[TOC]
引用:Redis详解(四)------ redis的底层数据结构
判断值类型:
object encoding keyname
127.0.0.1:6379> set k1 str
OK
127.0.0.1:6379> set k2 123
OK
127.0.0.1:6379> Object encoding k1
"embstr"
127.0.0.1:6379> Object encoding k2
"int"
127.0.0.1:6379> lpush list1 1 2 3
(integer) 3
127.0.0.1:6379> Object encoding list1
"quicklist"
127.0.0.1:6379>
1.SDS(simple dynamic string)简单动态字符串
-
结构定义
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
SDS保存的字符串结构图示:
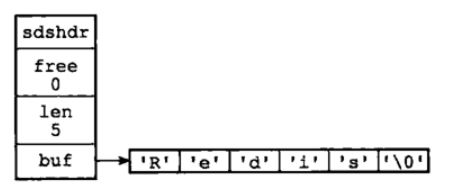
优势
- 常数复杂度获取字符串长度
- 由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过 strlen key 命令可以获取 key 的字符串长度。
- 杜绝缓冲区溢出
- 在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
- 减少修改字符串的内存重新分配次数
- 二进制安全
-
兼容部分C字符串函数
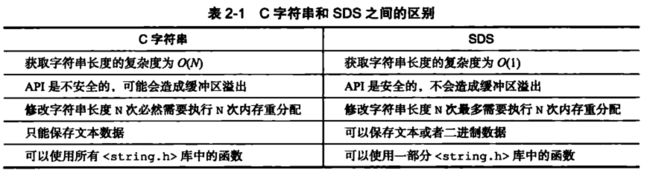 C字符串与Redis简单动态字符串对比图.png
C字符串与Redis简单动态字符串对比图.png
SDS 除了保存数据库中的字符串值以外,SDS 还可以作为缓冲区(buffer):包括 AOF 模块中的AOF缓冲区以及客户端状态中的输入缓冲区
2.链表
-
链表的定义
//链表节点
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}listNode
通过多个 listNode 结构就可以组成链表,这是一个双端链表,Redis还提供了操作链表的数据结构:
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void (*free) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match) (void *ptr,void *key);
}list;
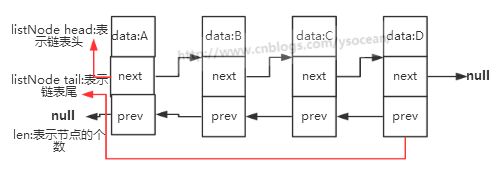
-
链表特性
- 双端:链表具有前置节点和后置节点的引用,获取这两个节点的时间复杂度都为O(1)
- 无环:表头节点的prev指针和表节点的next指针向NULL
- 长度计数器:获取长度时间复杂度O(1)
- 多态:链表节点使用void*指针来保存节点值,可以保存不同类型的值
3.字典
字典又称为符号表或者关联数组、或映射(map),是一种用于保存键值对的抽象数据结构。字典中的每一个键 key 都是唯一的,通过 key 可以对值来进行查找或修改。
- - Redis 的字典使用哈希表作为底层实现
-
哈希表结构定义
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht
哈希表是由数组 table 组成,table 中每个元素都是指向 dict.h/dictEntry 结构,dictEntry 结构定义如下:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
key 用来保存键,val 属性用来保存值,值可以是一个指针,也可以是uint64_t整数,也可以是int64_t整数。
注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过next这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
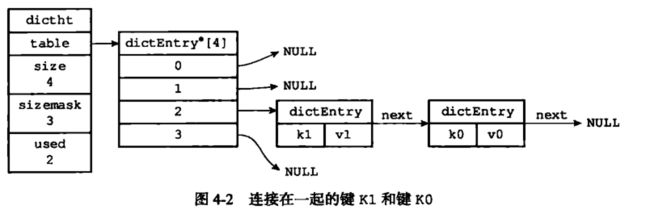
-
Hash表特性
- 哈希算法:Redis计算哈希值和索引值方法如下:
#1、使用字典设置的哈希函数,计算键 key 的哈希值
hash = dict->type->hashFunction(key);
#2、使用哈希表的sizemask属性和第一步得到的哈希值,计算索引值
index = hash & dict->ht[x].sizemask;
- 解决哈希冲突: 链地址法,通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点。
- 扩容和收缩:当哈希表保存的简直对太多或太少的时候,就需要通过rehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
3.1. 扩展操作:每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表;如果执行的是收缩操作:每次收缩根据已使用空间缩小一倍创建一个新的哈希表
3.2. 重新计算索引值(哈希算法),将键值对应到新的哈希表位置上
3.3. 所有键值迁移完成之后,释放旧哈希表的空间。 - 触发扩容的条件:
4.1. Redis服务目前没有执行BGSAVE命令或者BGREWRITEAOF命令,并且负载因子>=1
4.2. Redis服务目前正在执行 BGSAVE命令或者BGREWRITEAOF命令,并且负载因子>=5
4.3. 负载因子= 哈希表已保存节点数量 / 哈希表大小 - 渐进式rehash: 初始化扩容/收缩之后,查询在新旧两个哈希表查询,新增存放在新的哈希表,在迁移完成之后删除旧哈希表
4.跳跃表SkipList
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
-
结构定义
//表节点定义
typedef struct zskiplistNode {
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
} zskiplistNode
多个跳跃表节点构成了一个跳跃表
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
-
跳跃表特性:
- 由很多层结构组成;
- 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
- 最底层的链表包含了所有的元素;
- 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
- 链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
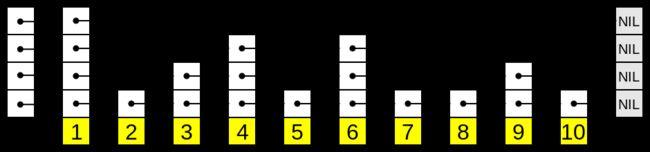 image
image
-
操作
- ①、搜索:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。
- ②、插入:首先确定插入的层数,有一种方法是假设抛一枚硬币,如果是正面就累加,直到遇见反面为止,最后记录正面的次数作为插入的层数。当确定插入的层数k后,则需要将新元素插入到从底层到k层。
- ③、删除:在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层。
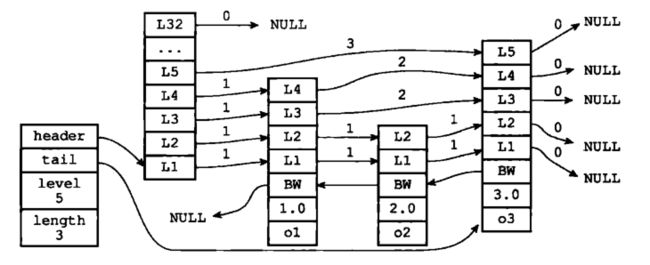 image
image
5.压缩表ZipList
- 压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
- 压缩列表的原理:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。
-
结构定义
//列表节点
typedef struct ziplistNode{
// 记录压缩列表前一个字节的长度.
int previous_entry_length;
// 节点的content的内容类型以及长度.encoding类型一共有两种,一种字节数组一种是整数,encoding区域长度为1字节、2字节或者5字节长。
buf encoding;
// 节点的内容,节点内容类型和长度由encoding决定。
buf content;
}
// 压缩表
typedef struct ziplist{
//表头节点和表尾节点
structz ziplistNode entryX;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int zlbytes;
int zltail;
int zlen;
int zlend:
}ziplist;
结构图
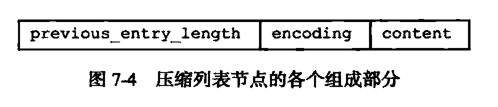

-
压缩表特性
- 节点数据
①、previous_entry_ength:记录压缩列表前一个字节的长度。previous_entry_ength的长度可能是1个字节或者是5个字节,如果上一个节点的长度小于254,则该节点只需要一个字节就可以表示前一个节点的长度了,如果前一个节点的长度大于等于254,则previous length的第一个字节为254,后面用四个字节表示当前节点前一个节点的长度。利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历。这么做很有效地减少了内存的浪费。
②、encoding:节点的encoding保存的是节点的content的内容类型以及长度,encoding类型一共有两种,一种字节数组一种是整数,encoding区域长度为1字节、2字节或者5字节长。
③、content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。
- 节点数据
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:
1、保存的元素数量小于128;
2、保存的所有元素长度都小于64字节。
不能满足上面两个条件的使用 skiplist 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
6.整数集合intset
整数集合intset是Redis用于保存整数值的集合抽象数据类型,他可以保存类型为int16_t,int32_t或者int64_t的整数值,并且保证集合中不会出现重复元素。
-
结构定义
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
整数集合的每一个元素都是contents数组的一个数据项,他们按照从大到小的顺序排列,并且不包含任何重复项
length属性记录来contents数组的大小
需要注意的是虽然contents数组声明为int_8类型,但是实际上contents数组并不保存任何int_8类型的值,其真正类型由encoding来决定。
- 升级
当我们新增的元素类型比原集合类型的长度要大时,需要对数组集合进行升级,才能将新元素放入整数集合中,具体步骤:
- 根据新元素的类型,扩展整数集合底层数组的大小/类型,并为新元素分配空间
- 如果扩展了类型,将底层数组现在的元素都转换为新元素的类型,并在转换后放到对应的位置,放置过程中,维持整个数组元素都是有序的。‘
- 将新元素添加到整数集合中
- 降级
整数集合不支持降级操作,一旦对数组进行来升级,编码就会一直保持升级后的状态。