本章讲了logistic regression、梯度下降、随机梯度下降。书中没有提到相关的数学公式,就连cross-entropy都没有说,只是提供了代码。这里总结下对于逻辑回归梯度下降的推导过程。
逻辑回归就是简单的二分类问题。使用sigmoid将特征值的线性组合转换到0-1之间,同时使用cross-entropy作为loss function。因为对于二分类问题,如果使用mean square error的话,其loss函数不保证只有一个global minimum。也就是使用梯度下降法时,可能会收敛到local minimun上。而使用cross-entropy的话就没有这个问题。
下面公式表示Logistic对样本i的预测过程,不支持LateX,只能上图了:
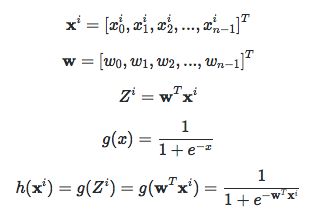
通常将h()的输出值看为该样本取为1的概率。模型对于该样本i的预测与真实值的交叉熵定义如下:
因为所有样本的cost函数为单个样本loss函数取和后平均,所以先求出单个样本的loss对某一权值分量wk的偏导数:
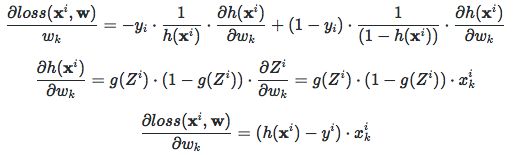
主要在于sigmoid函数导数的特点,即g`(x) = g(x)(1-g(x))。那么cost对某一权值分量的偏导为:

对于单个权值的更新公式为:

想要向量化实现上面的公式,即使用矩阵运算一次更新全部的权值。很简单,可以看到cost对单个权值k的偏导为所有样本的预测值与真实值的差乘以对应的样本特征后再取和。在numpy中也就是:
# h(x)为对所有样本的预测值,y为所有样本的真实值。
# xk为样本矩阵的第k列。
np.sum(np.multiply(h(x)-y, xk))
那么对于所有权值的偏导就很好求了,就是h(x)-y与样本矩阵的每一列相乘后按行取和。
np.sum(np.multiply(h(x)-y, X), axis=0)
下面为具体的代码实现,没有使用书中的代码,我自己重写了下:
先是一些helper function,用于帮助构建模型的训练过程:
# 导入两个库
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def sigmoid(z):
return 1. / (1 + np.exp(-z))
# weights.shape = (n,1)
# x.shape = (m,n)
# 返回shape = (m,1)
def forwardpass(weights, x):
return sigmoid(np.matmul(x,weights))
# 初始化权值
# shape为(n,1)
def initial_weights(n):
return np.random.randn(n,1)
# 用于评估样本准确率,阈值默认为0.5
def model_acc(weights, x, y, threshold=0.5):
z = forwardpass(weights, x)
z = (z > threshold).astype(np.float)
return np.mean((z==y))
# 该函数为一次梯度下降,训练时不断调用该函数更新权值
# weights.shape = (n,1)
# train_x.shape = (m,n)
# train_y.shape = (m,1)
# alpha为学习率
# 返回更新后的权值
def gradDescent(weights, train_x, train_y, alpha):
z = forwardpass(weights, train_x)
# 求和后为(1,n)行向量,转置为(n,1)列向量
dw = np.sum(np.multiply(z - train_y, train_x), axis = 0, keepdims=True).T
weights = weights - alpha * dw
return weights
下面就是模型的训练过程:
# 该函数中不光训练了模型,还将数据集和最后的decision boundary画了出来
# 这里使用的数据集就是书中给的,特征只有两个
# 第一个作为x坐标,第二个作为y坐标
# 同时也画出了训练过程中cost函数的变化趋势
# train_x.shape = (m,n),各样本按行排列
# trian_y.shape = (m,1)
# epoch为训练次数
# alpha为学习率
def train_model(train_x, train_y, epoch, alpha):
# m个样本,n个特征
m, n = train_x.shape
weights = initial_weights(n)
# 用于画出两类点
xcord1 = []; ycord1 = []
xcord0 = []; ycord0 = []
fig, ax = plt.subplots(1,2, figsize=(12,4))
for i in range(m):
if train_y[i,0] == 1:
# 因为对数据集做了预处理,在前面添加了一列1
# 就是将偏置b和各个权值合到一起了。
xcord1.append(train_x[i,1]); ycord1.append(train_x[i,2])
else:
xcord0.append(train_x[i,1]); ycord0.append(train_x[i,2])
ax[0].scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax[0].scatter(xcord0, ycord0, s=30, c='green')
# 画一下初始的线
x = [np.max(train_x[:,1])+1, np.min(train_x[:,1])-1]
y = -(weights[1]*x+weights[0]) / weights[2]
ax[0].plot(x, y, label='initial line')
c = []
# 训练过程
for i in range(epoch):
weights = gradDescent(weights, train_x, train_y, alpha)
c.append(cost(weights, train_x, train_y))
# 画出训练后的decision boundary,使用默认的thresholds=0
x = [np.max(train_x[:,1])+1, np.min(train_x[:,1])-1]
y = -(weights[1]*x+weights[0]) / weights[2]
ax[0].plot(x, y, label='decision boundary')
ax[0].legend()
ax[1].plot(c)
acc = model_acc(weights, train_x, train_y)
print(acc)
return weights
下面调用函数训练:
# 先读入数据集,其中样本按行排列,最后一列为label
dataset = np.loadtxt('./testSet.txt')
train_x = dataset[:,0:2]
# 一定不能忘记在前面添加一列1,否则训练得到的decision boundary只能过坐标原点
train_x = np.concatenate((np.ones((train_x.shape[0],1)),train_x), axis=1)
train_y = dataset[:,2][:,np.newaxis]
# 训练!
train_model(train_x, train_y, 500, 0.001)
下面为训练输出的结果:

可以看到对于训练集效果还不错,96%的正确率。这里的数据集少(100个),模型也简单。但重要的还是过程~~~
书中还较少了stochastic gradient descent,还有学习率下降,很简单。