TCGA学习01:数据下载与整理 -
TCGA学习02:差异分析 -
TCGA学习03:生存分析 -
TCGA学习04:建模预测-cox回归 -
TCGA学习04:建模预测-lasso回归 -
TCGA学习04:建模预测-随机森林&向量机 -
前言交代
1、学习参考
之前参加了生信技能树花花老师的TCGA数据挖掘试讲课,收获很多,最近整理一下上课笔记,同时参考了老师的相关教程。生信入门的朋友也可微信加入生信星球公众号,个人觉得很好的一个学习平台。一起来学习吧~
2、笔记内容
(1)在TCGA公共数据库,下载某一类癌症的某一种RNA的count数据,以及相应的病人临床信息;
(2)根据count数据进行差异分析,结合病人临床信息进行生存分析以及建模预测
课程还介绍有几点更深入的研究,就不记录了,可以参看老师的教程。
3、学习目标
TCGA的大致流程;R操作.....
第一步:数据下载与整理
1、下载
1.1 官网下载“脚本”文件
- (1)进入GDC官网的repository条目
https://portal.gdc.cancer.gov/repository -
(2)先在case选项中分别选择Primary Site(癌症位置)、Programme(选TCGA),还可以再选Project,我这里没选
出于小样本量考虑,选了testis的site,后来查了下原来是.......
 case
case -
(3)基于选择的case,在file选项中选择miRNAcount数据(因为小),注意改下名字,避免冲突,下同。
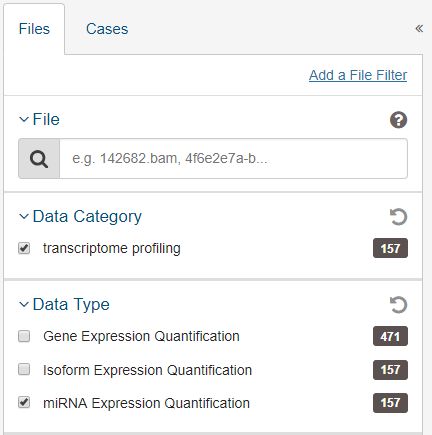 miRNA count数据
miRNA count数据 -
(4)基于选择的case,在file选项中选择病人临床信息数据,注意要是bcr xml格式
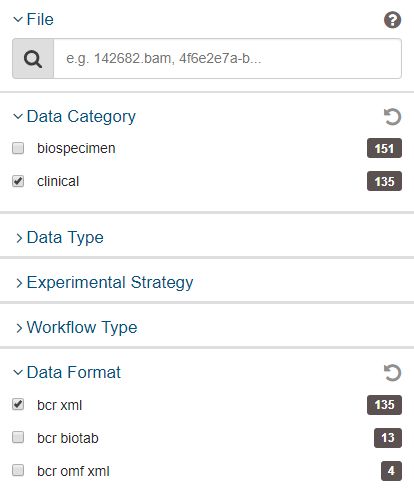 image.png
image.png
这里注意一下count矩阵信息有157个样本;临床信息则只有135份,对差异分析应该没影响;不知道会对后面生存分析等会不会有影响,存疑。
还有会注意到上面下载的两个文件只有几十KB大小,因为仅仅是类似下载“脚本”的文件,还需要利用GDC提供的程序下载到本地。
- (5)下载程序有不同系统版本,在
https://gdc.cancer.gov/access-data/gdc-data-transfer-tool选择适合自己系统的,一般window的R中提供的terminal终端使用window版本即可。下载代码如下:
mkdir mirna clinical
head gdc_manifest.2020-05-02.clinical.txt
./gdc-client download -m gdc_manifest.2020-05-02.mirna.txt -d mirna/
# -d表示储存路径
./gdc-client download -m gdc_manifest.2020-05-02.clinical.txt -d clinical/
# 切换到R
length(dir("./clinical/")) #统计子目录数
length(dir("./mirna/"))
- 以上两种数据文件就下载好了,但需要整理成我们想要的表达矩阵与临床信息的文件类型。
老师教程还提供了另外两种下载方式,基于R包实现的。但GDC下载还是比较常用的。
2、整理
2.1 整理临床信息
library(XML) #clinical临床信息为xml格式,我们目的转换成df
result <- xmlParse("./clinical/0f133012-23ef-4237-acfd-47b132b99775/nationwidechildrens.org_clinical.TCGA-W5-AA2Q.xml")
rootnode <- xmlRoot(result)
rootsize <- xmlSize(rootnode) #结果显示有两个节点
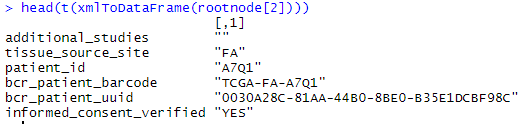
print(rootnode[2]) #病人信息在第二部分
xmldataframe <- xmlToDataFrame(rootnode[2]) #转换成df,发现是长长的一行
head(t(xmlToDataFrame(rootnode[2])))
xmls = dir("clinical/",pattern = "*.xml$",recursive = T)
#目的是取出所有的xml文件,pattern = "*.xml$"用正则表达式匹配;recursive = T表示递归模式。
head(xmls) #是带路径的

td = function(x){
result <- xmlParse(file.path("clinical/",x)) #补成全路径
rootnode <- xmlRoot(result)
xmldataframe <- xmlToDataFrame(rootnode[2])[c(
'bcr_patient_barcode',
'vital_status',
'days_to_death',
'days_to_last_followup',
'race_list',
'days_to_birth',
'gender' ,
'stage_event'
)]
return(t(xmldataframe)) #返回每个病人的信息df
} #编写小函数,批量处理
cl = lapply(xmls,td) # xmls即为td函数的x,lapply逐个处理,结果储存在cl列表中
do.call(cbind,cl)
cl_df <- t(do.call(cbind,cl)) #将所有病人信息合并
cl_df[1:3,1:3]
class(cl_df) #为矩阵
clinical = data.frame(cl_df)
rownames(clinical) <- stringr::str_to_upper(clinical$bcr_patient_barcode)
clinical <- clinical[,-1]
dim(clinical)
clinical[1:4,1:4]

2.2 整理表达矩阵
length(dir("./mirna/")) #157
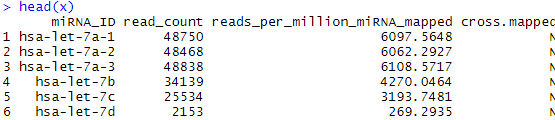
x = read.table("mirna/01b6ce76-61a8-4bc4-b0d7-f69d4ce187d6/3fa67c62-6856-42fe-a9f1-fa6831f42b53.mirbase21.mirnas.quantification.txt"
,header = TRUE)
head(x)
mis = dir("mirna/",pattern = "*tification.txt$",recursive = T)
mis
length(mis)
#同样先取名
ex = function(x){
result <- read.table(file.path("mirna/",x),sep = "\t",header = TRUE)[,1:2]
return(result)
}
#批量读取函数
mi = lapply(mis,ex) #结果是第一列为基因名,第二列为count数的两列数据
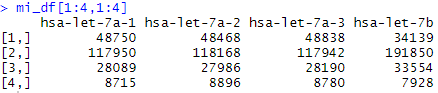
mi_df <- t(do.call(cbind,mi)) #合并并转置,因为45个病人所以90行
dim(mi_df)
tmp = mi_df[1:4,1:4]
tmp

colnames(mi_df) <- mi_df[1,] #添加列名
mi_df[1:4,1:5]
#奇数列(基因名)是重复多余的,只保留偶数列
mi_df <- mi_df[seq(2,nrow(mi_df),2),]
dim(mi_df)
mi_df[1:4,1:4]
#转为数值型
mi_df <- apply(mi_df, 2, as.numeric)
mi_df[1:4,1:4]
- 表达矩阵基本成形,但会发现致命的缺点--没有行名,即病人信息,目前只知道原始矩阵的文件名(见上
head(xmls)图),但不是我们需要的病人ID类型,因此还要回GDC网站下载相应的json文件,里面包含有名称对应关系。 -
下载方法(如下图):选择count或临床信息时,全选加入购物车,点击购物车,然后点击Metadata即可。这里因为是给表达矩阵加行名,所以选择count数据的157个样本到购物车。
 下载json文件
下载json文件
#接下来利用json文件给表达矩阵加上行名----
dim(mi_df)
meta <- jsonlite::fromJSON("metadata.cart.2020-05-02.157.json")
#观察到associated_entities列中每一格都是一个df,里面存放着病人的各种相关ID;
#其中entity_submitter_id即我们想要的,meta有157行,就对上了
meta$associated_entities[[1]]

entity <- meta$associated_entities
#取第四列,为列表,包含4个元素,每个元素为一个df
class(entity[157])
entity[[157]][4]
class(entity)
jh = function(x){
as.character(x[4])
} #取df中的entity_submitter_id,即我们最终想给矩阵加上的样本名
jh(entity[[1]])
ID = sapply(entity,jh) #取得了所有的病人ID
head(ID)

options(stringsAsFactors = F)
file2id = data.frame(file_name = meta$file_name,
#meta中file_name列即为我们下的mrna的文件名字
ID = ID)
#file2id表格157行2列,即储存着我们想要的文件名与ID的对应关系
head(mis) #mis文件是我们下载mrna的gz文件的递归路径,注意是有顺序的

#注意mis的样本顺序与之前表达矩阵样本顺序相同
mis2 = stringr::str_split(mis,"/",simplify = T)[,2] #取文件名
mis2[1] %in% file2id$file_name #序列匹配与否
#接下来就要把file2id列表按mis2排序,再把病人ID加到表达矩阵上
#match(A,B)
head(match(mis2,file2id$file_name))
#排序可以验证一下,match返回值的第一个是38,意思mis2的第一个元素是file2id$file_name的第38个元素。
mis2[1] == file2id$file_name[38]
row_tcga = file2id[match(mis2,file2id$file_name),]
#调整file2id行顺序以适应我们下载的miran数据
#如上match(mis2,file2id$file_name)第一个值为4;就把第四行放到第一行
rownames(mi_df) = row_tcga$ID #最后一步
#给mi_df添加行名
mi_df[1:4,1:4]

expr = t(mi_df)
dim(expr)
expr = expr[apply(expr, 1, function(x) {
sum(x > 1) > 9 #过滤掉低表达基因
}), ]
dim(expr)
group_list=ifelse(as.numeric(substr(colnames(expr),14,15)) < 10,'tumor','normal')
# 01转为tumor,大于10转为normal
table(group_list) #只有tumor样本
# group_list
# tumor
# 157
group_list <- factor(group_list,levels = c("normal","tumor")) #分组因子
- 为什么01转为tumor,大于10转为normal呢?参考癌症类型和样本代号详解TCGA一文中,Sample号从01-29的,其中01-09是tumor,也就是癌症样本;其中10-29是normal,也就是癌旁。
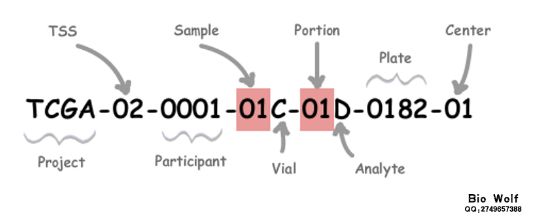 TCGA编号
TCGA编号 - 不过遗憾的是我尝试找的两个小样本癌中都是只有tumor样本(<10),就是说不能做差异分析了,就暂时先用花花老师的数据吧。
save(expr,clinical,group_list,file = "gdc.Rdata")
-
综上,我们一共得到三个文件,用于接下来的分析
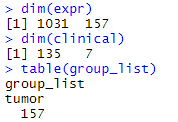 表达矩阵&样本信息&分组信息
表达矩阵&样本信息&分组信息 - 不足之处:(1)表达矩阵与样本信息数量不同;(2)表达矩阵全是tumor样本。