iOS之武功秘籍 文章汇总
写在前面
本文主要是理解LLVM的编译流程
本节可能用到的秘籍Demo
一、什么是编译器?
① Python案例
- 创建
Python文件夹,新建helloDemo.py文件,内容print("hello\n") - 调用
python helloDemo.py执行文件,打印出hello

② C 案例
-
vim创建helloDemo.c文件
-
clang helloDemo.c编译,生成a.out文件.
file a.out查看文件,发现.out文件是:64位的Mach-O可执行文件,当前clang出来的是x86_64架构,mac电脑可读. 所以可以./a.out直接执行:

③ 相关疑问
③.1 解释型语言与编译型语言
-
编译型语言:编译后输出的是指令(0、1组合),cpu可直接执行指令-
C语言是编译型语言,不能直接执行,需要编译器将其转换成机器识别语言
-
-
解释性语言:生成的是数据,不是0、1组合,机器也能直接识别-
python是解释型语言,一边翻译一边执行.和js一样,机器可直接执行.
-
编译器的作用,就是将高级语言转化为机器能够识别的语言(可执行文件)
③.2 汇编有指令吗?
- 早期科学家,使用
0、1编码. 比如00001111对应call,00000111对应bl.有了对应关系后. 再手敲0和1就有点难受了.于是写个中间解释器,我们只用输入call、bl这样的标记指令,经过解释器,变成0和1的组合,再交给机器去执行.这就是汇编的由来. - 而基于汇编往上,再
映射和封装相关对应关系.就跨时代性的c语言,再往上层封装,就出现了高级语言oc、swift等语言.所以汇编执行快,因为它是直接转换为机器语言. - 但
汇编的指令集,是针对同一操作系统而言,它不支持跨平台.机器指令是cpu的在识别.早期的计算机厂家非常多,虽然都用0和1的组合,但相同组合背后却是相应不同的指令.所以汇编无法跨平台,不同操作系统下,汇编指令是不同的.
二、LLVM概述
LLVM是架构编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼任已有脚本.
LLVM计划启动于2000年,最初由美国UIUC大学的Chris Lattner博士主持开展.
2006年Chris Lattner加盟Apple Inc.并致力于LLVM在Apple开发体系中的应用.Apple也是LLVM计划的主要资助者.
目前LLVM已经被苹果iOS开发工具、Xilinx Vivado、Facebook、Google等各大公司采用.
三、传统编译器的设计
源码 Source Code + 前端 Frontend + 优化器 Optimizer + 后端 Backend(代码生成器 CodeGenerator)+ 机器码 Machine Code,如下图所示

编译器前端(Frontend)
编译器前端的任务是解析源代码(编译阶段),它会进行 词法分析、语法分析、语义分析、检查源代码是否存在错误,然后构建抽象语法树(Abstract Syntax Tree AST),LLVM的前端还会生成中间代码(intermediate representation,简称IR),可以理解为LLVM是编译器 + 优化器, 接收的是IR中间代码,输出的还是IR,给后端,经过后端翻译成目标指令集
优化器(Optimizer)
优化器负责进行各种优化,改善代码的运行时间,例如消除冗余计算等
后端(Backend)/(代码生成器 Code Generator)
将代码映射到目标指令集,生成机器代语言,并且进行机器代码相关的代码优化
iOS的编译器架构
Objective C/C/C++ 使用的编译器前端是Clang,Swift是swift,后端都是LLVM.

LLVM的设计
当编译器决定支持多种源语言或多种硬件架构时,LLVM最重要的地方就来了.其他的编译器如GCC,它方法非常成功,但由于它是作为整体应用程序设计的,因此它们的用途受到了很大的限制.
LLVM设计的最重要方面是,使用通用的代码表示形式(IR),它是用来在编译器中表示代码的形式,所以LLVM可以为任何编程语言独立编写前端,并且可以为任意硬件架构独立编写后端,如下所示
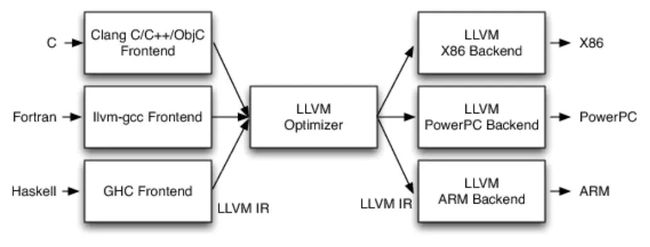
通俗的一句话理解就是:LLVM的设计是前后端分离的,无论前端还是后端发生变化,都不会影响另一个
Clang简介
Clang是LLVM项目中的一个子项目,它是基于LLVM架构图的轻量级编译器,诞生之初是为了替代GCC,提供更快的编译速度,它是负责C、C++、OC语言的编译器,属于整个LLVM架构中的 编译器前端,对于开发者来说,研究Clang可以给我们带来很多好处
四、LLVM编译流程
- 新建一个
Mac OS的命令行工程:
- 没有改动代码

① 打印源码的编译阶段
-
cd到main.m的文件夹.使用clang -ccc-print-phases main.m命令查看main.m的编译步骤:
编译流程分为以下7步:
-
0: input, "main.m", objective-c:- 输入文件:找到源文件
-
1: preprocessor, {0}, objective-c-cpp-output:- 预处理:宏的展开,头文件的导入
-
2: compiler, {1}, ir:- 编译:词法、语法、语义分析,最终生成IR
-
3: backend, {2}, assembler ():- 汇编: LLVM通过一个个的Pass去优化,每个Pass做一些事,最后生成汇编代码
-
4: assembler, {3}, object:- 目标文件
-
5: linker, {4}, image:- 链接: 链接需要的动态库和静态库,生成可执行文件
-
6: bind-arch, "x86_64", {5}, image:- 架构可执行文件:通过不同架构,生成对应的可执行文件
optimizer优化并没有作为一个独立阶段,在编译阶段内部完成的
② 预处理阶段
这个阶段主要是处理包括宏的替换,头文件的导入,可以执行如下命令,执行完毕可以看到头文件的导入和宏的替换
-
main.m文件中准备测试代码: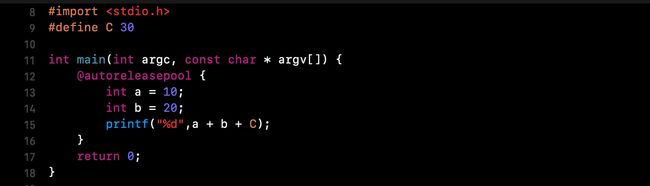
-
clang预编译输出main2.m文件:通过指令clang -E main.m >> main2.m - 打开
main2.m文件其中大部分是stdio库的代码:
我们发现测试代码中的
宏C,在预编译阶段完成了替换,变成了30-
修改测试代码,给
int类型取个别名CJ_INT_64,再次预编译处理: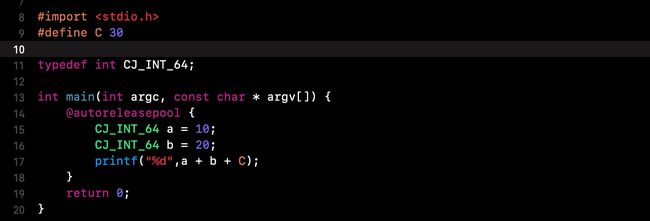
- 发现
typedef不会被替换
小结:
-
typedef在给数据类型取别名时,在预处理阶段不会被替换掉 -
define则在预处理阶段会被替换,所以经常被用来进行代码混淆,目的是为了app安全,实现逻辑是:将app中核心类、核心方法等用系统相似的名称进行取别名,然后在预处理阶段就被替换了,来达到代码混淆的目的
③ 编译阶段
编译阶段主要是进行词法、语法等的分析和检查,然后生成中间代码IR
③.1 词法分析
预处理完成后就会进行词法分析,这里会把代码切成一个个Token,比如大小括号、等于号还有字符串等,而且还标注了位置是第几行的第几个字符开始的.
- 可以通过
clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m命令查看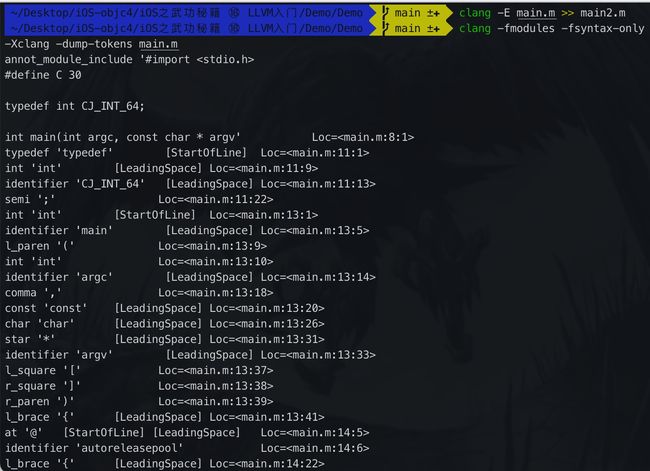
③.2 语法分析
词法分析完成后就是语法分析,它的任务是验证语法是否正确,在词法分析的基础上将单词序列组合成各类此法短语,如程序、语句、表达式 等等,然后将所有节点组成抽象语法树(Abstract Syntax Tree, AST),语法分析程序判断源程序在结构上是否正确.
- 可以通过
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m命令查看语法分析的结果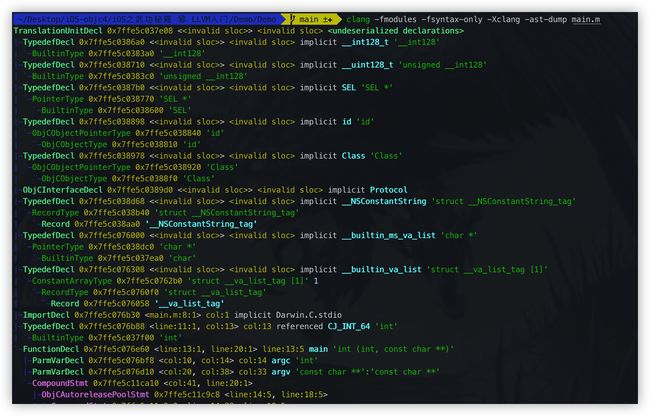
其中,主要说明几个关键字的含义
- -FunctionDecl 函数
- -ParmVarDecl 参数
- -CallExpr 调用一个函数
- -BinaryOperator 运算符
④ 生成中间代码IR
完成以上步骤后,就开始生成中间代码IR了,代码生成器(Code Generation)会将语法树自顶向下遍历逐步翻译成LLVM IR.
- 通过
clang -S -fobjc-arc -emit-llvm main.m命令可以生成.ll的文本文件,查看IR代码.OC代码在这一步会进行runtime桥接:property合成、ARC处理等
IR基本语法
-
@全局标识 -
%局部标识 -
alloca开辟空间 -
align内存对齐 -
i3232bit,4个字节 -
store写入内存 -
load读取数据 -
call调用函数 -
ret返回
下面是生成的中间代码.ll文件

其中,test函数的参数解释为

图中为何多创建那么多局部变量?(如test函数内的a5、a6)
因为在上一阶段(编译阶段),我们将代码编译成了语法树结构.而此时,我们只是沿着语法树进行读取.语法树每一个层级,都需要一个临时变量来承接.再返回上一层级处理.所以会产生那么多局部变量
当然,IR文件在OC中是可以进行优化的,一般Xcode中设置是在target - Build Setting - Optimization Level(优化器等级)中设置.(Debug模式默认None [O0]无优化,Release模式默认Fastest,Smallest [Os]最快最小)

LLVM的优化级别分别是-O0 -O1 -O2 -O3 -Os(第一个是大写英文字母O),下面是带优化的生成中间代码IR的命令
clang -Os -S -fobjc-arc -emit-llvm main.m -o main.ll
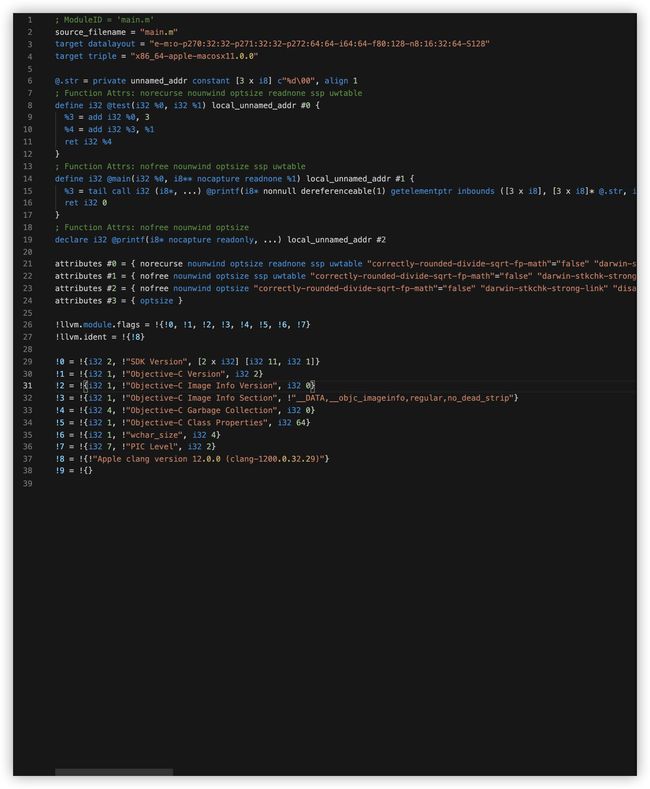
优化后的代码,舒服多了.之前那些冗余的临时局部变量,也都被优化,代码量减少很多.
-
xcode7以后开启bitcode,苹果会做进一步优化,生成.bc的中间代码,我们通过优化后的IR代码生成.bc代码.- 优化指令
clang -emit-llvm -c main.ll -o main.bc
- 优化指令
⑤ 生成汇编代码
LLVM在后端主要是会通过一个个的Pass去优化,每个Pass做一些事情,最终生成汇编代码
- 完成
中间代码的生成后,可以将代码转变为汇编代码了 - 此刻我们有
4种不同程度的代码(源代码->无优化IR代码->Os优化IR代码->bitcode优化代码)
- 分别对4种程度的代码输出汇编文件:
clang -S -fobjc-arc main.m -o main.s
clang -S -fobjc-arc main.ll -o mainO0.s
clang -S -fobjc-arc mainOs.ll -o mainOs.s
clang -S -fobjc-arc main.bc -o mainbc.s

可以看到在生成汇编代码时,只有选择了优化等级,才能减少汇编代码量.
- 生成汇编代码也可以进行优化---即在
生成中间代码的前后,都可以进行优化- ① 将
main.m直接选择Os级别优化生成.s汇编文件--clang -Os -S -fobjc-arc main.m -o mainOs.s - ② 将
main.m生成无优化的mainO0.ll,再mainO0.ll选择Os级别优化生成.s汇编文件 --clang -S -fobjc-arc -emit-llvm main.m -o mainO0.ll,clang -Os -S -fobjc-arc mainO0.ll -o mainO0Os.s - ③ 将
main.m选择Os级别优化生成mainOs.ll,再mainOs.ll选择无优化级别生成.s汇编文件 --clang -Os -S -fobjc-arc -emit-llvm main.m -o mainOs.ll,clang -S -fobjc-arc mainOs.ll -o mainOsO0.s - ④ 将
main.m选择Os级别优化生成mainOs.ll,再mainOs.ll选择Os级别优化生成.s汇编文件 --clang -Os -S -fobjc-arc -emit-llvm main.m -o mainOs.ll,clang -Os -S -fobjc-arc mainOs.ll -o mainOsOs.s
- ① 将
⑥ 生成目标文件(机器代码)
目标文件的生成,是汇编器以汇编代码作为插入,将汇编代码转换为机器代码,最后输出目标文件(object file)-- clang -fmodules -c main.s -o main.o
- 此时我们
file对比一下main.s汇编代码和main.o机器代码.
-
可以通过
nm命令,查看下main.o中的符号 --xcrun nm -nm main.o
-
_printf函数是一个是undefined 、external的 -
undefined表示在当前文件暂时找不到符号_printf -
external表示这个符号是外部可以访问的
-
所以当前虽转换成了机器代码.但是只是目标文件,并不能直接执行,需要将所有资源链接起来,才可以执行.
⑦ 生成可执行文件(链接)
链接主要是链接需要的动态库和静态库,生成可执行文件,其中
- 静态库会和可执行文件合并
- 动态库是独立的
连接器把编译生成的.o文件和 .dyld 、.a文件链接,生成一个mach-o文件,接着输入以下指令
clang main.o -o main // 将目标文件转成可执行文件
file main // 查看文件
xcrun nm -nm main // 查看main的符号
结果如下所示,其中的undefined表示会在运行时进行动态绑定
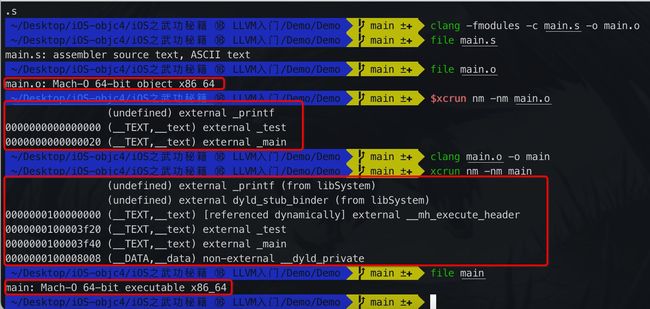
对比main.o目标文件,此时生成的main文件:
- 从
object文件变成了executable可执行文件 - 虽然都有
undefined,但是可执行文件中指定了该符号的来源库.机器在运行时,会从相应的库中取读取该符号(printf)
⑧ 绑定
绑定主要是通过不同的架构,生成对应的mach-o格式可执行文件
至此,我们已完整分析了:从源代码到可执行文件的整个流程.

写在后面
和谐学习,不急不躁.我还是我,颜色不一样的烟火.