Java牛客网社区项目——知识点&面试题
Java牛客网社区项目——知识点&面试题
持续更新中(ง •̀_•́)ง
文章目录
- Java牛客网社区项目——知识点&面试题
-
- 请简要介绍一下你的项目?
- 什么是Spring框架?
- 对Spring IoC的理解
- 什么是DAO
- Spring中关于Bean的注解
- Spring MVC是什么,是怎样的工作流程
- DispatcherServlet处理流程?
- 拦截器的作用
- 什么是SSM框架?
- 怎么实现注册功能的?
- 什么是Interceptor,在项目的哪里使用到了Interceptor?
- 使用什么技术生成验证码?
- 如何检查登陆状态
- 如何实现敏感词过滤
- 什么是Ajax,应用在项目哪些地方?
- 什么是事务,事务的四大特性。
- 怎么利用Spring实现事务管理
- 是怎样实现统一捕获异常的?
- 是怎样实现统一记录日志的?
- 什么是Redis,Redis有哪些优点?
- Redis分布式集群架构
- 怎么往Spring框架中配置Redis,介绍常见的Redis操作
- 项目中Redis的作用
- 怎样存储的点赞/关注/缓存用户数据
- 什么是消息队列
- 消息队列作为信息传递的中间件,需要注意哪些问题?
- Java中的blockingqueue,可以提供线程间的消息队列
- 什么是Kafka,有哪些功能和应用场景?
- Kafka的基础架构
- Kafka的消息模型,以及常见术语
- 在项目哪里用到了Kafka?
- 什么是ElasticSearch,存储原理,功能,特点
- 项目中哪里使用到了ES,如何使用
- 项目中使用到了SpringSecurity在哪些地方?
- 怎样统计网站UA和DAU
- 什么是Quartz,特点,专业术语,项目应用
- 什么是Caffeine,如何缓存,项目应用
请简要介绍一下你的项目?
这个项目的整体结构来源于牛客网,主要使用了Springboot、Mybatis、MySQL、Redis、Kafka、等工具。主要实现了用户的注册、登录、发帖、点赞、系统通知、按热度排序、搜索等功能。另外引入了redis数据库来提升网站的整体性能,实现了用户凭证的存取、点赞关注的功能。基于 Kafka 实现了系统通知:当用户获得点赞、评论后得到通知。利用定时任务定期计算帖子的分数,并在页面上展现热帖排行榜。
什么是Spring框架?
有很多模块组成,利用这些模块可以方便开发工作。这些模块是:核心容器(spring core)/数据访问和集成(Spring JDBC)/Web(Spring Web/MVC)/AOP(Spring Aop)/消息模块/测试模块(Spring Test)等。
对Spring IoC的理解
IoC的意思是控制反转,是一种设计思想,把需要在程序中手动创建对象的控制权交给了Spring框架。IoC的载体是IoC容器,本质是一个工厂,数据结构上来看是一个Map,用来存放着各种对象。当我们创建一个对象时,只需要配置好配置文件/注解,而不用担心对象是怎么被创建出来的。
IoC的优点:降低耦合,对象被容器管理需要两份数据:你的对象定义 + 配置文件,对象间的关系体现在配置文件,不会直接产生耦合。
什么是DAO
data access object,存放数据库访问对象。
Spring中关于Bean的注解
四种常见Bean
@Controller @Repository @Service @Component一般来说Bean只会被容器初始化一次,@PostConstruct:初始化前调用 @PreDestroy:销毁之前
如何使用Bean
bean通过容器管理,不需要我们实例化,如果要使用某个bean,使用依赖注入 @Autowired
Spring MVC是什么,是怎样的工作流程
服务器分为表现层/业务层/数据层,其中Spring MVC是工作在表现层,作用是接收/解析用户发送的请求,调用对应的业务类,根据业务类返回的结果(ModelAndView),调用view进行视图渲染,并将渲染后的View返回给请求者。具体分为以下8步。
- 客户端(浏览器)发送请求给前端处理器(DispatcherServlet)(发送请求,响应结果);
- DispatcherServlet根据请求信息调用HandlerMapping,查找到对应的Handler;
- 查找到对应的Handler(也就是Controller)后,由HandlerAdapter适配器处理;
- HandlerAdapter根据Handler来调用真正的Controller;
- Controller进行业务处理,返回ModelAndView对象,Model是数据对象,View是逻辑上的View;
- ViewResolver根据逻辑view找到实际view;
- DispatcherServlet把Model传给view进行视图渲染,然后返回给请求者。
C - Controller:控制器。接受用户请求,调用 Model 处理,然后选择合适的View给客户。
M - Model:模型。业务处理模型,接受Controller的调遣,处理业务,处理数据。
V - View:视图。返回给客户看的结果。
DispatcherServlet处理流程?
DispatcherServlet 处理流程:
在整个 Spring MVC 框架中,DispatcherServlet 处于核心位置,它负责协调和组织不同组件完成请求处理并返回响应工作。DispatcherServlet 是 SpringMVC统一的入口,所有的请求都通过它。DispatcherServlet 是前端控制器,配置在web.xml文件中,Servlet依自已定义的具体规则拦截匹配的请求,分发到目标Controller来处理。 初始化 DispatcherServlet时,该框架在web应用程序WEB-INF目录中寻找一个名为[servlet-名称]-servlet.xml的文件,并在那里定义相关的Beans,重写在全局中定义的任何Beans。在看DispatcherServlet 类之前,我们先来看一下请求处理的大致流程:
- Tomcat 启动,对 DispatcherServlet 进行实例化,然后调用它的 init() 方法进行初始化,在这个初始化过程中完成了:对 web.xml 中初始化参数的加载;建立 WebApplicationContext(SpringMVC的IOC容器);进行组件的初始化;
- 客户端发出请求,由 Tomcat 接收到这个请求,如果匹配 DispatcherServlet 在 web.xml中配置的映射路径,Tomcat 就将请求转交给 DispatcherServlet 处理;
- DispatcherServlet 从容器中取出所有 HandlerMapping 实例(每个实例对应一个 HandlerMapping接口的实现类)并遍历,每个 HandlerMapping 会根据请求信息,通过自己实现类中的方式去找到处理该请求的 Handler(执行程序,如Controller中的方法),并且将这个 Handler 与一堆 HandlerInterceptor (拦截器)封装成一个 HandlerExecutionChain 对象,一旦有一个 HandlerMapping 可以找到 Handler则退出循环;
- DispatcherServlet 取出 HandlerAdapter 组件,根据已经找到的 Handler,再从所有HandlerAdapter 中找到可以处理该 Handler 的 HandlerAdapter 对象;
- 执行 HandlerExecutionChain 中所有拦截器的 preHandler() 方法,然后再利用
HandlerAdapter 执行 Handler ,执行完成得到 ModelAndView,再依次调用拦截器的
postHandler() 方法; - 利用 ViewResolver 将 ModelAndView 或是 Exception(可解析成 ModelAndView)解析成View,然后 View 会调用 render() 方法再根据 ModelAndView 中的数据渲染出页面;
- 最后再依次调用拦截器的 afterCompletion() 方法,这一次请求就结束了。
拦截器的作用
目的:让未登录用户不能访问某些页面
原理:在方法前标注自定义注解,拦截所有的请求,只处理带有该注解的方法。
什么是SSM框架?
包括Spring + Spring MVC(和Spring天生集成) + MyBatis(帮你和数据库打交道的框架,简单的设置,你就可以像Java一样,操作数据库了)
怎么实现注册功能的?
根据请求来拆解功能
1,打开注册网页
2,把注册的信息发送给服务器(点注册)
3,把激活邮件发送给邮箱
4,利用激活链接打开网页
每一次请求都是先开发数据访问层,在开发业务层,最后开发视图层(三层架构),但是每一次请求不一定要用到这三层
什么是Interceptor,在项目的哪里使用到了Interceptor?
Interceptor是SpringMVC的处理器(handler)拦截器,用于对处理器进行预处理和后处理。本项目中,每次请求都会检查request中的login_ticket,把找到的user信息存放在协程中,并在完成处理后,自动释放。(方便的进行用户信息取用)
使用什么技术生成验证码?
使用Kaptcha包,可随机生成字符和图片。
如何检查登陆状态
加拦截器注解。
如何实现敏感词过滤
使用前缀树(字典树)存储敏感词,对text中的敏感词实现替换。
什么是Ajax,应用在项目哪些地方?
ajax指异步的json和xml技术,不是一门新的语言,而是使用现有技术的新方法。最大的特点是:不重新加载整个页面的基础上,可以与服务器交换数据,并更新部分网页数据。
项目中:帖子发布成功/失败的提示,使用到ajax
什么是事务,事务的四大特性。
定义:事务是逻辑上的一组操作,要么都执行,要么都不执行。
事物的四大特性-ACID:
A:原子性,事务是最小的执行单位,不允许被分割,事务的全部操作要么全部提交成功,要么全部失败回滚。
C:一致性,数据库在事务执行前后保持一致性状态,在一致性状态下,所有事务对同一个数据的读取结果相同。
I :隔离性,一个事务所作的修改在最终提交前,对其他事务是不可见的。避免多个事物交叉执行所导致的数据不一致问题。
D(Duability):持久性,一旦事务提交,所做的修改将被永远保存到数据库中。即使系统发生崩溃,事务执行的结构也不能丢失。
怎么利用Spring实现事务管理
Spring管理事务忽略了底层数据库的结构,非常方便。有两种方式:注解(类型,传播方式)/编程式事务(override)。
是怎样实现统一捕获异常的?
在SpringBoot的项目某一路径下,加上对应的错误页面,发生错误时自动会跳转。服务器的三层结构中,错误会层层向上传递,所以只需要在表现层(controller)统一处理错误即可。
方法:在controller中加上advice包,并通过注解@ControllerAdvice和@ExceptionHandler,统一捕获异常。
是怎样实现统一记录日志的?
使用了AOP技术(面向切面编程),这里使用到的是SpringAOP。 AOP技术能够将哪些与业务,但是为业务模块共同调用的逻辑或责任(比如事务处理,日志记录,权限控制等),封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的扩展性和维护性。 SpringAOP本质上基于动态代理,当要代理的对象实现了某接口,会使用JDK动态代理,在运行时通过创建接口的代理实例,织入代码。当要代理的对象没有实现接口,则使用Cglib技术(编译时增强),通过子类代理织入代码。
什么是Redis,Redis有哪些优点?
概念:redis是一个非关系型数据库,数据存储在内存中,读写速度快。可以存储键和五种不同类型值的映射。只能以字符串为键,值支持:字符串,列表,无序集合,有序集合,hash散列表。
优点:由于数据存储在内存中,读写速度非常快,满足高性能,高并发的系统要求。与Java原生的map/guava相比,支持分布式缓存。与memcached相比,支持更丰富的数据类型,且支持数据持久化。
Redis分布式集群架构
典型的分片+复制
怎么往Spring框架中配置Redis,介绍常见的Redis操作
如何配置:
1,导入jar包
2,配置端口,以及配置类redisTemplate(注入连接工厂/设置序列化方式(json))
常见操作
Value类型:redisTemplate.opsForValue().set(redisKey, 1),redisTemplate.opsForValue().get(redisKey), redisTemplate.opsForValue().increment(redisKey),
Hash类型:redisTemplate.opsForHash().put(redisKey, “id”, 1), 还有get等操作
List类型:redisTemplate.opsForList().leftPush(redisKey, 101), 还有size, index, range, leftPop等操作
Set类型:add, size, pop, members等操作
Zset类型:redisTemplate.opsForZSet().add(redisKey, “Linda”, 92), 有socre,rank,reverseRank, range等操作
操作key:可以delete,以及设置过期时间
同时支持绑定操作,支持事务(编程式事务,在事务中一般不包含查询)
为什么不包含查询:redis事务就是一系列命令的批量操作,批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到。
项目中Redis的作用
1、事务操作:redisTemplate直接调用opfor…来操作redis数据库,每执行一条命令是要重新拿一个连接,因此很耗资源,让一个连接直接执行多条语句的方法就是使用SessionCallback,同样作用的还有RedisCallback,但不常用。
2、使用redis存储验证码:
- 因为验证码需要频繁的进行访问与刷新,因此对性能的要求较高;
- 验证码不需要永久保存,通常在很短的时间后就会失效;
- 分布式部署的时候,存在session共享的问题。
3、使用redis存储登录凭证:
因为后台在每次处理请求的时候都要查询用户的登录凭证,访问的频率非常高,因此需要使用redis存储。
4、使用redis缓存用户信息:
因为后台在每次处理请求的时候都要根据用户的凭证用户信息,访问的频率非常高。
5、Redis可以使用zset对需要排序的数据进行自定义的排序。
怎样存储的点赞/关注/缓存用户数据
点赞使用set类型存储,key为点赞对象,set中保存点赞人的ID
关注使用zSet类型存储,key为被关注者,set保存关注者以及关注时间为score
缓存用户数据使用Value类型,key为用userID得到的key,value为user对象(设置过期时间,且数据修改时需要清除缓存)
什么是消息队列
消息队列是一个存放消息的容器,生产者把消息放在队列中,消费者从消息队列中取出数据。消息队列的主要功能(优点)在于:
- 解耦:生产者只负责把消息放在队列中,而不用关心谁去使用它。
- 异步:生产者把消息放在队列中后即可返回,而不用一个个的通知消费者去执行,消费者是异步的获取消息的。
- 限流:生产者一次性产生大量的数据时,不会给消费者造成压力,消费者可以根据自身的能力,去消息队列中取数据。
消息队列作为信息传递的中间件,需要注意哪些问题?
1、高可用:因为消息队列如果宕机,会导致整个系统不可用。(分布式/集群的现成支持)
2、数据持久化:防止数据丢失
3、如何取数据:消息队列主动通知或者消费者轮询。
Java中的blockingqueue,可以提供线程间的消息队列
BQ也是生产者与消费者模式,属于点对点式消息队列?(一个消息只会被消费一次)Blocking Queue构建了一个桥梁,能够解决生产速度/消费速度不匹配问题。阻塞的时候只是在那里等着,但是不会占用CPU资源,对性能不会有影响。
什么是Kafka,有哪些功能和应用场景?
Kafka为分布式流处理平台。流处理是指对不断产生的动态数据流实时处理,基于分布式内存,具有数据处理快速,高效,低延迟的特性。
Kafka简介:Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景
特点:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka主要提供的功能包括:消息系统,日志收集,用户行为跟踪,流式数据处理。
Kafka的基础架构
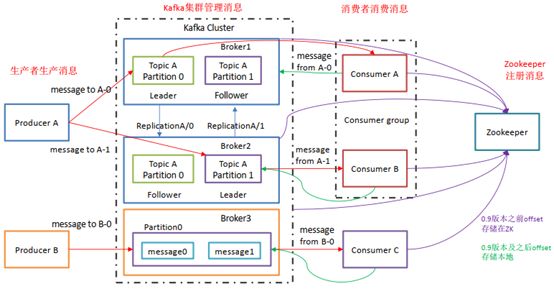
Producer:消息生产者,向Kafka中发布消息的角色。
Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
Kafka的消息模型,以及常见术语
消息模型:发布-订阅模型,消费者订阅了某一主题(topic)后,生产者采用类似广播的方式,将消息通过主题传递给所有的订阅者。
Topic:主题,类似于文件夹,用来存放不同的数据。
Partition:主题分区,同一主题的不同分区可以存放在不同的Broker上面,保证并发能力和负载均衡。
Offset:消息在Partition中的存放位置。
Broker:可以理解为kafka集群里面的一台或多台服务器,它本身是没有复制的,上面可能运行着topic1的leader, topic2的follower等等。
在项目哪里用到了Kafka?
当有点赞,评论,关注请求时,会发送系统通知点赞,评论,关注的对象。在处理系统信息时,使用到了Kafka,具体来说,先定义了生产者类和消费者类,其中生产者被点赞/评论/关注功能对应的Controller使用,产生消息。而消费者负责消息(message)到来时,把消息存到数据库内。
什么是ElasticSearch,存储原理,功能,特点
概念:ES是一个基于lucene构建的,分布式的,RESTful的开源全文搜索引擎。
存储原理:数据按照Index – Type – Document – 字段四级存储,其中Index对应数据库,Type对应表,Document为搜索的原子单位,包含一个或多个容器,基于JSON表示。字段是指JSON中的每一项组成,类似于数据库中的行/列。Mapping是文档分析过滤后的结果,根据用户自定义,将某些文字过滤掉,类似于表结构定义DDL??。同时ES也和分布式数据库一样,支持shard的replication。
功能:
1、分布式的搜索引擎和数据分析引擎
2、全文检索,结构化检索,数据分析。
3、对海量数据进行近实时的处理
特点:
1、可以作为分布式集群处理PB级别的数据,也可单机使用。
2、不是特有技术,而是将分布式+全文搜索(lucene) + 数据分析合并在一起。
3、操作简单,作为传统数据库的补充,提供了数据库所不具备的很多功能。
项目中哪里使用到了ES,如何使用
在进行帖子搜索时,使用到了ES。可用Repository和Template两种方式,由于Repository搜索到的结果(直接返回的post类,方便)没有高亮标签(why),所以使用了template方式重写了mapResults函数,获得了带有高亮标签的post。
使用消息队列(kafka)的方式,实现发帖/删帖后ES数据库的自动更新。
搜索:定义SearchQuery,确定搜素内容,排序方式,高亮等。接着使用elasticTemplate.queryForPage方法,需要重写mapResults函数,得到高亮数据。
项目中使用到了SpringSecurity在哪些地方?
重构了用户权限控制(之前用的拦截器)
怎样统计网站UA和DAU
使用Redis的高级数据结构:
HyperLogLog:超级日志,统计独立整数个数。统计UA(独立访问)时,以日期为 rediskey ,将客户端IP add 到HyperLogLog中(redisTemplate.opsForHyperLogLog().add(redisKey, i);)
Bitmap:位图,比如365天的签到,只需要365/8个字节的大小。统计DAU(日活跃用户)时,以日期为 rediskey ,以用户ID作为位(在数据中的位置),用 or 操作,既可以方便的统计一段时间内的注册用户访问人数。
什么是Quartz,特点,专业术语,项目应用
概念:quartz是一个开源项目,完全基于java实现。是一个优秀的开源调度框架。
特点:
1,强大的调度功能,例如支持丰富多样的调度方法
2,灵活的应用方式,例如支持任务和调度的多种组合方式
3,分布式和集群能力
专业术语:
scheduler:任务调度器 , scheduler是一个计划调度器容器,容器里面有众多的JobDetail和trigger,当容器启动后,里面的每个JobDetail都会根据trigger按部就班自动去执行
trigger:触发器,用于定义任务调度时间规则
job:任务,即被调度的任务, 主要有两种类型的 job:无状态的(stateless)和有状态的(stateful)。一个 job 可以被多个 trigger 关联,但是一个 trigger 只能关联一个 job
misfire:本来应该被执行但实际没有被执行的任务调度
项目应用:定时的统计帖子分数(如何设置定时任务和trigger)
什么是Caffeine,如何缓存,项目应用
概念:Caffeine 是一个基于Java 8的高性能本地缓存框架
初始化cache:缓存保存的对象,使用Caffeine.newBuilder()创建,创建时设置缓存大小,过期时间,缓存未命中时的加载方式。
为什么只缓存热度帖子?答:因为不会经常变。
` 参考文献 `
- https://blog.csdn.net/mosthandsomeboy/article/details/110070906
- 感谢牛哥马哥乐哥赛哥华哥指导~