HashMap的扩容机制:JDK1.7,JDK1.8 - cosmos_lee - CSDN博客
HashMap的扩容机制:JDK1.7,JDK1.8
参考文章:
http://www.importnew.com/20386.html
https://blog.csdn.net/z69183787/article/details/64920074?locationNum=15&fps=1
以前看HashMap的时候,resize扩容部分没有仔细看,今天挤出时间,看之。
1. 确定hash桶数组的索引位置
我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表,大大优化了查询的效率。HashMap定位数组索引位置,直接决定了hash方法的离散性能。先看看源码的实现(方法一+方法二):
方法一:
staticfinalinthash(Object key){//jdk1.8 & jdk1.7
inth;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return(key ==null) ?0: (h = key.hashCode()) ^ (h >>>16);
}
方法二:
staticintindexFor(inth,intlength){//jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
returnh & (length-1);//第三步 取模运算
}
这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
第一步:显而易见,直接取就是了。
第二步:在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
第三步:不是 直接的取模运算,由于length为2的幂次,所以可以使用“与”运算 h & (length-1)代替取模运算。这样速度更快。
2. resize()方法
voidresize(intnewCapacity){
Entry[] oldTable = table;
intoldCapacity = oldTable.length;
if(oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable =newEntry[newCapacity];
booleanoldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
booleanrehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);//transfer函数的调用
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY +1);
}
其实就是新建一个 newCapacity大小的数组,然后调用transfer()方法将元素复制进去。
voidtransfer(Entry[] newTable,booleanrehash){
intnewCapacity = newTable.length;
for(Entry e : table) {//这里才是问题出现的关键..
while(null!= e) {
Entry next = e.next;//寻找到下一个节点..
if(rehash) {
e.hash =null== e.key ?0: hash(e.key);
}
inti = indexFor(e.hash, newCapacity);//重新获取hashcode
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
来看看JDK1.7的trantransfer方法吧,可以看到其中是一些指针的操作,首先将 当前节点e的next节点保存下来,然后找到在新数组中的 下标 index, 使用头插法插入节点, 然后 接着处理 next 节点。
这里有两个重要的地方:
1. JDK1.8 当中 是如何找到新的数组中的下标的。
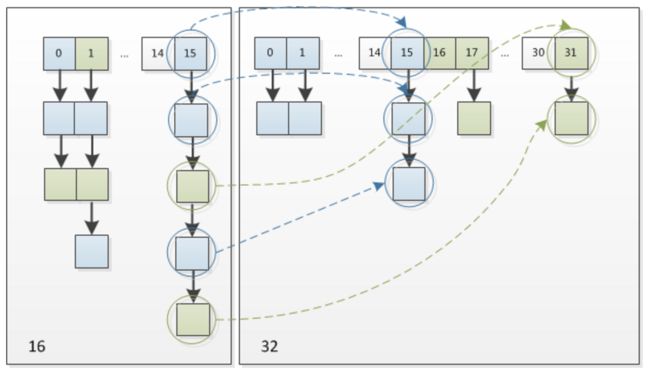
图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。

可以看到, 此key 要么在原先的index上, 要么在 index+old_length 上,old_length为扩容前数组的长度。
这样做的好处:增加随机性了,hashmap性能更好了。 效率更高了,不需要重新计算了。
2. 在JDK1.7中这样使用头插法在多线程的场景下是会出问题的,会形成一个环。
具体就是 线程a 一个节点插入完成后,还没有执行 e = next ,线程 b 执行 next = e.next , 线程a此时执行 e = next,此时就变成刚刚插入节点的下一个节点了,然后调用 e.next = newTable[i] , 这样第二个线程就会变成一个死循环了。

3.JDK1.8中的改变
JDK1.8中不采用头插法了,也就不存在出现环的情况了,具体可以见下图。