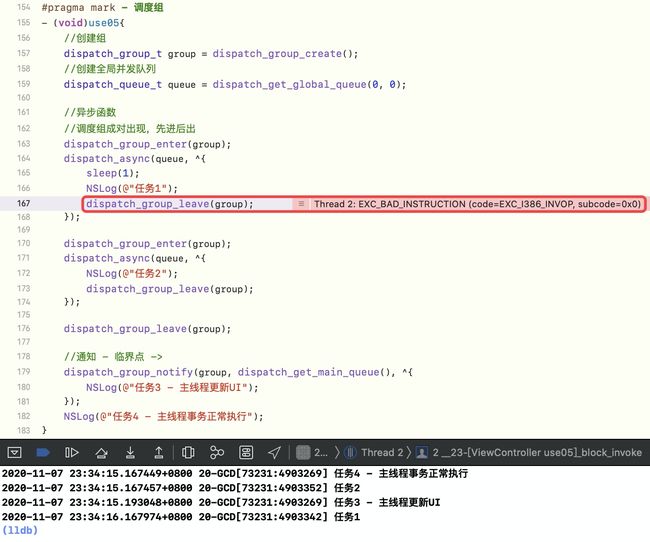 修改3
修改3
会崩溃,因为enter-leave不成对,崩溃在里面是因为async有延迟
dispatch_group_create 创建组
主要是创建group,并设置属性,此时的group的value为0
- 进入
dispatch_group_create源码
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
- 进入
_dispatch_group_create_with_count源码,其中是对group对象属性赋值,并返回group对象,其中的n等于0
DISPATCH_ALWAYS_INLINE
static inline dispatch_group_t
_dispatch_group_create_with_count(uint32_t n)
{
//创建group对象,类型为OS_dispatch_group
dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),
sizeof(struct dispatch_group_s));
//group对象赋值
dg->do_next = DISPATCH_OBJECT_LISTLESS;
dg->do_targetq = _dispatch_get_default_queue(false);
if (n) {
os_atomic_store2o(dg, dg_bits,
(uint32_t)-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); //
}
return dg;
}
dispatch_group_enter 进组
进入dispatch_group_enter源码,通过os_atomic_sub_orig2o对dg->dg.bits 作 --操作,对数值进行处理
void
dispatch_group_enter(dispatch_group_t dg)
{
// The value is decremented on a 32bits wide atomic so that the carry
// for the 0 -> -1 transition is not propagated to the upper 32bits.
uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits,//原子递减 0 -> -1
DISPATCH_GROUP_VALUE_INTERVAL, acquire);
uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;
if (unlikely(old_value == 0)) {//如果old_value
_dispatch_retain(dg); //
}
if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) {//到达临界值,会报crash
DISPATCH_CLIENT_CRASH(old_bits,
"Too many nested calls to dispatch_group_enter()");
}
}
dispatch_group_leave 出组
- 进入
dispatch_group_leave源码- -1 到 0,即
++操作 - 根据状态,do-while循环,唤醒执行block任务
- 如果0 + 1 = 1,enter-leave不平衡,即leave多次调用,会crash
- -1 到 0,即
void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,//原子递增 ++
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
//根据状态,唤醒
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);//唤醒
}
//-1 -> 0, 0+1 -> 1,即多次leave,会报crash,简单来说就是enter-leave不平衡
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
- 进入
_dispatch_group_wake源码,do-while 循环进行异步命中,调用_dispatch_continuation_async执行
DISPATCH_NOINLINE
static void
_dispatch_group_wake(dispatch_group_t dg, uint64_t dg_state, bool needs_release)
{
uint16_t refs = needs_release ? 1 : 0; //
if (dg_state & DISPATCH_GROUP_HAS_NOTIFS) {
dispatch_continuation_t dc, next_dc, tail;
// Snapshot before anything is notified/woken
dc = os_mpsc_capture_snapshot(os_mpsc(dg, dg_notify), &tail);
do {
dispatch_queue_t dsn_queue = (dispatch_queue_t)dc->dc_data;
next_dc = os_mpsc_pop_snapshot_head(dc, tail, do_next);
_dispatch_continuation_async(dsn_queue, dc,
_dispatch_qos_from_pp(dc->dc_priority), dc->dc_flags);//block任务执行
_dispatch_release(dsn_queue);
} while ((dc = next_dc));//do-while循环,进行异步任务的命中
refs++;
}
if (dg_state & DISPATCH_GROUP_HAS_WAITERS) {
_dispatch_wake_by_address(&dg->dg_gen);//地址释放
}
if (refs) _dispatch_release_n(dg, refs);//引用释放
}
- 进入
_dispatch_continuation_async源码
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc);//跟踪日志
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos);//与dx_invoke一样,都是宏
}
这步与异步函数的block回调执行是一致的,这里不再作说明
dispatch_group_notify 通知
- 进入
dispatch_group_notify源码,如果old_state等于0,就可以进行释放了
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
uint64_t old_state, new_state;
dispatch_continuation_t prev;
dsn->dc_data = dq;
_dispatch_retain(dq);
//获取dg底层的状态标识码,通过os_atomic_store2o获取的值,即从dg的状态码 转成了 os底层的state
prev = os_mpsc_push_update_tail(os_mpsc(dg, dg_notify), dsn, do_next);
if (os_mpsc_push_was_empty(prev)) _dispatch_retain(dg);
os_mpsc_push_update_prev(os_mpsc(dg, dg_notify), prev, dsn, do_next);
if (os_mpsc_push_was_empty(prev)) {
os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, release, {
new_state = old_state | DISPATCH_GROUP_HAS_NOTIFS;
if ((uint32_t)old_state == 0) { //如果等于0,则可以进行释放了
os_atomic_rmw_loop_give_up({
return _dispatch_group_wake(dg, new_state, false);//唤醒
});
}
});
}
}
除了leave可以通过_dispatch_group_wake唤醒,其中dispatch_group_notify也是可以唤醒的
- 其中
os_mpsc_push_update_tail是宏定义,用于获取dg的状态码
#define os_mpsc_push_update_tail(Q, tail, _o_next) ({ \
os_mpsc_node_type(Q) _tl = (tail); \
os_atomic_store2o(_tl, _o_next, NULL, relaxed); \
os_atomic_xchg(_os_mpsc_tail Q, _tl, release); \
})
dispatch_group_async
- 进入
dispatch_group_async源码,主要是包装任务和异步处理任务
#ifdef __BLOCKS__
void
dispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC;
dispatch_qos_t qos;
//任务包装器
qos = _dispatch_continuation_init(dc, dq, db, 0, dc_flags);
//处理任务
_dispatch_continuation_group_async(dg, dq, dc, qos);
}
#endif
- 进入
_dispatch_continuation_group_async源码,主要是封装了dispatch_group_enter进组操作
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dc, dispatch_qos_t qos)
{
dispatch_group_enter(dg);//进组
dc->dc_data = dg;
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);//异步操作
}
- 进入
_dispatch_continuation_async源码,执行常规的异步函数底层操作。既然有了enter,肯定有leave,我们猜测block执行之后隐性的执行leave,通过断点调试,打印堆栈信息
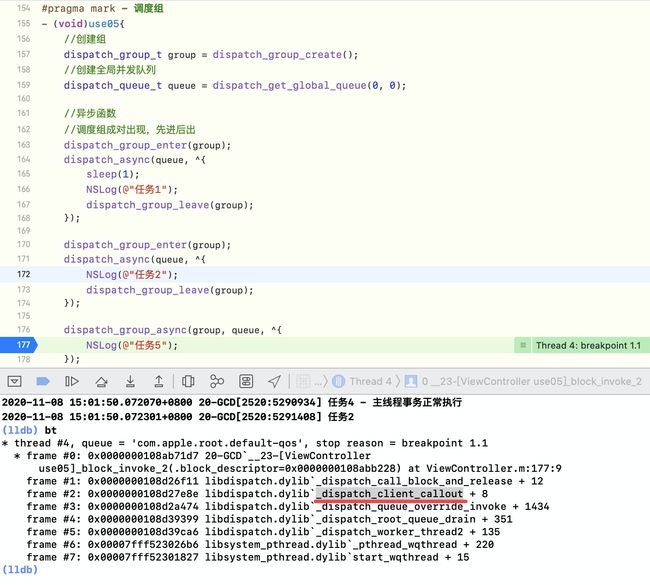 堆栈信息
堆栈信息
- 搜索
_dispatch_client_callout的调用,在_dispatch_continuation_with_group_invoke中
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_with_group_invoke(dispatch_continuation_t dc)
{
struct dispatch_object_s *dou = dc->dc_data;
unsigned long type = dx_type(dou);
if (type == DISPATCH_GROUP_TYPE) {//如果是调度组类型
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);//block回调
_dispatch_trace_item_complete(dc);
dispatch_group_leave((dispatch_group_t)dou);//出组
} else {
DISPATCH_INTERNAL_CRASH(dx_type(dou), "Unexpected object type");
}
所以,完美的印证dispatch_group_async底层封装的是enter-leave
总结
enter-leave只要成对就可以,不管远近dispatch_group_enter在底层是通过C++函数,对group的value进行--操作(即0 -> -1)dispatch_group_leave在底层是通过C++函数,对group的value进行++操作(即-1 -> 0)dispatch_group_notify在底层主要是判断group的state是否等于0,当等于0时,就通知block任务的唤醒,可以通过
dispatch_group_leave,也可以通过dispatch_group_notifydispatch_group_async等同于enter - leave,其底层的实现就是enter-leave
所以综上所述,调度组的底层分析流程如下图所示

dispatch_source
简述
dispatch_source是基础数据类型,用于协调特定底层系统事件的处理。
dispatch_source替代了异步回调函数,来处理系统相关的事件,当配置一个dispatch时,你需要指定监测的事件、dispatch queue、以及处理事件的代码(block或函数)。当事件发生时,dispatch source会提交你的block或函数到指定的queue去执行
使用 Dispatch Source 而不使用 dispatch_async 的唯一原因就是利用联结的优势。
联结的大致流程为:在任一线程上调用它的一个函数dispatch_source_merge_data后,会执行Dispatch Source事先定义好的句柄(可以把句柄简单理解为一个block),这个过程叫 Custom event ,用户事件。是 dispatch source 支持处理的一种事件。
简单来说:这种事件是由你调用 dispatch_source_merge_data 函数来向自己发出的信号。
句柄是一种指向指针的指针,它指向的就是一个类或者结构,它和系统有密切的关系,这当中还有一个通用的句柄,就是HANDLE
- 实例句柄 HINSTANCE
- 位图句柄 HBITMAP
- 设备表句柄 HDC
- 图标句柄 HICON
特点
其CPU负荷非常小,金陵不占用资源
联结的优势
使用
- 创建dispatch源
dispatch_source_t source = dispatch_source_create(dispatch_source_type_t type, uintptr_t handle, unsigned long mask, dispatch_queue_t queue)
| 参数 | 说明 |
|---|---|
| type | dispatch源可处理的事件 |
| handle | 可以理解为句柄、索引或id,假如要监听进程,需要传入进程的ID |
| mask | 可以理解为描述,提供更详细的描述,让它知道具体要监听什么 |
| queue | 自定义源需要的一个队列,用来处理所有的响应句柄 |
Dispatch Source 种类
其中type的类型有以下几种
| 种类 | 说明 |
|---|---|
| DISPATCH_SOURCE_TYPE_DATA_ADD | 自定义的事件,变量增加 |
| DISPATCH_SOURCE_TYPE_DATA_OR | 自定义的事件,变量OR |
| DISPATCH_SOURCE_TYPE_MACH_SEND | MACH端口发送 |
| DISPATCH_SOURCE_TYPE_MACH_RECV | MACH端口接收 |
| DISPATCH_SOURCE_TYPE_MEMORYPRESSURE | 内存压力 (注:iOS8后可用) |
| DISPATCH_SOURCE_TYPE_PROC | 进程监听,如进程的退出、创建一个或更多的子线程、进程收到UNIX信号 |
| DISPATCH_SOURCE_TYPE_READ | IO操作,如对文件的操作、socket操作的读响应 |
| DISPATCH_SOURCE_TYPE_SIGNAL | 接收到UNIX信号时响应 |
| DISPATCH_SOURCE_TYPE_TIMER | 定时器 |
| DISPATCH_SOURCE_TYPE_VNODE | 文件状态监听,文件被删除、移动、重命名 |
| DISPATCH_SOURCE_TYPE_WRITE | IO操作,如对文件的操作、socket操作的写响应 |
注意:
DISPATCH_SOURCE_TYPE_DATA_ADD
当同一时间,一个事件的的触发频率很高,那么Dispatch Source会将这些响应以ADD的方式进行累积,然后等系统空闲时最终处理,如果触发频率比较零散,那么Dispatch Source会将这些事件分别响应。DISPATCH_SOURCE_TYPE_DATA_OR和上面的一样,是自定义的事件,但是它是以OR的方式进行累积
常用函数
//挂起队列
dispatch_suspend(queue)
//分派源创建时默认处于暂停状态,在分派源分派处理程序之前必须先恢复
dispatch_resume(source)
//向分派源发送事件,需要注意的是,不可以传递0值(事件不会被触发),同样也不可以传递负数。
dispatch_source_merge_data
//设置响应分派源事件的block,在分派源指定的队列上运行
dispatch_source_set_event_handler
//得到分派源的数据
dispatch_source_get_data
//得到dispatch源创建,即调用dispatch_source_create的第二个参数
uintptr_t dispatch_source_get_handle(dispatch_source_t source);
//得到dispatch源创建,即调用dispatch_source_create的第三个参数
unsigned long dispatch_source_get_mask(dispatch_source_t source);
////取消dispatch源的事件处理--即不再调用block。如果调用dispatch_suspend只是暂停dispatch源。
void dispatch_source_cancel(dispatch_source_t source);
//检测是否dispatch源被取消,如果返回非0值则表明dispatch源已经被取消
long dispatch_source_testcancel(dispatch_source_t source);
//dispatch源取消时调用的block,一般用于关闭文件或socket等,释放相关资源
void dispatch_source_set_cancel_handler(dispatch_source_t source, dispatch_block_t cancel_handler);
//可用于设置dispatch源启动时调用block,调用完成后即释放这个block。也可在dispatch源运行当中随时调用这个函数。
void dispatch_source_set_registration_handler(dispatch_source_t source, dispatch_block_t registration_handler);
使用场景
经常用于验证码倒计时,因为dispatch_source不依赖于Runloop,而是直接和底层内核交互,准确性更高。
- (void)use033{
//倒计时时间
__block int timeout = 3;
//创建队列
dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0);
//创建timer
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, globalQueue);
//设置1s触发一次,0s的误差
/*
- source 分派源
- start 数控制计时器第一次触发的时刻。参数类型是 dispatch_time_t,这是一个opaque类型,我们不能直接操作它。我们得需要 dispatch_time 和 dispatch_walltime 函数来创建它们。另外,常量 DISPATCH_TIME_NOW 和 DISPATCH_TIME_FOREVER 通常很有用。
- interval 间隔时间
- leeway 计时器触发的精准程度
*/
dispatch_source_set_timer(timer,dispatch_walltime(NULL, 0),1.0*NSEC_PER_SEC, 0);
//触发的事件
dispatch_source_set_event_handler(timer, ^{
//倒计时结束,关闭
if (timeout <= 0) {
//取消dispatch源
dispatch_source_cancel(timer);
}else{
timeout--;
dispatch_async(dispatch_get_main_queue(), ^{
//更新主界面的操作
NSLog(@"倒计时 - %d", timeout);
});
}
});
//开始执行dispatch源
dispatch_resume(timer);
}
使用GCD中的dispatch_source实现 自定义倒计时按钮
实现思路只要是继承自UIButton,然后通过GCD的dispatch_source 实现倒计时按钮,以下是demo的下载地址
CJLCountDownButton- CJLCountDownButton