转载 https://blog.csdn.net/DXRfighting/article/details/114978505
模型原理
Wide&&Deep 是谷歌于2016年提出的一个经典推荐系统模型,至今仍发挥着巨大的影响力。Wide&Deep 模型分为单层的wide层和多层的deep层,分别为模型带来相应的记忆能力和泛化能力。所谓记忆能力,是指模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。如简单的协同过滤模型就有比较强的记忆能力。而泛化能力是指模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。神经网络由于其强大的挖掘信息能力可以为模型带来很好的泛化能力。
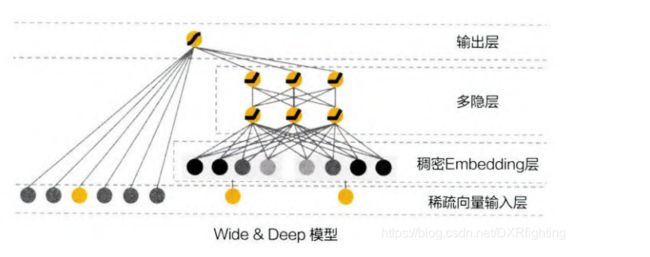
(图片来自于《深度学习推荐系统》),一边是只有一层的wide层,另一边是包含隐藏层的deep层。wide部分擅长处理大量稀疏的id类特征,deep部分利用神经网络的表达能力挖掘特征背后的数据模式。最终使用逻辑回归模型将两部分组合起来形成统一的模型。下图为模型的详细结构图(图片来自《深度学习推荐系统》)。
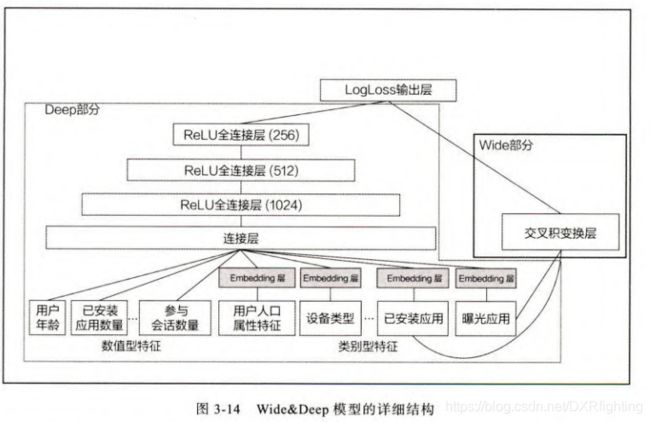
在Wide&Deep模型中十分关键的一个问题是选择哪些特征在wide层,哪些特征放到deep层。因为wide侧不发现数据新的模式,因此我们可以将共现频率高的特征放到wide侧。举个例子,比如在应用商店的应用推荐中,就可以把已安装应用和曝光应用两个特征放到wide侧,因为已安装应用是用户已经安装的应用,而曝光应用是待推荐应用,模型可根据这两个特征直接进行推荐。
接下来看一下如何使用TensorFlow实现模型。
模型实现
以下代码来自组队学习内容。先看一下模型是如何构建的:
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
def WideNDeep(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layer = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layer)
return model
模型具体流程可参考下图(图片来自DataWhale社区):
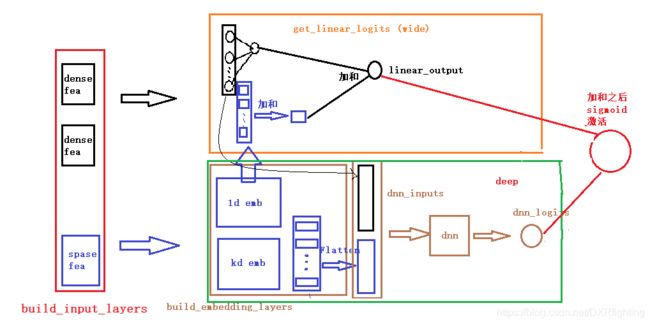
接下来我们来看一下模型在critro数据集上的运行结果。
首先读取数据集:

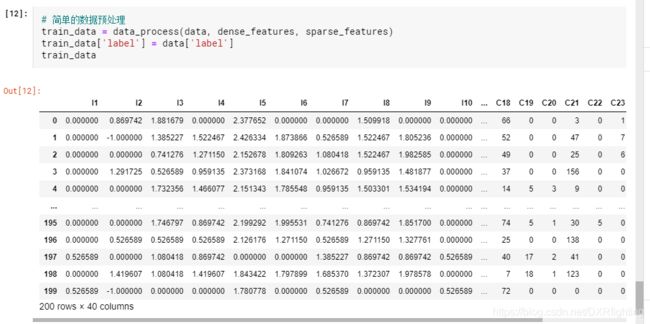
可以看到数据集包含200条数据,每条数据40个特征,其中I开头的为数值型稠密特征,C开头的为稀疏的特征。
接着我们对将稠密特征和稀疏特征区分开:

接着对数据集做一个简单的预处理,主要处理缺失值以及对类别编码:
下一步将特征分为两组,分别对应wide部分和deep部分:

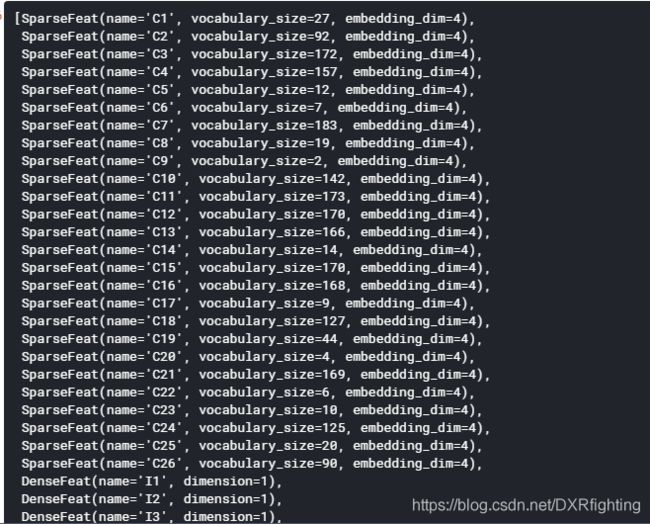
wide部分特征的选取一般都是需要结合业务进行选择,这里由于我们实现并不知道哪些特征组合具有更好的效果,因此我们将全部特征都放进去。
这里需要注意的一点是SparseFeat和DenseFeat是命名元组。定义如下:
from collections import namedtuple
# 使用具名元组定义特征标记
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
DenseFeat = namedtuple('DenseFeat', ['name', 'dimension'])
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'vocabulary_size', 'embedding_dim', 'maxlen'])
下面构建模型:
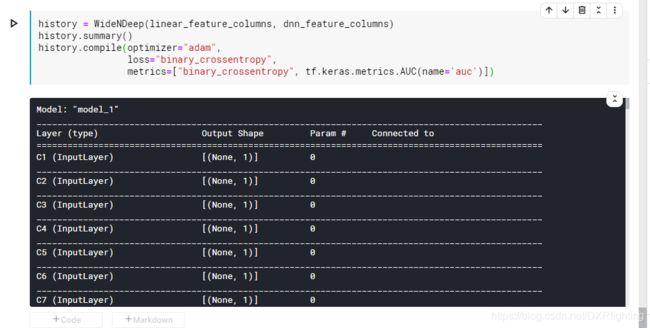
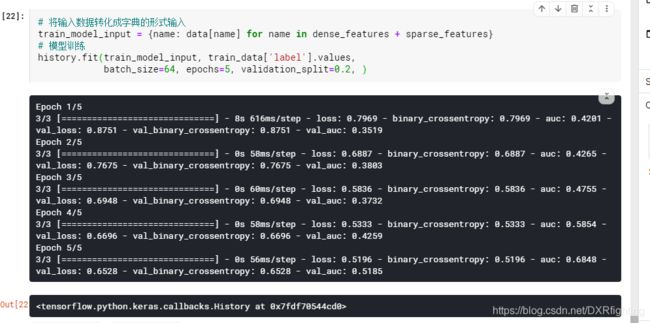
最后对模型训练: