前言
这篇基础文章其实原本写得很久,内容有点冗余,因为老想把每句源码都解释清除,但是写着写着又坚信你们有能力读懂。综合考虑还是对于大部分简单的源码都cv即可,少部分源码再解释。
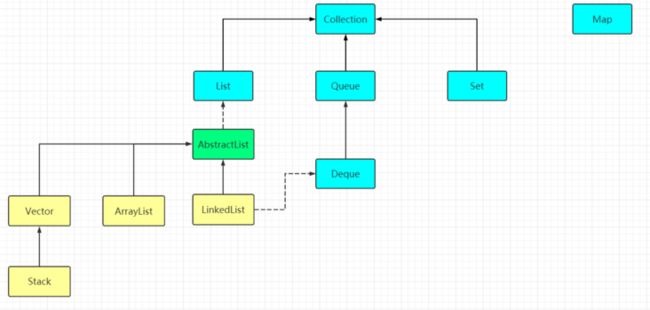
java集合可以说无论是面试、刷题还是工作中都是非常常用的。抛去Iterable , 从Collection 级别说起,整个java集合主要分为Collection 和Map 两大类。
Collection 接口下呢,又有List 、Queue 和Set 三大接口,本篇文章就List 而言描述了Vector 、Stack 、ArrayList 和LinkedList 四大常用的类。
List 简单来说就是存取有序的集合,并且有索引值,元素可以重复。
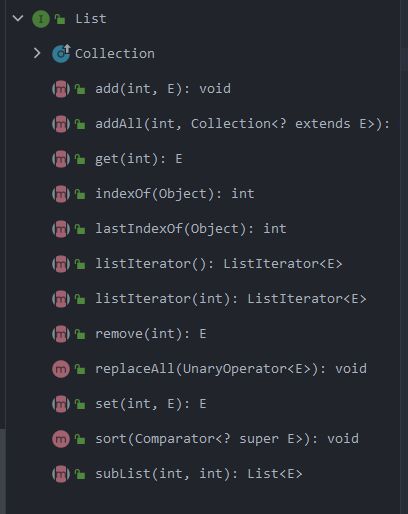
ArrayList
结构及构造函数

查看源码可以知道,ArrayList 的底层是使用elementData 来存储数据的。


对于ArrayList的构造函数而言,本质都是构造elementData
ArrayList(int initialCapacity)
如果有初始容量,那么直接新建一个数组;为0则为空数组,待第一次add的时候初始化数组;小于0直接抛出异常
ArrayList()
空构造函数则是构造一个空数组
ArrayList(Collection c)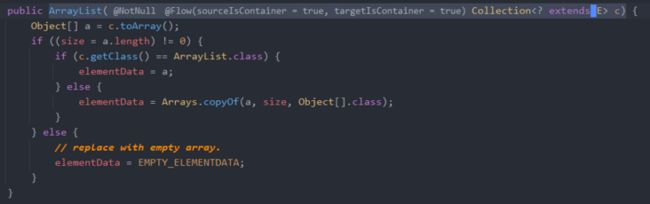
如果传进来的集合类型是
ArrayList,直接赋值即可,否则借助Arrays.copyOf进行赋值。
有关数据的处理,肯定离不开增删改查,所以在本篇文章中主要讲述了几个非常常用的方法,至于其它个别方法,各位小伙伴自行查看源码即可。
增加元素

在插入元素的时候需要对容量进行一个检查操作ensureCapacityInternal(size + 1)

先计算一次容量calculateCapacity(elementData, minCapacity)
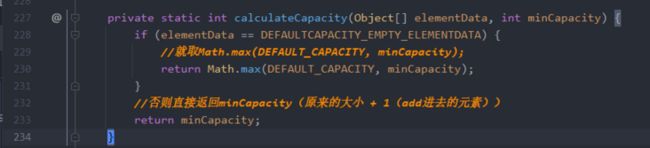
就算出来容量后就调用ensureExplicitCapacity(int minCapcity)
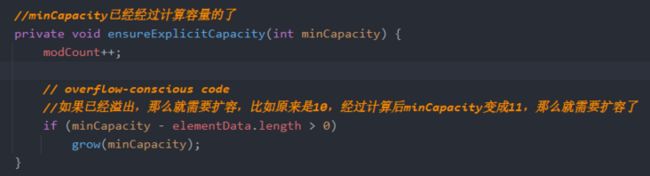
/如果已经溢出,那么就需要扩容,比如原来是10,经过计算后minCapacity变成11,那么就需要grow(minCapacity)扩容了
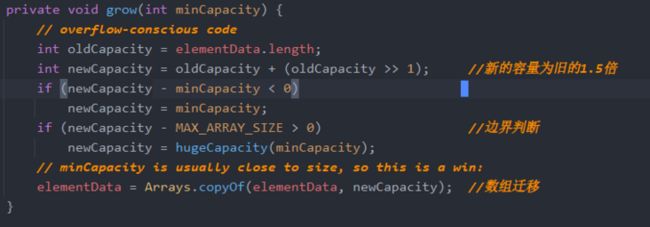
有很多边界判断,包括hugeCapacity(minCapacity) 其实也是一个边界判断

重点是可以看到扩容后的数组容量为旧容量的1.5倍,并且整个扩容就是利用Arrays.copyOf(elementData, newCapacity) 进行数据迁移。
除了add方法,还有很多以add开头的方法
在特定下标下增加元素,add(int index, Integer element)
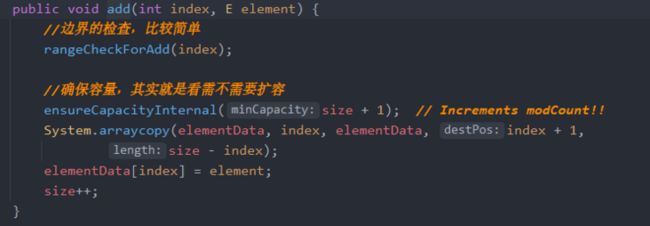
其它基本都一样,由于需要在某个特定位置插入元素,所以导致了数据迁移时候的代码有区别。剩下的两个方法代码就不贴了,甚至自己实现都可以,核心就是数据迁移。
删除
对于删除而言,有2个重载方法,一个是删除某个下标的元素,另外一个是删除某个特定的元素。
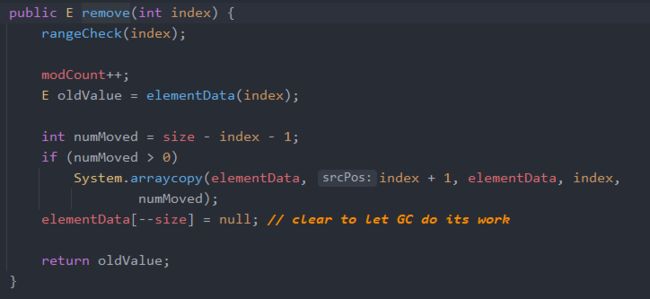
先获取要删除下标的元素值;如果下标不是最后一个,那么还是同样采用数据迁移即可;如果下标是最后一个,那么直接让最后一个元素等于null,这样同时也能够方便垃圾收集(Garbage Collect)。
对于删除某个特定的元素
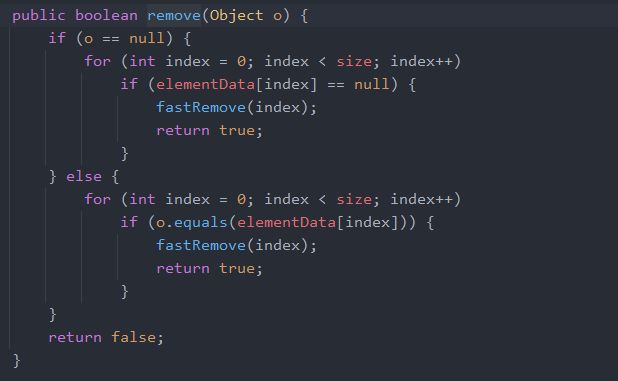
可以发现抛弃了对象的判断等一些操作,核心函数是fastRemove(index)。
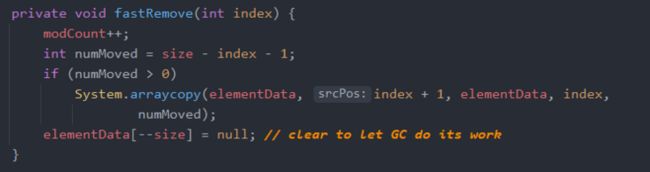
和删除特定下标的代码不能说毫无关系,只能说一模一样。
这里需要排坑,当我们存包装类型,而删除的时候传入了基本类型,就会调用删除下标的函数;要想调用删除元素的函数,就需要强制类型转换。
修改

查询
查找特定元素下标
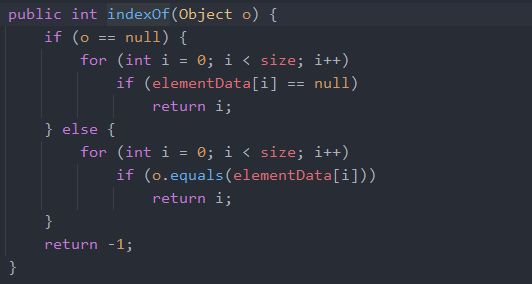
这没啥好说的,就是逐个遍历,找到想要的元素,为了效率高一点甚至可以考虑自己修改下源码,采用二分查找,但是用到的ArrayList 存取的数据量一般都不是很大,效率提升也不明显。

对于查找元素最后出现的下标,那就是倒过来遍历即可。
得到某个下标元素

LinkedList
结构及构造函数
值得注意的是LinkedList 即实现了List 接口,也实现了Deque ,本篇文章仅讨论实现了List 接口的部分。
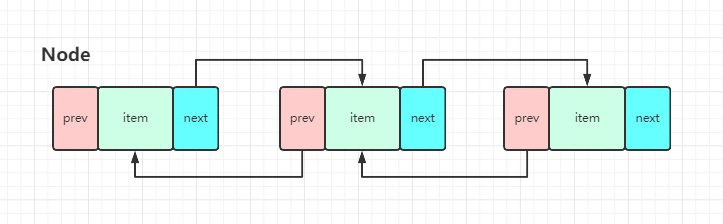
LinkedList 正是由多个结点组成的双向链表
public LinkedList() {
}
public LinkedList(Collection c) {
this();
addAll(c);
}两种构造函数,不过后者也是采用了空构造函数,然后调用了addAll 方法添加元素。
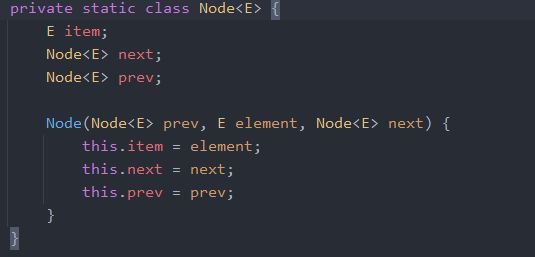
Node结点 的构造也是需要学习的
增加


增加的话就是获取最后的一个元素,然后维护结点关系即可。

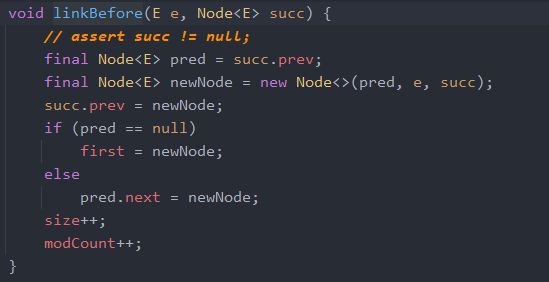
往最后添加元素刚说过,其它情况有两个重要的函数linkBefore 和node,后者留着等查询的时候再分析。
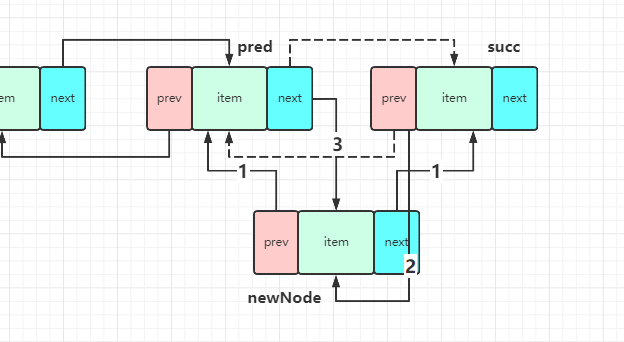
找到结点,然后一样维护结点关系即可。
还有一种是增加另外一个集合,也是有两种。

简单地插在末尾的情况就不说了,主要说下图中标序号的情况

删除
删除某个对象的代码如下

删除某个下标的代码如下,会发现是一样的,也是得根据下标找到对象,然后调用上面删除对象的代码

所以现在重点是来到了unlink 方法

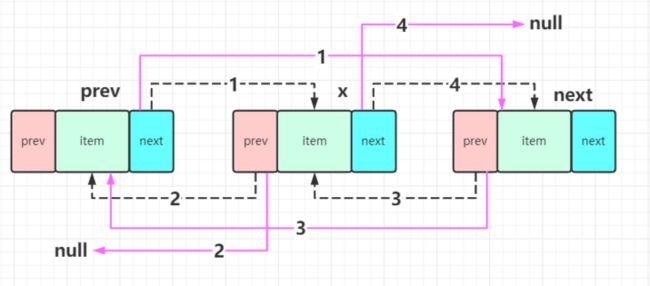
修改
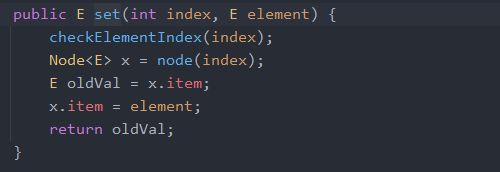
很简单,就是找到结点,然后替换掉item即可。
查询
查询结点

还记得吗,前面说过先把node看成是获取某个下标的结点,现在就来看看是什么。
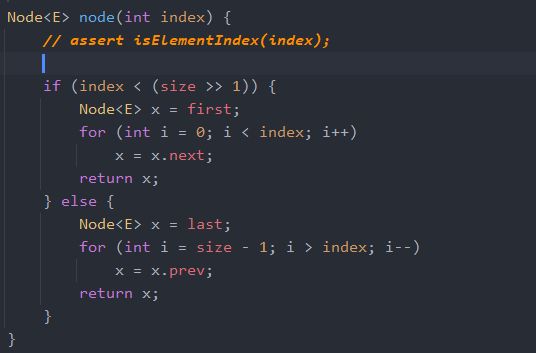
可能如果给各位小伙伴,第一印象还是从头开始遍历,然后往后找。但是由于是双向链表的远古,所以如果index小与一半从first开始后找,否则从last开始往前找。
查询下标
很简单啦,维护一个变量index = 0,从前开始往后找,变量自增1,找不到返回-1。

如果是想要最后一个下标,从后往前找即可,然后维护的变量是index = size ,每次自减1
Vector
Vector同样也是采用了数组来存储数据,可以说是ArrayList 的线程安全版本,包括所有的实现基本都类似

可以看到,为了保证线程安全,在方法体中会加入synchronized 关键字。还有一点不同的是扩容 的实现。
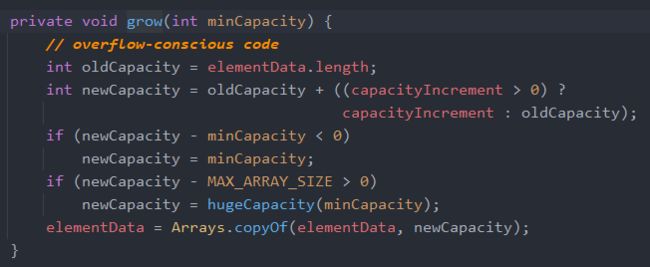
可以看到不同于ArrayList 增长为原来的1.5倍,Vector 是增长为原来的2倍。
Stack
查看源码可以知道Stack是继承了Vector ,所以它也是用数组来存储元素,所有的操作都是基于数组。
栈的所有方法都在这了,主要还是一样的增删改查,看一下push() 的源码
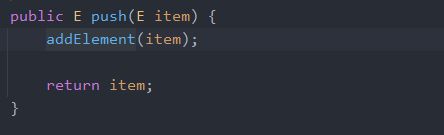
会调用addElement(item)
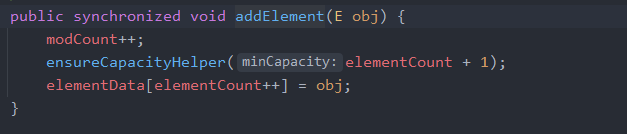
又回到了数组方面的实现,这个在ArrayList 的分析中都讲过了,甚至都不用什么分析,就是简单的数组存储数据。
总结
List存储一组不唯一(可以有多个元素引用相同的对象),有序的对象,分为Arraylist,LinkedList,Vector和Stack。
Arraylist是使用数组来实现的,适合随机访问和遍历(各位小伙伴看源码的时候发现了ArrayList实现了RandomAccess接口,不过这个接口是个空实现,估计只是个标记)但是不适合添加和删除,是线程不安全的.
LinkedList是通过双向链表结构来存储数据的,一般来说可以当作队列,双向队列和堆栈来使用。由于链表的结构,所以更加适合添加和删除,随机访问和遍历效率相对比较低。