- 语法
- 多字段查询的类型
2.1 best_fields
2.2 most_fields
2.3 phrase和phrase_prefix
2.4 cross_fields
-- 2.4.1 字段解析器
-- 2.4.2 按字段提高权重 - 关键属性
3.1 lenient的作用 - 附录
4.1 附录1 - 推荐阅读
multi_match查询基于匹配查询且允许多字段查询
1. 语法
multi_match查询基于匹配查询且允许多字段查询构建的:
GET /_search
{
"query": {
"multi_match" : {
"query": "this is a test", (1)
"fields": [ "subject", "message" ] (2)
}
}
}
(1)要查询的字符串
(2)要查询的字段
fields中的每个字段都可以使用通配符来指定,比如:
GET /_search
{
"query": {
"multi_match" : {
"query": "Will Smith",
"fields": [ "title", "*_name" ] (1)
}
}
}
(1)查询title、first_name、last_name字段。
可以使用插入符号(^)表示增强某个字段的score,例如:
GET /_search
{
"query": {
"multi_match" : {
"query" : "this is a test",
"fields" : [ "subject^3", "message" ] (1)
}
}
}
(1)subject字段的score是message字段score的三倍。
2. 多字段查询的类型
| type | 含义 |
|---|---|
| best_fields | (默认)查找与任何字段匹配的文档,使用最佳字段的权重 |
| most_fields | 查找与任何字段匹配的文档,并组合每个字段的权重 |
| cross_fields | 使用相同的分析仪处理字段,就像它们是一个大字段。 在任何字段中查找每个字词 |
| phrase | 对每个字段运行match_phrase查询,并合并每个字段的权重 |
| phrase_prefix | 对每个字段运行match_phrase_prefix查询,并合并每个字段的权重 |
2.1 best_fields
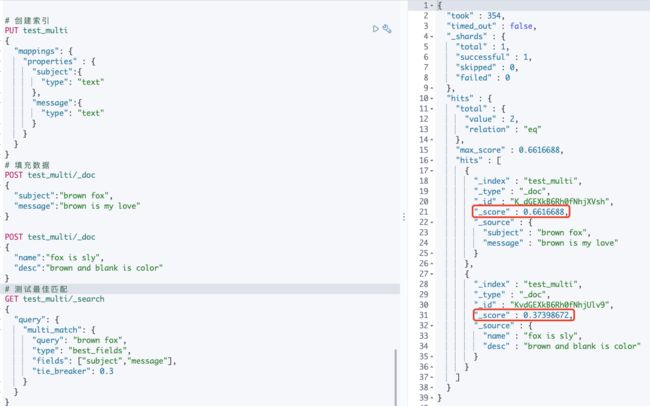
best_fields类型是非常有用的,当您搜索在同一字段中要找多个字词时。 例如,单个字段中的“brown fox”比一个字段中的“ brown”和另一个字段中的“fox”更有意义。
best_fields类型会为每个字段生成一个match查询,并将它们包装在dis_max查询中,以找到最匹配的字段。
通常,best_fields类型使用单个最佳匹配字段的分数,但如果tie_breaker指定了该分数,则按照以下方式计算score:单个最佳匹配字段的分数+(tie_breaker*其他所有匹配字段的score)
GET /_search
{
"query": {
"multi_match" : {
"query": "brown fox",
"type": "best_fields",
"fields": [ "subject", "message" ],
"tie_breaker": 0.3
}
}
}
可以被替换为:
GET /_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "subject": "brown fox" }},
{ "match": { "message": "brown fox" }}
],
"tie_breaker": 0.3
}
}
}
测试代码:见附录1
此外,可接收analyzer,boost,operator,minimum_should_match,fuzziness,lenient, prefix_length,max_expansions,fuzzy_rewrite, zero_terms_query,cutoff_frequency, auto_generate_synonyms_phrase_query and fuzzy_transpositions参数。
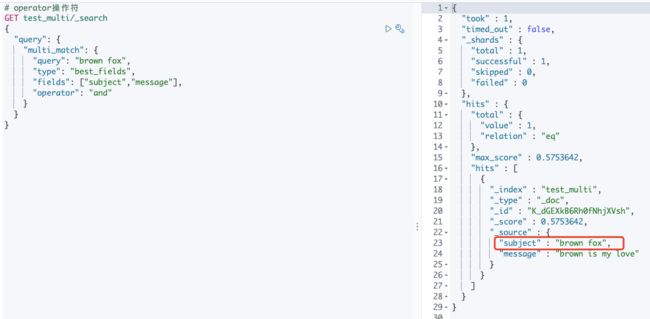
operator以及minimum_should_match
对于best_fields和most_fields类型是以字段为中心的—它们会为每一个字段生成一个匹配查询。这意味着operator以及minimum_should_match分别应用于每个字段,最终的结果不是想得到的。
GET /_search
{
"query": {
"multi_match" : {
"query": "Will Smith",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and" (1)
}
}
}
这个查询意味着:Will Smith两个字段必须同时出现在first_name字段或者last_name字段中。
2.2 most_fields
当以不同方式查询相同文本的多个字段时,most_fields类型最有用。
语法如下:
GET /_search
{
"query": {
"multi_match" : {
"query": "quick brown fox",
"type": "most_fields",
"fields": [ "title", "title.original", "title.shingles" ]
}
}
}
等价于
GET /_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "quick brown fox" }},
{ "match": { "title.original": "quick brown fox" }},
{ "match": { "title.shingles": "quick brown fox" }}
]
}
}
}
每个匹配子句的_score加在一起,然后除以匹配子句的数量。
此外,和match相同,可以接收analyzer,boost,operator,minimum_should_match,fuzziness,lenient,prefix_length,max_expansions,rewrite,zero_terms_query和cutoff_frequency
2.3 phrase和phrase_prefix
phrase和phrase_prefix类型的行为为best_fields类型,但是它们使用match_phrase或match_phrase_prefix查询,而不是匹配查询。
GET /_search
{
"query": {
"multi_match" : {
"query": "quick brown f",
"type": "phrase_prefix",
"fields": [ "subject", "message" ]
}
}
}
等效于
GET /_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase_prefix": { "subject": "quick brown f" }},
{ "match_phrase_prefix": { "message": "quick brown f" }}
]
}
}
}
此外,和match相同,可以接收analyzer,boost,operator,minimum_should_match,fuzziness,lenient,prefix_length,max_expansions,rewrite,zero_terms_query和cutoff_frequency
2.4 cross_fields
使用cross_fields类型进行multi_match查询。cross_fields使用词中心式(term-centric)的查询方式,这与best_fields和most_fields使用字段中心式(field-centric)的查询方式非常不同,它将所有字段当做一个大字段,并在每个字段中查找这个词。
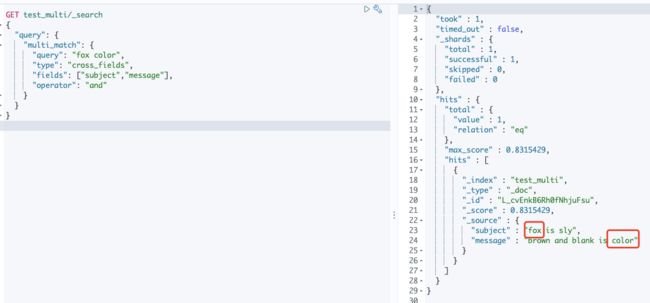
并且,cross_field通过混合不同字段逆向索引文档频率的方式解决了词频的问题:在多个字段中查找对应的词的IDF,然后以IDF最小值作为多个字段的IDF。
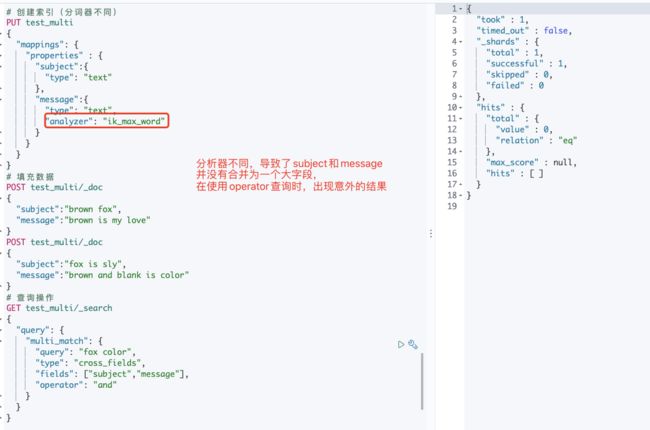
2.4.1 字段解析器
为了让 cross_fields 查询以最优方式工作,所有的字段都须使用相同的分析器,具有相同分析器的字段会被分组在一起作为混合字段使用。
如果包含不同分析器的字段,它们会以best_fields的相同方式被加入到查询结果中。当在使用 minimum_should_match 和 operator 参数时,这点尤为重要。
2.4.2 按字段提高权重
采用 cross_fields 查询与 自定义 _all 字段 相比,其中一个优势就是它可以在搜索时为单个字段提升权重。
可以使用前面介绍过的 ^ 符号语法来实现:
GET test_multi/_search
{
"query": {
"multi_match": {
"query": "fox color",
"type": "cross_fields",
"fields": ["subject^2","message"] (1)
}
}
}
(1)subject字段的权重提升值为 2 , message字段的权重提升值默认为 1 。
3. 关键属性
3.1 lenient的作用
elasticsearch multi_match的一个小坑
lenient默认值是 false , 表示用来在查询时如果数据类型不匹配且无法转换时会报错。如果设置成 true 会忽略错误。


4. 附录
4.1 附录1
# 创建索引
PUT test_multi
{
"mappings": {
"properties" : {
"subject":{
"type": "text"
},
"message":{
"type": "text"
}
}
}
}
# 填充数据
POST test_multi/_doc
{
"subject":"brown fox",
"message":"brown is my love"
}
POST test_multi/_doc
{
"subject":"fox is sly",
"message":"brown and blank is color"
}
5. 推荐阅读
elasticsearch7.x multi_match的官方文档
多字段匹配检索 multi_match query
cross-fields跨字段查询