[TOC]
MHA部署安装
环境
| 描述 | IP | hostname | Desc |
|---|---|---|---|
| Master | 192.168.20.1 | initnode101 | Mysql Master节点,read-write |
| Slave1 | 192.168.20.2 | initnode102 | Mysql Slave 1节点,read-only |
| Slave2 | 192.168.20.3 | initnode103 | Mysql Slave 3节点,read-only,当Master宕机后,被提升为Master(New) |
| MHA Manager | 192.168.20.4 | initnode104 | Mysql Master节点 |
配置主从
简单介绍下配置好主从,已开启GTID,建议在5.7环境下配置为无损复制。
- 创建复制用户
#
### mysql 101执行
#
mysql> create user 'rpl'@'%' identified by '123456';
mysql> grant replication slave on *.* to rpl;
mysql> flush privileges;
- 备份同步
#
# master 101
#
[root@initnode ~]# mysqldump --single-transaction --master-data=1 -A > mysql101_99.sql
# 102、103 需要去执行下
flush privileges;
# 将文件传输到slave服务器上
[root@initnode ~]# scp mysql101_99.sql [email protected]:/root
[root@initnode ~]# scp mysql101_99.sql [email protected]:/root
# 导入数据同步
#
# slave 101、102
#
mysql> reset master;
[root@initnode ~]# mysql < mysql101_99.sql
- 设置主从关系
#
# slave 101、102 分别执行
#
mysql> change master to master_host='192.168.20.101',master_user='rpl',master_password='123456',master_port=3306,master_auto_position=1;
mysql> start slave;
mysql> show slave status\G
下载MHA安装包
这边下载的是 RPM 包,个人喜欢简单点的
wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
下载安装依赖包
#
# MHA Manager
#
# 下载 EPEL扩展包 地址:https://pkgs.org/download/epel-release
wget http://mirror.centos.org/centos/7/extras/x86_64/Packages/epel-release-7-11.noarch.rpm
# 安装补充包EPEL
yum -y localinstall --nogpgcheck epel-release-7-11.noarch.rpm
# 安装依赖包
yum install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager -y
#
# node节点 101、102、103
#
yum install perl-DBD-MySQL -y
安装MHA的RPM包
#
# 所有服务器安装,包括 MHA Manager
#
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#
# 仅在 MHA Manager 上安装 manager包
#MHA节点服务器安装依赖
yum install -y perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
# 仅在从节点安装 master 包,本例安装在 104 上
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
注意: node 需要在所有节点上安装!~
- 可以查看安装好的脚本
[root@initnode4 ~]# ll /usr/bin/ | grep masterha
-rwxr-xr-x 1 root root 1995 Mar 23 2018 masterha_check_repl
-rwxr-xr-x 1 root root 1779 Mar 23 2018 masterha_check_ssh
-rwxr-xr-x 1 root root 1865 Mar 23 2018 masterha_check_status
-rwxr-xr-x 1 root root 3201 Mar 23 2018 masterha_conf_host
-rwxr-xr-x 1 root root 2517 Mar 23 2018 masterha_manager
-rwxr-xr-x 1 root root 2165 Mar 23 2018 masterha_master_monitor
-rwxr-xr-x 1 root root 2373 Mar 23 2018 masterha_master_switch
-rwxr-xr-x 1 root root 5172 Mar 23 2018 masterha_secondary_check
-rwxr-xr-x 1 root root 1739 Mar 23 2018 masterha_stop
主库上创建MHA管理用户
#
# master 101端
#
mysql> create user 'manager'@'192.168.20.%' identified by '1122333';
Query OK, 0 rows affected (0.01 sec)
mysql> grant all privileges on *.* to 'manager'@'192.168.20.%' identified by '1122333';
Query OK, 0 rows affected, 1 warning (0.10 sec)
SSH免密登陆配置
SSH免密码登录是为了能够让 MHA Manager 可以远程登录到各个MySQL Server,以及各个MySQL Server之间可以相互远程登录 ,然后进行相关操作,避免输入密码。
生成密钥
#
# 所有服务端生成密钥,包括 MHA Manager
#一路回车
[root@initnode4 ~]# ssh-keygen -t rsa
公钥分发
# MHA Manager 104端
[root@initnode4 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@initnode4 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@initnode4 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
# Master 101端
[root@initnode1 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@initnode1 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
# Slave 102端
[root@initnode2 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@initnode2 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
# Slave 103端
[root@initnode3 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@initnode3 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
注意:仅仅需要 MySQL Server节点之间 ,以及 MHA Manager到所有MySQL Servers 之间相互打通SSH免密码登录;MySQL Servers到MHA Manager并不需要
修改hosts
为了方便使用主机名登录, 同时MHA Manager在Failover阶段会做resolve name 的操作,所以需要把下列信息加入到所有的节点中。
#
# 所有节点,包括 MHA Manager
#
Shell> vim /etc/hosts
# 添加如下信息
192.168.20.101 initnode1
192.168.20.102 initnode2
192.168.20.103 initnode3
确认SSH已配置完成
在每个服务器上,执行ssh@IP 和 ssh@hostname 的操作(MySQL Server 节点之间相互连接,以及MHA Manager 到所有的 MySQL Server),确认可以免密码登录成功。
Shell> ssh 192.168.20.101
Shell> ssh 192.168.20.102
Shell> ssh 192.168.20.103
Shell> ssh initnode1
Shell> ssh initnode2
Shell> ssh initnode3
MHA配置
配置文件统一放在 /etc/masterha/ 中,针对当前这个MySQL复制组,我们定义为 app1.conf ,如果还有 其他MySQL复制组 ,可以 继续定义app2.conf / app3.conf等等
创建MHA目录
#
# MHA Manager端
#
[root@initnode4 ~]# mkdir -p /etc/masterha
[root@initnode4 ~]# mkdir -p /var/log/masterha/app1
MHA配置文件设置
#
# MHA Manager端
#
[root@initnode4]# vi /etc/masterha/app1.conf
# 写入如下,需更改对应IP与binlog的实际路径
[server default]
# 这两个参数需要根据不同的集群进行修改,工作目录/日志目录
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/manager.log
# 按照master服务器存放binlog的实际路径进行修改,主要为了让MHA拉取binlog
master_binlog_dir=/data/mysql_data/
# 设置自动failover的脚本
master_ip_failover_script= /usr/bin/master_ip_failover
# 设置手动切换时候的脚本(供(masterha_master_switch使用)
master_ip_online_change_script= /usr/bin/master_ip_online_change
# 切换邮件发送
report_script=/usr/bin/send_report
# 日志级别
log_level=debug
#监控的用户,因为要执行一些必要的管理命令,比如:Stop Slave、Change Master、#Reset Slave,所以该账户应该为高权限帐号,这也是缺省值。
user=manager
password=1122333
# 监控主库的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover
ping_interval=3
# 检测方式是insert,MHA-0.56开始支持insert,默认select
# 会在Master中生成一个 infra 数据库
ping_type=INSERT
# 设置远端mysql在发生切换时binlog的保存位置,默认为 /var/tmp
remote_workdir=/tmp
# 复制的用户
repl_user=rpl
# 复制用的密码
repl_password=123456
# 告警脚本,可自行修改,这里没有使用
#report_script=/usr/send_report
# 通过从机进行二次探测的脚本, IP地址按照实际的情况进行修改,强烈建议使用两个或多个网络路由来检查MySQL主服务器的可用性
secondary_check_script=/usr/bin/masterha_secondary_check -s 192.168.20.102 -s 192.168.20.103 --user=manager --master_host=192.168.20.101 --master_port=3306
# 设置故障发生后关闭故障主机的脚本(主要作用是关闭主机防止发生脑裂,这里没有使用,类似Fence功能)
#shutdown_script="/usr/bin/power_manager --command=stopssh2 --host=test-1 --ssh_user=root"
# 定义ssh的用户
ssh_user=root
[server1]
# 这个hostname也可以配置成IP地址,同 ip 参数一样
# 如果这里写名字,需要DNS配合,或者使用 /etc/hosts
hostname=192.168.20.101
port=3306
# candidate_master参数的意思为:设置为候选Master,如果发生主从切换,该主机会被提升为Master,即使这个服务器上的数据不是最新的(会用relay-log补全)
candidate_master=1
[server2]
hostname=192.168.20.102
port=3306
candidate_master=1
# check_repl_delay参数的意思为:默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master;
# 因为对于这个slave的恢复需要花费很长时间;
# 通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时;# 这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0
[server3]
hostname=192.168.20.103
port=3306
# no_master 表示该主机不会被提升为Master
no_master=1
#[binlog1]
#hostname=192.168.20.101
#master_binlog_dir=/data/mysql_data/
#no_master=1
MHA脚本说明
- 修改下面两个脚本中的
$vip和$eth,以符合自己实际的需求; - 将下面两个文件复制到 MHA Manager 节点的 /usr/bin中(同masterha_*在同一个目录);
- 赋予执行权限
- chmod +x master_ip_failover
- chmod +x master_ip_online_change
master_ip_failover
vi /usr/bin/master_ip_failover
#!/usr/bin/env perl
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
#use MHA::DBHelper;
#my $if = "eth0";
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
#自定义该组机器的vip
my $vip = '192.168.20.111/24';
# 广播域(ip a 可查看)
my $brd='192.168.20.255';
#网卡名称
my $eth = 'ens32';
# 网卡的别名编号
my $key = "1";
# 使用的系统是centos7 ,默认没有安装ifconfig命令,改为使用ip addr 添加
#my $ssh_start_vip = "/sbin/ifconfig ens32:$key $vip";
#my $ssh_stop_vip = "/sbin/ifconfig ens32:$key down";
my $ssh_start_vip = "/usr/sbin/ip addr add $vip broadcast $brd dev $eth";
my $ssh_stop_vip = "/usr/sbin/ip addr del $vip broadcast $brd dev $eth";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
#sub add_vip {
# my $output1 = `ssh -o ConnectTimeout=15 -o ConnectionAttempts=3 $orig_master_host /sbin/ip addr del $vip/32 dev $if`;
# my $output2 = `ssh -o ConnectTimeout=15 -o ConnectionAttempts=3 $new_master_host /sbin/ip addr add $vip/32 dev $if`;
#}
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
# updating global catalog, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
###my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
###$new_master_handler->connect( $new_master_ip, $new_master_port,
### $new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
###$new_master_handler->disable_log_bin_local();
###print "Set read_only=0 on the new master.\n";
###$new_master_handler->disable_read_only();
## Creating an app user on the new master
#print "Creating app user on the new master..\n";
#FIXME_xxx_create_user( $new_master_handler->{dbh} );
###$new_master_handler->enable_log_bin_local();
###$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
###&add_vip();
print "Enable the VIP -$vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
# If you want to continue failover, exit 10.
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip {
`ssh -p 22 $ssh_user\@$new_master_host \" $ssh_start_vip \"`; # 按需修改端口
}
sub stop_vip {
return 0 unless ($ssh_user);
`ssh -p 22 $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
master_ip_online_change
vi /usr/bin/master_ip_online_change
#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofday tv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
#自定义该组机器的vip
my $vip = '192.168.20.111/24';
#网卡名称
my $eth = 'ens32';
# 网卡的别名编号
#my $key = "1";
#my $ssh_start_vip = "/sbin/ifconfig ens32:$key $vip";
#my $ssh_stop_vip = "/sbin/ifconfig ens32:$key down";
my $ssh_start_vip = "/usr/sbin/ip addr add $vip dev $eth";
my $ssh_stop_vip = "/usr/sbin/ip addr del $vip dev $eth";
my $ssh_user = "root";
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'orig_master_ssh_user=s' => \$orig_master_ssh_user,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
'new_master_ssh_user=s' => \$new_master_ssh_user,
);
exit &main();
sub current_time_us {
my ( $sec, $microsec ) = gettimeofday();
my $curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec );
}
sub sleep_until {
my $elapsed = tv_interval($_tstart);
if ( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my $dbh = shift;
my $my_connection_id = shift;
my $running_time_threshold = shift;
my $type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless ($type);
my @threads;
my $sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command = $ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time < $running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect" );
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if ( $command eq "stop" ) {
## Gracefully killing connections on the current master
# 1. Set read_only= 1 on the new master
# 2. DROP USER so that no app user can establish new connections
# 3. Set read_only= 1 on the current master
# 4. Kill current queries
# * Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master.. ";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
$orig_master_handler->disable_log_bin_local();
print current_time_us() . " Drpping app user on the orig master..\n";
FIXME_xxx_drop_app_user($orig_master_handler);
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(except SUPER) can write
print current_time_us() . " Set read_only=1 on the orig master.. ";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries can complete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Terminating all threads
print current_time_us() . " Killing all application threads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
print current_time_us() . " done.\n";
$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
# 1. Create app user with write privileges
# 2. Moving backup script if needed
# 3. Register new master's ip to the catalog database
# We don't return error even though activating updatable accounts/ip failed so that we don't interrupt slaves' recovery.
# If exit code is 0 or 10, MHA does not abort
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print current_time_us() . " Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
print current_time_us() . " Creating app user on the new master..\n";
FIXME_xxx_create_app_user($new_master_handler);
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
sub usage {
print
"Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
# die;
}
邮件脚本send_report
vim /usr/bin/send_report126、163邮箱测试了下有问题,发不出邮件,换成新浪邮箱即可
#!/usr/bin/perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
# 需要修改此处信息
my $smtp='smtp.sina.com';
my $mail_from='[email protected]';
my $mail_user='[email protected]';
my $mail_pass='db01c4d285980b6f';
#my $mail_to=['[email protected]','[email protected]'];
my $mail_to='[email protected]';
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' => \$new_master_host,
'new_slave_hosts=s' => \$new_slave_hosts,
'subject=s' => \$subject,
'body=s' => \$body,
);
# Do whatever you want here
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ($smtp, $mail_from, $mail_user, $mail_pass, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, ">/var/log/masterha/app1/mail.log"
or die "Can't open the debug file:$!\n";
my $sender = new Mail::Sender {
ctype => 'text/plain;charset=utf-8',
encoding => 'utf-8',
smtp => $smtp,
from => $mail_from,
auth => 'LOGIN',
TLS_allowed => '0',
authid => $mail_user,
authpwd => $mail_pass,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{
msg => $msg,
debug => $DEBUG
}
) or print $Mail::Sender::Error;
return 1;
}
exit 0;
Slave需要的设置【5.7开启增强半同步不用设置】
从 MHA Failover 的过程中可以了解到, MHA Manager 在恢复(补齐)其他Slave数据时会用到 relay-log ,因此这些 relay-log 需要被保留。
而默认情况下,SQL线程在回放完毕后,MySQL会 主动删除relay-log ,需要 禁用 该功能,确保 relay-log 不被自动删除。
# 关闭relay_log自动清除功能
mysql> set global relay_log_purge = 0;
Query OK, 0 rows affected (0.00 sec)
# 设置只读库为 read_only
mysql> set global read_only = 1;
Query OK, 0 rows affected (0.01 sec)
但是这样做了以后又带来另外一个问题, relay-log会大量堆积 ,导致磁盘空间紧张,所以需要 定时清空 过时的 relay-log 。
所幸的是MHA帮我们实现了这个功能, MHA Node 的安装包中有一个 pure_relay_logs 工具,提供 删除大量relay-log 的功能。
定时清理relay-log的脚本【5.7开启增强半同步不用设置】
将下面这个脚本以及定时任务放入 所有的Slave节点
#!/bin/bash
# Filename:/usr/bin/cron_purge_relay_logs.sh
user=manager
passwd=1122333
port=3306
log_dir='/data/mysql_data/purge_relay_logs'
work_dir='/data/mysql_data/relay_log_hardlink'
purge='/usr/bin/purge_relay_logs'
if [[ ! -d ${work_dir} ]];then
mkdir ${work_dir} -p
fi
if [[ ! -d ${log_dir} ]];then
mkdir ${log_dir} -p
fi
${purge} --user=${user} --password=${passwd} --port=${port} --workdir=${work_dir} --disable_relay_log_purge >> ${log_dir}/purge_relay_logs.log 2>&1
- 增加执行权限
Shell> chmod +x /usr/bin/cron_purge_relay_logs.sh
- 添加到计划任务
Shell> crontab -e # 编辑定时任务
# 输入如下
0 5 * * * /bin/bash /usr/bin/cron_purge_relay_logs.sh
# 保存退出
Shell> crontab -l # 查看当前cron信息
0 5 * * * /bin/bash /usr/bin/cron_purge_relay_logs.sh
pure_relay_logs的参数
- --user : 用户名
- --password : 密码
- --port : 端口号
- --workdir : 指定 创建relay-log的硬链接 的位置
- 默认是 /var/tmp ,由于 硬连接不能跨分区 ,所以请 确保这个目录和你的relay-log在同一个分区 ;
- 当脚本执行成功后,硬链接会被删除
- --disable_relay_log_purge : 默认情况下,如果 relay_log_purge=1 ,脚本会什么都不清理,自动退出
- 通过设定这个参数,当 relay_log_purge=1 的情况下,会执行脚本,并将该参数relay_log_purge设置为0。
- 但是最好还是要在 /etc/my.cnf 中显示配置 relay_log_purge=0 ,避免重启服务后被还原。
MHA配置检测
MHA Master上操作
SSH关系检测
[root@initnode4 bin]# masterha_check_ssh --conf=/etc/masterha/app1.conf
Tue Sep 10 00:45:20 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Sep 10 00:45:20 2019 - [info] Reading application default configuration from /etc/masterha/app1.conf..
Tue Sep 10 00:45:20 2019 - [info] Reading server configuration from /etc/masterha/app1.conf..
...省略...
Tue Sep 10 00:45:23 2019 - [info] All SSH connection tests passed successfully. # 看到最后这一行为 successfully
主从复制关系检测
[root@initnode4 bin]# masterha_check_repl --conf=/etc/masterha/app1.conf
Tue Sep 10 00:46:23 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Sep 10 00:46:23 2019 - [info] Reading application default configuration from /etc/masterha/app1.conf..
Tue Sep 10 00:46:23 2019 - [info] Reading server configuration from /etc/masterha/app1.conf..
Tue Sep 10 00:46:23 2019 - [info] MHA::MasterMonitor version 0.58.
Tue Sep 10 00:46:23 2019 - [debug] Connecting to servers..
...省略...
MySQL Replication Health is OK. # 最后一行为检测OK
启动或关闭MHA
添加VIP
目前大概有如下几种访问方式:
1-虚拟IP
- 方式一: Keepalived :Keepalived是Linux下的一个高可用组件,可以让两台或多台Linux主机组成一个高可用集群,对外提供一个虚拟IP进行访问,但是 Keepalived 可能由于网络问题导致脑裂。
- 方式二:使用脚本 masterha_ip_failover ;由于这个脚本的start/stop操作只有在切换(Failover)期间才会执行。即便你设置了该脚本,MHA也不会在一开始( masterha_manager启动 )的时候,帮你在Master上设置VIP,初次在Master上设置VIP需要人工操作,后期如果有Failover操作,MHA会执行脚本,帮你切换。
2-智能DNS
此种模式下,MySQL集群本身只做高可用,维持复制关系,Apps通过内网DNS来访问MySQL。此种情况下,需要DNS端可以检测MySQL服务是否可用,从而决定推送Master还是Slave1的IP地址给Apps,类似Smart Client的效果;
推荐使用的方式是方式二,生成VIP
#
# Master 101端
#
#在我的虚拟机中,网卡名称为ens32,初始化VIP
Shell> ip addr add 192.168.20.111/24 dev ens32
## 删除 VIP 如下
ip addr del 192.168.20.111/24 dev ens32
启动MHA
#
# MHA Manager 104端
# 启动如果出错去配置的日志文件下查看
[root@initnode4 bin]# nohup masterha_manager --conf=/etc/masterha/app1.conf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
[1] 22390
# 查看启动状态
[root@initnode4 bin]# masterha_check_status --conf=/etc/masterha/app1.conf
app1 (pid:22390) is running(0:PING_OK), master:192.168.20.101 # 当前状态正常,master是 101
masterha_manager参数解释
- --conf :当前MySQL集群的配置文件,可以有多个,应用于不同的集群
- --remove_dead_master_conf :当发生切换操作后(Failover),需要把之前的 Dead Master 从配置文件中删除。如果不删除,且没有恢复的话,此时 masterha_manager 重启后,会报错 "there is a dead slave"
- --ignore_last_failover :如果前一次Failover失败了,MHA不会去再一次去做Failover操作,除非人为的删除 (manager_workdir)/(app_name).failover.error ,或者增加此参数,MHA会继续进行Failover操作。
自动Failover测试
测试步骤如下:
1. 停掉 Slave的IO线程 ,模拟复制延时(Slave1保持不变);
2. 使用sysbench对Master进行测试,生成测试数据(可以 产生大量的binlog );
3. 等待步骤2完成 后, 开启Slave上的IO线程 ,去追Master的binlog,同时立即操作第四步;
4. 关闭Master上的MySQL ,让MHA 产生 Failover 操作;
5. 观察最终状态;
停止Slave的IO线程
#
#Slave 102,103端
#
# show slave status\G 会看到 Slave_IO_Running: No
mysql> stop slave io_thread;
生成测试数据,模拟大量写入
主上没有安装 sysbench 可以使用yum安装,需要安装EPEL源
- sysbench 生成测试数据
#
# Master 101端
# 若主库不存在 sbtest 需要创建,给sysbench使用
mysql> create database sbtest;
# 写入测试数据,产生测试的binlig
[root@initnode1 ~]# sysbench /usr/share/sysbench/oltp_insert.lua --mysql-user=test --mysql-password=123456 --mysql-host=192.168.20.101 --mysql-port=3306 --threads=2 --events=0 --time=30 --table-size=10000 --tables=2 --report-interval=3 prepare
[root@initnode1 ~]# sysbench /usr/share/sysbench/oltp_insert.lua --mysql-user=test --mysql-password=123456 --mysql-host=192.168.20.101 --mysql-port=3306 --threads=2 --events=0 --time=30 --table-size=10000 --tables=2 --report-interval=3 run
- sysbench跑完后,继续手动写入一些数据
mysql> create database aaa;
Query OK, 1 row affected (0.00 sec)
mysql> use aaa;
Database changed
mysql> create table t(id int);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t select 1;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into t select 2;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into t select 3;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
开启Slave的IO线程,同时kill掉master上mysql进程
#
# Slave 1、Slave 2上执行
#
mysql> start slave io_thread;
#
# master(101)上执行
#
[root@initnode1 ~]# ps -ef|grep mysql
root 6641 1 0 Sep09 ? 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir=/data/mysql_data --pid-file=/data/mysql_data/initnode1.pid
mysql 7644 6641 1 Sep09 ? 00:02:20 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql_data --plugin-dir=/usr/local/mysql/lib/plugin --user=mysql --log-error=error.log --pid-file=/data/mysql_data/initnode1.pid --port=3306
root 8306 7875 0 01:20 pts/1 00:00:00 grep --color=auto mysql
[root@initnode1 ~]# kill -9 6641 #记得先kill mysqld_safe进程,否则kill掉的mysql进程会被自动拉起
[root@initnode1 ~]# kill -9 7644
MHA切换日志明细
Failover过程,大致包含如下步骤:
1. 多次探测(含通过Slave进行二次探测)Master,确认是否宕机;
2. 检查配置文件阶段, 包括MySQL实例的当前的配置
3. 处理Master,前提是还能ssh到Master,否则跳过该步骤; 包括删除虚拟IP,还有关机操作(防止脑裂,但是关机配置我们注释了);
4. 如果还能SSH到Master上,则 复制binlog 到MHA Manager上,否则跳过◦ 这一步在源码和之前网上别人的日志中是能看到 scp 信息的,但是我这里没出现scp信息,不知道是否是MHA0.57的问题,但是最终数据是能一致(表明确实是获取binlog了)
从这里看出,单纯的靠MHA是不能完全保证数据不丢的;
5. 确认包含最新更新的Slave ;
6. 应用从master保存的binlog ;
7. 将配置中配置为 candidate_master=1 的Slave,提升为 New Master;
8. 配置其他的Slave连接( CHANGE MASTER TO ) New Master;
Tue Sep 10 02:48:12 2019 - [info] Ping(INSERT) succeeded, waiting until MySQL doesn't respond..
# ----------------MHA 发现Master已经不通了-------------------
Tue Sep 10 02:48:33 2019 - [warning] Got error on MySQL insert ping: 2006 (MySQL server has gone away)
Tue Sep 10 02:48:33 2019 - [info] Executing SSH check script: exit 0
Tue Sep 10 02:48:33 2019 - [debug] SSH connection test to 192.168.20.101, option -o StrictHostKeyChecking=no -o PasswordAuthentication=no -o BatchMode=yes -o ConnectTimeout=5, timeout 5
# ----------启用二次探测的方式,进一步确认Master是否挂了---------
Tue Sep 10 02:48:33 2019 - [info] Executing secondary network check script: /usr/bin/masterha_secondary_check -s 192.168.20.102 -s 192.168.20.103 --user=root --master_host=192.168.20.101 --master_port=3306 --user=root --master_host=192.168.20.101 --master_i
p=192.168.20.101 --master_port=3306 --master_user=root --master_password=1122333 --ping_type=INSERT
Tue Sep 10 02:48:34 2019 - [info] HealthCheck: SSH to 192.168.20.101 is reachable.
Monitoring server 192.168.20.102 is reachable, Master is not reachable from 192.168.20.102. OK.
Monitoring server 192.168.20.103 is reachable, Master is not reachable from 192.168.20.103. OK.
Tue Sep 10 02:48:34 2019 - [info] Master is not reachable from all other monitoring servers. Failover should start.
Tue Sep 10 02:48:36 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.20.101' (111))
Tue Sep 10 02:48:36 2019 - [warning] Connection failed 2 time(s)..
Tue Sep 10 02:48:39 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.20.101' (111))
Tue Sep 10 02:48:39 2019 - [warning] Connection failed 3 time(s)..
Tue Sep 10 02:48:42 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.20.101' (111))
Tue Sep 10 02:48:42 2019 - [warning] Connection failed 4 time(s)..
# ----------------------确认Master已经挂了----------------------
Tue Sep 10 02:48:42 2019 - [warning] Master is not reachable from health checker!
Tue Sep 10 02:48:42 2019 - [warning] Master 192.168.20.101(192.168.20.101:3306) is not reachable!
Tue Sep 10 02:48:42 2019 - [warning] SSH is reachable.
Tue Sep 10 02:48:42 2019 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/masterha/app1.conf again, and trying to connect to all servers to check server status..
Tue Sep 10 02:48:42 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
# --------------------检查MHA配置----------------------
Tue Sep 10 02:48:42 2019 - [info] Reading application default configuration from /etc/masterha/app1.conf..
Tue Sep 10 02:48:42 2019 - [info] Reading server configuration from /etc/masterha/app1.conf..
Tue Sep 10 02:48:42 2019 - [debug] Skipping connecting to dead master 192.168.20.101(192.168.20.101:3306).
Tue Sep 10 02:48:42 2019 - [debug] Connecting to servers..
Tue Sep 10 02:48:43 2019 - [debug] Connected to: 192.168.20.102(192.168.20.102:3306), user=root
Tue Sep 10 02:48:43 2019 - [debug] Number of slave worker threads on host 192.168.20.102(192.168.20.102:3306): 0
Tue Sep 10 02:48:43 2019 - [debug] Connected to: 192.168.20.103(192.168.20.103:3306), user=root
Tue Sep 10 02:48:43 2019 - [debug] Number of slave worker threads on host 192.168.20.103(192.168.20.103:3306): 0
Tue Sep 10 02:48:43 2019 - [debug] Comparing MySQL versions..
Tue Sep 10 02:48:43 2019 - [debug] Comparing MySQL versions done.
Tue Sep 10 02:48:43 2019 - [debug] Connecting to servers done.
Tue Sep 10 02:48:43 2019 - [info] GTID failover mode = 1
Tue Sep 10 02:48:43 2019 - [info] Dead Servers:
Tue Sep 10 02:48:43 2019 - [info] 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:43 2019 - [info] Alive Servers:
Tue Sep 10 02:48:43 2019 - [info] 192.168.20.102(192.168.20.102:3306)
Tue Sep 10 02:48:43 2019 - [info] 192.168.20.103(192.168.20.103:3306)
Tue Sep 10 02:48:43 2019 - [info] Alive Slaves:
Tue Sep 10 02:48:43 2019 - [info] 192.168.20.102(192.168.20.102:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:43 2019 - [info] GTID ON
Tue Sep 10 02:48:43 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:43 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:43 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Sep 10 02:48:43 2019 - [info] 192.168.20.103(192.168.20.103:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:43 2019 - [info] GTID ON
Tue Sep 10 02:48:43 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:43 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:43 2019 - [info] Not candidate for the new Master (no_master is set)
Tue Sep 10 02:48:43 2019 - [info] Checking slave configurations..
Tue Sep 10 02:48:43 2019 - [info] Checking replication filtering settings..
Tue Sep 10 02:48:43 2019 - [info] Replication filtering check ok.
Tue Sep 10 02:48:43 2019 - [info] Master is down!
Tue Sep 10 02:48:43 2019 - [info] Terminating monitoring script.
Tue Sep 10 02:48:43 2019 - [debug] Disconnected from 192.168.20.102(192.168.20.102:3306)
Tue Sep 10 02:48:43 2019 - [debug] Disconnected from 192.168.20.103(192.168.20.103:3306)
Tue Sep 10 02:48:43 2019 - [info] Got exit code 20 (Master dead).
Tue Sep 10 02:48:43 2019 - [info] MHA::MasterFailover version 0.58.
# --------------------开始进行切换----------------------
Tue Sep 10 02:48:43 2019 - [info] Starting master failover.
Tue Sep 10 02:48:43 2019 - [info]
#==================第一阶段:配置检查(包括MySQL的配置)==============
Tue Sep 10 02:48:43 2019 - [info] * Phase 1: Configuration Check Phase..
Tue Sep 10 02:48:43 2019 - [info]
Tue Sep 10 02:48:44 2019 - [debug] Skipping connecting to dead master 192.168.20.101.
Tue Sep 10 02:48:44 2019 - [debug] Connecting to servers..
Tue Sep 10 02:48:45 2019 - [debug] Connected to: 192.168.20.102(192.168.20.102:3306), user=root
Tue Sep 10 02:48:45 2019 - [debug] Number of slave worker threads on host 192.168.20.102(192.168.20.102:3306): 0
Tue Sep 10 02:48:45 2019 - [debug] Connected to: 192.168.20.103(192.168.20.103:3306), user=root
Tue Sep 10 02:48:45 2019 - [debug] Number of slave worker threads on host 192.168.20.103(192.168.20.103:3306): 0
Tue Sep 10 02:48:45 2019 - [debug] Comparing MySQL versions..
Tue Sep 10 02:48:45 2019 - [debug] Comparing MySQL versions done.
Tue Sep 10 02:48:45 2019 - [debug] Connecting to servers done.
Tue Sep 10 02:48:45 2019 - [info] GTID failover mode = 1
Tue Sep 10 02:48:45 2019 - [info] Dead Servers:
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Alive Servers:
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.102(192.168.20.102:3306)
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.103(192.168.20.103:3306)
Tue Sep 10 02:48:45 2019 - [info] Alive Slaves:
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.102(192.168.20.102:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.103(192.168.20.103:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Not candidate for the new Master (no_master is set)
Tue Sep 10 02:48:45 2019 - [info] Starting GTID based failover.
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] ** Phase 1: Configuration Check Phase completed.
# ==========================第一阶段完成=======================
Tue Sep 10 02:48:45 2019 - [info]
# ====================第二阶段: 开始清理Master===================
Tue Sep 10 02:48:45 2019 - [info] * Phase 2: Dead Master Shutdown Phase..
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] Forcing shutdown so that applications never connect to the current master..
Tue Sep 10 02:48:45 2019 - [info] Executing master IP deactivation script:
Tue Sep 10 02:48:45 2019 - [info] /usr/bin/master_ip_failover --orig_master_host=192.168.20.101 --orig_master_ip=192.168.20.101 --orig_master_port=3306 --command=stopssh --ssh_user=root
Tue Sep 10 02:48:45 2019 - [debug] Stopping IO thread on 192.168.20.102(192.168.20.102:3306)..
Tue Sep 10 02:48:45 2019 - [debug] Stopping IO thread on 192.168.20.103(192.168.20.103:3306)..
Tue Sep 10 02:48:45 2019 - [debug] Stop IO thread on 192.168.20.103(192.168.20.103:3306) done.
Tue Sep 10 02:48:45 2019 - [debug] Stop IO thread on 192.168.20.102(192.168.20.102:3306) done.
# ====================第二阶段完成===================
IN SCRIPT TEST====/usr/sbin/ip addr del 192.168.20.111/24 dev ens32==/usr/sbin/ip addr add 192.168.20.111/24 dev ens32===
# --------------------清除当前主上的VIP----------------------
Disabling the VIP on old master: 192.168.20.101
Tue Sep 10 02:48:45 2019 - [info] done.
# shutdown_script 是关机脚本,为了防止脑裂,由于配置中被注释了,所以这里忽略
Tue Sep 10 02:48:45 2019 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Tue Sep 10 02:48:45 2019 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Tue Sep 10 02:48:45 2019 - [info]
# ====================第三阶段:Master日志拉取===================
# 如果Master服务器挂了,这个阶段应该跳过
Tue Sep 10 02:48:45 2019 - [info] * Phase 3: Master Recovery Phase..
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [debug] Fetching current slave status..
Tue Sep 10 02:48:45 2019 - [debug] Fetching current slave status done.
Tue Sep 10 02:48:45 2019 - [info] The latest binary log file/position on all slaves is bin.000014:5757
Tue Sep 10 02:48:45 2019 - [info] Retrieved Gtid Set: a7776f71-c8be-11e9-838f-0050563bb195:751444-751708
Tue Sep 10 02:48:45 2019 - [info] Latest slaves (Slaves that received relay log files to the latest):
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.102(192.168.20.102:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.103(192.168.20.103:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Not candidate for the new Master (no_master is set)
Tue Sep 10 02:48:45 2019 - [info] The oldest binary log file/position on all slaves is bin.000014:5757
Tue Sep 10 02:48:45 2019 - [info] Retrieved Gtid Set: a7776f71-c8be-11e9-838f-0050563bb195:751444-751708
Tue Sep 10 02:48:45 2019 - [info] Oldest slaves:
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.102(192.168.20.102:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.103(192.168.20.103:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Not candidate for the new Master (no_master is set)
Tue Sep 10 02:48:45 2019 - [info]
# -----------------------选举新的Master------------------
Tue Sep 10 02:48:45 2019 - [info] * Phase 3.3: Determining New Master Phase..
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] Searching new master from slaves..
Tue Sep 10 02:48:45 2019 - [info] Candidate masters from the configuration file:
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.102(192.168.20.102:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Sep 10 02:48:45 2019 - [info] Non-candidate masters:
Tue Sep 10 02:48:45 2019 - [info] 192.168.20.103(192.168.20.103:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled
Tue Sep 10 02:48:45 2019 - [info] GTID ON
Tue Sep 10 02:48:45 2019 - [debug] Relay log info repository: TABLE
Tue Sep 10 02:48:45 2019 - [info] Replicating from 192.168.20.101(192.168.20.101:3306)
Tue Sep 10 02:48:45 2019 - [info] Not candidate for the new Master (no_master is set)
Tue Sep 10 02:48:45 2019 - [info] Searching from candidate_master slaves which have received the latest relay log events..
Tue Sep 10 02:48:45 2019 - [info] New master is 192.168.20.102(192.168.20.102:3306)
#----------------------开始切换 new master----------------
Tue Sep 10 02:48:45 2019 - [info] Starting master failover..
Tue Sep 10 02:48:45 2019 - [info]
From:
192.168.20.101(192.168.20.101:3306) (current master)
+--192.168.20.102(192.168.20.102:3306)
+--192.168.20.103(192.168.20.103:3306)
To:
192.168.20.102(192.168.20.102:3306) (new master)
+--192.168.20.103(192.168.20.103:3306)
Tue Sep 10 02:48:45 2019 - [info]
# -------------------新master恢复---------------
Tue Sep 10 02:48:45 2019 - [info] * Phase 3.3: New Master Recovery Phase..
Tue Sep 10 02:48:45 2019 - [info]
# --------------------等待日志被应用-------------
Tue Sep 10 02:48:45 2019 - [info] Waiting all logs to be applied..
Tue Sep 10 02:48:45 2019 - [info] done.
Tue Sep 10 02:48:45 2019 - [debug] Stopping slave IO/SQL thread on 192.168.20.102(192.168.20.102:3306)..
Tue Sep 10 02:48:45 2019 - [debug] done.
Tue Sep 10 02:48:45 2019 - [info] Getting new master's binlog name and position..
Tue Sep 10 02:48:45 2019 - [info] bin.000001:61448
# ------------------执行Change Master操作--------------
Tue Sep 10 02:48:45 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.20.102', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rpl', MASTER_PASSWORD='xxx';
Tue Sep 10 02:48:45 2019 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: bin.000001, 61448, a7776f71-c8be-11e9-838f-0050563bb195:1-751708
Tue Sep 10 02:48:45 2019 - [info] Executing master IP activate script:
Tue Sep 10 02:48:45 2019 - [info] /usr/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.20.101 --orig_master_ip=192.168.20.101 --orig_master_port=3306 --new_master_host=192.168.20.102 --new_master_ip=192.168.20.102 --new_mast
er_port=3306 --new_master_user='root' --new_master_password=xxx
IN SCRIPT TEST====/usr/sbin/ip addr del 192.168.20.111/24 dev ens32==/usr/sbin/ip addr add 192.168.20.111/24 dev ens32===
# -----------------将 VIP 漂移到 Slave1 上----------------
Enable the VIP -192.168.20.111/24 on the new master - 192.168.20.102
Tue Sep 10 02:48:45 2019 - [info] OK.
Tue Sep 10 02:48:45 2019 - [info] Setting read_only=0 on 192.168.20.102(192.168.20.102:3306)..
Tue Sep 10 02:48:45 2019 - [info] ok.
Tue Sep 10 02:48:45 2019 - [info] ** Finished master recovery successfully.
# ------------------Master恢复完成----------------
Tue Sep 10 02:48:45 2019 - [info] * Phase 3: Master Recovery Phase completed.
# ====================== 第三阶段 完成 =======================
a":{}}}
Tue Sep 10 02:48:45 2019 - [info]
# ====================== 第四阶段 slave恢复 =======================
Tue Sep 10 02:48:45 2019 - [info] * Phase 4: Slaves Recovery Phase..
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] * Phase 4.1: Starting Slaves in parallel..
Tue Sep 10 02:48:45 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] -- Slave recovery on host 192.168.20.103(192.168.20.103:3306) started, pid: 24015. Check tmp log /var/log/masterha/app1/192.168.20.103_3306_20190910024843.log if it takes time..
Tue Sep 10 02:48:46 2019 - [info]
Tue Sep 10 02:48:46 2019 - [info] Log messages from 192.168.20.103 ...
Tue Sep 10 02:48:46 2019 - [info]
Tue Sep 10 02:48:45 2019 - [info] Resetting slave 192.168.20.103(192.168.20.103:3306) and starting replication from the new master 192.168.20.102(192.168.20.102:3306)..
Tue Sep 10 02:48:45 2019 - [debug] Stopping slave IO/SQL thread on 192.168.20.103(192.168.20.103:3306)..
Tue Sep 10 02:48:45 2019 - [debug] done.
Tue Sep 10 02:48:45 2019 - [info] Executed CHANGE MASTER.
Tue Sep 10 02:48:45 2019 - [debug] Starting slave IO/SQL thread on 192.168.20.103(192.168.20.103:3306)..
Tue Sep 10 02:48:45 2019 - [debug] done.
Tue Sep 10 02:48:45 2019 - [info] Slave started.
Tue Sep 10 02:48:45 2019 - [info] gtid_wait(a7776f71-c8be-11e9-838f-0050563bb195:1-751708) completed on 192.168.20.103(192.168.20.103:3306). Executed 0 events.
Tue Sep 10 02:48:46 2019 - [info] End of log messages from 192.168.20.103.
Tue Sep 10 02:48:46 2019 - [info] -- Slave on host 192.168.20.103(192.168.20.103:3306) started.
Tue Sep 10 02:48:46 2019 - [info] All new slave servers recovered successfully.
# ====================== 第四阶段 完成,所有从机恢复完成 =======================
Tue Sep 10 02:48:46 2019 - [info]
# ====================== 第五阶段 New Master清理 =======================
Tue Sep 10 02:48:46 2019 - [info] * Phase 5: New master cleanup phase..
Tue Sep 10 02:48:46 2019 - [info]
Tue Sep 10 02:48:46 2019 - [info] Resetting slave info on the new master..
Tue Sep 10 02:48:46 2019 - [debug] Clearing slave info..
Tue Sep 10 02:48:46 2019 - [debug] Stopping slave IO/SQL thread on 192.168.20.102(192.168.20.102:3306)..
Tue Sep 10 02:48:46 2019 - [debug] done.
Tue Sep 10 02:48:46 2019 - [debug] SHOW SLAVE STATUS shows new master does not replicate from anywhere. OK.
Tue Sep 10 02:48:46 2019 - [info] 192.168.20.102: Resetting slave info succeeded.
Tue Sep 10 02:48:46 2019 - [info] Master failover to 192.168.20.102(192.168.20.102:3306) completed successfully.
Tue Sep 10 02:48:46 2019 - [info] Deleted server1 entry from /etc/masterha/app1.conf .
Tue Sep 10 02:48:46 2019 - [debug] Disconnected from 192.168.20.102(192.168.20.102:3306)
Tue Sep 10 02:48:46 2019 - [debug] Disconnected from 192.168.20.103(192.168.20.103:3306)
Tue Sep 10 02:48:46 2019 - [info]
----- Failover Report -----
app1: MySQL Master failover 192.168.20.101(192.168.20.101:3306) to 192.168.20.102(192.168.20.102:3306) succeeded
Master 192.168.20.101(192.168.20.101:3306) is down!
Check MHA Manager logs at initnode4:/var/log/masterha/app1/manager.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.20.101(192.168.20.101:3306)
Selected 192.168.20.102(192.168.20.102:3306) as a new master.
192.168.20.102(192.168.20.102:3306): OK: Applying all logs succeeded.
192.168.20.102(192.168.20.102:3306): OK: Activated master IP address.
192.168.20.103(192.168.20.103:3306): OK: Slave started, replicating from 192.168.20.102(192.168.20.102:3306)
192.168.20.102(192.168.20.102:3306): Resetting slave info succeeded.
Master failover to 192.168.20.102(192.168.20.102:3306) completed successfully.
# =======================在线切换成功======================
查看最终复制关系
- VIP 查看
VIP从101端漂移到了102端
#
#101、102端查看
#
shell> ip a
- Slave 查看
可见102已被设置为新主,103的主从关系修改为102为主
#
# Slave 103 端
#
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.20.102
Master_User: rpl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: bin.000002
Read_Master_Log_Pos: 194
Relay_Log_File: relay.000004
Relay_Log_Pos: 355
Relay_Master_Log_File: bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
查看切换后masterha_manager的配置
现在由于 masterha_manager 配置了--remove_dead_master_conf的参数,在 Failover完成后 ,自动将 Dead Master 从配置文件中去除,这样可以确保 重新启动masterha_manager 时,不会把 Dead Master 加入到MySQL集群中去,从而引发错误。
[root@initnode4 app1]# more /etc/masterha/app1.conf
[server default]
log_level=debug
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1
master_binlog_dir=/data/mysql_data/
master_ip_failover_script=/usr/bin/master_ip_failover
master_ip_online_change_script=/usr/bin/master_ip_online_change
password=1122333
ping_interval=3
ping_type=INSERT
remote_workdir=/tmp
repl_password=123456
repl_user=rpl
secondary_check_script=/usr/bin/masterha_secondary_check -s 192.168.20.102 -s 192.168.20.103 --user=root --master_host=192.168.20.101 --master_port=3306
ssh_user=root
user=root
# ---------------- 之前配置的 [server1] 被移除了 -----------
[server2]
candidate_master=1
check_repl_delay=0
hostname=192.168.20.102
port=3306
[server3]
hostname=192.168.20.103
no_master=1
port=3306
注意事项
Failover后MHA_Manager自动退出
当自动Failover完成后,MHA Manager服务器上的 masterha_manager 进程自动退出。
可以使用 supervisor 来进行托管(python程序员用的很多),该软件的主要作用就是托管程序,并且可以简单的检测程序状态,发现停止后可以自动重启运行;
注意:在MHA重启后, 日志部分会被自动回滚覆盖 ,MHA日志中的binlog的filename和pos、以及GTID信息也会消失。所以是否自动重启还是需要看DBA和业务需要。
如果 masterha_manager可以自动重启 后,那一定要开启--remove_dead_master_conf参数。因为既然切换(Failover)了(masterha_manager默认自动退出),说明配置文件列表中有server是宕机了,需要踢出MySQL集群,那如果此时没有配置该参数,当masterha_manager自动重启时, 仍能读取到宕机的server的配置 ,就会启动失败,然后一直循环启动。
# 安装
Shell> yum install supervisor
• 配置文件/etc/supervisord.conf
[unix_http_server]
file=/var/run/supervisor.sock ; (the path to the socket file)
[supervisord]
logfile=/var/log/supervisord.log ; (main log file;default $CWD/supervisord.log)
logfile_maxbytes=50MB ; (max main logfile bytes b4 rotation;default 50MB)
logfile_backups=10 ; (num of main logfile rotation backups;default 10)
loglevel=info ; (log level;default info; others: debug,warn,trace)
pidfile=/var/run/supervisord.pid ; (supervisord pidfile;default supervisord.pid)
nodaemon=false ; (start in foreground if true;default false)
minfds=1024 ; (min. avail startup file descriptors;default 1024)
minprocs=200 ; (min. avail process descriptors;default 200)
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///var/run/supervisor.sock ; use a unix:// URL for a unix socket
[program:mha_manager]
command=nohup /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.conf --remove_dead_master_conf --ignore_last_failover
process_name=%(program_name)s
autostart=true
autorestart=true
redirect_stderr=true
stdout_logfile=/var/log/masterha/app1/manager.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=5
user=root
#启动supervisord
Shell> systemctl start supervisord.service
# 开启自启动
Shell> systemctl enabled supervisord.service
# 测试,kill掉MHA进程观察是否被拉起
手动Failover测试
在使用手动Failover的时候,masterha_manager(在线Failover功能)需要关闭,这个也是MHA留给我们自己决定的地方,线上使用可以选择使用自动切换,也可以通过报警后,处理问题,然后决定是否手工切换。
注意事项:
1. 如果你的 app1.conf 中配置的 hostname 为 Master、Slave1 等,则上述命令中的 --dead_master_host 和 --new_master_host 也需要写成 Master、Slave1 ,而 不能写成IP地址
2. 如果你的 app1.conf 中配置的 hostname 为IP地址,则 --dead_master_host 和 --new_master_host 也要配置成IP地址
3.在进行手动Failover的时候,请确保Master上的MySQL挂了,否则会提示服务没挂
#
# MHA Manager 端
#
Shell> masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.conf --dead_master_host=192.168.20.101 --dead_master_port=3306 --new_master_host=192.168.20.103 --new_master_port=3306 --ignore_last_failover
... 省略 ...
# 会问你俩个问题,都回答 yes
Master 192.168.20.101(192.168.20.101:3306) is dead. Proceed? (yes/NO): yes
Starting master switch from 192.168.20.101(192.168.20.101:3306) to 192.168.20.103(192.168.20.103:3306)? (yes/NO): yes
... 省略 ...
192.168.20.103(192.168.20.103:3306): Resetting slave info succeeded.
Master failover to 192.168.20.103(192.168.20.103:3306) completed successfully.
MHA总结
部署操作
1. 配置好MySQL 复制关系 ,至少三个节点,且确保 rpl用户 传递到Slave上;
2. 在 MHA Manager 上安装 Manager 组件;
3. 在 所有节点 上安装 Node 组件;
4. 配置好 /etc/masterha/app1.conf ;
5. 验证主从配置masterha_check_repl --conf=/etc/masterha/app1.conf;
6. 启动 masterha_manager (或supervisord托管);
7. 确认 masterha_check_status 状态;
Old_Master恢复
当切换完成后, 假如Old Master修复完成 ,这时需要对比一下数据是否一致;如果主从不一致,即Old Master 宕机时刻的binlog 没有传到Slave, 且MHA也无法获取到这部分binlog ,需要通过 Flashback 工具将这部分数据切除;
- Old Master 的binlog信息可以通过 show master status\G 看到,或者通过 mysqlbinlog 进行查看;
- New Master 上查看执行到的 Old Master 复制过来的binlog信息可以通过 show global variables like "%gtid%"; 来进行查看(mysql会保留之前执行过的GTID信息);
- 在没有使用MHA,或者使用MHA手动Failover的时候,可以通过在Slave上执行 show slave status\G 通过 Exec_Master_Log_Pos 观察到执行到的位置(等待回放完毕)
- 而使用MHA切换后, show slave status\G 的信息会被MHA给reset掉(除非自己给MHA打补丁,将信息记录下来);
一般情况下,只需要将挂掉的机器启动后,查看下gtid值,直接change master到新主就能追平数据
mysql> change master to master_host='192.168.20.102',master_user='rpl',master_password='123456',master_port=3306,master_auto_position=1;
# 启动复制
start slave;
# 查看状态
show slave status\G

如果中间产生问题,和之前处理GTID复制出错一样, 跳过执行的部分 即可(注意,需要知道自己跳过的是什么,小数据量若出现无法正常复制建议重建从库):
mysql> stop slave;
mysql> reset master;
mysql> set @@global.gtid_purged='22302bb1-c8bb-11e9-8669-00505620a3cf:1-308';
mysql> change master to master_host='192.168.20.102',master_user='rpl',master_password='123456',master_port=3306,master_auto_position=1;
mysql> start slave;
MHA进程恢复
在发生切换后,MHA默认会退出进程,需要配置后再次启动
- 在从库[原挂掉的主库]配置上去后,修改MHA配置文件
# MHA 104上操作
vi /etc/masterha/app1.conf
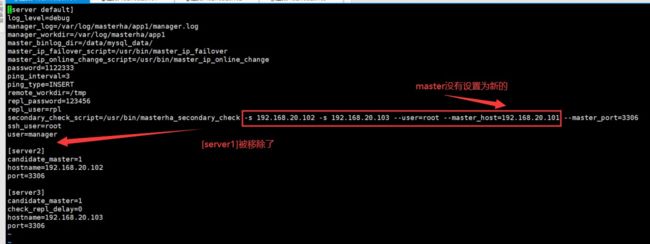
因为我们已经将原来的主库作为从库挂载上去了,而MySQL主机已更换,因此需要修改配置文件,假设主现在切换为 192.168.20.102 了,修改如下:
[server default]
log_level=debug
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1
master_binlog_dir=/data/mysql_data/
master_ip_failover_script=/usr/bin/master_ip_failover
master_ip_online_change_script=/usr/bin/master_ip_online_change
password=1122333
ping_interval=3
ping_type=INSERT
remote_workdir=/tmp
repl_password=123456
repl_user=rpl
### 这边需要配置为俩个从库地址-s 192.168.20.101 -s 192.168.20.10
### master_host 需要更改为新主地址
secondary_check_script=/usr/bin/masterha_secondary_check -s 192.168.20.101 -s 192.168.20.103 --user=root --master_host=192.168.20.102 --master_port=3306
ssh_user=root
user=manager
### 添加 [server1]
[server1]
candidate_master=1
hostname=192.168.20.101
port=3306
[server2]
candidate_master=1
hostname=192.168.20.102
port=3306
[server3]
candidate_master=1
check_repl_delay=0
hostname=192.168.20.103
port=3306
- MHA配置健康监测
masterha_check_ssh --conf=/etc/masterha/app1.conf
masterha_check_repl --conf=/etc/masterha/app1.conf
- 启动MHA
nohup masterha_manager --conf=/etc/masterha/app1.conf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
- 查看状态
masterha_check_status --conf=/etc/masterha/app1.conf
自动恢复MHA配置与自动挂载已挂从库
有个奇葩需求,客户那边的机器会被插拔网线,又需要保证高可用,而MHA特性是切换完成即退出监控进程。
- MHA配置文件修改,若切换了则启动修改为双机切换
- 修复被踢出的原主
- 比对GTID,挂载原主为从库
- 原主GTID = 新主 GTID ,直接原主change过去
- 原主GTID > 新主 GTID 记录,修正原主GTID后挂载过去
- 修改MHA配置文件
- 检测SSH状态
- 检测主从状态
- 启动MHA进程