在编写解析文本或者流的程序中, 常常要面对转义字符的处理, 而这其中遇到的很多坑, 常常是因为不理解转义字符的在计算机中的存储而生. 本文分析转义字符在计算机中的存储, 帮助理解本质, 方能快速写好程序.
1 定义
转义符号, 英文escape(逃避), 在Python中就是反斜线符号"", 它被用来使得该符号紧接的字符能"逃避"当前含义, 而采用另一种特殊含义.
转义字符, 指的是形如"\n", "\r", "\t", "'"这样一个实际被转义符号转换含义的字符.
2 转义字符实际有哪些?
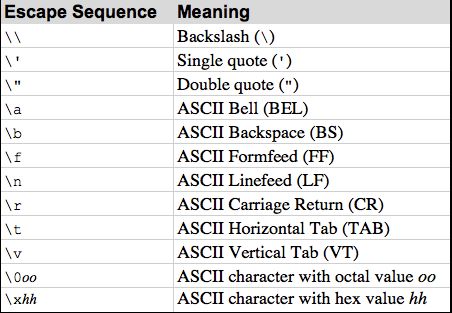
Python官方文档所给出的转义字符如下: 引用1
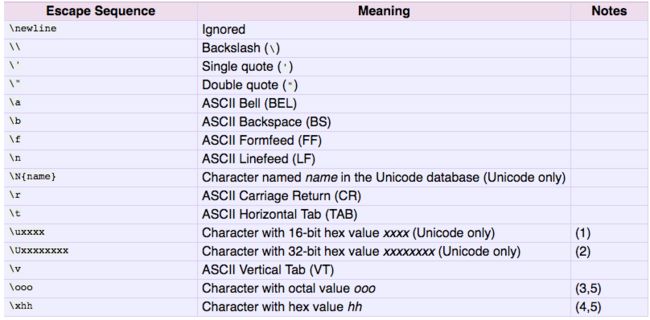
然而, 实际上, 这个表格是不准确的. 我们可以用如下一段Python程序进行测试.
# -*- coding:utf-8 -*-
# 测试平台: macOS 10.13 Terminal + Python2.7.14
t = ('text\newlinetext', # 无效
'text\\text',
'text\'text',
'text\"text',
'text\atext',
'text\btext',
'text\ftext',
'text\ntext',
'text\rtext',
'text\ttext',
'text\ua000text', # 无效
'text\Ua000a000text', # 无效
'text\vtext',
'八进制text\012text', # 注意第一个字符是数字零, \012会被转化为十进制的10, 再以ASCII表第10个输出linefeed导致换行效果
'八进制text\000text', # 本质上就是八进制获得00, 再按照ASCII表第0个输出
'十六进制text\xfftext', # 注意八进制和十进制转义字符都不能直接表示数值, 而是表示ASCII对应的字符
)
for char in t:
print char
# 防转义
print '防转义方法两种方法:', r'\n', "\\t"
# 格式化
formalize = '%s is %d old. He loves %x and %o' % ('Tom', 25, 100, 10) # 格式化输出时, octal value是用%o(字母o)
print formalize
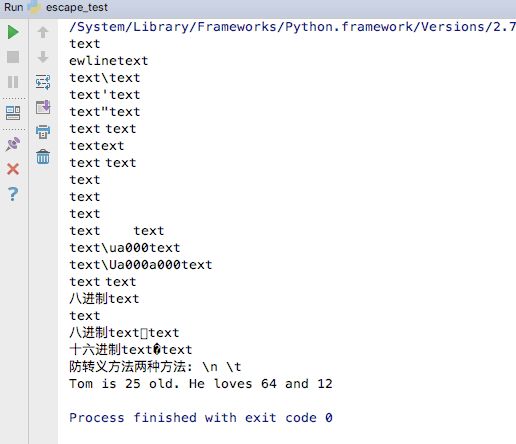
注意到octal value反斜线后面第一个字符是数字0而非字母o.
3 转义字符在计算机中的存储和视觉展示
假设我们在test.py中写了如下代码
s = "\n"
那么, 转义字符在计算机内存中存储: \n
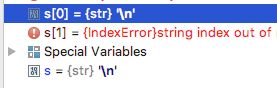
(注意, 在内存中, 这是一个字符, 而非两个字符!)
如果选择打印, 则输出一个linefeed换行效果.
假设我们在data.txt文件中, 写下了\n
那么, 实际在计算机中这个文件存储的是\\n
\\是一个字符, 代表的是\,
n是一个字符, 代表的就是n,
因此, 为了打开一个文件我们能够视觉上看到"\n", 实际上计算机文件存储的是\\ + n两个字符.
如果这个文件被读入到内存中, 变成一个字符串, 其仍然是\\和n两个字符, 如果我们把它print出来, 仍然是"\n" .
这样, 打开文本文件视觉上看到的文本, 和我们使用print看到的文本是完全一致的.
如果我们在test.py程序文件中, 写的是s = r"\n"
那么, 计算机将存储的是\\ + n, 因此print出来仍然还是\n, 也就是说达到了不转义的效果. (注意即使加了r, '和"如果遇到周围包裹的是同样类型的引号, 仍然得转义)

END