4月week2文献阅读2:MOBCdb: a comprehensive database integrating multi‑omics data on breast cancer for precision medicine
MOBCdb:一个综合了乳腺癌多组学数据的精确医学数据库
Abstract
Background :
Breast cancer is one of the most frequently diagnosed cancers among women worldwide, characterized by diverse biological heterogeneity.
乳腺癌是世界范围内女性最常被诊断的癌症之一,具有多样性的生物学异质性。
It is well known that complex and combined gene regulation of multi-omics is involved in the occurrence and development of breast cancer.
众所周知,多组学中复杂和结合的基因调控参与了乳腺癌的发生发展。
Results:
In this paper, we present the Multi-Omics Breast Cancer Database (MOBCdb), a simple and easily accessible repository that integrates genomic, transcriptomic, epigenomic, clinical, and drug response data of different subtypes of breast cancer.
在本文中,我们介绍了多组学乳腺癌数据库(MOBCdb),这是一个简单易用的存储库,集成了不同亚型乳腺癌的基因组、转录组、表观基因组、临床和药物反应数据。
MOBCdb allows users to retrieve simple nucleotide variation (SNV), gene expression, microRNA expression, DNA methylation, and specific drug response data by various search fashions.
MOBCdb允许用户通过各种搜索方式检索简单核苷酸变异(SNV)、基因表达、microRNA表达、DNA甲基化和特定药物反应数据。
The genome-wide browser /navigation facility in MOBCdb provides an interface for visualizing multi-omics data of multi-samples simultaneously.
MOBCdb中的全基因组浏览器/导航功能为同时显示多样本的多组数据提供了一个接口。
Furthermore, the survival module provides survival analysis for all or some of the samples by using data of three omics.
此外,生存模块利用三个组学的数据为所有或部分样本提供生存分析。
The approved public drugs with genetic variations on breast cancer are also included in MOBCdb.
经批准的具有乳腺癌基因变异的公共药物也包括在MOBCdb中。
Conclusion: In summary, MOBCdb provides users a unique web interface to the integrated multi-omics data of different subtypes of breast cancer, which enables the users to identify potential novel biomarkers for precision medicine.
综上所述,MOBCdb为用户提供了一个针对不同亚型乳腺癌的综合多组学数据的独特web界面,使用户能够识别出可能用于精准医疗的新型生物标志物。
Keywords :Precision medicine · Breast cancer · Multi-omics · Genome · Transcriptome · Epigenome · Databas
关键词精准医学·乳腺癌·多组学·基因组·转录组·表观基因组·数据库
Introduction
Breast cancer is the most frequently diagnosed cancer (accounting for 30% of cancer cases) and the second leading cause of cancer-related mortality (14% of cancer deaths) among women in the United States [1].
乳腺癌是美国女性中最常见的癌症(占癌症病例的30%),也是癌症相关死亡的第二大原因(占癌症死亡的14%)。
Moreover, the high incidence rate has also been reported in Europe and China [2, 3].
此外,欧洲和中国也报道了高发病率[2,3]。
Breast cancer is highly heterogeneous, its molecular subtypes stratified on the basis of microarray-based gene expression comprise luminal A, luminal B, HER2-enriched, basal-like, and normal-like [4].
乳腺癌具有高度异质性,其分子亚型以微阵列基因表达为基础分层,包括luminal A、luminal B、her2富集、basal-like和normal-like[4]。
Adjuvant endocrine therapy and chemotherapy are extensively used for the treatment of luminal breast cancer [5].
辅助内分泌治疗和化疗广泛应用于腔内乳腺癌[5]的治疗。
Two approved HER2-targeted agents (trastuzumab and lapatinib) are used for the treatment of HER2-enriched breast cancer [6].
两种经批准的her2靶向药物(曲妥珠单抗和拉帕替尼)用于治疗her2富集的乳腺癌[6]。
However, currently available targeted systemic therapy seems not quite effective on patients with basal-like breast cancer [7].
然而,目前可用的靶向全身治疗对基底样乳腺癌[7]患者似乎并不十分有效。
With the rapid development of next-generation sequencing, massive omics data of breast cancer have been produced.
随着下一代测序技术的迅速发展,已经产生了大量的乳腺癌组学数据。
Compared to using single-omics data [4, 8], integrating multiple omics is more effective in identifying specific cancer subtypes and finding novel biomarkers [9].
与使用单一组学数据相比[4,8],整合多个组学在识别特定癌症亚型和寻找新的生物标志物[9]方面更有效。
Integrating multi-omics data for the identification of molecular patterns associated with a disease is popular in life science research [10, 11].
整合多组学数据来识别与疾病相关的分子模式在生命科学研究中很受欢迎[10,11]。
Some integration methods have shown significant clinical implications [9, 12].
一些整合方法已显示出重要的临床意义[9,12]。
An integrated web interface for breast cancer data storage, retrieval, and visualization is urgent and critical to deal with the increasing amount of multi-omics breast cancer data for precise medicine applications.
一个用于乳腺癌数据存储、检索和可视化的集成web界面对于处理越来越多的用于精确医学应用的多组学乳腺癌数据是迫切和关键的。
(目前现状以及多组学乳腺癌数据库建立的必要性)
Over the past years, several databases have been developed for the storage and analysis of breast cancer data [13–17].
在过去的几年里,已经开发了几个数据库来存储和分析乳腺癌数据[13-17]。
Among them, BIC [13] (Breast Cancer Information Core by National Human Genome Research Institute) is an open-access database dedicated to creating a catalog of all the reported mutations and polymorphisms in BRCA1 and BRCA2.
其中,BIC13是一个开放存取数据库,致力于创建一个目录,所有报告的突变和多态性在BRCA1和BRCA2。
It has a collection of 3416 and 2292 entries describing the genetic variants of BRCA1 and BRCA2, respectively, with detailed detection protocols and technologies.
它收集了3416和2292个条目,分别描述了BRCA1和BRCA2的遗传变异,并提供了详细的检测协议和技术。
BCGD [14] (Breast Cancer Gene Database by Baylor College of Medicine) is a compendium of molecular data related to 60 genes involved in breast cancer, most of the data were extracted from published biomedical research papers/articles.
BCGD [14] (Baylor College of Medicine乳腺癌基因数据库)是一个与乳腺癌相关的60个基因相关的分子数据的汇编,其中大部分数据是从已发表的生物医学研究论文/文章中提取的。
Both BIC and BCGD are based on published information of different biological processes at genomic level, transcriptomic level, proteomic level, etc.
BIC和BCGD均基于已发表的基因组水平、转录组水平、蛋白质组水平等不同生物学过程的信息。
However, these two databases do not provide arranged raw data to users for identifying new biomarkers of breast cancer.
然而,这两个数据库并没有为用户提供经过整理的原始数据来识别新的乳腺癌生物标志物。
Unlike BIC and BCGD, ROCK [15] is a resource of microarray gene expression data, DNA copy numbers, and RNA interferences screening data from breast cancer cell lines and tumor samples.
与BIC和BCGD不同,ROCK[15]是一种来自乳腺癌细胞系和肿瘤样本的微阵列基因表达数据、DNA拷贝数和RNA干扰筛选数据的资源。
However, these different types of data were collected from different samples, which make data integration, analysis, and utilization very complicated or even impossible.
然而,这些不同类型的数据是从不同的样本中收集的,这使得数据集成、分析和利用非常复杂,甚至是不可能的。
Another database, G2SBC [16] (Genes-to-Systems Breast Cancer) is an integrated data source of genes, transcripts, and proteins of breast cancer cell lines described in the literature.
另一个数据库G2SBC16是文献中描述的乳腺癌细胞系的基因、转录本和蛋白质的综合数据源。
So we can see that the existing breast cancer databases not only have very limited amounts of data, but also are relatively incomplete, which makes them not quite suitable for precise medicine applications.
所以我们可以看到现有的乳腺癌数据库不仅数据量非常有限,而且相对不完整,这使得它们不太适合精确的医学应用。
(目前已存数据库的局限性:)
On the other hand, the Cancer Genome Atlas (TCGA) has collected detailed omics data and clinical records of various cancers, including breast cancer.
另一方面,癌症基因组图谱(TCGA)收集了包括乳腺癌在内的各种癌症的详细组学数据和临床记录。
It is more like a primary data source even though the data were classified into from level 1 to level 3, and the users could hardly access directly to the huge raw data.
它更像是一个主数据源,虽然数据被划分为1级到3级,但是用户很难直接访问这些庞大的原始数据。
cBioPortal [18, 19] provides a web resource for exploring, visualizing, and analyzing multidimensional TCGA data, and the interactive exploration and graphical summary of TCGA data make complex cancer genomics profiles accessible.
cBioPortal[18,19]提供了一个用于探索、可视化和分析多维TCGA数据的web资源,对TCGA数据的交互式探索和图形化总结使复杂的癌症基因组学概要文件变得可访问。
However, cBioPortal lacks genome browser and analysis tools for integrated multi-omics, as well as targeted drug information.
然而,cBioPortal缺乏用于整合多组学和靶向药物信息的基因组浏览器和分析工具。
To support precise medicine application to breast cancer, we constructed the Multi-Omics Breast Cancer Database (MOBCdb in short).
为了支持乳腺癌的精准用药,我们构建了乳腺癌多组学数据库(MOBCdb)。
MOBCdb extracted SNV, gene expression, microRNA expression, DNA methylation data, and clinical records from TCGA, and integrated these data with breast cancer-related drugs from pharmGKB [20] under a web interface.
MOBCdb从TCGA中提取SNV、基因表达、microRNA表达、DNA甲基化数据和临床记录,并将这些数据与药物基因学知识库[20]中的乳腺癌相关药物在web界面下整合。
Besides, MOBCdb modified the JBrowse genome browser [21] to support the visualization of multi-omics data on genome-wide at the same time.
此外,MOBCdb还对JBrowse基因组浏览器[21]进行了修改,支持同时在全基因组上显示多组数据。
Furthermore, MOBCdb has a survival analysis tool that provides the Kaplan–Meier curve and statistical information relevant to clinical factors.
此外,MOBCdb有一个生存分析工具,提供Kaplan-Meier曲线和与临床因素相关的统计信息。
Last but not least, MOBCdb collected drug data for specific genetic variants, which may be essential to the interpretation of biological omics data for clinical implications.
最后但并非最不重要的是,MOBCdb收集了特定基因变异的药物数据,这可能对解释具有临床意义的生物组学数据至关重要。
Currently, MOBCdb is freely available at the URL:http://bigd.big.ac.cn/MOBCdb/.
目前,MOBCdb可以通过以下URL免费获得:http://bigd.big.ac.cn/MOBCdb/。
(MOBCdb数据来源以及数据库特性)
MOBCdb: an overview
MOBCdb:概述
SNV, gene expression, microRNA expression, DNA methylation, and clinical data of breast cancer were extracted from the level 3 datasets of TCGA portal (https ://cance rgeno me.nih.gov/).
从TCGA门户网站的三级数据集(https://cancergenome.nih.gov/)中提取乳腺癌的SNV、基因表达、microRNA表达、DNA甲基化和临床数据。
More than 10,000 files were stored in MOBCdb.
MOBCdb中存储了超过10,000个文件。
The details regarding the number of samples and data types are shown in Supplementary Table 1.
关于样本数量和数据类型的详细信息见补充表1。
Access to the protected data on SNV is authorized, and the annotations of SNV data can be utilized by annovar [22] with build hg38.
授权对SNV上受保护数据的访问,annovar[22]使用build hg38可以使用SNV数据的注释。
The basic gene annotation file was downloaded from GENECODE and NCBI.
基本基因注释文件从GENECODE和NCBI下载。
The microRNA annotation file was downloaded from miRBase version 21 [23].
microRNA注释文件是从miRBase version 21[23]下载的。
Information regarding the correlation of drugs with specific genetic variants was gathered from PharmGKB [20].
从药物基因学知识库[20]中收集有关药物与特定遗传变异之间关系的信息。
(MOBCdb的信息来源)
To process the SNV data, four tools including MuSE, MuTect2, SomaticSniper, and VarScan2 were equipped.
为了处理SNV数据,我们配备了MuSE、MuTect2、SomaticSniper和VarScan2四个工具。
As the results from these tools vary a lot, we dealt with each SNV by using from one to four tools.
由于这些工具的结果差异很大,我们使用1到4个工具来处理每个SNV。
There are 41355226 records in SNV data.
SNV数据中有41355226条记录。
The gene expression data contain three forms: Count, FPKM, and FPKM_UQ.
基因表达数据包括三种形式:Count、FPKM和FPKM_UQ。
The ensemble gene id was used in gene expression level3 data so that the counts of ensemble gene id in three forms are consistent.
在基因表达水平3的数据中使用了集成基因id,使三种形式的集成基因id计数一致。
The genecode v25 basic annotation (ftp://ftp.sanger.ac.uk/pub/gencode/Gencode_human/release_25/) was used to translate ensemble id to gene name.
使用genecode v25 basic注释(ftp://ftp.sanger.ac.uk/pub/gencode/Gencode_human/release_25/)将集成id翻译为基因名。
There are 43084054 records in gene expression data.
基因表达数据有43084054条记录。
The microRNA data have two forms: read count and reads per million miRNA mapped.
microRNA数据有两种形式:读计数和每百万miRNA的读图。
There are 2270367 records in microRNA expression data.
microRNA表达数据中有2270367条记录。
The DNA methylation data consist of two datasets: a 27 K dataset and a 450 K dataset.
DNA甲基化数据由两个数据集组成:27k数据集和450k数据集。
The former has 27578 CpG sites and the latter has 485578 CpG sites.
前者有27578个CpG站点,后者有485578个CpG站点。
There are 361238969 records in the DNA methylation data.
DNA甲基化数据中有361238969条记录。
The variant-related drug information collected from pharmGKB contains variant, pmid, drug, gene, p value, race, association, etc.
从药物基因学知识库中收集到的与变异体相关的药物信息包括变异体、pmid、药物、基因、p值、种族、关联等。
There are 986 records in drug data.
药品数据有986条记录。
(各数据类型的记录数,处理)
The genome-wide browsed data were from the data mentioned above.
全基因组浏览数据来自上述数据。
The browsed data include SNV, gene expression, microRNA expression, DNA methylation, and clinical information.
浏览的数据包括SNV、基因表达、microRNA表达、DNA甲基化和临床信息。
The SNV data were rearranged to VCF form with clinical factor in the last column joined by semicolon.
将SNV数据重新排列为VCF格式,最后一列用分号连接临床因子
The gene expression and microRNA expression data were rearranged to GFF form with clinical factor in the last column joined by semicolon.
将基因表达和microRNA表达数据重新排列为GFF形式,并在最后一列中加入临床因子分号。
The DNA methylation data were transformed to BigWig.
将DNA甲基化数据转化为BigWig。
(各类型数据格式)
MOBCdb was implemented with Linux, Apache, MySQL, Strust, and MyBatis, which form an open source development environment for users to add new data and develop new web applications easily.
MOBCdb是使用Linux、Apache、MySQL、Strust和MyBatis实现的,这为用户提供了一个开源的开发环境,可以方便地添加新数据和开发新的web应用程序。
Multi-omics raw data were processed by Perl and R. The omics data were stored in a MySQL relational database system (version 5.6.19).
组学数据存储在MySQL关系数据库系统(5.6.19版本)中。
The omics data were organized in two forms: MySQL tables and files to facilitate efficient access for general retrieval and JBrowse.
组学数据以两种形式组织:MySQL表和文件,以方便对普通检索和JBrowse的高效访问。
The computing component of Survival analysis was implemented by R. The browser-based interfaces of different omics data include various figures, which were developed with a number of web front techniques, including JavaScript, CSS, and Highchart.
生存分析的计算组件由r实现。不同组学数据的基于浏览器的接口包括各种图形,这些图形是用JavaScript、CSS和Highchart等多种web前端技术开发的。
(网站开发架构,工具,以及数据存储形式)
Multiple ways to search breast cancer omics data
The search section comprises four different components in terms of the data to be searched: somatic mutation, gene expression, miRNA expression, and DNA methylation.
搜索部分根据需要搜索的数据包括四个不同的成分:体细胞突变、基因表达、miRNA表达和DNA甲基化。
MOBCdb offers multiple methods to efficiently retrieve information, including gene, miRNA, cgid, and chromosomal region.
MOBCdb提供了多种有效检索信息的方法,包括基因、miRNA、cgid和染色体区域。
MOBCdb was designed to provide a userfriendly web interface for data search.
MOBCdb旨在为数据搜索提供一个用户友好的web界面。
For example, a dictionary of entry names (e.g., gene names) in the database was integrated into the search bar so that the users can get candidate names to conveniently form queries.
例如,将数据库中的条目名字典(如基因名)集成到搜索栏中,以便用户能够获得候选名称,方便地形成查询。
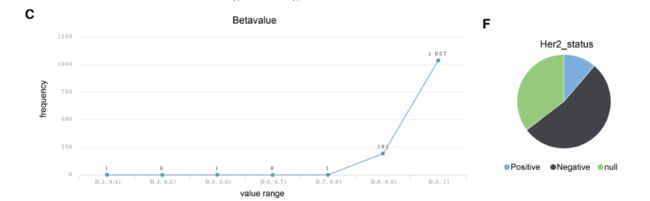
The results are presented as figures (the upper part) and a table (the lower part), as shown in Fig. 1, which consist of data of different dimensions.
结果以图(上半部分)和表(下半部分)的形式表示,如图1所示,表中包含了不同维度的数据。
-
The figures present statistical analysis results, while the detailed information is given in the table.
图中为统计分析结果,详细情况见表。
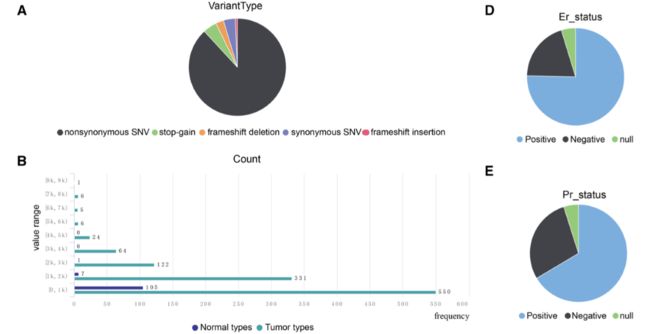 1554706035074.png
1554706035074.png
In Fig. 1a, the pie chart illustrates the BRCA1 somatic mutation status of all the samples.
在图1a中,饼图显示了所有样本的BRCA1体细胞突变状态。
In Fig. 1b, BRCA1 expression data of tumor samples and normal samples are presented separately by histogram.
图1b中,肿瘤样本和正常样本的BRCA1表达数据分别用直方图表示。
-
Figure 1c shows the methylation data of cg07054526 by line graph.
图1c为cg07054526的甲基化数据用线形图表示。
-
Figure 1d–f illustrates the status of ER, PR, and HER2.
图1d-f说明了ER、PR和HER2的状态。
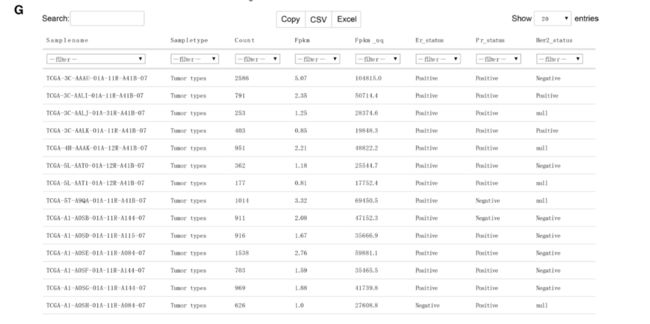 fig1df
fig1df
From the figures of statistical analysis results, we can see that the mutation types of BRCA1 are diverse, the expression level is relatively low and some methylation sites exhibit hypermethylation.
从统计分析结果图中可以看出,BRCA1的突变类型多样,表达水平相对较低,部分甲基化位点表现为高甲基化。
In Fig. 1g, the users can search, sort, copy, and download the detailed data in the table.
在图1g中,用户可以搜索、排序、复制、下载表格中的详细数据。
The results from the four tools related to somatic mutation data are integrated and presented in one column.
将四种与体细胞突变数据相关的工具的结果整合在一栏中。
The users can easily see which tool filters the search result.
用户可以很容易地看到哪个工具过滤搜索结果。
Different types of expression data (FPKM, count, and RPM) are shown simultaneously in the table, and the 450 K/27 K methylation data are also integrated into the same column.
表中同时显示了不同类型的表达数据(FPKM、count和RPM),并将450 K/ 27k甲基化数据集成到同一列中。
(web 页面展示可视化说明)
Visualization and analysis tools to facilitate the usage of omics data
The genome-wide browser in MOBCdb was built based on JBrowse.
MOBCdb中的全基因组浏览器是基于JBrowse构建的。
We redeveloped the selection box such that it is more suitable for presenting multi-omics data.
我们重新开发了选择框,使其更适合显示多组数据。
As shown in Fig. 2, the browser contains a selection box on the left panel and the corresponding visualization figure on the right panel.
如图2所示,浏览器在左侧面板中包含一个选择框,右侧面板中包含相应的可视化图形。
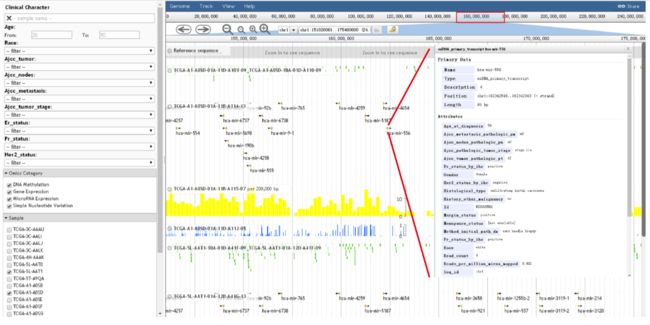
The selection box has three parts, including Clinical Factors, Omics Category, and Sample, from top to bottom.
从上到下,选择框由临床因素、组学分类、样本三部分组成。
The users can filter their search results through clinical factors such as age, race, AJCC classification, ER, PR, and HER2 status.
用户可以通过年龄、种族、AJCC分类、ER、PR和HER2状态等临床因素过滤搜索结果。
Similarly, the Omics Category part contains four boxes, corresponding to SNV, gene expression, microRNA expression, and DNA methylation data.
同样,组学类包含四个盒子,分别对应SNV、基因表达、microRNA表达和DNA甲基化数据。
The sample part includes different TCGA sample names.
示例部分包括不同的TCGA示例名称。
Furthermore, the Omics Category and Sample parts provide checker boxes that allow the users to choose multiple boxes at the same time.
此外,组学类别和样例部件提供了检查框,允许用户同时选择多个框。
The checker boxes can be easily used to show multi-omics and multi-sample data, so that the users can compare the data of a certain region of many samples or different omics data in this region.
该复选框可以方便地显示多组学和多样本数据,使用户可以比较该区域内多个样本或不同组学数据在某一区域的数据。
The figure on the right panel shows a variety of data tracks and allows zooming in and out for detailed or general information.
右侧面板上的图显示了各种数据跟踪,并允许对详细信息或一般信息进行放大和缩小。
By clicking a track, its detailed information, including all the collected clinical characteristics, the data of the related sample, and the description of the omics data, will be displayed in a new window.
通过点击一个track,它的详细信息,包括所有收集到的临床特征,相关样本的数据,以及组学数据的描述,将会显示在一个新的窗口中。
By using the genome browser, the users can easily visualize different omics data of a certain sample, and compare the specified omics data across different samples in a selected subgroup.
通过使用基因组浏览器,用户可以方便地查看特定样本的不同组学数据,并在选定的子组中比较不同样本之间的特定组学数据。
(组学数据可视化)
Three datasets (gene expression, microRNA expression, and DNA methylation) were used for survival analysis.
使用三个数据集(基因表达、microRNA表达和DNA甲基化)进行生存分析。
SNV was not used because more than 90% SNVs emerged in no more than three of the 1097 samples.
没有使用SNV,因为在1097个样本中,超过90%的SNV出现在不超过3个样本中。
The users can do search by gene, microRNA, cgid or their combinations, and the samples can be filtered by four features: ER status, PR status, HER2 status, and sample type.
用户可以通过基因、microRNA、cgid或它们的组合进行搜索,样本可以通过ER状态、PR状态、HER2状态和样本类型四个特征进行筛选。
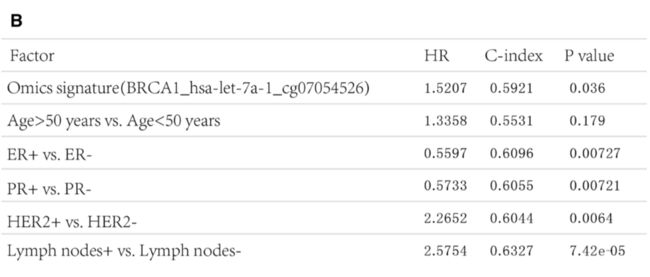
As shown in Fig. 3, the results are presented in a statistical summary table with omics signature and clinical factors, and a Kaplan–Meier plot of two groups stratified by mean score obtained by Cox regression.
如图3所示,结果以统计汇总表的形式呈现,其中包含组学特征和临床因素,并以Cox回归得到的均分对两组进行分层,得到Kaplan-Meier图。
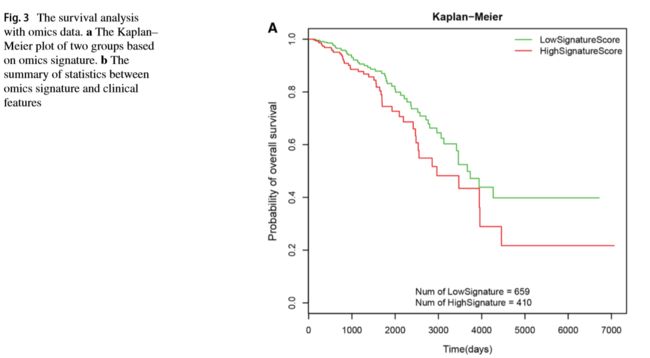
The Kaplan–Meier plot shows the survival time between two groups (BRCA1, hsa-let-7a-1, cg07054526) with noticeable difference in tumor samples (Hazard ratio 1.5207, C-index = 0.5921, p value = 0.036).
Kaplan-Meier图显示两组患者的生存时间(BRCA1, hsa-let-7a-1, cg07054526),肿瘤样本差异显著(危险比1.5207,c指数= 0.5921,p值= 0.036)。
In the table, HR, C-index, p value, and clinical features (e.g., age, ER, PR, HER2 status, and lymph nodes) are presented.
表中列出了HR、c指数、p值以及临床特征(如年龄、ER、PR、HER2状态、淋巴结)。
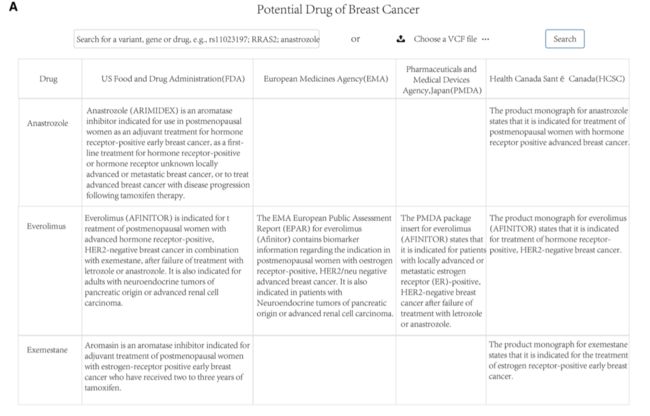
Drugs with variant information useful for precision medicine
Along with the understanding of diseases, target therapy becomes an important part of precision medicine.
随着对疾病认识的加深,靶向治疗成为精准医疗的重要组成部分。
Due to the large-scale GWAS study and clinical research, PharmGKB have accumulated a lot of genetic variants with drug response.
由于GWAS的大规模研究和临床研究,药物基因学知识库积累了大量具有药物反应性的遗传变异。
We extracted 12 breast cancer-related drugs and their variant information.
我们提取了12种乳腺癌相关药物及其变异信息。
The drugs collected were approved by the US Food and Drug Administration (FDA), European Medicines Agency (EMA), Pharmaceuticals and Medical Devices Agency, Japan (PMDA), and Health Canada (Santé Canada) (HCSC).
所收集的药物已获美国食品及药物管理局(FDA)、欧洲药物管理局(EMA)、日本药物及医疗器械管理局(PMDA)、加拿大卫生部(Sante Canada) (HCSC)批准。
The 12 drugs have a summary description about how using the drugs under specific conditions and reliability.
这12种药物都有关于如何在特定条件下使用药物和可靠性的概述。
7 of the 12 drugs have 986 entries of information associated with variants and genes, which impact specific genotypes and may cause the increasing or decreasing of breast cancer risk.
12种药物中有7种含有986条与变异和基因相关的信息,这些信息会影响特定的基因型,并可能导致乳腺癌风险的增加或减少。
The population size, race, significance, and phenotype were also provided, as shown in Fig. 4.
还提供了种群大小、种族、显著性和表型,如图4所示。
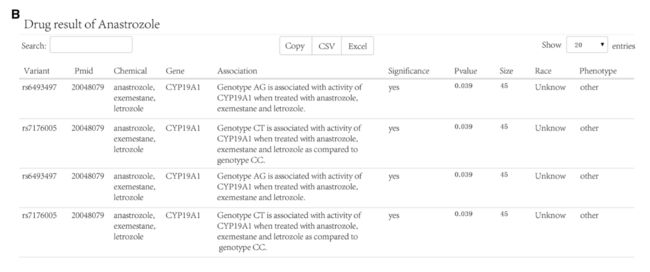
The information of genetic variants related to drug response is extremely useful in precision medicine, which makes applying omics data to breast cancer clinic practice be possible.
与药物反应相关的基因变异信息在精准医学中非常有用,这使得将组学数据应用于乳腺癌临床成为可能。
The users can easily issue queries on the information by rsid, gene, and drug, and upload the annotated VCF file after they perform genetic analysis.
用户可以方便地通过rsid、gene、drug对信息进行查询,并在进行遗传分析后上传带注释的VCF文件。
Discussion
With the development of next-generation sequencing technologies, the volume of multi-omics data of breast cancer has been increasing rapidly, and some related databases were built.
随着下一代测序技术的发展,乳腺癌多组学数据量迅速增加,并建立了相关数据库。
However, most of the existing databases focused on single-omics data to identify the potential targets [24–26].
然而,现有的数据库大多侧重于单一组学数据来识别潜在的目标[24-26]。
As life is a complex regulatory system, it is obvious that using single-omics data to determine effective therapeutic biomarkers has its limitations [11].
由于生命是一个复杂的调控系统,使用单组学数据来确定有效的治疗性生物标志物显然有其局限性。
Instead, integrating multi-omics data for deep analysis will provide new perspectives for precision medicine.
相反,整合多组学数据进行深度分析,将为精准医疗提供新的视角。
Therefore, we collected large amounts of genomic, transcriptomic, epigenomic, and drug response studies data and built up the MOBCdb database, with the aim of providing integrated data and analysis tools for precise medicine.
因此,我们收集了大量的基因组、转录组、表观基因组和药物反应研究数据,建立了MOBCdb数据库,旨在为精准医疗提供综合的数据和分析工具。
The current implementation of MOBCdb integrates data of SNV, gene expression, microRNA expression, DNA methylation, clinic information, and targeted drug response.
目前MOBCdb的实施整合了SNV、基因表达、microRNA表达、DNA甲基化、临床信息、靶向药物反应等数据。
Each type of these data was processed with multiple tools or methods, and various search methods are provided.
这些数据的每一种类型都使用多种工具或方法进行处理,并提供了各种搜索方法。
Based on the JBrowse framework, we developed an efficient embedded web genome browser, with selection boxes for conveniently displaying multi-omics data simultaneously.
在JBrowse框架的基础上,开发了一种高效的嵌入式web基因组浏览器,该浏览器具有多个选择框,可以方便地同时显示多组数据。
The users can choose one or more samples of interest to check the specific clinic characteristics.
用户可以选择一个或多个感兴趣的样本来检查特定的临床特征。
Survival analysis tools were provided to help researchers to find the prognostic biomarkers for different subtypes of breast cancer.
生存分析工具的提供,以帮助研究人员找到预后生物标志物的不同亚型乳腺癌。
MOBCdb also collected data of drug response to specific genetic variants of breast cancer.
MOBCdb还收集了乳腺癌特定基因变异的药物反应数据。
(MOBdb 数据库总结和优势)
In summary, MOBCdb can serve the breast cancer research and clinic community as a valuable resource of multi-omics data and analysis.
综上所述,MOBCdb可以为乳腺癌研究和临床社区提供一个有价值的多组学数据和分析资源。
Certainly, MOBCdb still has some limitations.
当然,MOBCdb仍然有一些限制。
First, SNV data were obtained from exome sequencing, which cover only about 1.5% of the human genome.
首先,SNV数据是通过外显子组测序获得的,外显子组测序仅覆盖约1.5%的人类基因组。
Second, DNA methylation data were derived from illumina 27 K/450 K bead array, they account up to only 2% of the total CpGs in the human genome.
其次,DNA甲基化数据来源于illumina 27k / 450k珠粒阵列,它们仅占人类基因组总cpg的2%。
The low coverage of SNV and DNA methylation data will surely limit their applications.
SNV和DNA甲基化数据的低覆盖率必将限制它们的应用。
Third, the normal tissue samples account for about 10% of all samples and there are no data available from healthy individuals.
第三,正常组织样本约占所有样本的10%,没有来自健康个体的数据。
In the future, on the one hand, we will try to include more multi-omics data from both breast cancer and control samples.
在未来,一方面,我们将尝试包括更多来自乳腺癌和对照样本的多组学数据。
On the other hand, we will enrich the data analysis tools to support real clinic practices.
另一方面,我们将丰富数据分析工具,以支持实际的临床实践。
(MOBCdb 的局限)
Compliance with ethical standards
遵守道德标准
Conflict of interest We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and/or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled.
利益冲突声明,我们没有资金和人际关系与他人或组织不当会影响我们的工作,没有专业的或其他任何性质的个人利益或在任何产品,服务和/或公司可能被视为影响的位置,或审查,手稿资格。
详细见文献:
MOBCdb: a comprehensive database integrating multi‑omics data on breast cancer for precision medicine
https://link.springer.com/article/10.1007%2Fs10549-018-4708-z