@TOC
Redis概述 ✍
什么是Redis
Redis是Remote Dictionary Server(远程字典服务器)的缩写,可以作为高效的缓存。
Redis使用C语言开发,将数据保存在内存中,可以看成是一款纯内存的数据库,所以它的数据存取速度非常快。
Redis通过键值对的形式来存储数据。Redis的Key只能是String类型,Value值则可以是String类型,Map类型、List(列表)类型、Set(集合)类型、SortedSet(有序集合)等类型。
为什么用Redis做缓存
相比于其他的键值对内存数据库,Redis有如下特点:
- 速度快。不需要等待磁盘IO,而是在内存之间进行数据存储和查询,速度非常快。缓存的数据总量不能太大,因为受到物理内存空间大小的限制
- 丰富的数据结构
- 单线程,避免了线程切换和锁机制的性能消耗 ,不过6.0后是多线程了
- 可持久化,支持RDB与AOF两种方式,将内存中的数据写入外部的物理存储设备
- 支持发布、订阅
- 支持Lua脚本
- 支持分布式锁
- 支持原子操作和事务
- 支持主从复制和高可用集群
- 支持管道,Redis管道是指客户端可以将多个命令一次性发送到服务器,然后由服务器一次性返回所有结果。管道技术的优点是,在批量执行命令的应用场景中,可以大大减少网络传输开销,提高性能
Redis安装启动
下载配置一下Redis
Linux服务器上:
下载:
wget http://download.redis.io/releases/redis-4.0.10.tar.gz
解压
tar -zxvf redis-4.0.10.tar.gz
cd redis-4.0.10
make MALLOC=libc (要求已安装gcc)
make install修改redis.conf文件

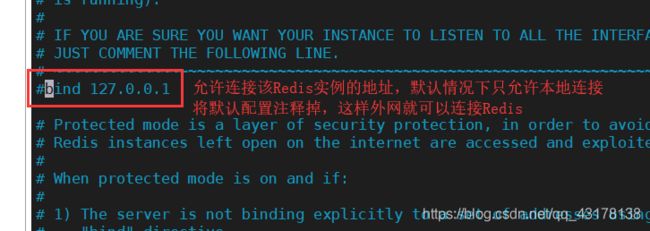
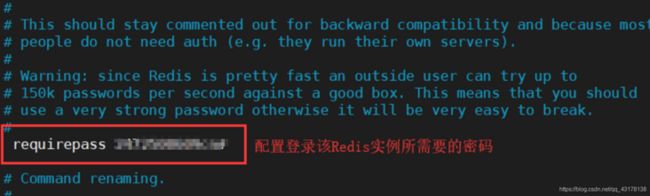


> redis-server redis.conf 启动
> redis-cli -a password 连接
也可以在命令行关闭:
redis-cli -p 6379 -a your_password shutdown压测工具:
redis-benchmark -h localhost -p 6379 -c 50 -n 10000
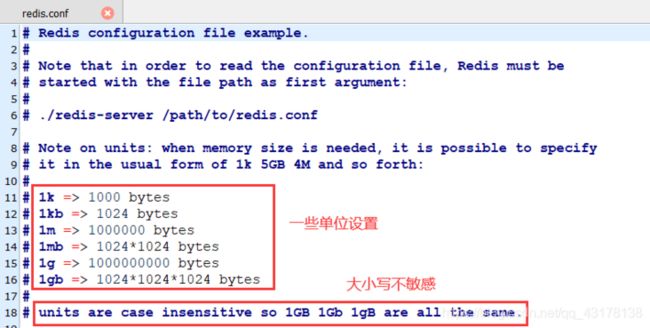
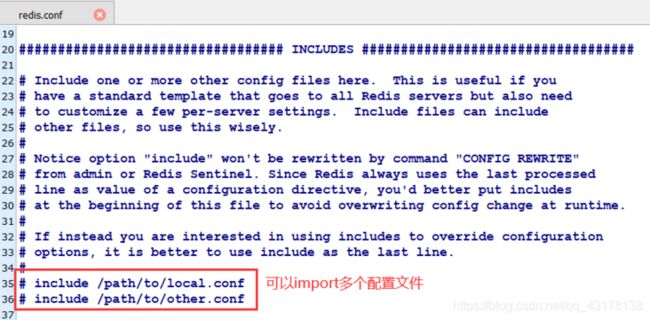
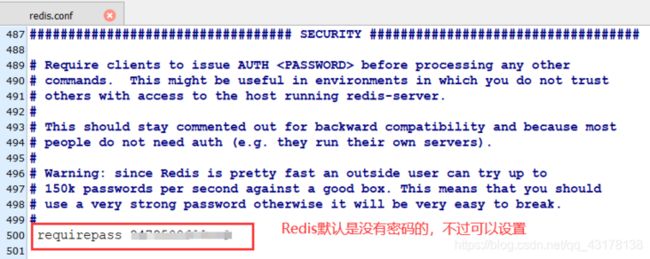
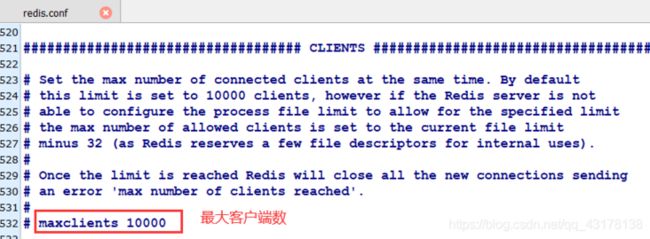
具体可用参数翻文档Redis配置文件解读 ⚙


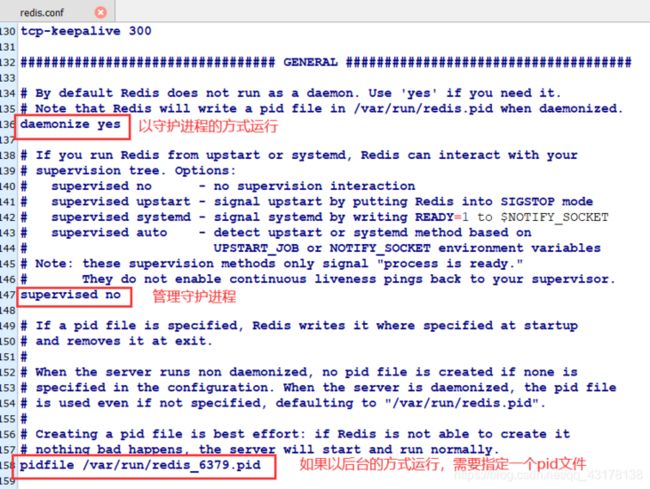
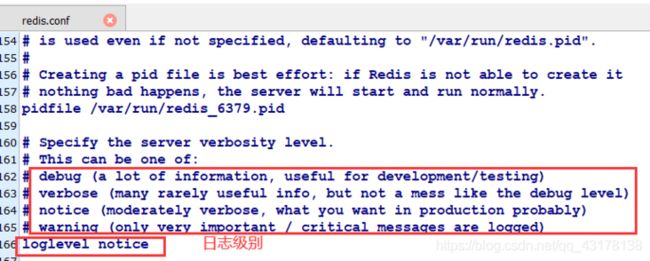
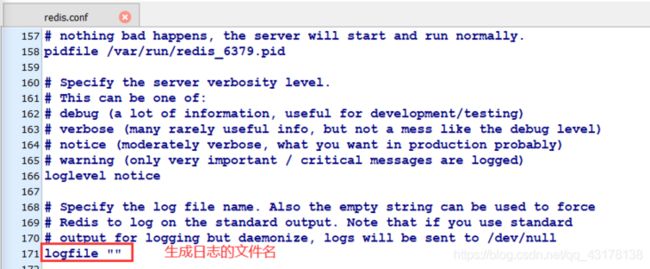



Redis数据类型 ✍
String字符串
Redis自己构建了简单的动态字符串SDS(类似ArrayList,预分配冗余空间),没有用c语言原生的。
String类型既可以存储文字,又可以存储数数字,还可以存储二进制数据。
127.0.0.1:6379> set foo name
OK
127.0.0.1:6379> mset f1 str f2 strr f3 strrr
OK
127.0.0.1:6379> get foo
"name"
127.0.0.1:6379> get f1
"str"
127.0.0.1:6379> mget f1 f2 f3
1) "str"
2) "strr"
3) "strrr"
127.0.0.1:6379> strlen f1
(integer) 3
127.0.0.1:6379> set n1 1.0
OK
127.0.0.1:6379> get n1
"1.0"
127.0.0.1:6379> set n2 1
OK
127.0.0.1:6379> incr n2
(integer) 2
127.0.0.1:6379> set bina1 101110
OK
127.0.0.1:6379> get bina1
"101110"应用场景
- 缓存,String是很多语言都有的类型
- 计数器,使用Redis做系统的实时计数器
- 共享用户Session,用户刷新一次页面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,可以利用Redis将用户的Session集中管理,只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成。
List列表
Redis的List类型是基于双向链表实现的,可以支持正向、反向查找和遍历。List列表是简单的字符串列表,字符串按照添加的顺序排列。可以添加一个元素到List列表的头部或尾部。
一个List列表最多可以包含2^32^-1个元素。
List列表的典型应用场景
网络社区中最新的发帖列表、简单的消息队列、最新新闻的分页列表、博客的评论列表、排队系统等。
比如在秒杀活动中,短时间有大量的用户请求发向服务器,而后台的程序不可能立即响应每一个用户的请求。需要一个排队系统,根据用户的请求时间,将用户的请求放入List队列中,后台程序依次从队列中获取任务,处理并将结果返回到结果队列。
- 消息队列:List的链表结构可以实现阻塞队列,使用左进右出的命令来完成队列的设计,比如生产者通过Lpush从左边插入数据,多个消费者用BRpop命令阻塞地抢右边的数据。
- 文章列表、分页展示:可以使用List做分页展示,可以通过lrange命令获取某个闭区间的元素,实现分页查询,还可以做成下拉不断分页那种。
127.0.0.1:6379> set ts taylor
OK
127.0.0.1:6379> get ts
"taylor"
127.0.0.1:6379> rpush ts a b c
(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> del ts
(integer) 1
127.0.0.1:6379> rpush ts a b c
(integer) 3
127.0.0.1:6379> lpush ts 1 3 4
(integer) 6
127.0.0.1:6379> llen ts
(integer) 6
127.0.0.1:6379> rpop ts
"c"
127.0.0.1:6379> lpop ts
"4"
127.0.0.1:6379> lrange ts
(error) ERR wrong number of arguments for 'lrange' command
127.0.0.1:6379> lrange ts 0
(error) ERR wrong number of arguments for 'lrange' command
127.0.0.1:6379> llen ts
(integer) 4
127.0.0.1:6379> lrange ts 0 3
1) "3"
2) "1"
3) "a"
4) "b"
127.0.0.1:6379> lindex ts 0
"3"
127.0.0.1:6379> lset ts 0 5
OK
127.0.0.1:6379> lrange ts 0 3
1) "5"
2) "1"
3) "a"
4) "b"Hash
Redis中的Hash(哈希表)是一个String类型的Field(字段)和Value(值)之间的映射表。基于数组加链表实现。(?像Java中的HashMap)
在同一个哈希表中,每个字段的名字必须是唯一的。
127.0.0.1:6379> hset hm 001 alice
(integer) 1
127.0.0.1:6379> hget hm 001
"alice"
127.0.0.1:6379> hdel hm 001
(integer) 1
127.0.0.1:6379> hexists hm 001
(integer) 0
127.0.0.1:6379> hset hm 001 alice
(integer) 1
127.0.0.1:6379> hset hm 002 bob
(integer) 1
127.0.0.1:6379> hexists hm 002
(integer) 1
127.0.0.1:6379> hkeys hm
1) "001"
2) "002"
127.0.0.1:6379> hvals hm
1) "alice"
2) "bob"Set
Set集合也是一个列表,可以自动去掉重复元素,所以可以去实现全局去重。
底层使用了 intset和 hashtable两种数据结构存储的,intset我们可以理解为数组,hashtable就是普通的哈希表(key为set的值,value为null)
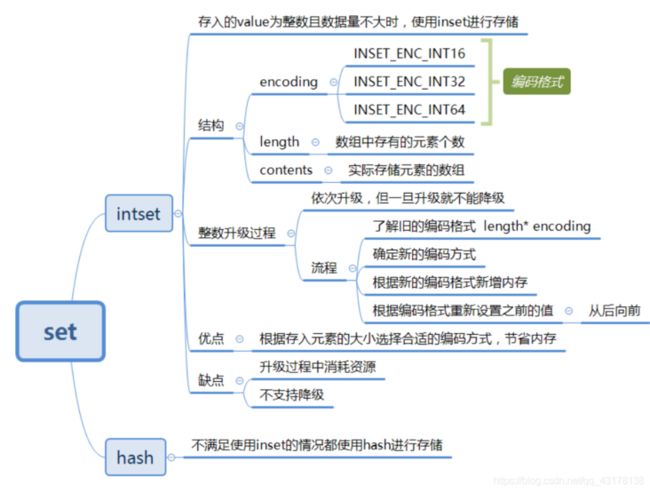
Set拥有一个命令,可用于判断某个元素是否存在,而List类型并没有这种功能的命令。
通过Set类型的命令可以快速地向集合添加元素,或者从集合里面删除元素,也可以对多个Set进行集合运算,例如并集、交集、差集,这个可以用来实现找共同好友那种功能。
127.0.0.1:6379> sadd st 001
(integer) 1
127.0.0.1:6379> sadd st 001
(integer) 0
127.0.0.1:6379> sadd st 002 003 004
(integer) 3
127.0.0.1:6379> srem st 002
(integer) 1
127.0.0.1:6379> sismember st 002
(integer) 0
127.0.0.1:6379> sismember st 003
(integer) 1
127.0.0.1:6379> scard st
(integer) 3
127.0.0.1:6379> smembers st
1) "004"
2) "003"
3) "001"ZSet
ZSet(有序集合)和Set(集合)的使用场景类似,区别是Zset会根据提供的score参数自动排序。
当需要一个不重复且有序的集合列表时,可以选择ZSet。
Zset的每个元素都关联着一个分值(Score),这是一个浮点数格式的关联值。ZSet会根据分值按从大到小的顺序来排列各个元素。
zset也有两种不同的实现,分别是zipList和skipList
zipList:满足以下两个条件[score,value]键值对数量少于128个;
每个元素的长度小于64字节;
skipList:不满足以上两个条件时使用跳表、组合了hash和skipListhash用来存储value到score的映射,这样就可以在O(1)时间内找到value对应的分数;
skipList按照从小到大的顺序存储分数
skipList每个元素的值都是[socre,value]对
127.0.0.1:6379> zadd salary 1000 user001
(integer) 1
127.0.0.1:6379> zadd salary 2000 user002
(integer) 1
127.0.0.1:6379> zadd salary 3000 user003
(integer) 1
127.0.0.1:6379> zadd salary 4000 user004
(integer) 1
127.0.0.1:6379> type salary
zset
127.0.0.1:6379> zrank salary user004
(integer) 3
127.0.0.1:6379> zrem salary user004
(integer) 1
127.0.0.1:6379> zrank salary user004
(nil)
127.0.0.1:6379> zincrby salary 200 user002
"2200"
127.0.0.1:6379> zcard salary
(integer) 3
127.0.0.1:6379> zcount salary 1000 4000
(integer) 3
127.0.0.1:6379> zrangebyscore salary 1000 3000
1) "user001"
2) "user002"
3) "user003"应用场景
- 排行榜
- 带权重的队列,让重要的任务先执行
Redis的内部扩容机制
Redis是一个键值对数据库,Redis服务器中的所有数据保存在db数组中,数据库的结构是redis.h/redisDb,其中,redisDb结构的dict字典保存了数据库中的所有键值对,所以,说起Redis的扩容机制,指的是字典中的哈希表的rehash(重新散列)操作。
哈希表保存的键值对会逐渐地增多或者减少,当字典内数据过大时,会导致更多的键冲突。
当数据减少时,已经分配的内存还在占用,会造成内存浪费。
渐进式rehash 的详细步骤: (准确性待研究,暂时这么表述)
- 为ht[1] 分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
- 在几点钟维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash 开始
- 在rehash 进行期间,每次对字典执行CRUD操作时,程序除了执行指定的操作以外,还会将ht[0]中的数据rehash 到ht[1]表中,并且将rehashidx加一
- 当ht[0]中所有数据转移到ht[1]中时,将rehashidx 设置成-1,表示rehash 结束
采用渐进式rehash 的好处在于它采取分而治之的方式,避免了集中式rehash 带来的庞大计算量。
Redis怎样删除大Key
1. 非String的bigkey
Hash、ZSet、List、Set 日积月累越来越大,比如到GB了,如果直接使用del删除会导致长时间阻塞。
del命令在删除集合类型数据时,时间复杂度为O(M),M是集合中元素的个数。
Redis是单线程的,单个命令执行时间过长就会阻塞其他命令,容易引起缓存雪崩。
解决方案:
渐进式删除
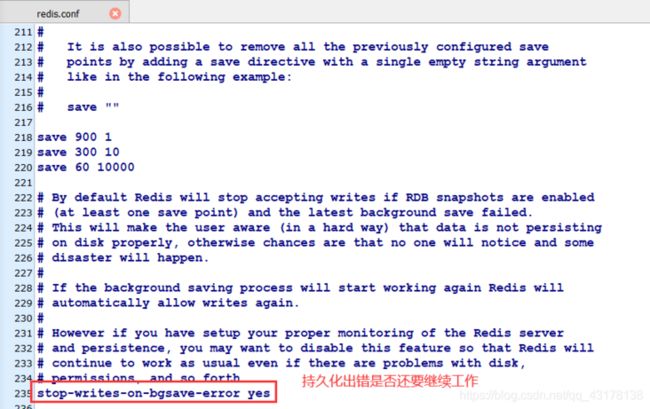
分批删除,通过
scan命令遍历大Key,每次取得少部分元素,对其删除,然后再获取和删除下一批元素。hscan、sscan、zscan。unlink:
unlink命令由Redis 4.0推出,在所有命名空间中把Key删除,立即返回,不阻塞;后台线程执行真正的释放空间的操作。
三种特殊数据类型
geospatial 地理位置
定位、距离计算。
geoadd
geopos
geodist
georadius
……Hyperloglog
HyperLogLog是一个专门为了计算集合的基数而创建的概率算法。(不重复的元素的个数)。
对于一个给定的集合,HyperLogLog可以计算出整个集合的近似基数:近似基数并非集合的实际基数,它可能会比实际的基数小一点或者大一点,但是估算基数和实际基数之间的误差会处于一个合理的范围之内。因此那些不需要知道实际基数或者因为条件限制而无法计算出实际基数的程序就可以把这个近似基数当作集合的基数来使用。
pfadd 对集合元素进行计数
pfcount 返回集合的近似基数
pfmerge 计算多个HyperLogLog的并集Bitmap
Redis的位图(bitmap)是由多个二进制位组成的数组,数组中的每个二进制位都有与之对应的偏移量(也称索引),用户通过对这些偏移量可以对位图中指定的一个或多个二进制位进行操作。
setmit 设置二进制位的值
>> setbit bitmap001 0 1
>> setbit bitmap002 10 1
getbit 获取二进制位的值
>> getbit bitmap001 0
bitcount 统计被设置的二进制位数量
bitpos 查找第一个指定的二进制位值Redis的事务 ✍
使用事务
Redis单条命令是保持原子性的,但事务是不保持原子性的。
一个事务中的所有命令都会被序列化,在事务执行的过程中,会按照顺序执行。
具有一次性、顺序性、排他性。
Redis事务没有隔离级别的概念。
所有的命令在事务中,并没有直接被执行,只有发起执行命令的时候才会执行 (Exec)
Redis的事务
- 开启事务(multi)
- 命令入队
- 执行事务(exec)
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set key1 hello
QUEUED
127.0.0.1:6379> set key2 world
QUEUED
127.0.0.1:6379> get key2
QUEUED
127.0.0.1:6379> set key3 hi
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) "world"
4) OK放弃事务:
> discard如果有编译时异常,就是有命令写错了,那全部命令都取消了。
如果有运行时异常(比如给字符串incr),除了错的,其他的依旧可以执行。
监控 乐观锁
悲观锁
- 认为什么时候都会出错,无论什么时候都会加锁
乐观锁
- 认为什么时候都不会出问题,所以不会上锁。更新的时候去判断是否有人修改过
- 获取version
- 更新的时候比较version
Redis监视测试:

上图是正常情况,exec提交执行然后出现结果。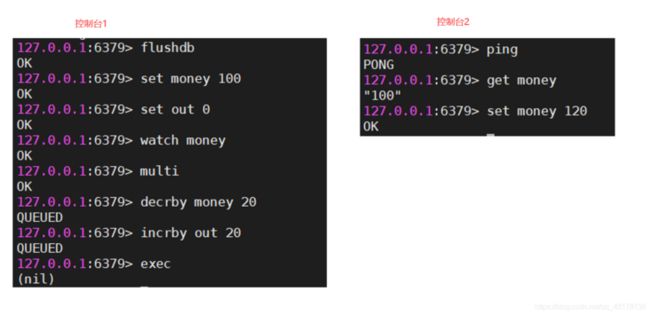
这里两个进程,在第一个进程还没提交事务之前,进程2修改了数据,所以进程1的数据提交不了,返回了nil。
使用watch可以当做redis的乐观锁操作。
解锁使用unwatch。
使用watch实现乐观锁:使用watch监视数据,在事务执行失败后,解锁,获取最新的值再次监视,再次开启事务。
Redis持久化 ✍
Redis作为一个内存数据库,持久化是必不不可少的。
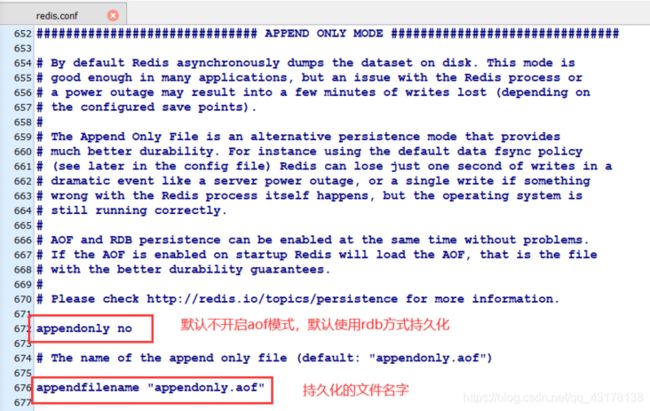
Redis持久化有两种方式:
- RDB:RDB持久化机制,是对Redis中的数据执行周期性的持久化。
- AOF:AOF机制对每条写入命令作为日志,以
append-only的模式写入一个日志文件中,在Redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集。
通过RDB或AOF,都可以将Redis内存中的数据给持久化到磁盘上面来,还可以将数据备份到别的地方。
如果Redis挂了,可以将备份放到指定目录中重启Redis,Redis就会自动根据持久化文件恢复内存中的数据。
如果同时使用RDB和AOF两种持久化机制,那么在Redis重启的时候,会使用AOF来重新构建数据,因为AOF中的数据更加完整。
RDB
RDB持久化功能所生成的RDB文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件时的数据库状态。
RDB文件的创建与载入
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。
SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器阻塞期间,服务器不能处理任何命令请求:
redis> SAVE //等待直到RDB文件创建完毕
OK和SAVE命令直接阻塞服务器进程的做法不同,BGSAVE命令会派生(fork)出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求:
redis> BGSAVE //派生子进程,并由子进程创建RDB文件BGSAVE命令执行期间,SAVE命令会被拒绝、BGSAVE也会被拒绝。
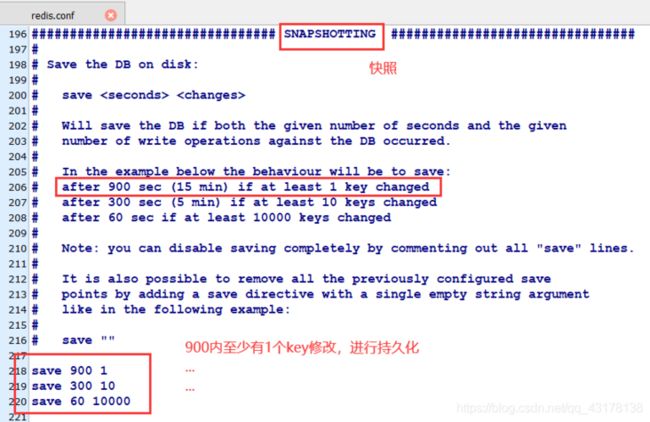
自动间隔性保存
因为BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器配置的save选项让服务器每隔一段时间自动执行一次BGSAVE命令。
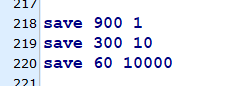
只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行:
- 服务器在900秒内对数据库进行了至少1次修改
- 服务器在300秒内对数据库进行了至少10次修改
- 服务器在60秒内对数据库进程了至少10000次修改
AOF
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态。
AOF持久化的实现
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
当AOF持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾。
RDB、AOF对过期键的处理
对于RDB,在执行SAVE或BGSAVE命令时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的RDB文件中。
对于AOF,某个键过期但还没被惰性删除或定期删除,AOF文件不会因为这个过期键而产生任何影响。
当过期键被惰性删除或定期删除后,程序会向AOF文件追加一条DEL命令。
RDB优缺点 ⚙
- RDB会产生多个数据文件,每个数据文件代表某一个时刻中Redis的数据,这种模式非常适合做冷备(非实时,定期备份)。
- RDB对Redis对外提供的读写服务,影响非常小,可以让Redis保持搞性能,因为fork了一个子进程。
- 基于RDB恢复比AOF更快。
- 希望尽可能少丢数据,RDB没有AOF好。
- RDB在fork子进程来执行RDB快照数据文件生成的时候,如数据文件特别大,可能导致对客户端提供的服务暂停数毫秒甚至秒。
AOF优缺点 ⚙
- AOF可以更好地保证数据不丢失,一般AOF会每间隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
- AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能高,就算文件尾部破损也比较容易修复。
- AOF日志文件过大的时候,出现后台重写操作,也不会影响客户端的读写,在rewrite log的时候,会对其中指令进行压缩。在创建新日志文件时,老日志文件还是照常写入,当新的merge后的日志文件ready的时候,再交换新老日志文件即可。
- AOF日志文件的命令通过可读较强的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如不小心flushall了,可以立即拷贝AOF文件,将最后一条flushall命令删除,将AOF文件放回去,就可以通过恢复机制自动恢复。
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大。
- AOF开启后,支持的写QPS(每秒请求数)会比RDB支持的写QPS低,因为AOF会配置成每秒fsync一次日志文件。
以前AOP发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说类似AOF这种较为复杂的基于命令日志/merge/回放的方式,比RDB完整数据快照的方式要脆弱一些,容易有bug。AOF为了避免rewrite导致的bug,所以都是基于当时内存中的数据进行指令的重新构建。
RDB和AOF如何抉择
- 不要仅仅使用RDB,会导致丢失很多数据
- 也不要仅仅使用AOF,AOF做冷备没有RDB做冷备的恢复速度快;RDB每次简单粗暴生成数据快照,更加健壮。
- Redis支持同时开启两种持久化方式,可以综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择;用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。
内存淘汰策略
每进行一次redis操作的时候,redis都会检测可用内存,判断是否要进行内存淘汰,当超过可用内存的时候,我们就会使用对应策略,默认是no-eviction
noeviction:该策略对于写请求不再提供服务,会直接返回错误,排除del等特殊操作allkeys-random:从redis中随机选取key进行淘汰allkeys-lru:从redis中选取使用最少的key进行淘汰volatile-random:从redis中设置过过期时间的key,进行随机淘汰volatile-ttl:从redis中选取即将过期的key,进行淘汰volatile-lru:从redis中设置过过期时间的key中,选取最少使用的进行淘汰
config get maxmemory-policy //获取当前内存淘汰策略
config set maxmemory-policy valatile-lru //通过命令修改淘汰策略想永久配置还是要在配置文件里改~
发布和订阅 ✍
Redis的发布与订阅功能可以让客户端通过广播方式,将消息(message)
同时发送给可能存在的多个客户端,并且发送消息的客户端不需要直到接收消息的客户端的具体信息。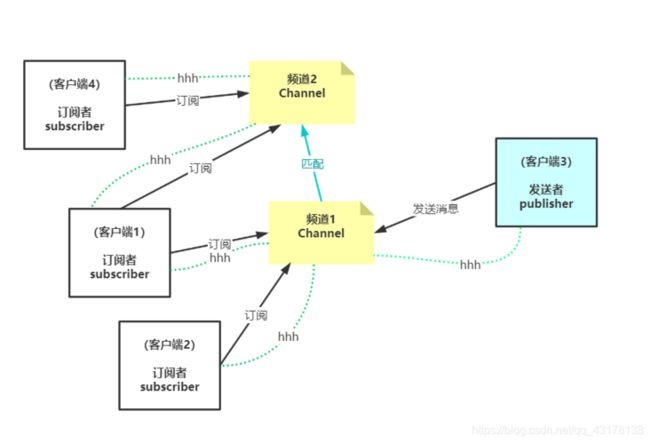
PUBLISH、SUBSCRIBE
publish命令将一条消息发送给指定频道,publish命令会返回接收到消息的客户端数量作为返回值。
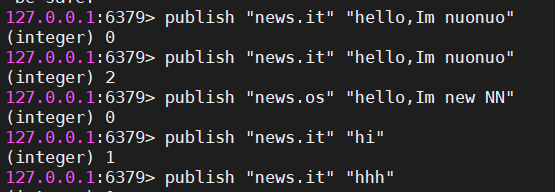
publish命令从Redis 2.0.0版本开始可用。
subscribe命令让客户端订阅一个或多个频道,subscribe命令在每次成功执行订阅一个频道之后,都会向执行命令的客户端返回一条订阅消息,消息包含了被订阅成功的频道以及客户端目前已订阅的频道数量。
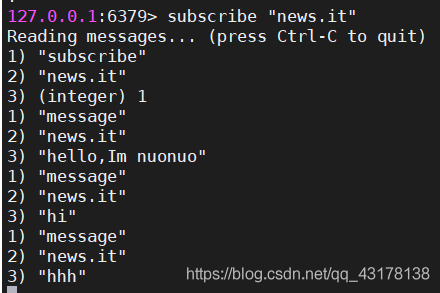
当客户端成为频道的订阅者之后,就会接收到来自被订阅频道的消息,这些消息成为频道消息。
和订阅消息一样,由3个元素组成:
- message ,表示这是一条频道消息并非订阅消息
- 消息的来源频道
正文,消息的真正内容
UNSUBSCRIBE
虽然Redis提供了退订的命令,但是Redis自带的命令行客户端redis-cli在执行subscribe命令之后就会进入阻塞状态,无法再执行其他任何命令,实际上根本用不上subscribe命令。
一些编程语言为发布和订阅提供了更好的支持,也可以使用unsubscribe。PSUBSCRIBE PUNSUBSCRIBE
想要订阅所有带有"news."前缀的频道的消息:
redis> psubscribe "news.*"想要退订 "news." 模式的频道:
redis> punsubscribe "news.*" redis> punsubscribe //退订所有的模式PUBSUB
redis> pubsub channels [pattern] //查看被订阅的频道 [pattern]="news.*" redis> pubsub nunsub [channel channel ...] //查看频道的订阅者数量 redis> pubsub numpat //查看被订阅模式的总数量