23篇大数据系列(三)sql基础知识(史上最全,建议收藏)
作者简介
蓝桥签约作者、大数据&Python领域优质创作者。维护多个大数据技术群,帮助大学生就业和初级程序员解决工作难题。
我的使命与愿景:持续稳定输出,赋能中国技术社区蓬勃发展!
免费下载海量【PPT模板、简历模板、学习资料】:
https://blog.csdn.net/weixin_39032019/article/details/118088462
大数据系列文章,从技术能力、业务基础、分析思维三大板块来呈现,你将收获:
❖ 提升自信心,自如应对面试,顺利拿到实习岗位或offer;
❖ 掌握大数据的基础知识,与其他同事沟通无障碍;
❖ 具备一定的项目实战能力,对于大数据工作直接上手;
【评论、点赞、收藏】是对我最大的支持!!!
大数据工程师系列专栏: 面试真题、开发经验、调优策略
大数据工程师知识体系:
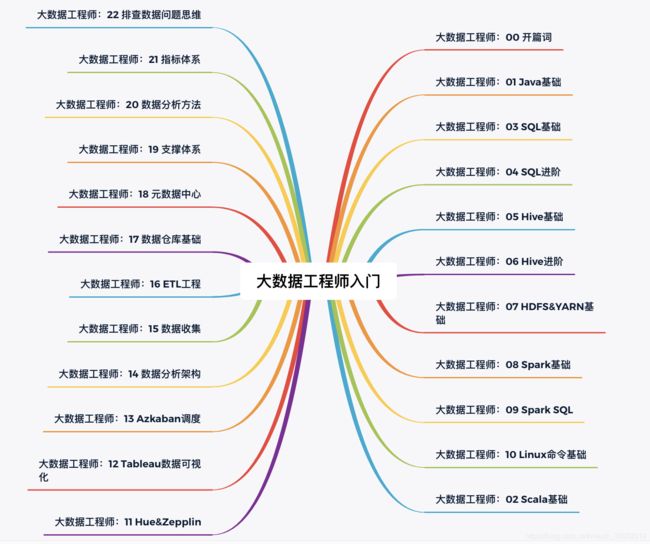
大数据工程师的工作内容是什么?
而大数据时代,有一个关键性的岗位不得不提,那就是大数据工程师。想必大家也会好奇,大数据工程师,日常是做什么的呢?
| 1.数据采集 | 找出描述用户或对业务发展有帮助的数据,并将定义相关的数据格式,交由业务开发部门负责收集对应的数据。 |
| 2.ETL工程 | 对收集到的数据,进行各种清洗、处理、转化等操作,完成格式转换,便于后续分析,保证数据质量,以便得出可以信赖的结果。 |
| 3.构建数仓 | 将数据有效治理起来,构建统一的数据仓库,让数据与数据间建立连接,碰撞出更大的价值。 |
| 4.数据建模 | 基于已有的数据,梳理数据间的复杂关系,建立恰当的数据模型,便于分析出有价值的结论。 |
| 5.统计分析 | 对数据进行各种维度的统计分析,建立指标体系,系统性地描述业务发展的当前状态,寻找业务中的问题,发现新的优化点与增长点。 |
| 6.用户画像 | 基于用户的各方面数据,建立对用户的全方位理解,构建每个特定用户的画像,以便针对每个个体完成精细化运营。 |
大数据工程师必备技能
那么,问题来了,如果想成为一名大数据工程师,胜任上述工作内容,需要具备什么样的条件?拥有什么样的知识呢?
| 分类 |
子分类 |
技能 |
描述 |
| 技 术 能 力 |
编程基础 |
Java基础 |
大数据生态必备的java基础 |
| Scala基础 |
Spark相关生态的必备技能 |
||
| SQL基础 |
数据分析师的通用语言 |
||
| SQL进阶 |
完成复杂分析的必备技能 |
||
| 大数据框架 |
HDFS&YARN |
大数据生态的底层基石 |
|
| Hive基础 |
大数据分析的常用工具 |
||
| Hive进阶 |
大数据分析师的高级装备 |
||
| Spark基础 |
排查问题必备的底层运行原理 |
||
| Spark SQL |
应对复杂任务的利刃 |
||
| 工具 |
Hue&Zeppelin |
通用的探索分析工具 |
|
| Azkaban |
作业管理调度平台 |
||
| Tableau |
数据可视化平台 |
||
| 业务基础 |
数据收集 |
数据是如何收集到的? |
|
| ETL工程 |
怎么清洗、处理和转化数据? |
||
| 数据仓库基础 |
如何完成面向分析的数据建模? |
||
| 元数据中心 |
如何做好数据治理? |
||
| 分析思维 |
数据分析思维方法论 |
怎么去分析一个具体问题? |
|
| 排查问题思维 |
如何高效排查数据问题? |
||
| 指标体系 |
怎么让数据成体系化? |
||
由于介绍的是基础知识,因此本文的主要内容是讲解面向数据分析的SQL基础知识。本文会从4个方面来讲解:
第1部分,数据库体系的一些基本概念。我们会提到数据库相关的一些重要概念,方便大家理解SQL的写法,更重要的是理解这些概念是与他人沟通SQL相关内容的前提。
第2部分,SQL查询的基本语法。我们会来讲解下SELECT子句的使用方法,如何完成一些针对单表的简单的统计分析。
第3部分,数据库函数、谓词和CASE表达式。我们会来介绍下常用的一些函数、用于判断真假的谓词和用于多条件判断的CASE表达式。
第4部分,关联查询和子查询。我们将会带大家学习下,如何把多张表连接起来,通过表交叉来获取更多的信息,以及使用子查询实现在查询的结果上继续分析。
由于不同数据库厂商,引擎实现各有不同,SQL的语法、关键字、函数等都略有差异,因此本文只拿在互联网公司使用最广泛的MySQL为例进行讲解,文中涉及的SQL和例子都是在MySQL中运行的。下面我们就进入正式的知识讲解。
1 数据库体系的一些基本概念
本部分的核心目标是让大家理解一些核心的基本概念,这些概念在日常工作中经常会提到和用到,因此理解了这些概念才能和团队其他小伙伴顺畅地沟通,愉快地协作。由于本文的重点是讲SQL,因此我们只讲解关系型数据库相关的概念。
1.1 数据库与数据库管理系统
我们通常口中所说的数据库,有两种含义,一是指实际存储数据的仓库,二是指抽象层面上容纳一组表的那个database。其中,表达后一种含义更常见。数据库管理系统,通常是指管理数据库的一套系统,通过它可以实现对数据的定义、插入、更新、删除、查询等操作,它提供了数据分析师与数据交互的窗口。
1.2 表
关系型数据库中的表,通常是指由行和列组成的用于存储数据的二维表。表是数据存储的直接载体,我们的数据通常都需要存储在表中。数据库基本上都是通过表来组织数据的。所以,表也是我们查询并获取数据最直接的对象。
对于表而言,有以下几个特性:
a. 表是由存在关联性的多列组成的,可以存储N多行数据,每行数据称为一条记录,行和列的交叉点唯一确定一个单元格
b. 表中的列名不重复,即列名需唯一
c. 表中的任意一列都只能存储一种数据类型的数据
1.3 数据类型
在不同的数据库管理系统中,支持的数据类型会略有差异,本文就以MySQL为例,介绍几种最常用的数据类型,分别如下所示:
数值类型
| 类型(有符号) |
大小 |
范围 |
描述 |
| TINYINT |
1字节 |
(-128 ~ 127) |
小整型,通常用于存储一些整型枚举值 |
| INT |
4字节 |
(-2,147,483,648 ~ 2,147,483,647) |
整型,使用频率较高 |
| BIGINT |
8字节 |
(-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807) |
长整型,通常存储比较大的数值 |
| FLOAT(n,d) |
4字节 |
与n和d的值有关 |
单精度浮点数(不精准表达) |
| DOUBLE(n,d) |
8字节 |
与n和d的值有关 |
双精度浮点数(不精准表达) |
| DECIMAL(p,d) |
与p和d 的值有关 |
与p和d的值有关 |
定点数(精准表达) |
日期类型
| 类型 |
示例 |
描述 |
| DATE |
2019-05-01 |
日期 |
| TIME |
12:23:34 |
时间 |
| DATETIME |
2019-05-01 12:23:34 |
日期时间 |
字符串类型
| 类型 |
范围 |
描述 |
| CHAR(n) |
n <= 255 |
定长字符串 |
| VARCHAR(n) |
n <= 65535 |
变长字符串 |
| TEXT |
0 - 65535字节 |
长文本数据 |
| MEDIUMTEXT |
0 - 16,777,215字节 |
中等长度文本数据 |
上面只是罗列出了几种最常用的数据类型,如果大家接触到了其他不常用的类型,可以自己在网上搜索一下相关的信息。
1.4 主键
主键是一列或多列的组合,用于标识表中唯一的一条记录。所以,它天然的一个属性就是不重复性,也不允许为NULL值。通常我们会使用自增的整型值来作为主键,由数据库管理系统来维护,既能保证唯一性,又使用起来很方便。一个表的主键,通常也会作为其他表引用的对象,即后面要讲到的外键。
1.5 外键
外键通常用来建立两张表之间的关联关系,一个表的外键通常是与之关联的另一个表的主键。这样在进行关联查询时,就可以通过两个表外键和主键之间的关系,将两张表连接起来,形成一张中间表,将两张表的信息融合,产生更大的价值。
1.6 索引
如果你想快速找到一本书中,你感兴趣的部分,你就会去查找目录,目录可以帮你快速定位到你想看的内容在哪一页。对于数据库中的表来说,索引就相当于是表的目录。其存在的主要目的就是为了加快查询速度。当然,索引也还有一些其他用途,其设计原理也是非常巧妙,我们会在下一篇SQL进阶文章中,详细讲解这块内容。
1.7 表关系
在关系型数据库中,表和表之间的关系通常有三种,1对1、1对多、多对多。为方便描述,我们假定有两张表,分别为表A和表B。
- 1对1,是指表A和表B通过某字段关联后,表A中的一条记录最多对应表B中的一条记录,表B中的一条记录也最多对应表A中的一条记录。
- 1对多,是指表A和表B通过某字段关联后,表A中的一条记录可能对应表B中的多条记录,而表B中的一条记录最多对应表A中的一条记录。
- 多对多,是指表A和表B通过某字段关联后,表A中的一条记录可能对应表B中的多条记录,而表B中的一条记录可能对应表A中的多条记录。
1对1 和 1对多关系,通常使用外键引用对应表的主键就可以表达。而多对多关系,通常需要使用中间表来表达,中间表中记录了两张表的主键的对应关系。
1.8 视图
如果一条SQL的结果在日常查询中经常被用到,我们通常就会考虑使用视图将其存储起来,下次再使用时直接读取视图,就会执行视图对应的SQL语句,非常地简洁方便。所以,视图就是一张虚拟的表。不过,值得注意的是,视图存储的是SQL语句,而不是SQL执行后的结果,其结果是每次执行时动态生成的,可能每次读取都会有变化。
1.9 集合
集合在数学领域表示“(各种各样的)事物的总和”,在数据库领域表示记录的集合。具体来说,表、视图和查询的执行结果都是记录的集合。是集合,就可以进行集合运算,如求并集、交集、差集等。另外,查询的执行结果也是集合,那么就可以把查询的结果再当做一个表,继续基于这个表做分析。这个便是子查询的理论基础。在第4部分,我们会详细讲到子查询。
2 SQL查询的基本语法
SQL是结构化查询语言(Structural Query Language)的简称,是开发者与数据库管理系统对话的语言。SQL用关键字、表名、列名、操作符等组合而成的一条语句,用来描述操作的内容。SQL是有国际标准的,因此其通用性不言而喻。
2.1 关键字
SQL有很多关键字,每个关键字的含义和用法都不相同。本文只罗列出在数据分析工作中与查询分析相关的常用的基础关键字及其含义,其中有一些会在下面的段落中详细讲解,如下表格所示:
| 关键字 |
描述 |
| SELECT |
后面跟用户想获取的列或计算公式 |
| FROM |
后面跟要读取数据的表 |
| LEFT/RIGHT/INNER JOIN |
后面跟要进行关联的表 |
| ON |
后面跟关联条件 |
| WHERE |
后面跟过滤条件,只有满足条件的行才会保留下来 |
| GROUP BY |
后面跟用来分组的列或计算公式 |
| HAVING |
后面跟分组后的过滤条件 |
| ORDER BY |
后面跟用于排序的列或计算公式 |
| LIMIT |
从结果中选取前N行,后面跟具体行数 |
| DISTINCT |
对后面跟的列进行去重 |
| COUNT |
对指定的一列或多列计数,会忽略掉NULL值 |
| SUM |
对指定的列求和,会忽略掉NULL值 |
| AVG |
对指定的列求平均值,会忽略掉NULL值 |
| MIN |
求指定列的最小值 |
| MAX |
求指定列的最大值 |
| ASC/DESC |
ASC表示升序排列,DESC表示降序排列,与ORDER BY配合使用 |
| [NOT] IN |
多条件搜索 |
| [NOT] LIKE |
模糊匹配 |
| REGEXP |
正则匹配 |
| AND/OR/NOT |
逻辑判断符 |
| [NOT] BETWEEN AND |
区间限定 |
| [NOT] EXISTS |
判断集合是否为空 |
| IS [NOT] NULL |
判断是否为NULL值 |
| UNION/UNION ALL |
求两个集合的并集,UNION会剔除结果集中的重复记录,UNION ALL则会保留重复记录 |
| AS |
取别名或用于使用查询结果集创建表 |
| * |
单独出现或出现在"."后面表示表中的所有列,出现在两个字段间表示乘法 |
2.2 书写规则
SQL的书写规则非常简单灵活,但是如果不注意,也是很容易犯错的,工作中常用的规则如下:
a. 关键字、表名和列名等大小写不敏感;
b. 使用全英文半角(关键字、空格、符号)来书写;
c. SQL语句以分号结尾;
d. SQL语句的单词及运算符之间需使用半角空格或换行符来进行分隔;
e. 函数名和括号是一个整体,中间不能有空格,空参数函数括号不能省略;
f. 数字常量直接书写,如 20 ;
g. 日期和字符串常量需要使用英文单引号包裹起来,如 '2002-10-01 12:23:21','Lily';
h. 注释的三种写法:单行注释(#,--)和多行注释(/* */)。单行注释推荐使用"--"。
2.3 简单查询
最简单的查询语句莫过于"SELECT * FROM A",其中A表示数据表名A,这条
SQL的含义是从表A中查询出所有列的所有数据。"*"代表表A中的所有列,是一种简写形式。我们就从这条最简单的SQL开始,逐渐添加关键字,最后变成一条复杂的SQL。
接下来我们要讲解的简单查询,都是针对单个表的查询。针对单表的查询虽然比较简单,但是却是复杂查询的基础。为了方便演示,我们先定义一个数据表student,用于存储学生的信息,表里的数据如下所示:

从左到右列的含义依次为学号、姓名、年龄、英语成绩、数学成绩、总成绩。
2.4 过滤
如果要对表中的数据进行过滤,只保留满足我们需求的数据,那就要用到WHERE关键字了。WHERE关键字后跟的是由逻辑运算符连接的一个或多个表达式,每个表达式的最终结果为TRUE或FALSE,只保留表达式结果为TRUE的行。
例如,我们要获取英文成绩不合格的学生姓名和学号,则对应的SQL为
SELECT sno, nameFROM studentWHERE eng_score < 60运行结果如下:
| sno |
name |
| 22270202 |
Lily |
| 22270203 |
Tom |
2.5 运算符
运算符,顾名思义就是用于做运算的符号。常见的运算符有三种,比较运算符、算术运算符和逻辑运算符。
| 比较运算符 |
含义 |
| = |
等值比较 |
| > |
大于 |
| < |
小于 |
| >= |
大于或等于 |
| <= |
小于或等于 |
| <> |
不等于 |
不等于的判断,目前绝大部分的数据库管理系统厂商也都支持了"!="运算符,与"<>"表达的含义相同。
| 算术运算符 |
含义 |
| + |
加法运算 |
| - |
减法运算 |
| * |
乘法运算 |
| / |
除法运算 |
算术运算符在书写时可以紧挨着字段名写,如eng_score-math_score,所以字段名和表名的命名中不能使用中划线("-"),否则它会被误判为是在做减法运算的。
| 逻辑运算符 |
含义 |
| AND |
与,并且 |
| OR |
或,或者 |
| NOT |
非,取反 |
当存在多种逻辑运算符时,为了避免歧义,需要使用括号来界定执行的先后顺序,使用括号组织的表达式,可读性也会更强。建议大家不要去记忆逻辑运算符的优先级,容易记混,而且写出的SQL可读性比较差,最好是使用括号,来厘清多个逻辑条件的关系,清晰易懂,可读性强,不容易出错。
了解了上面这些运算符,我们便可以通过组合各种运算符,书写出WHERE后面复杂的表达式,来满足我们的过滤需求了。
2.6 分组聚合
分组聚合是指,我们可以将表中的数据,根据某一列或多列进行分组,然后将其他列的值进行聚合计算,如计数、求和和求平均值等。用到的关键字是GROUP BY,对于分组后的计算结果,我们还可以使用HAVING进行过滤。
例如,从student表中,求出不同年龄的人数、英语总成绩和数学成绩的平均值,且过滤掉。对应的SQL为
SELECT age, COUNT(sno) AS student_num,SUM(eng_score) AS sum_eng_score,AVG(math_score) AS avg_math_scoreFROM studentGROUP BY ageHAVING avg_math_score >= 60
运行后结果如下所示:
| age |
student_num |
sum_eng_score |
avg_math_score |
| 10 |
2 |
138 |
70.5 |
| 12 |
1 |
89 |
82 |
这里需要注意的是,出现在group by后面的字段或计算公式,必须出现在对应的select的后面,并且除了这些字段或计算公式外,select后面不能有其他字段,只能使用聚合函数。
2.7 去重
DISTINCT关键字用于对一列或多列去重,返回剔除了重复行的结果。DISTINCT对多列去重时,必须满足每一列都相同时,才认为是重复的行进行剔除。DISTINCT不会过滤掉NULL值,但去重后的结果只会保留一个NULL值。
例如,从student表中,找出有几种年龄的学生,即求出去重后的年龄。对应的SQL为
SELECT DISTINCT age FROM student运行后的结果如下所示:
| age |
| 10 |
| 11 |
| 12 |
2.8 排序
日常生活场景里,我们经常对各种各样的排名比较感兴趣,比较关注排在前面的内容。在数据库中,求出排名,就需要用到ORDER BY子句。ORDER BY通常配合ASC和DESC使用,可以根据一列或多列,进行升序或降序排列,之后使用LIMIT取出满足条件的前N行。
例如,从student表中,求出数学成绩最好的前3名学生的姓名、年龄和其数学成绩。对应的SQL如下:
SELECT name, age, math_scoreFROM studentORDER BY math_score DESCLIMIT 3
运行后的结果为:
| name |
age |
math_score |
| Jack |
12 |
82 |
| Alice |
10 |
76 |
| Tom |
10 |
65 |
2.9 增加常量列
增加常量列,即把某一固定的常量值做为一列添加到我们的结果数据中。这种做法的应用场景,通常是结果集中所有的行在某个属性上值是相同的,这时便可以通过增加常量列的方式,来增加这一列。我们通过下面的例子来演示其语法形式。
例如,从student表中,查询英语成绩大于80分的学生的姓名和学号,并把他们都分入A班。对应的SQL如下:
SELECT sno, name, 'A' AS class FROM student WHERE eng_score > 80运行后的结果为:
| sno |
name |
class |
| 22270201 |
Alice |
A |
| 22270204 |
Jack |
A |
从示例中可以看出,直接通过"常量 AS 新列名"的方式就可以增加常量列,非常地方便。
3 数据库函数、谓词和CASE表达式
SQL之所以具有强大的分析表达能力,其中一个重要原因,就是它具备丰富的函数,通过这些函数的组合可以实现对数据的复杂处理,最终得到我们想要的数据。另外一方面,SQL也有丰富的谓词来对数据进行判断,匹配出符合我们需求的数据。CASE表达式是一种多条件判断表达式,可以根据不同条件返回不同的值,类似于编程语言中的IF ELSE。
3.1 聚合函数
聚合函数,又称分析函数,是将一组值通过聚合分析后得到一个值,因此得名聚合函数。使用频率最高的聚合函数有5个,如下表所示
| 函数名 |
含义 |
| COUNT |
计数 |
| SUM |
求和 |
| AVG |
求平均值 |
| MIN |
求最小值 |
| MAX |
求最大值 |
聚合函数有一个共同的特点,即在计算过程中都会忽略掉NULL值,因为对NULL的聚合是没有任何意义的。COUNT、SUM和AVG三个函数还可以和DISTINCT配合使用,其含义为先对目标列进行去重,之后再对去重后的结果聚合。SUM和AVG只能应用于一列,且列的数据类型为数值型。MIN和MAX也是只能应用于一列,不过除了支持数值型外,还支持字符串类型和日期类型。COUNT可以应用于一列或多列,而且不限制列的类型。
3.2 算术函数
算术函数,主要用于对数值类型进行各种数学运算。SQL中除了加减乘除(+-*/)四个运算符外,还提供了一系列的算术函数,如下表所示:
| 函数名 |
含义 |
| CEIL(x) |
向上取整 |
| FLOOR(x) |
向下取整 |
| ABS(x) |
求绝对值 |
| ROUND(x, d) |
四舍五入,对x保留d位小数 |
| POWER(x, y) |
幂运算,求x的y次方 |
| MOD(x, y) |
取余数,求x被y整除后的余数 |
| RAND([n]) |
返回0-1.0的随机数,n为随机种子,可以省略不写 |
这里只罗列了常用的一些函数,通过他们之间的组合,可以实现复杂的运算,如果上述表格不满足你的分析需求,可以自行Google或查看官方文档,寻找匹配的算术函数。
3.3 日期函数
日常分析工作中,经常需要对日期进行加减、格式化等处理,这就离不开强大的日期处理函数,常用的日期函数如下:
| 函数名 |
含义 |
| CURDATE() |
返回当前日期 |
| CURRENT_DATE() |
返回当前日期,和上面的函数作用相同 |
| CURRENT_TIME() |
返回当前时间 |
| NOW() |
返回当前的日期和时间 |
| DATE_ADD(d, interval n unit) |
返回日期d加上n个单位后的时间,unit为具体单位,如day,表示天 |
| DATE_SUB(d, interval n unit) |
返回日期d减去n个单位后的时间,unit为具体单位,如day,表示天 |
| DATE_DIFF(d1, d2) |
返回日期d1和日期d2的天数差 |
| DATE_FORMAT(d, 'format_exp') |
返回使用日期格式表达式format_exp格式化日期d后得到的字符串 |
| YEAR(d) |
返回日期d的年份 |
| MONTH(d) |
返回日期d的月份 |
| DATE(d) |
返回日期时间d的日期部分,舍弃时间部分 |
日期函数用于获取当前日期时间的函数多数是空参数函数,虽然参数为空,但是函数名后的括号不能省略不写。数据库厂商虽然也提供了部分与函数名相同的属性值,不带括号也能调用,不过笔者建议最好还是使用函数带上空括号,这样识别度更高,可读性更好。
3.4 字符串函数
字符串是信息的一个重要载体,其中包含着大量的重要信息,因此对字符串的处理非常重要,相应地字符串处理函数也是非常丰富,以下我们罗列出最常用的一些函数:
| 函数 |
含义 |
使用示例 |
返回值 |
| LENGTH(str) |
求字符串str的长度 |
LENGTH('bigdata') |
7 |
| INSTR(str, substr) |
返回substr在str第一次出现的位置(str不包含substr时返回0) |
INSTR('bigdata', 'data') |
4 |
| LEFT(str, len) |
返回str的左端len个字符 |
LEFT('bigdata',3) |
'big' |
| RIGHT(str, len) |
返回str的右端len个字符 |
RIGHT('bigdata',4) |
'data' |
| SUBSTRING(str, pos, len) |
返回str的从位置pos起len个字符 |
SUBSTRING('bigdata',4,4) |
'data' |
| SUBSTRING_INDEX(str, delim, count) |
当count为正数时,从左找到第count个分隔符delim所在位置,并返回其左侧的字符;否则从右开始找,并返回对应位置右侧的字符 |
SUBSTRING_INDEX('180.97.33.108', '.', 3) |
'180.97.33' |
| REPLACE(str, from_str, to_str) |
返回用to_str替换str中的from_str后的字符串 |
REPLACE('bigdata', 'big', 'Big') |
'Bigdata' |
| LOWER(str) |
返回str转小写后的字符串 |
LOWER('Bigdata') |
'bigdata' |
| UPPER(str) |
返回str转大写后的字符串 |
UPPER('Bigdata') |
'BIGDATA' |
| CONCAT(str1, str2,...) |
将参数连接起来并返回 |
CONCAT('big', 'data') |
'bigdata' |
| CONCAT_WS(delim, str1, str2,...) |
将参数使用分隔符delim连接起来并返回 |
CONCAT_WS('_', 'big', 'data') |
'big_data' |
3.5 转换函数
当某些数据的类型与我们需要的类型不符时,可以使用类型转换函数,将其类型转换为我们需要的类型。常用的类型转换函数有两个,分别为CAST和CONVERT,两个函数的作用是相同的,只是语法略有不同。CAST函数的用法为CAST(字段 AS 数据类型),而CONVERT的用法为CONVERT(字段, 数据类型)。
不过,并不是所有的类型都是可以互相转换的,而且有些转换会导致精度的损失,因此请谨慎使用。
3.6 其他函数
还有一些函数是使用在特定用途上的,本文也罗列出几个数据分析工作中常用的。
MD5函数,其作用是生成等长的信息摘要。在数据分析工作中,经常用于对敏感信息的脱敏,因为很难通过md5值反向推断加密前的内容,因此是非常安全的。其使用方法为,MD5(str),返回对str进行md5算法计算得到的校验和字符串。
IFNULL(expr1, expr2):如果expr1不为NULL,则返回expr1,否则返回expr2。通常用于对某个字段的NULL值填补,也叫缺失值填补。
IF(expr1, expr2, expr3):如果expr1不等于0或者不为NULL,则返回expr2的值,否则返回expr3的值。相当于编程语言中的IF ELSE条件判断语句
3.7 谓词
简单来说,谓词就是用于真假判断的关键字,用来判定两个对象间关系论断的真假,返回值只有真或假。这么说可能还是有点抽象。我们来举一些谓词的例子大家就明白了。
例如,我们前面讲到的比较运算符,就都属于谓词的范畴。还有一些其他谓词如下表所示:
| 谓词 |
含义 |
| [NOT] LIKE |
模糊匹配,通常配合%和_使用 |
| [NOT] IN |
多值包含关系判断 |
| [NOT] BETWEEN ... AND ... |
区间判断 |
| IS [NOT] NULL |
是否为NULL值判断 |
| [NOT] EXISTS |
是否为空集合判断 |
| [NOT] REGEXP |
是否满足正则表达式判断 |
3.8 CASE表达式
SQL语句中的CASE表达式,对应着编程语言中的条件分支,起到多条件判断返回多种值的作用。其语法形式为:
CASE
WHEN <求值表达式1> THEN <表达式1>
WHEN <求值表达式2> THEN <表达式2>
WHEN <求值表达式3> THEN <表达式3>
......
ELSE <表达式> END
其执行过程为,按照书写顺序,依次判断WHEN后面求值表达式返回的值为真或假,如果返回值为假,则继续向下搜索;如果返回值为真时,执行THEN后面对应的表达式,将执行后的值返回,CASE表达式退出;如果所有WHEN子句都不满足时,则执行ELSE后面的表达式,返回执行后得到的值,CASE表达式退出。
了解了执行过程,那么在书写CASE表达式时,就一定要注意顺序问题。这里需要注意一点的是,如果执行到第二个THEN的时候,实际生效的条件为<求值表达式1>的值为假,与此同时<求值表达式2>的值为真;如果执行到第三个THEN的时候,实际生效的条件为<求值表达式1>和<求值表达式2>的值都为假,与此同时<求值表达式3>的值为真,往后以此类推。
3.9 NULL值判断
NULL值的判断必须使用谓词IS,因为NULL和其他任何值(包括NULL值)比较结果都为NULL,也就对应着假。这一点很好理解,你可以把NULL值理解为未知。未知和任何值比较结果还是未知,未知和未知比较,结果也只能是未知。
4 关联查询与子查询
拥有了前面3部分的知识基础,那么我们就可以开始学习SQL的复杂查询。本文要讲的复杂查询有两个,一个是关联查询,一个是子查询。首先,我们先来看下他们的理论基础,集合运算。
4.1 集合运算
在第1部分,我们提到过,在数据库领域,集合是指一组记录的总和,它可以指代表,也可以指代视图、查询执行的结果。所以,表和查询执行的结果都是集合,那么就都可以参与集合运算。也就是说,可以把查询执行的结果看做是一张中间表或临时表,继续参与运算,这就是子查询的理论基础。
集合运算主要包含四种,并集、交集、差集和笛卡尔积。
并集,是求两个集合合并后的集合。在MySQL中使用关键字UNION或UNION ALL实现,两者的区别是,UNION会剔除掉合并后集合中的多余重复值,只保留一份;而UNION ALL,不会剔除重复值。因此,UNION操作,运行结束后,可能会导致记录数的减少。
交集,是求两个集合都共同拥有的元素的集合。在MySQL中没有提供专门的关键字,而是通过内关联实现的,下一小结会详细介绍。
差集,是求在一个集合中存在而在另一个集合中不存在的元素的集合。差集计算具有方向性,同样的,MySQL也没有提供差集计算的关键字,而是需要通过左/右关联然后再过滤出未关联成功的记录而得到。
笛卡尔积,是将两个集合中记录两两组合,相当于集合的乘法。它是关联查询的数学理论基础。你可以简单理解为,关联查询的过程就是,先做笛卡尔积,然后再通过on条件过滤出符合条件的记录。当然,实际的执行过程,不会这么简单,但是是在这个流程基础上去做优化,减少计算量的。
在进行集合的并集、交集和差集运算时,需要注意的是:
-
参与运算的两个集合记录的列数必须相同
-
参与运算的两个集合对应位置的列的类型必须一致
-
如果使用ORDER BY子句,必须写在最后
4.2 表关联类型
常见的表关联类型有四种,内连接(INNER JOIN)、左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)、全外连接(FULL OUTER JOIN)。
关联的语法比较简单,拿内连接举例,书写为,A INNER JOIN B ON expr。其中,A和B表示两个表的名称,也可以是子查询。ON后面跟的expr表示关联条件,通常是由表A和表B关联字段组成的表达式。
内连接(INNER JOIN),通常可以省略掉INNER不写,它的含义是左右两个集合相乘后,只保留满足ON后面关联条件的记录。所以,可以利用内连接计算两个集合的交集,只需要把集合元素的字段都写在ON后面的关联条件里即可。
左外连接(LEFT OUTER JOIN),OUTER通常可以省略不写,它的含义是,左右两个集合相乘后,保留满足ON后面关联条件的记录加上左表中原有的但未关联成功的记录。因此,左外连接,可以用来计算集合的差集,只需要过滤掉关联成功的记录,留下左表中原有的但未关联成功的记录,就是我们要的差集。
右外连接(RIGHT OUTER JOIN),与左外连接含义相同,只是方向不同而已,通常也是省略OUTER不写。
全外连接(FULL OUTER JOIN),含义是,左右两个集合相乘后,保留满足ON后面关联条件的记录加上左表和右表中原有的但未关联成功的记录。

4种JOIN方式的示意图
4.3 多表关联
多表关联的本质,还是两两关联。例如,表A内关联表B再内关联表C,实际上就可以等价于表A内关联表B,运行后的结果作为一张中间表,然后再与表C内关联。所以,执行过程仍然是两两关联。
4.4 表关联注意事项
表关联是比较复杂的查询方式,在书写时,大家要在脑海中构建关联后的集合的样子,对应去选择需要使用的连接方法。下面是根据实际工作经验总结的容易出错的点,希望大家注意。
a. 使用UNION可能会导致记录数的减少,在使用聚合函数时,可能会导致计算出现偏差
b. 在使用1对多或多对多关系的表进行关联时,记录数可能会增多,也可能会导致计算出现偏差
c. 左外连接和右外连接都有连接方向的问题,表放的位置对结果是有影响的,尤其是多表关联时,一定要关注书写的顺序,尽可能先做内连接再做左/右外连接。
d. 尽量避免使用交叉连接
4.5 子查询
子查询,就是指被括号嵌套起来的查询SQL语句,通常是一条完整的SELECT语句。
子查询放在不同的位置,起到的作用也是不同的。它经常出现在3个位置上,分别是SELECT后面、FROM/JOIN后面,还有WHERE/HAVING后面。
- 当子查询出现在SELECT后面时,其作用通常是要为结果添加一列。不过,这里要注意的是,在SELECT后使用的子查询语句只能返回单个列,且要保证满足条件时子查询语句只会返回单行结果。企图检索多个列或返回多行结果将引发错误。
- 子查询出现在FROM/JOIN后面,是我们最常用的方式,就是将子查询的结果作为中间表,继续基于这个表做分析。
- 当子查询出现在WHERE/HAVING后面时,则表示要使用子查询返回的结果做过滤。这里根据子查询返回的结果数量,分三种情况,即1行1列、N行1列、N行N列。
- 当返回结果为1行1列时,实际上就是返回了一个具体值,这种子查询又叫标量子查询。标量子查询的结果,可以直接用比较运算符来进行计算。
- 当返回结果是N行1列时,实际上就是返回了一个相同类型数值的集合。因此可以使用IN谓词判断,同时也可以配合ANY、SOME、ALL等关键字使用。
- 当返回结果是N行N列时,实际上就是返回一个临时表,这时就不能进行值的比较了,而是使用EXISTS谓词判断返回的集合是否为空。

大数据俱乐部、数据与智能: https://blog.csdn.net/weixin_39032019/article/details/117997723
整理不易,【评论、点赞、收藏】 是对我最最最大的支持!!!