本来想将macvlan和ipvlan放一起写,但是在测试过程中发现,ipvlan使用起来还是挺复杂的,于是单独作为一章来写。
ipvlan 和 macvlan 类似,都是从一个主机接口虚拟出多个虚拟网络接口。一个重要的区别就是所有的虚拟接口都有相同的 macv 地址,而拥有不同的 ip 地址。
ipvlan 有两种不同的模式:L2 和 L3。一个父接口只能选择一种模式,依附于它的所有虚拟接口都运行在这个模式下,不能混用模式。
L2 模式和 macvlan bridge 模式工作原理很相似,父接口作为交换机来转发子接口的数据。同一个网络的子接口可以通过父接口来转发数据,而如果想发送到其他网络,报文则会通过父接口的路由转发出去。
L3 模式下,ipvlan 有点像路由器的功能,它在各个虚拟网络和主机网络之间进行不同网络报文的路由转发工作。
为了更好的理解代码,在做代码分析之前,先按照场景看一下ipvlan的使用。
如下图:
两个主机: host1,host2
host1上:
Ns0~Ns3 是三个network namespace;
ipv0_0, ipv0_1 是在eth0上创建的两个ipvlan接口;
ipv1_0, ipv1_1, ipv1_2 是在eth1上创建的三个ipvlan接口;
ipv2_0, ipv2_1, 是在eth1上创建的两个ipvlan接口。
ipv0_0, ipv1_0, ipv2_0 在宿主机的namespace,其它的在相应的namespace中。
注意修改一下宿主接口的rp_filter配置为0或者2(场景二、三)
echo 0 > /proc/sys/net/ipv4/conf/eth0/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/eth1/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/eth2/rp_filter
场景一、ipvlan mode l2,ipv1_1, ipv1_2 互通

即同一宿主接口的两个ipvlan接口之间互通,2.1.1.1 ping 2.1.1.2,两个接口是同一网段,arp获取到对方的mac地址后,ipv1_1的驱动发送函数通过查找ip地址(2.1.1.2)所在的ipvlan接口为ipv1_2,直接走接口的接收流程。反向一样。
场景二、ipvlan mode l2,ipv1_1, Host1互通
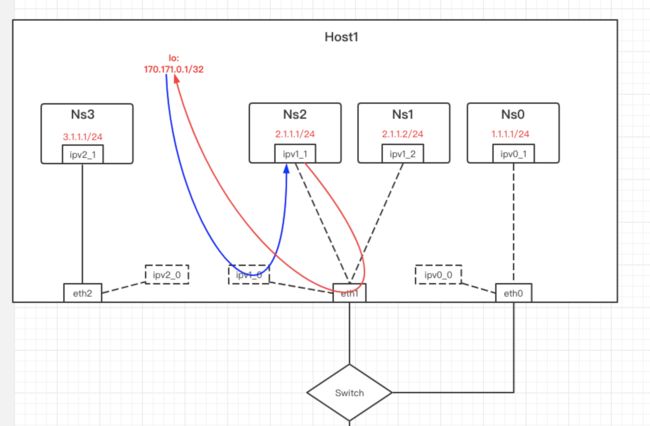
这种场景,即如何使用ipvlan 和宿主机互通,很常用的一个场景。
如图,我们从 Ns2 ping 宿主机,即2.1.1.1 ping 170.171.0.1,流量分红色的出方向和蓝色的入方向,走的是不同的路。
先贴配置,Ns2中的路由配置:
# ip route
default via 2.1.1.254 dev ipv2_1
宿主机的配置:
# ip addr
2: eth0: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:89:49:80 brd ff:ff:ff:ff:ff:ff
inet 1.1.1.254/24 scope global ens9
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe89:4980/64 scope link
valid_lft forever preferred_lft forever
3: eth1: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:4e:0a:de brd ff:ff:ff:ff:ff:ff
inet 2.1.1.254/24 scope global ens10
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe4e:ade/64 scope link
valid_lft forever preferred_lft forever
33: ipv0_0@ens9: mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 52:54:00:89:49:80 brd ff:ff:ff:ff:ff:ff
inet 192.168.114.1/32 scope host ipv1_0
valid_lft forever preferred_lft forever
inet6 fe80::5254:0:189:4980/64 scope link
valid_lft forever preferred_lft forever
39: ipv1_0@ens10: mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 52:54:00:4e:0a:de brd ff:ff:ff:ff:ff:ff
inet 192.168.114.1/32 scope host ipv2_0
valid_lft forever preferred_lft forever
inet6 fe80::5254:0:24e:ade/64 scope link
valid_lft forever preferred_lft forever
40: ipv2_0@ens15: mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 52:54:00:8f:77:cd brd ff:ff:ff:ff:ff:ff
inet 192.168.114.1/32 scope host ipv3_0
valid_lft forever preferred_lft forever
inet6 fe80::5254:0:28f:77cd/64 scope link
# ip route
1.1.1.1 dev ipv0_0 scope link
2.1.1.1 dev ipv1_0 scope link
2.1.1.2 dev ipv1_0 scope link
3.1.1.1 dev ipv2_0 scope link
# ip neigh
2.1.1.1 dev ipv1_0 lladdr 52:54:00:4e:0a:de
可以看到,Ns2中,路由的配置我们指定了nexthop为宿主接口的ip地址,而不是直接指向ipv1_1,两者的区别是前者arp请求网关ip所以会有数据报文dst mac==src mac的结果;而后者请求ping包的dst ip。
因为宿主机和Ns2不是一个广播域,出方向数据报文,目的ip不是eth1任何一个ipvlan接口的ip,且dst mac==src mac,数据报文需要通过宿主接口协议栈,查找路由表,找到170.171.0.1 为宿主机loopback口ip地址;而回来的包,是无法通过eth1进入的(进eth1就直接发到设备外),这需要通过宿主机中和ipv1_1同宿主的ipv1_0进入ipv1_1,我们配置了“2.1.1.1 dev ipv1_0 scope link”,在宿主机上通过三层将流量转发至ipv1_0,后面流程就入场景一一样,报文进入Ns2。
至于为什么配置了一个静态的arp表项,是因为 " who-has 2.1.1.1 tell 170.171.0.1" 的arp request进入可以通过ipv1_0进入eth1的ipvlan网络,但arp reply这个单播报文是无法通过ipv1_0出来的(arp的Target IP address不属于任何ipvlan接口的ip),会被从eth1发出去。所以这里配置了静态arp,防止宿主机到2.1.1.1 的arp request。
场景三、ipvlan mode l2,ipv1_1, ipv2_1 互通

这种场景,即同一宿主机上,不同宿主接口的ipvlan接口间互通,。
如下图,2.1.1.1 ping 3.1.1.1,namespace中仍然配置指定下一跳ip为宿主接口ip地址的default路由。
# Ns2:
# ip route
default via 2.1.1.254 dev ipv1_1
宿主机配置路由和arp表项:
#ip route
2.1.1.1 dev ipv1_0 scope link
3.1.1.1 dev ipv2_0 scope link
#ip neigh
2.1.1.1 dev ipv1_0 lladdr 52:54:00:4e:0a:de PERMANENT
3.1.1.1 dev ipv2_0 lladdr 52:54:00:8f:77:cd PERMANENT
Ns2 中 2.1.1.1 ping 3.1.1.1流程:
1、走默认路由,从ipv1_1 发下一跳ip地址的arp request(target ip=2.1.1.254);
2、arp reply返回eth1 mac地址,封装 icmp 报文发送;
3、ipv1_1驱动发送函数,检查报文src mac == dst mac,又无法找到3.1.1.1 对应的ipvlan接口(同一宿主接口eth1),于是将报文送入eth1,走接收流程协议栈,查找宿主机namespace路由表,出接口为 ipv2_0;
4、这一跳,我们配置了静态arp,不会有arp广播报文,否者将在 ipv2_0 上发送 “who-has 3.1.1.1 tell 170.171.0.1”的arp request,同场景二,这个request的reply是收不到的。
5、 ipv2_0驱动发送函数,检查报文src mac == dst mac,并找到3.1.1.1 的ipvlan接口是ipv2_1,走ipv2_1接收流程,报文到达Ns3,完成。
6、回包路径完全一样。
场景四、ipvlan mode l2,ipv1_1, ipv0_1 互通

这种场景,即同一宿主机上,不同宿主接口的ipvlan接口间互通,。这一点区别是为了演示通过宿主接口转发,而不需要走宿主机转发。
如下图,2.1.1.1 ping 1.1.1.1,namespace中配置的default路由。
# Ns0:
# ip route
default dev ipv0_1 scope link
# Ns2:
# ip route
default dev ipv1_1 scope link
Ns0 中 1.1.1.1 ping 2.1.1.1流程:
1、走默认路由,从ipv0_1 发送target ip=2.1.1.1 的arp request,由于eth0 和 eth1是二层互通的,arp request会到达eth1,在到达Ns2的ipv1_1;
2、arp reply沿愿路径返回ipv1_1的 mac地址,封装 icmp 报文发送;
3、ipv0_1驱动发送函数,检查报文src mac != dst mac(不属于任何ipvlan接口),走eth0发送进入switch,转发至eth1,查找2.1.1.1 为eth1的ipvlan接口ipv1_1的ip地址,将报文送入ipv1_1;
4、应答报文的回程流程完全一样。
可以看到这个场景简单很多。
看一下相关代码
ipvlan接口发包流程
ipvlan_start_xmit--> ipvlan_queue_xmit,分为三种模式,l2、l3、l3s。
int ipvlan_queue_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct ipvl_dev *ipvlan = netdev_priv(dev);
struct ipvl_port *port = ipvlan_port_get_rcu_bh(ipvlan->phy_dev);
if (!port)
goto out;
if (unlikely(!pskb_may_pull(skb, sizeof(struct ethhdr))))
goto out;
switch(port->mode) {
case IPVLAN_MODE_L2:
return ipvlan_xmit_mode_l2(skb, dev);
case IPVLAN_MODE_L3:
case IPVLAN_MODE_L3S:
return ipvlan_xmit_mode_l3(skb, dev);
}
/* Should not reach here */
WARN_ONCE(true, "ipvlan_queue_xmit() called for mode = [%hx]\n",
port->mode);
out:
kfree_skb(skb);
return NET_XMIT_DROP;
}
l2 mode的发送处理,大致分为三种情况:
1、发往内部(宿主接口+其上创建的所有ipvlan接口,dmac==smac),且dst ip属于其它ipvlan接口。这种情况下可以查询到目的ipvlan接口,走他的ipvlan_rcv_frame接收报文。
2、发往内部(宿主接口+其上创建的所有ipvlan接口,dmac==smac),且dst ip不属于其它ipvlan接口。这种情况下可以查不到目的ipvlan接口,走宿主接口(物理口)的dev_forward_skb,基本走一遍非NAPI接收流程,在宿主接口的namespace中走协议栈,查路由表三层转发。
3、发往外部。调用dev_queue_xmit发往网络。
这里暂时不看广播和组播报文的处理。再提一下,什么情况下mac会不相等,一种情况,dip和sip不是同一网段,且dip的路由指向出方向ipvlan接口,而不是同网段的ip地址。如上面的测试场景4,我也是根据代码分支做的测试。
static int ipvlan_xmit_mode_l2(struct sk_buff *skb, struct net_device *dev)
{
const struct ipvl_dev *ipvlan = netdev_priv(dev);
struct ethhdr *eth = eth_hdr(skb);
struct ipvl_addr *addr;
void *lyr3h;
int addr_type;
/* 这里就是上面各个场景中经常提到的,判断报文的dmac==smac,以判断是否发往内部接口(宿主接口+其上创建的所有vlan接口)。
*/
if (ether_addr_equal(eth->h_dest, eth->h_source)) {
// 根据报文信息查询接收ipvlan接口,注意这里不止是ip报文,arp reply也会走到这里,其查询ip取的是arp报文的target ip address。
lyr3h = ipvlan_get_L3_hdr(skb, &addr_type);
if (lyr3h) {
addr = ipvlan_addr_lookup(ipvlan->port, lyr3h, addr_type, true);
if (addr)
// 如上情况1,发往内部且dst ip属于其它ipvlan接口,测试场景一走这里。
return ipvlan_rcv_frame(addr, &skb, true);
}
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
return NET_XMIT_DROP;
/* Packet definitely does not belong to any of the
* virtual devices, but the dest is local. So forward
* the skb for the main-dev. At the RX side we just return
* RX_PASS for it to be processed further on the stack.
*/
// 如上情况2,发往内部且dst ip不属于其它ipvlan接口。测试场景二、三走这里。
// skb->dev换成物理接口后走一遍协议栈。
return dev_forward_skb(ipvlan->phy_dev, skb);
} else if (is_multicast_ether_addr(eth->h_dest)) {
ipvlan_skb_crossing_ns(skb, NULL);
ipvlan_multicast_enqueue(ipvlan->port, skb);
return NET_XMIT_SUCCESS;
}
// 如上情况2,发往外部,测试场景四走这里。
ipvlan_skb_crossing_ns(skb, ipvlan->phy_dev);
return dev_queue_xmit(skb);
}
l3 mode的发送处理,这个模式把宿主接口当成一个路由器,完全不支持广播,这个模式下的接口也比l2模式下的ipvlan接口多了一个 NOARP属性,也不会发送广播报文。如果dip属于同宿主接口的一个ipvlan接口,转发给这个接口接收,否者,在宿主接口上查找路由,走ip协议栈的ip_local_out流程处理报文。
static int ipvlan_xmit_mode_l3(struct sk_buff *skb, struct net_device *dev)
{
const struct ipvl_dev *ipvlan = netdev_priv(dev);
void *lyr3h;
struct ipvl_addr *addr;
int addr_type;
// 这里直接根据三层头(dip或arp的target ip)查ipvlan接口,不会检查mac,也不会处理广播报文
lyr3h = ipvlan_get_L3_hdr(skb, &addr_type);
if (!lyr3h)
goto out;
addr = ipvlan_addr_lookup(ipvlan->port, lyr3h, addr_type, true);
if (addr)
// 存在对应的ipvlan接口,走接口的接收,送到ipvlan接口
return ipvlan_rcv_frame(addr, &skb, true);
out:
// 没找到ipvlan接口的情况,交给宿主口(物理口),走三层转发
ipvlan_skb_crossing_ns(skb, ipvlan->phy_dev);
return ipvlan_process_outbound(skb);
}
static int ipvlan_process_outbound(struct sk_buff *skb)
{
struct ethhdr *ethh = eth_hdr(skb);
int ret = NET_XMIT_DROP;
/* l3 mode是不处理广播报文的,接口是NOARP的,报文进入接口后的dmac和smac都是接口的mac地址 */
if (is_multicast_ether_addr(ethh->h_dest)) {
pr_warn_ratelimited("Dropped {multi|broad}cast of type= [%x]\n",
ntohs(skb->protocol));
kfree_skb(skb);
goto out;
}
/* The ipvlan is a pseudo-L2 device, so the packets that we receive
* will have L2; which need to discarded and processed further
* in the net-ns of the main-device.
*/
if (skb_mac_header_was_set(skb)) {
skb_pull(skb, sizeof(*ethh));
skb->mac_header = (typeof(skb->mac_header))~0U;
skb_reset_network_header(skb);
}
if (skb->protocol == htons(ETH_P_IPV6))
ret = ipvlan_process_v6_outbound(skb);
else if (skb->protocol == htons(ETH_P_IP))
ret = ipvlan_process_v4_outbound(skb);
else {
pr_warn_ratelimited("Dropped outbound packet type=%x\n",
ntohs(skb->protocol));
kfree_skb(skb);
}
out:
return ret;
}
static int ipvlan_process_v4_outbound(struct sk_buff *skb)
{
const struct iphdr *ip4h = ip_hdr(skb);
struct net_device *dev = skb->dev;
struct net *net = dev_net(dev);
struct rtable *rt;
int err, ret = NET_XMIT_DROP;
struct flowi4 fl4 = {
.flowi4_oif = dev->ifindex,
.flowi4_tos = RT_TOS(ip4h->tos),
.flowi4_flags = FLOWI_FLAG_ANYSRC,
.daddr = ip4h->daddr,
.saddr = ip4h->saddr,
};
// 查找路由表
rt = ip_route_output_flow(net, &fl4, NULL);
if (IS_ERR(rt))
goto err;
if (rt->rt_type != RTN_UNICAST && rt->rt_type != RTN_LOCAL) {
ip_rt_put(rt);
goto err;
}
skb_dst_set(skb, &rt->dst);
// 这里走的是local_out 流程的协议栈
err = ip_local_out(net, skb->sk, skb);
if (unlikely(net_xmit_eval(err)))
dev->stats.tx_errors++;
else
ret = NET_XMIT_SUCCESS;
goto out;
err:
dev->stats.tx_errors++;
kfree_skb(skb);
out:
return ret;
}

总结一下:
1、l3模式下,ipvlan接口是NOARP的,不会收发ARP报文。l2模式下,则会处理广播报文;
2、l3模式下,发送到外部的报文,只会走三层。二l2模式,如果dmac==smac,才会进入宿主物理接口走三层,否则将宿主物理接口当二层接口转发二层报文出设备;
3、l3模式下走三层时处理外部报文时,直接查路由,走三层转发。而l2模式下,会模拟宿主物理接口收包流程,走非NAPI的收包流程。
宿主物理口收包流程
还是分为l2,l3, l3s三种模式。
rx_handler_result_t ipvlan_handle_frame(struct sk_buff **pskb)
{
struct sk_buff *skb = *pskb;
struct ipvl_port *port = ipvlan_port_get_rcu(skb->dev);
if (!port)
return RX_HANDLER_PASS;
switch (port->mode) {
case IPVLAN_MODE_L2:
return ipvlan_handle_mode_l2(pskb, port);
case IPVLAN_MODE_L3:
return ipvlan_handle_mode_l3(pskb, port);
case IPVLAN_MODE_L3S:
return RX_HANDLER_PASS;
}
/* Should not reach here */
WARN_ONCE(true, "ipvlan_handle_frame() called for mode = [%hx]\n",
port->mode);
kfree_skb(skb);
return RX_HANDLER_CONSUMED;
}
l2模式下,根据三层头,查找ipvlan接口,找到,就走接口接收流程,送到接口处理。没有对应的ipvlan接口,返回RX_HANDLER_PASS,在__netif_receive_skb_core 函数中,会继续走三层协议栈处理。
static rx_handler_result_t ipvlan_handle_mode_l2(struct sk_buff **pskb,
struct ipvl_port *port)
{
struct sk_buff *skb = *pskb;
struct ethhdr *eth = eth_hdr(skb);
rx_handler_result_t ret = RX_HANDLER_PASS;
void *lyr3h;
int addr_type;
if (is_multicast_ether_addr(eth->h_dest)) {
if (ipvlan_external_frame(skb, port)) {
struct sk_buff *nskb = skb_clone(skb, GFP_ATOMIC);
if (nskb) {
ipvlan_skb_crossing_ns(nskb, NULL);
ipvlan_multicast_enqueue(port, nskb);
}
}
} else {
struct ipvl_addr *addr;
// 根据三层头,查找ipvlan接口
lyr3h = ipvlan_get_L3_hdr(skb, &addr_type);
if (!lyr3h)
return ret;
addr = ipvlan_addr_lookup(port, lyr3h, addr_type, true);
if (addr)
// 找到,就走接口接收流程,送到接口处理
ret = ipvlan_rcv_frame(addr, pskb, false);
}
// 没有对应的ipvlan接口,返回RX_HANDLER_PASS,在__netif_receive_skb_core 函数中,会继续走三层协议栈处理。
return ret;
}
l3模式,只是不处理广播和组播报文,其它的一样。
static rx_handler_result_t ipvlan_handle_mode_l3(struct sk_buff **pskb,
struct ipvl_port *port)
{
void *lyr3h;
int addr_type;
struct ipvl_addr *addr;
struct sk_buff *skb = *pskb;
rx_handler_result_t ret = RX_HANDLER_PASS;
lyr3h = ipvlan_get_L3_hdr(skb, &addr_type);
if (!lyr3h)
goto out;
addr = ipvlan_addr_lookup(port, lyr3h, addr_type, true);
if (addr)
ret = ipvlan_rcv_frame(addr, pskb, false);
out:
return ret;
}
这里再补充一个函数,ipvlan_rcv_handle,即找到ipvlan接口后,送入ipvlan接口的处理。
ipvlan子接口的发送流程和宿主物理接口的接收流程都会走到这个函数,前者传入的local标记为true,后者为false。
local==true,调用dev_forward_skb的处理,会走完整的ipvlan接口的接收流程,报文放入CPU SD结构队列,通过触发软中断,处理报文。返回结果是RX_HANDLER_CONSUMED,__netif_receive_skb_core结束处理。
local==false,直接返回RX_HANDLER_ANOTHER,__netif_receive_skb_core函数对这个结果的处理是再走一遍__netif_receive_skb_core函数。
其实这两个流程最终都是走__netif_receive_skb_core,处理大部分一样,最大的区别是是否再次入队列,通过软中断触发处理的问题。这其中应该有什么考虑,有大神明白的话,留言指教一下吧。
static int ipvlan_rcv_frame(struct ipvl_addr *addr, struct sk_buff **pskb,
bool local)
{
struct ipvl_dev *ipvlan = addr->master;
struct net_device *dev = ipvlan->dev;
unsigned int len;
rx_handler_result_t ret = RX_HANDLER_CONSUMED;
bool success = false;
struct sk_buff *skb = *pskb;
len = skb->len + ETH_HLEN;
/* Only packets exchanged between two local slaves need to have
* device-up check as well as skb-share check.
*/
if (local) {
if (unlikely(!(dev->flags & IFF_UP))) {
kfree_skb(skb);
goto out;
}
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
goto out;
*pskb = skb;
}
// 后面可能切换ns
ipvlan_skb_crossing_ns(skb, dev);
/*
local==true,是指ipvlan子接口的发送流程,dev_forward_skb的处理即走完整的ipvlan接口的接收流程,
通过软中断触发。返回结果是RX_HANDLER_CONSUMED,__netif_receive_skb_core结束处理。
local==false,是指宿主物理接口的接收流程。返回结果是RX_HANDLER_ANOTHER,再走一遍__netif_receive_skb_core函数。
*/
if (local) {
//
skb->pkt_type = PACKET_HOST;
if (dev_forward_skb(ipvlan->dev, skb) == NET_RX_SUCCESS)
success = true;
} else {
ret = RX_HANDLER_ANOTHER;
success = true;
}
out:
ipvlan_count_rx(ipvlan, len, success, false);
return ret;
}