来自公众号: Gopher指北
我内心一直有一个欲望,想要高声呼喊“我胡汉三又回来了”,而现在就是合适的时机。
正式开干之前有点手生,太久没有写技术类的文章,总有点怠惰,不得不说坚持确实是一件很难的事情。如果不是因为愧疚和写点东西能让自己稍微平静下来一些,我可能还将继续怠惰下去。
另外还有一件很有意思的事情分享一下。前一篇在公众号上的文章仅思考就花了近一个月,写只花了一天,而技术文章我一般边思考边写平均耗时一周。结果是不会骗人的,前一篇文章阅读量首次突破一千,果然这届读者的思想深度至少也有一个月那么多,老许佩服佩服。

切片底层结构
切片和结构体的互转
其他不扯多了,我们还是回归本篇主题。 在正式了解切片底层结构之前, 我们先看几行代码。
type mySlice struct {
data uintptr
len int
cap int
}
s := mySlice{}
fmt.Println(fmt.Sprintf("%+v", s))
// {data:0 len:0 cap:0}
s1 := make([]int, 10)
s1[2] = 2
fmt.Println(fmt.Sprintf("%+v, len(%d), cap(%d)", s1, len(s1), cap(s1))) // [0 0 2 0 0 0 0 0 0 0], len(10), cap(10)
s = *(*mySlice)(unsafe.Pointer(&s1))
fmt.Println(fmt.Sprintf("%+v", s)) // {data:824634515456 len:10 cap:10}
fmt.Printf("%p, %v\n", s1, unsafe.Pointer(s.data)) // 0xc0000c2000, 0xc0000c2000
在上述代码中,通过获取切片的地址,并将其转为*mySlice, 成功获得了切片的长度和容量。以及一个类似于指针一样的东西。而这个指针就是指向存储真实数据的数组,下面我们来进行验证。
//Data强转为一个数组
s2 := (*[5]int)(unsafe.Pointer(s.data))
s3 := (*[10]int)(unsafe.Pointer(s.data))
// 修改数组中的数据后切片中对应位置的值也发生了变化
s2[4] = 4
fmt.Println(s1) // [0 0 2 0 4 0 0 0 0 0]
fmt.Println(*s2) // [0 0 2 0 4]
fmt.Println(*s3) // [0 0 2 0 4 0 0 0 0 0]到这里,切片的底层结构已经呼之欲出了,不过为了做更进一步的验证,我们继续测试结构体转为切片的过程。
var (
// 一个长度为5的数组
dt [5]int
s4 []int
)
s5 := mySlice{
// 将数组地址赋值给data
data: uintptr(unsafe.Pointer(&dt)),
len: 2,
cap: 5,
}
// 结构体强转为切片
s4 = *((*[]int)(unsafe.Pointer(&s5)))
fmt.Println(s4, len(s4), cap(s4)) // [0 0] 2 5
// 修改数组中的值, 切片内容也会发生变化
dt[1] = 3
fmt.Println(dt, s4) // [0 3 0 0 0] [0 3]通过上述三段代码,我们将切片的底层结构以结构体的形式更加清晰的表达出来。如下图所示,其中第一部分(Data)为指向数组的地址,第二部分(Len)为切片的长度即数组已使用的长度, 第三部分(Cap)为数组的长度。
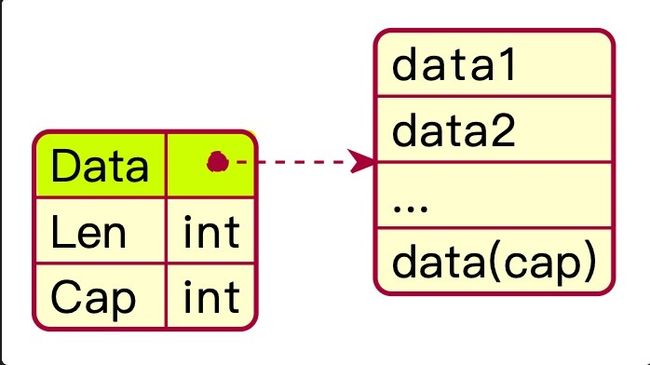
小结:切片是对数组的包装,底层仍使用数组存储数据。
额外再多说一嘴:
reflect包要操作切片时通过
reflect.SliceHeader结构体,详见https://github.com/golang/go/...runtime对切片进行扩容时使用
slice结构体, 详见https://github.com/golang/go/...
unsafe题外话
在前一部分的Demo中几乎离不开unsafe包的使用。当然本篇并不是介绍此包的用法,只是作为一个题外话简单看一下它为什么不安全。
func otherOP(a, b *int) {
reflect.ValueOf(a)
reflect.ValueOf(b)
}
var (
a = new(int)
b = new(int)
)
otherOP(a, b) // 如果注释此函数调用,最终输出结果会发生变化
*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(a)) + unsafe.Sizeof(int(*a)))) = 1
fmt.Println(*a, *b)上述代在是否注释otherOP时,其输出结果是不一致的。
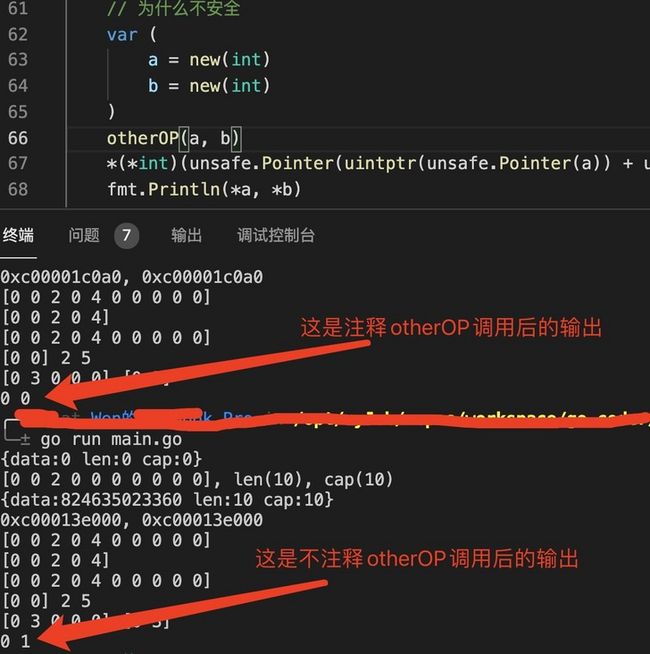
当变量逃逸至堆上时变量a和变量b内存地址相邻,故能够通过a变量地址去设置b变量的值。当未逃逸到堆上时,设置变量b的值并未生效,如此我们根本无法得知修改了哪一块儿内存的值,这种不确定性在老许看来即是我们需要慎重使用此包的原因。
关于上述demo的补充解释:
- reflect.ValueOf会调用底层的escapes方法以保证对象逃逸到堆中
- Go中采用按大小分割的空闲链表内存分配器以及多级缓存,故a,b变量在大小一致且本demo变量较少的的情况下很有可能被分配到连续的内存空间中
创建切片
创建切片方式有四种。第一种直接通过var进行变量声明,第二种通过类型推导,第三种通过make方式去创建,第四种通过切片表达式创建。
// 通过变量声明的方式创建
var a []int
// 类型推导
b := []int{1, 2, 3}
// make创建
c := make([]int, 2) // c := make([]int, 0, 5)
// 切片表达式
d := c[:3]上述例子中,前三种没什么特别好说的,老许主要介绍一下第四种,以及它的相关限制和注意事项。
简单的切片表达式
对于字符串、数组、数组指针和切片(切片指针不能使用下面的表达式)均可使用下面的表达式:
s[low:high] // 生成的切片长度为high-low通过上述表达式可创建新的子串或者切片。特别注意的是,对字符串使用此表达式时既不是生成字符串切片也不是生成字节切片而是生成子字符串。另外,老许在go中字符串的编码问题中提到Go中的字符串存储的就是utf8字节切片,所以我们在使用此方法获取包含中文等特殊字符时有可能会出现意想不到的结果。正确得到子串的方式应该是先转为rune切片再截取。
上述表达式已经可以十分方便地创建新的切片,然而更加方便地是low和high还可以省略。
s[2:] // same as s[2 : len(a)]
s[:3] // same as s[0 : 3]
s[:] // same as s[0 : len(a)]下标限制
对不同的类型使用切片表达式,low和high的取值范围不同。对于字符串和数组/数组指针而言,low和high的取值范围为0 <= low <= len(s)。对于切片而言,low和high的取值范围为0 <= low <= cap(s)。在切片面试题系列一中正是对此知识点的考察。
切片容量
通过切片表达式生成的切片,其底层数组共享,因此切片的容量为底层数组的长度减去low。由此可以推断下述代码输出结果为3 8和3 13。
var (
s1 [10]int
s2 []int = make([]int, 10, 15)
)
s := s1[2:5]
fmt.Println(len(s), cap(s))
s = s2[2:5]
fmt.Println(len(s), cap(s))
return完整的切片表达式
说实话这种方式真的不常用,虽然它可以控制切片的容量,但老许在实际开发中并未使用过。其完整表达式如下:
s[low : high : max]这种表达式有几个需要注意的点分别是:
- 只适用于数组、数组指针和切片不适用于字符串。
- 和简单切片表达式不同的是,它只能忽略
low这个下标且忽略后该下标默认值为0。 - 和简单切片表达式一样,通过完整切片表达式生成的切片底层数组共享
下标限制
对数组/数组指针而言,下标取值范围为0 <= low <= high <= max <= len(s)。对切片而言,下标取值范围为0 <= low <= high <= cap(s)。在切片面试题系列二中正是对此知识点的考察。
切片容量
前面提到此切片表达式可以控制切片的容量。在low一定的情况下,通过改变max在允许范围内的值即可改变切片的容量,其容量计算方式为max - low。
切片扩容
runtime/slice.go文件的growslice函数实现了切片的扩容逻辑,在正式分析内部逻辑之前我们先看看growslice的函数签名:
type slice struct {
array unsafe.Pointer
len int
cap int
}
func growslice(et *_type, old slice, cap int) slice第一个参数_type是Go语言类型的运行时表示,其中包含了很多元信息,例如:类型大小、对齐以及种类等。
第二个参数为待扩容切片的信息。
第三个参数为真实需要的容量,即原容量和新增元素数量之和,老许对其简称为所需容量。为了更加容易理解所需容量的含义,我们先看一段代码:
s := []int{1,2,3} // 此时切片长度和容量均为3
s = append(s, 4) // 此时所需容量为3 + 1
s1 := []int{1,2,3} // 此时切片长度和容量均为3
s1 = append(s1, 4, 5, 6) // 此时所需容量为3 + 3扩容逻辑
有了上面的概念之后,下面我们看看切片扩容算法:
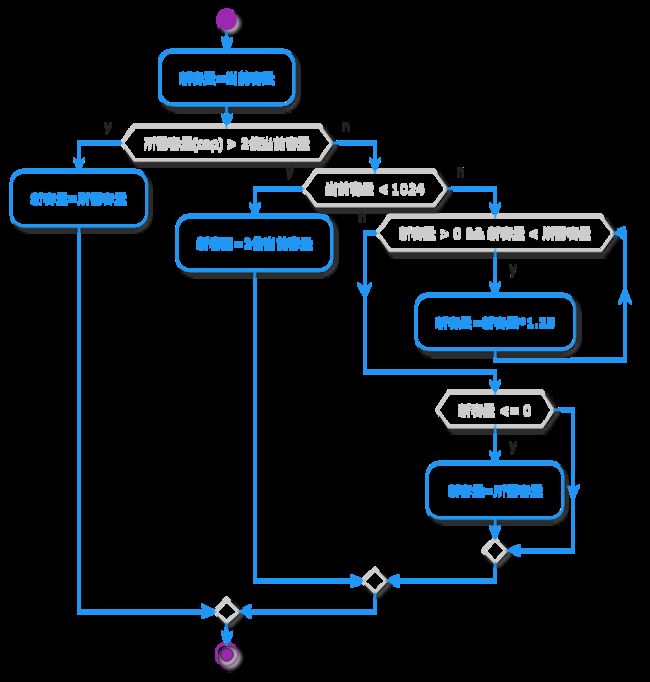
上图逻辑总结如下:
首先,如果所需容量大于2倍当前容量则新容量为所需容量。
其次,判断当前容量是否大于1024。如果当前容量小于1024则新容量等于2倍当前容量。如果当前容量大于等于1024则新容量循环增加1/4倍新容量直到新容量大于等于所需容量。
老许在这里特别提示,和0的比较是有用的。初始时,老许也觉得这逻辑十分多余,后来有一天突然顿悟,这实际上是对整形溢出的判断。因为平时开发中很少会考虑这个问题,一时间惊为天人。也许我们和大神之间的代码差距仅仅是少了对溢出的判断。
另外一个有意思的事情是,切片的逻辑最开始也不是这样的。这逻辑并不复杂,即使是刚入门的人写起来也毫无压力。然而即便是这样简单的逻辑,也是经过多个版本的迭代才有了如今的模样。
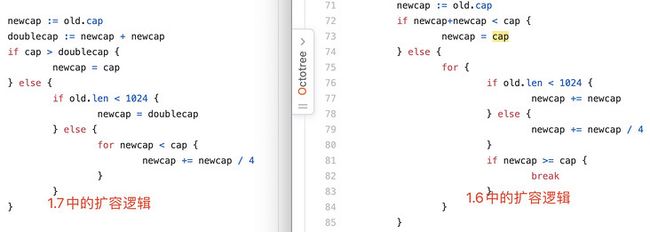
有一说一,在老许看来1.6中的扩容逻辑并不算优雅。想到这儿,一种“我赢了”的感觉油然而生,程序猿的快乐就是如此简单。
计算内存容量
前文中的扩容逻辑是理想的内存分配容量,而真实的内存分配十分复杂。在Go1.6中切片扩容分配内存时分为四种情况,分别是类型大小为1字节、类型大小为指针大小、类型大小为2的n次幂和其他。而切片扩容分配内存时在不同的Go版本中又略有不同,这里只介绍1.16中类型大小为2的n次幂时内存分配。
下面直接上代码:
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
// et.size = 1 << n
// shift = n
// &63是因为uint64中1最大左移63,再大就溢出了
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}上述代码中,通过对指针大小判断以区分当前运行的是32位还是64位平台。Ctz64和Ctz32函数是针对不同类型计算最低位0的个数。又因为类型大小是2的n次幂,则0的个数即为n。
类型大小为2的n次幂,则类型大小一定为 1 << n,因此计算最低位0的个数即可得到左移的位数。
源码中通过
x&(x-1) == 0表达式判断一个无符号整数是否为2的n次幂。我们平时开发中如果有类似的逻辑,请参考切片扩容源码开始装逼之旅。
接下来是计算内存容量的逻辑:
capmem = roundupsize(uintptr(newcap) << shift)
newcap = int(capmem >> shift)结合前文易知,uintptr(newcap) << shift实际上可以理解为uintptr(newcap) * et.size,capmem >> shift可理解为capmem / et.size。uintptr(newcap) << shift是最理想的所需内存大小,而实际分配内存时因为内存对齐等问题无法达到理想状况,所以通过roundupsize计算出实际需要的内存大小,最后再计算出真实容量。有了这个理解之后我们接下来着重分析roundupsize函数。
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}上面函数有很多含义不清楚的变量,老许接下来会对其一一解释。
_MaxSmallSize: 其值为32768,即32kb大小。在Go中,当对象大小超过32kb时,内存分配策略和小于等于32kB时是有区别的。
smallSizeMax: 其值为1024字节。
smallSizeDiv: 其值为8字节。
largeSizeDiv: 其值为128字节。
_PageSize: 8192字节,即8kb大小。Go按页来管理内存,而每一页的大小就为8kb。
class_to_size: Go中的内存分配会按照不同跨度(也可理解为内存大小)将内存分割成不同内存块链表。当需要分配内存时,按照对象大小去匹配最合适的跨度找到空闲的内存块儿。Go中总共分为67个跨度,class_to_size是一个长度为68的数组,分别记录0和这67个跨度的值。源码详见sruntime/izeclasses.go。
size_to_class8: 这是一个长度为129的数组,代表的内存大小区间为0~1024字节。以索引i为例,此位置的对象大小m为i * smallSizeDiv,size_to_class8[i]的值为class_to_size数组中跨度最接近m的下标。
size_to_class128:这是一个长度为249的数组,代表的内存大小区间为1024~32768字节。以索引i为例,此位置的对象大小m为smallSizeMax + i*largeSizeDiv, size_to_class128[i]的值为class_to_size数组中跨度最接近m的下标。
divRoundUp: 此函数返回a/b向上舍入最接近的整数。
alignUp: alignUp(size, _PageSize) = _PageSize * divRoundUp(size, _PageSize)。
最终将计算实际需要内存大小的逻辑表示如下:
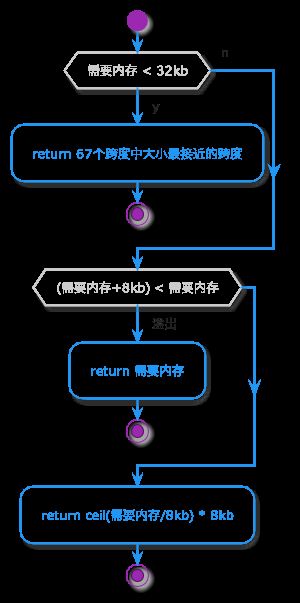
到这里,切片扩容的核心逻辑就已经分析完毕。本篇不对类型大小为1字节、类型大小为指针大小以及其他大小进行扩容逻辑分析的原因是整体逻辑差别不大。在老许看来源码中对类型大小区分的主要目的是为了尽可能减少除法和乘法运算。每每阅读这些优秀的源码都令老许直呼细节怪物。
为了加深印象我们以切片面试题系列三中的一个例子进行一次演算。
s3 := []int{1, 2}
s3 = append(s3, 3, 4, 5)
fmt.Println(cap(s3))根据前文知,所需容量为5,又因所需容量大于2倍当前容量,故新容量也为5。
又因为int类型大小为8(等于64位平台上的指针大小),所以实际需要的内存大小为5 * 8 = 40字节。而67个跨度中最接近40字节的跨度为48字节,所以实际分配的内存容量为48字节。
最终计算真实的容量为48 / 8 = 6,和老许实际运行输出一致。
最后,衷心希望本文能够对各位读者有一定的帮助。
注:
- 写本文时, 笔者所用go版本为: go1.16.6
- 文章中所用完整例子:https://github.com/Isites/go-...