本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. 快速生成Flink项目
1.推荐开发工具
idea+maven+git
2.推荐开发语言
Java或者Scala
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/java_api_quickstart.html
3.Flink项目构建步骤
1)通过maven构建Flink项目
这里我们选择构建1.6.2版本的Flink项目,打开终端输入如下命令:
mvn archetype:generate-DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.6.2
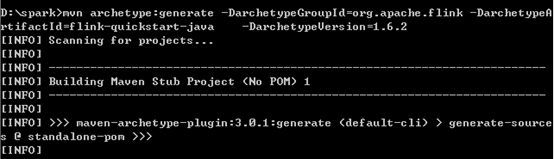
项目构建过程中需要输入groupId,artifactId,version和package

然后输入y确认
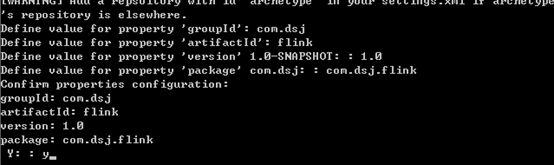
然后显示Maven项目构建成功
2)打开IDEA导入Flink 构建的maven项目
打开IDEA开发工具,点击open选项
选择刚刚创建的Flink项目
IDEA打开Flink项目
2. Flink Batch版WordCount
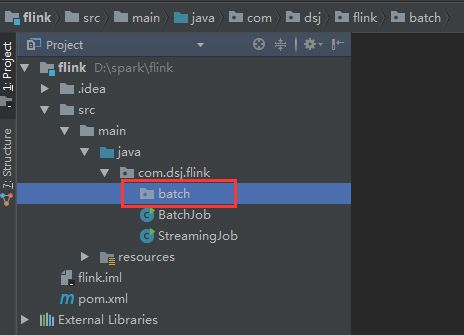
新建一个batch package
打开github Flink源码,将批处理WordCount代码copy到batch包下。
https://github.com/apache/flink/tree/master/flink-examples/flink-examples-batch/src/main/java/org/apache/flink/examples/java/wordcount

打开批处理WordCount代码:
package com.dsj.flink.batch;
import
org.apache.flink.api.common.functions.FlatMapFunction;
import
org.apache.flink.api.java.DataSet;
import
org.apache.flink.api.java.ExecutionEnvironment;
import
org.apache.flink.api.java.tuple.Tuple2;
import
org.apache.flink.api.java.utils.ParameterTool;
import
org.apache.flink.examples.java.wordcount.util.WordCountData;
import
org.apache.flink.util.Collector;
/**
*统计单词词频
*/public class WordCount {
public static void main(String[]
args) throws Exception {
//解析命令行传过来的参数
final ParameterToolparams = ParameterTool.fromArgs(args);
// 获取一个执行环境,本地或者集群环境会自动识别
final ExecutionEnvironmentenv = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// 读取输入数据
DataSet
if
(params.has("input")) {
// 读取text文件
text = env.readTextFile(params.get("input"));
} else{
// 读取默认测试数据集
System.out.println("Executing WordCount example with default input data
set.");
System.out.println("Use --input to specify file input.");
text = WordCountData.getDefaultTextLineDataSet(env);
}
DataSet
, Integer>> counts =
// 切分每行单词
text.flatMap(new Tokenizer())
//对每个单词分组统计词频数
.groupBy(0)
.sum(
1);
// 输出统计结果
if (params.has("output")) {
//数据输出为CSV格式
counts.writeAsCsv(params.get("output"), "\n", " ");
// 提交执行flink应用
env.execute("WordCount Example");
} else{
System.
out.println("Printing
result to stdout. Use --output to specify output path.");
//数据打印控制台,内部封装了execute提交flink应用
counts.print();
}
}
//*************************************************************************
// USER FUNCTIONS
// *************************************************************************
public static final class Tokenizer implementsFlatMapFunction
@Override
public void flatMap(String value, Collector
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (Stringtoken : tokens) {
if (token.length()
> 0) {
out.collect(
new Tuple2<>(token, 1));
}
}
}
}
}
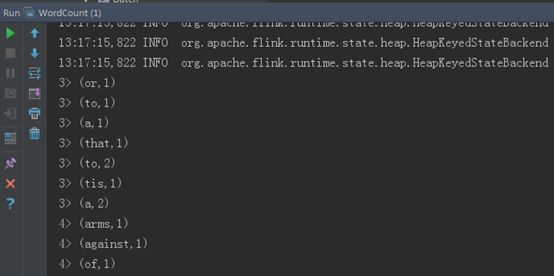
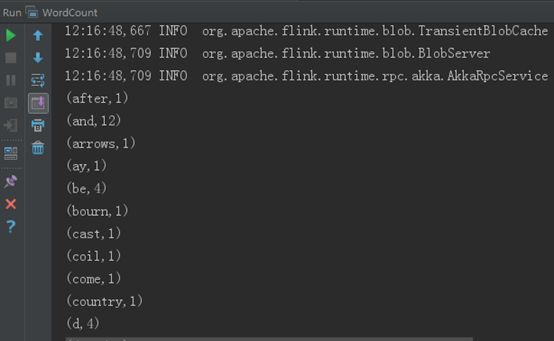
右键选择run,运行Flink批处理WordCount,运行结果如下所示:
3. Flink Stream版WordCount
同样,流处理我们也单独创建一个包stream
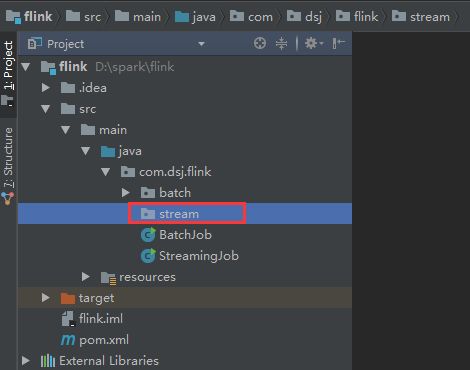
打开github Flink源码,将流处理WordCount代码copy到stream包下。
https://github.com/apache/flink/tree/master/flink-examples/flink-examples-streaming/src/main/java/org/apache/flink/streaming/examples/wordcount
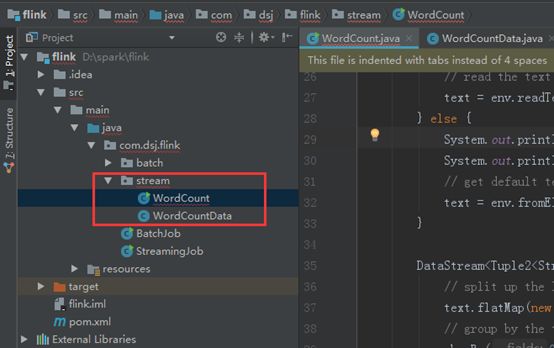
打开流处理WordCount代码:
package com.dsj.flink.stream;
import
org.apache.flink.api.common.functions.FlatMapFunction;
import
org.apache.flink.api.java.tuple.Tuple2;
import
org.apache.flink.api.java.utils.ParameterTool;
import
org.apache.flink.streaming.api.datastream.DataStream;
import
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import
org.apache.flink.util.Collector;
/**
*
统计单词词频
*/public class WordCount {
public static void main(String[] args) throws Exception {
//解析命令行传过来的参数
final ParameterTool params = ParameterTool.fromArgs(args);
// 获取一个执行环境,本地或者集群环境会自动识别
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// 读取输入数据
DataStream
if
(params.has("input")) {
// 读取text文件
text = env.readTextFile(params.get("input"));
} else {
System.
out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
// 读取默认测试数据集
text = env.fromElements(WordCountData.WORDS);
}
DataStream
, Integer>> counts =
// 切分每行单词
text.flatMap(new Tokenizer())
//对每个单词分组统计词频数
.keyBy(0).sum(1);
// 输出统计结果
if (params.has("output")) {
//写入文件地址
counts.writeAsText(params.get("output"));
} else {
System.
out.println("Printing result to stdout. Use --output to specify output path.");
//数据打印控制台
counts.print();
}
// 执行flink 程序
env.execute("Streaming WordCount");
}
public static final class Tokenizer implements FlatMapFunction
@Override
public void flatMap(String value, Collector
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(
new Tuple2<>(token, 1));
}
}
}
}
}
右键选择run,运行Flink流处理WordCount,运行结果如下所示: