2018年年初
论文地址:https://arxiv.org/pdf/1611.07709.pdf
要点
第一个提出了在物体分割中可以端到端训练的框架,是继 FCN 之后分割领域的又一个重要进展。
实例分割与语义分割不同。在一张图像中,待分割的物体个数是不定的,每个物体标记一个类别的话,这张图像的类别个数也是不定的,导致输出的通道个数也无法保持恒定,所以不能直接套用 FCN 的端到端训练框架。因此,一个直接的想法是,先得到每个物体的检测框,在每个检测框内,再去提取物体的分割结果。这样可以避免类别个数不定的问题。比如,在 faster rcnn 的框架中,提取 ROI 之后,对每个 ROI 区域多加一路物体分割的分支。这种方法虽然可行,但留有一个潜在的问题:label 的不稳定。想象一下有两个人(A,B)离得很近,以至于每个人的检测框都不得不包含一些另一个人的区域。当我们关注 A 时,B 被引入的部分会标记为背景;相反当我们关注 B 时,这部分会被标记为前景。为了解决上述问题,本文引用了一种 Instance-sensitive score maps 的方法(首先在 Instance-sensitive Fully Convolutional Networks 一文中被提出),简单却有效的实现了端到端的物体分割训练。
具体的作法是:将一个 object 的候选框分为 NxN 的格子,每个格子的 feature 来自不同通道的 feature map。
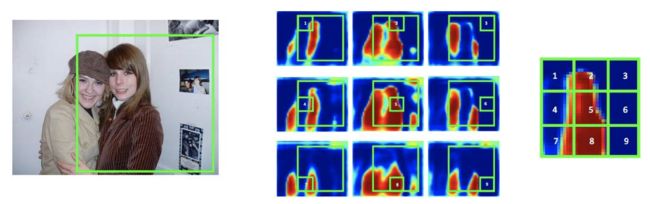
以上图为例,可以认为,将物体分割的输出分成了 9 个 channel,分别学习 object 的左上,上,右上,….. 右下等 9 个边界。这种改变将物体从一个整体打散成为 9 个部分,从而在任何一张 feature map 上,两个相邻的物体的 label 不再连在一起(feature map 1 代表物体的左上边界,可以看到两个人的左上边界并没有连在一起),因此,在每张 feature map 上,两人都是可区分的。
打个比喻,假设本来我们只有一个 person 类别,两个人如果肩并肩紧挨着站在一起,则无法区分彼此。如果我们划分了左手,右手,中心躯干等三个类别,用三张独立的 feature map 代表。那么在每张 feature map 上两个人都是可区分的。当我们需要判断某个候选框内有没有人时,只需要对应的去左手,右手,中心躯干的 feature map 上分别去对应的区域拼在一起,看能不能拼成一个完整的人体即可。
借用这个方法,本文提出了一个物体分割端到端训练的框架,如上图所示,使用 region proposal 网络提供物体分割的 ROI,对每个 ROI 区域,应用上述方法,得到物体分割的结果。
问题1:由于全连接层的输入要求,所有ROI区域都要被转化为相同的尺度,这对于不同尺度的目标(尤其是面积比较大的目标)来说,细节信息损失巨大。大家都知道,全连接层的本质是矩阵乘法,因此需要相同尺度的输入,才能和固定尺度的参数进行矩阵相乘得出结果。那么,所有目标区域(ROI)都要被放大或者缩小成一样的尺度(这个被称为ROI-Pooling技术被Fast R-CNN提出,该论文发表于ICCV 2015,值得一提的是这也是微软团队的工作)。那么,在前景与背景分离这个问题上面,对于面积大的目标区域,是将其缩小之后再进行分离,然后将得到的结果(Mask)放大到原来的尺度作为前景,这样对ROI区域的操作非常容易损失掉目标的细节信息(比如说,车子的轮子在缩小的过程中就没了,再放大之后也不会再有)。
对于问题1,论文做出了如下表述:
First, the ROI pooling step losses spatial details due to feature warping and resizing, which however, is necessary to obtain a fixed-size representation for fc layers. Such distortion and fixed-size representation degrades the segmentation accuracy, especially for large objects.
问题2:全连接层参数规模庞大,这种尾大不掉的架构很有可能发生过拟合。从笔者的caffemodel解析这一篇博文中提到了,将一个简单的LeNet模型的可训练参数提取出来,最后两个全连接的参数竟然达到了网络参数规模的90%以上。由于这个问题,训练与测试的代价也会增多。
对于问题2,论文做出了如下表述:
Second, the fc layers over-parametrize the task, without using regularization of local weight sharing.
问题3:在ROI区域提出后,图像分割的子任务与图像分类的子任务之间没有共享参数。大家从上图可以看到,在图标区域提出后,图像分割任务与图像分类任务都是各自训练不同的全连接层,这样使得架构的效率异常低下。
对于问题3,论文做出了如下表述:
Last, the per-ROI network computation in the last step is not shared among ROIs. As observed empirically, a considerably complex sub-network in the last step is necessary to obtain good accuracy. It is therefore slow for a large number of ROIs (typically hundreds or thousands of region proposals).
针对以上3个问题,我们来看看FCIS是怎么解决的。
首先针对问题1,ROI-Pooling被取消了,取而代之的是对ROI区域的聚合,实质就是复制粘贴。
然后针对问题2,全连接层(FC layer)被取消了,取而代之的是分类器(softmax)。
最后,针对问题3,图像分割与图像分类使用的是相同的特征图。
文章借鉴多篇网文,仅用于学习目的,侵权请联系
论文翻译

Abstract
We present the first fully convolutional end-to-end solution for instance-aware semantic segmentation task. It inherits all the merits of FCNs for semantic segmentation [29] and instance mask proposal [5]. It detects and segments the object instances jointly and simultanoulsy. By the introduction of position-senstive inside/outside score maps, the underlying convolutional representation is fully shared between the two sub-tasks, as well as between all regions of interest. The proposed network is highly integrated and achieves state-of-the-art performance in both accuracy and efficiency. It wins the COCO 2016 segmentation competition by a large margin. Code would be released at https: //github.com/daijifeng001/TA-FCN.
我们提出了第一个完全卷积的端到端解决方案,用于实例感知语义分段任务。它继承了FCN在语义分割[29]和实例掩码建议[5]的所有优点。它同时一起检测和分割对象。通过引入位置敏感内/外部评分图,两个子任务之间以及所有感兴趣的区域之间完全共享潜在的卷积表示形式。建议的网络高度集成,在准确性和效率方面实现了最先进的性能。它以较大优势赢得了 COCO 2016 分割比赛。代码将在 https 发布://github.com/daijifeng001/TA-FCN。
1. Introduction
Fully convolutional networks (FCNs) [29] have recently dominated the field of semantic image segmentation. An FCN takes an input image of arbitrary size, applies a series of convolutional layers, and produces per-pixel likelihood score maps for all semantic categories, as illustrated in Figure 1(a). Thanks to the simplicity, efficiency, and the local weight sharing property of convolution, FCNs provide an accurate, fast, and end-to-end solution for semantic segmentation.
完全卷积网络(FCN)[29]最近主导了语义图像分割领域。FCN 采用任意大小的输入图像,应用一系列卷积层,并生成所有语义类别的像素可能性分数图,如图 1(a) 所示。由于卷积的简单性、效率和局部权重共享特性,FCN 为语义分段提供了准确、快速和端到端的解决方案。
However, conventional FCNs do not work for the instance-aware semantic segmentation task, which requires the detection and segmentation of individual object instances. The limitation is inherent. Because convolution is translation invariant, the same image pixel receives the same responses (thus classification scores) irrespective to its relative position in the context. However, instance-aware semantic segmentation needs to operate on region level, and the same pixel can have different semantics in different regions. This behavior cannot be modeled by a single FCN on the whole image. The problem is exemplified in Figure 2.
但是,传统的 FCN 不适用于语义分割任务任务,这需要检测和分割单个对象实例。局限性是固有的。由于卷积是平移不变的,因此同一图像像素接收相同的响应(因此分类分数),而不管它在上下文中的相对位置如何。但是,实例分割需要在区域级别上操作,并且同一像素在不同的区域中可能具有不同的语义。此行为不能由整个映像上的单个 FCN 建模。图 2 说明了这个问题。
Certain translation-variant property is required to solve the problem. In a prevalent family of instance-aware semantic segmentation approaches [7, 16, 8], it is achieved by aopting different types of sub-networks in three stages: 1) an FCN is applied on the whole image to generate intermediate and shared feature maps; 2) from the shared feature maps, a pooling layer warps each region of interest (ROI) into fixed-size per-ROI feature maps [17, 12]; 3) one or more fully-connected (fc) layer(s) in the last network convert the per-ROI feature maps to per-ROI masks. Note that the translation-variant property is introduced in the fc layer(s) in the last step.
要解决此问题,需要某些转换变量属性。在流行的实例感知语义分段方法系列[7,16,8]中,它通过分三个阶段选择不同类型的子网络来实现:1)在整个图像上应用FCN来生成中间和共享要素映射;2) 从共享要素地图中,池层将每个感兴趣的区域 (ROI) 扭曲为固定大小的每个 ROI 要素映射 [17, 12];3) 最后一个网络中的一个或多个完全连接 (fc) 层将每个 ROI 要素映射转换为每个 ROI 掩码。请注意,在最后一步中的 fc 层中引入了转换变量属性。
Such methods have several drawbacks. First, the ROI pooling step losses spatial details due to feature warping and resizing, which however, is necessary to obtain a fixed-size representation (e.g., 14 × 14 in [8]) for fc layers. Such distortion and fixed-size representation degrades the segmentation accuracy, especially for large objects. Second, the fc layers over-parametrize the task, without using regularization of local weight sharing. For example, the last fc layer has high dimensional 784-way output to estimate a 28 × 28 mask. Last, the per-ROI network computation in the last step is not shared among ROIs. As observed empirically, a considerably complex sub network in the last step is necessary to obtain good accuracy [36, 9]. It is therefore slow for a large number of ROIs (typically hundreds or thousands of region proposals). For example, in the MNC method [8], which won the 1st place in COCO segmentation challenge 2015 [25], 10 layers in the ResNet-101 model [18] are kept in the per-ROI sub-network. The approach takes 1.4 seconds per image, where more than 80% of the time is spent on the last per-ROI step. These drawbacks motivate us to ask the question that, can we exploit the merits of FCNs for end-to-end instance-aware semantic segmentation?
这些方法有几个缺点。首先,ROI 池级步因要素扭曲和调整而丢失空间细节,但是,对于 fc 图层,获取固定大小的表示形式(例如,14 * 14 [8])是必要的。这种失真和固定大小的表示会降低分割精度,尤其是对于大型对象。其次,,若不使用局部权重共享的正则化,fc 层过度辅助任务。例如,最后一个 fc 图层具有高维 784 输出来估计 28 × 28 掩码。最后,最后一步中的每 ROI 网络计算不在 ROI 之间共享。正如经验所观察到的,在最后一步中,为了获得良好的精度(36,9]),需要一个相当复杂的子网络。因此,对于大量区域执行(通常为数百或数千个区域提案)而言,速度很慢。例如,在 2015 年 COCO 分段挑战中赢得第一名的 MNC 方法 [8]中,ResNet-101 模型 [18] 中的 10 层保存在每个 ROI 子网络中。该方法每张映像需要 1.4 秒,其中超过 80% 的时间用于最后一个 ROI 步骤。这些缺点促使我们提出这样一个问题:我们能否利用 FCN 的优点进行端到端实例感知语义分段?
Recently, a fully convolutional approach has been proposed for instance mask proposal generation [5]. It extends the translation invariant score maps in conventional FCNs to position-sensitive score maps, which are somewhat translation-variant. This is illustrated in Figure 1(b). The approach is only used for mask proposal generation and presents several drawbacks. It is blind to semantic categories and requires a downstream network for detection. The object segmentation and detection sub-tasks are separated and the solution is not end-to-end. It operates on square, fixed-size sliding windows (224 × 224 pixels) and adopts a time-consuming image pyramid scanning to find instances at different scales.
最近,有人提出了一个完全卷积的方法用于mask proposal生成[5]。它将传统 FCN 中的转换不变量分数映射扩展到位置敏感分数图,这些分数图在某种程度上是平移变体。如图 1(b) 所示。该方法仅用于掩码提案生成,并存在几个缺点。它对语义类别视而不见,需要下游网络进行检测。对象分割和检测子任务是分开的,解决方案不是端到端的。它在方形固定大小的滑动窗口(224 × 224 像素)上运行,并采用耗时的图像金字塔扫描来查找不同比例的实例。
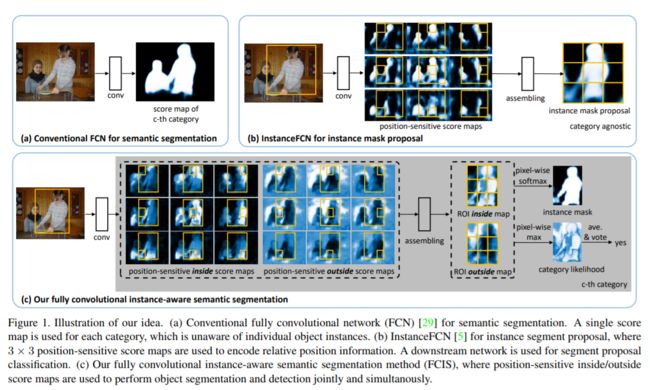
In this work, we propose the first end-to-end fully convolutional approach for instance-aware semantic segmentation. Dubbed FCIS, it extends the approach in [5]. The underlying convolutional representation and the score maps are fully shared for the object segmentation and detection sub-tasks, via a novel joint formulation with no extra parameters. The network structure is highly integrated and efficient. The per-ROI computation is simple, fast, and does not involve any warping or resizing operations. The approach is briefly illustrated in Figure 1(c). It operates on box proposals instead of sliding windows, enjoying the recent advances in object detection [34].
在这项工作中,我们提出了第一个端到端的完全卷积方法,用于实例感知语义分割。它被称为FCIS,扩展了[5]中的方法。通过没有额外参数的新型联合公式,为对象分割和检测子任务完全共享基础卷积表示和分数图。网络结构高度集成,效率高。每个 ROI 计算简单、快速,不涉及任何变形或调整大小操作。该方法在图 1(c) 中进行了简要说明。它根据盒子建议而不是滑动窗口运行,享受物体检测的最新进展[34]。
[5]J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive fully convolutional networks. In ECCV, 2016
Extensive experiments verify that the proposed approach is state-of-the-art in both accuracy and efficiency. It achieves significantly higher accuracy than the previous challenge winning method MNC [8] on the large-scale COCO dataset [25]. It wins the 1st place in COCO 2016 segmentation competition, outperforming the 2nd place entry by 12% in accuracy relatively. It is fast. The inference in COCO competition takes 0.24 seconds per image using ResNet-101 model [18] (Nvidia K40), which is 6× faster than MNC [8]. Code would be released at https: //github.com/daijifeng001/TA-FCN.
广泛的实验验证了该方法在准确性和效率方面都是最先进的。与之前的挑战获胜方法 MNC [8] 相比,在大型 COCO 数据集 [25] 上,它实现了更高的精度。它在 COCO 2016 分段竞赛中获得第一名,在准确性方面以 12% 的精度超过第二名。速度很快。使用 ResNet-101 模型 [18] (Nvidia K40)(Nvidia K40),COCO 竞赛中的推理每幅图像需要 0.24 秒,比 MNC [8] 快 6 倍。代码将在 https 发布://github.com/daijifeng001/TA-FCN。
2. Our Approach
2.1. Position-sensitive Score Map Parameterization
In FCNs [29], a classifier is trained to predict each pixel’s likelihood score of “the pixel belongs to some object category”. It is translation invariant and unaware of individual object instances. For example, the same pixel can be foreground on one object but background on another (adjacent) object. A single score map per-category is insufficient to distinguish these two cases.
在 FCN [29]中,对分类器进行了训练,以预测每个像素的可能性分数"像素属于某个对象类别"。它是转换不变的,不知道单个对象实例。例如,同一像素可以是一个对象上的前景,但在另一个(相邻)对象上是背景。每个类别的单个分数图不足以区分这两种情况。
To introduce translation-variant property, a fully convolutional solution is firstly proposed in [5] for instance mask proposal. It uses k^2 position-sensitive score maps that correspond to k × k evenly partitioned cells of objects. This is illustrated in Figure 1(b) (k = 3). Each score map has the same spatial extent of the original image (in a lower resolution, e.g., 16× smaller). Each score represents the likelihood of “the pixel belongs to some object instance at a relative position”. For example, the first map is for “at top left position” in Figure 1(b).
为了引入平移变量特性,首先在[5]中提出了一种完全卷积方法来提出instance mask proposal。它使用 k^2 位置敏感分数图,对应于对象均匀分区的单元格 k * k。如图 1(b) (k = 3)所示。每个分数图都具有相同的原始图像的空间范围(分辨率较低,例如,16x 较小)。每个分数表示"像素属于相对位置的某个对象实例"的可能性。例如,第一个映射用于图 1(b) 中的"左上位置"。
During training and inference, for a fixed-size square sliding window (224×224 pixels), its pixel-wise foreground likelihood map is produced by assembling (copy-paste) its k×k cells from the corresponding score maps. In this way, a pixel can have different scores in different instances as long as the pixel is at different relative positions in the instances.
在训练和推理过程中,对于固定尺寸的方形滑动窗口(224×224 像素),通过从相应的分数图组装(复制粘贴)其 k*k 单元格来生成其像素级前景可能性图。这样,只要像素在实例中处于不同的相对位置,像素在不同的实例中可以有不同的分数。

FCIS是怎么实现图像分类与图像分割的并联呢? 通过两类score map解决,一类叫inside score map,一类叫outside score map。inside score map表征了像素点在ROI区域内部中前景的分数,如果一个像素点是位于一个ROI区域内部并且是目标(前景),那么在inside score map中就应该有较高的分数,而在outside score map中就应该有较低的分数。反之亦然,如果一个像素点是位于一个ROI区域内部并且是背景,那么在inside score map中就应该有较低的分数,而在outside score map中就应该有较高的分数。针对图像分割,使用两类score map,通过一个分类器就可以分出前景与背景。针对图像分类,将两类score map结合起来,可以实现分类问题。
这样做还有一个好处,通过两类score map的结合,可以甄别出ROI检测失误的区域。
首先,对于每个ROI区域,将inside score maps和outside score maps中的小块特征图复制出来,拼接成为了ROI inside map和ROI outside map。针对图像分割任务,直接对上述两类map通过softmax分类器分类,得到ROI中的目标前景区域(Mask)。针对图像分类任务,将两类map中的score逐像素取最大值,得到一个map,然后再通过一个softmax分类器,得到该ROI区域对应的图像类别。在完成图像分类的同时,还顺便验证了ROI区域检测是否合理,具体做法是求取最大值得到的map的所有值的平均数,如果该平均数大于某个阈值,则该ROI检测是合理的。 针对输入图像上的每一个像素点,有三种情况:第一种情况是inside score高,outside score低;则该像素点位于ROI中的目标部分。第二种情况是inside score低,outside score高,则该像素点位于ROI中的背景部分。第三种情况是inside score和outside score都很低,那么该像素点不在任何一个ROI里面。因此,我们在上一段中描述的,针对ROI inside map和ROI outside map中逐像素点取最大值得到的图像:如果求平均后分数还是很低,那么,我们可以断定这个检测区域是不合理的。如果求平均后分数超过了某个阈值,我们就通过softmax分类器求ROI的图像类别,再通过softmax分类器求前景与背景。
As shown in [5], the approach is state-of-the-art for the object mask proposal task. However, it is also limited by the task. Only a fixed-size square sliding window is used. The network is applied on multi-scale images to find object instances of different sizes. The approach is blind to the object categories. Only a separate “objectness” classification sub-network is used to categorize the window as object or background. For the instance-aware semantic segmentation task, a separate downstream network is used to further classify the mask proposals into object categories [5].
如 {5} 所示,该方法是对象掩码建议任务的最先进的方法。但是,它还受到任务的限制。仅使用固定大小的方形滑动窗口。网络应用于多比例图像,以查找不同大小的对象实例。该方法对对象类别视而不见。只有单独的"对象"分类子网络用于将窗口分类为对象或背景。对于实例感知语义分段任务,使用单独的下游网络将进一步将掩码建议分为对象类别 [5]。
2.2. Joint Mask Prediction and Classification
For the instance-aware semantic segmentation task, not only [5], but also many other state-of-the-art approaches, such as SDS [15], Hypercolumn [16], CFM [7], MNC [8], and MultiPathNet [42], share a similar structure: two subnetworks are used for object segmentation and detection sub-tasks, separately and sequentially.
对于实例感知语义分段任务,不仅 [5],而且许多其他最先进的方法,如 SDS [15]、超列 [16]、CFM [7]、MNC [8]和 MultiPathNet [42],共享一个类似的结构:对象使用两个子网分别用于分割和检测子任务。
Apparently, the design choices in such a setting, e.g., the two networks’ structure, parameters and execution order, are kind of arbitrary. They can be easily made for convenience other than for fundamental considerations. We conjecture that the separated sub-network design may not fully exploit the tight correlation between the two tasks.
显然,在这样的环境中,设计选择,例如两个网络的结构、参数和执行顺序,都是任意的。除了基本考虑之外,它们可以很容易地为方便而制作。我们推测分离的子网络设计不能充分利用两个任务之间的紧密关联。
We enhance the “position-sensitive score map” idea to perform the object segmentation and detection sub-tasks jointly and simultaneously. The same set of score maps are shared for the two sub-tasks, as well as the underlying convolutional representation. Our approach brings no extra parameters and eliminates non essential design choices. We believe it can better exploit the strong correlation between the two sub-tasks.
我们强化"位置敏感分数图position-sensitive score map"理念,共同、同时地执行对象分割和检测子任务。对于两个子任务以及基础卷积(underlying convolutional representation)表示,共享相同的一组分数图。我们的方法没有额外的参数,消除了不必要的设计选择。我们相信它可以更好地利用两个子任务之间的强相关性。
Our approach is illustrated in Figure 1(c) and Figure 2. Given a region-of-interest (ROI), its pixel-wise score maps are produced by the assembling operation within the ROI. For each pixel in a ROI, there are two tasks: 1) detection: whether it belongs to an object bounding box at a relative position (detection+) or not (detection-); 2) segmentation: whether it is inside an object instance’s boundary (segmentation+) or not (segmentation-). A simple solution is to train two classifiers, separately. That’s exactly our baseline FCIS (separate score maps) in Table 1. In this case, the two classifiers are two 1 × 1 conv layers, each using just one task’s supervision.
图 1(c) 和图 2 说明了我们的方法。给定感兴趣区域 (ROI),其像素级分数图由 ROI 内的装配操作生成。对于 ROI 中的每个像素,有两个任务:1) 检测:它是否属于位于相对位置(检测+)的对象边界框(检测-);2) 分段:是否位于对象实例的边界内(分割+)或非(分割-)。一个简单的解决方案是分别训练两个分类器。这正是表 1 中的基准 FCIS(单独的分数映射)。在这种情况下,两个分类器是两个 1 × 1 conv 层,每个分类器仅使用一个任务的监督。
Our joint formulation fuses the two answers into two scores: inside and outside. There are three cases: 1) high inside score and low outside score: detection+, segmentation+; 2) low inside score and high outside score: detection+, segmentation-; 3) both scores are low: detection-, segmentation-. The two scores answer the two questions jointly via softmax and max operations. For detection, we use max to differentiate cases 1)-2) (detection+) from case 3) (detection-). The detection score of the whole ROI is then obtained via average pooling over all pixels’ likelihoods (followed by a softmax operator across all the categories). For segmentation, we use softmax to differentiate cases 1) (segmentation+) from 2) (segmentation-), at each pixel. The foreground mask (in probabilities) of the ROI is the union of the per-pixel segmentation scores (for each category). Similarly, the two sets of scores are from two 1 × 1 conv layer. The inside/outside classifiers are trained jointly as they receive the back-propagated gradients from both segmentation and detection losses.
我们的联合将两个答案融合成两个分数:内部和外部。有三种情况:1) 内得分高,外线得分低:检测+、分割-;2) 内得分低,外高分:检测+,分割-;3) 两个分数都很低:检测-,分段-。两个分数通过softmax和最大操作共同回答了这两个问题。对于检测,我们使用最大值来区分案例 1)-2)(检测+)和案例 3)(检测-)。然后,通过对所有像素可能性的平均池(后跟所有类别的 softmax 运算符)获得整个 ROI 的检测分数。对于分割,我们使用 softmax 来区分每个像素的情况 1)(分段+)和 2)(分段-)。ROI 的前景掩码(概率)是每像素分割分数(每个类别)的合并。同样,两组分数来自两个 1 × 1 conv 层。内部/外部分类器在从分段和检测损耗中接收反传播梯度时,会共同训练。
The approach has many desirable properties. All the perROI components (as in Figure 1(c)) do not have free parameters. The score maps are produced by a single FCN, without involving any feature warping, resizing or fc layers. All the features and score maps respect the aspect ratio of the original image. The local weight sharing property of FCNs is preserved and serves as a regularization mechanism. All per-ROI computation is simple (k^2cell division, score map copying, softmax, max, average pooling) and fast, giving rise to a negligible per-ROI computation cost.
该方法具有许多理想的属性。所有 perROI 组件(如图 1(c)所示)没有自由参数。分数图由单个 FCN 生成,不涉及任何要素扭曲、调整大小或 fc 图层。所有要素和记分贴图都尊重原始图像的纵横比。保留 FCN 的本地权重共享属性,并充当正则化机制。所有每 ROI 计算都很简单(k^2 单元分割、分数图复制、softmax、最大值、平均池),因此每 ROI 计算成本可忽略不计。
2.3. An End-to-End Solution
Figure 3 shows the architecture of our end-to-end solution. While any convolutional network architecture can be used [39, 40], in this work we adopt the ResNet model [18]. The last fully-connected layer for 1000−way classification is discarded. Only the previous convolutional layers are retained. The resulting feature maps have 2048 channels. On top of it, a 1 × 1 convolutional layer is added to reduce the dimension to 1024.
图 3 显示了端到端解决方案的体系结构。虽然可以使用任何卷积网络架构 [39, 40],但在这项工作中,我们采用了 ResNet 模型 [18]。将丢弃 1000 路分类的最后一个完全连接的图层。仅保留以前的卷积层。生成的要素地图具有 2048 个通道。在上面,添加 1 × 1 卷积层,将尺寸减小到 1024。
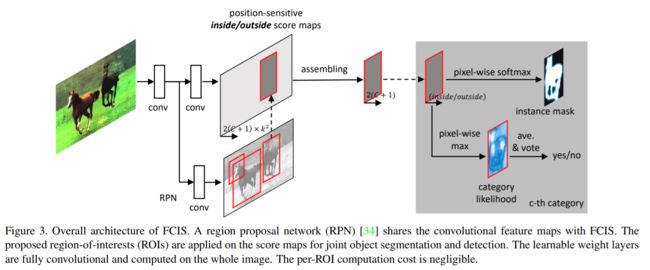
图像输入进来,经过卷积层提取初步特征,然后利用这些特征,一边经过RPN(Region Proposal Network)网络提取ROI区域,一边再经过一些卷积层生成2×(C+1)×k×k个特征图。2代表inside和outside两类;C+1代表图像类别一共C类,再加上背景(未知的)1类;k×k代表每一类score map中各有k个(上图的例子中k就为3)。在经过assembling之后(其实就是复制粘贴),对于每一个ROI,k×k个position-sensitive score map被综合成了一个,然后放小了16倍(长宽各变成1/4),得到2×(C+1)个特征图。然后开始并行操作,第一条线:对于每一类的ROI inside map和ROI outside map逐像素取最大值,得到了C+1个特征图,对这C+1个特征图逐个求平均值,将平均值同阈值比较,若大于阈值,则判定该ROI合理,则直接送入softmax分类器进行分类,得到图像类别。若小于阈值,则不进行任何操作。第二条线:做C+1次softmax分类,对每一个类别得到前景与背景,然后根据第一条并行线的分类结果,选择出对应类别的前景与背景划分结果。
In the original ResNet, the effective feature stride (the decrease in feature map resolution) at the top of the network is 32. This is too coarse for instance-aware semantic segmentation. To reduce the feature stride and maintain the field of view, the “hole algorithm” [3, 29] (Algorithme a` trous [30]) is applied. The stride in the first block of conv5 convolutional layers is decreased from 2 to 1. The effective feature stride is thus reduced to 16. To maintain the field of view, the “hole algorithm” is applied on all the convolutional layers of conv5 by setting the dilation as 2.
在原始 ResNet 中,网络顶部的有效要素步幅(要素地图分辨率的降低)为 32。对于实例感知语义分段来说,这太粗糙了。为了减小特征步幅并保持视野,应用了"孔算法"[3,29](空洞卷积)。conv5 卷积层第一块的步幅从 2 减少到 1。因此,有效特征步幅减少到 16。为了保持视野,通过将扩张设置为 2,将"孔算法"应用于 conv5 的所有卷积层。
We use region proposal network (RPN) [34] to generateROIs. For fair comparison with the MNC method [8], it isadded on top of the conv4 layers in the same way. Note that RPN is also fully convolutional.
我们使用区域建议网络 (RPN) [34] 来生成 ROI。为了与 MNC 方法 [8] 进行公平比较,它以同样的方式添加到 conv4 层的顶部。请注意,RPN 也是完全卷积的。
From the conv5 feature maps, 2k^2 ×(C + 1) score maps are produced (C object categories, one background category, two sets of k^2 score maps per category, k = 7 by default in experiments) using a 1×1 convolutional layer. Over the score maps, each ROI is projected into a 16× smaller region. Its segmentation probability maps and classification scores over all the categories are computed as described in Section 2.2.
在 conv5 要素图中,使用 1*1 卷积层生成 2k^2 *(C + 1) 分数图(C 对象类别、一个背景类别、每个类别两组 k^2 得分图,默认情况下 k = 7)。在分数图上,每个 ROI 被投影到 16x 多个较小的区域。如第 2.2 节所述,计算了所有类别的细分概率图和分类分数。
有inside score map和outside score map
Following the modern object detection systems, bounding box (bbox) regression [13, 12] is used to refine the initial input ROIs. A sibling 1×1 convolutional layer with 4k^2 channels is added on the conv5 feature maps to estimate the bounding box shift in location and size. Below we discuss more details in inference and training.
在现代对象检测系统之后,边界框(bbox)回归 [13, 12] 用于优化初始输入 ROIs。在 conv5 要素图上添加了具有 4k^2 通道的同级 1⁄1 卷积层,以估计边界框的位置和大小变化。下面我们将讨论推理和培训中的更多详细信息。
Inference For an input image, 300 ROIs with highest scores are generated from RPN. They pass through the bbox regression branch and give rise to another 300 ROIs. For each ROI, we get its classification scores and foreground mask (in probability) for all categories. Figure 2 shows an example. Non-maximum suppression (NMS) with an intersection-over-union (IoU) threshold 0.3 is used to filter out highly overlapping ROIs. The remaining ROIs are classified as the categories with highest classification scores. Their foreground masks are obtained by mask voting [8] as follows. For an ROI under consideration, we find all the ROIs (from the 600) with IoU scores higher than 0.5. Their foreground masks of the category are averaged on a per-pixel basis, weighted by their classification scores. The averaged mask is binarized as the output.
对于输入图像,从 RPN 生成 300 个得分最高的 ROIs。它们通过 bbox 回归分支,并产生另外 300 个 ROIs。对于每个 ROI,我们获取所有类别的分类分数和前景掩码(概率)。图 2 显示了一个示例。具有交集过结合 (IoU) 阈值 0.3 的非最大抑制 (NMS) 用于筛选出高度重叠的 ROI。其余的 ROI 被归类为分类分数最高的类别。其前景掩码通过掩码投票 [8] 获得,如下所示。对于正在考虑的投资回报率,我们发现所有 IOU 分数高于 0.5 的 ROI(从 600 中) 。类别的前景蒙版按像素求平均值,按分类分数加权。平均蒙版被二元化为输出。