一、前言
所谓埋点,是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程,为进一步优化产品或制定有针对性的运营计划提供数据支撑。
埋点的实质,是先监听软件应用运行过程中的关键节点,当需要关注的事件发生时进行判断和捕获,获取必要的上下文信息,最后将信息整理后发送至指定的服务端。
神策分析 iOS SDK,是一款轻量级用于 iOS 端的数据采集埋点 SDK。神策分析 iOS SDK 不仅有代码埋点功能,还有通过使用运行时机制(Runtime)中的相关技术实现 iOS 端的全埋点(无埋点、无码埋点、无痕埋点、自动埋点)、点击图、可视化全埋点等功能。
其中,代码埋点是最基本也是最重要的埋点方式,适用于需要精准控制埋点位置、灵活的自定义事件和属性等精细化需求的场景。下面针对神策分析 iOS SDK 代码埋点进行详细的介绍,希望能够给大家提供一些参考。
二、实现原理
在介绍代码埋点的实现原理之前,我们先来看下完整的数据采集流程,希望大家可以了解代码埋点在数据采集流程中的作用。
2.1 数据采集流程
数据采集流程中主要包括事件采集、添加属性、事件入库、读取上报等流程,详细的步骤如下所示:
在产品、服务转化的某些关键点,调用埋点相关接口采集事件;
获取有意义的属性丰富该事件,保证数据的广度与深度;
数据采集完成,转换成标准 JSON 数据格式,以队列的形式存储到 SDK 的数据库内;
定时读取数据库中的数据,封装请求并上报数据,并在上报成功后,删除数据库内存储的已上报数据。
整体流程如图 2-1 所示: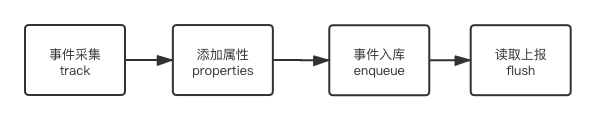
图 2-1 数据采集流程图
从图中可以看出,代码埋点位于数据采集流程的第一步,是数据采集流程中最关键的步骤。数据采集是否丰富、准确、及时,都直接影响整个数据分析平台的使用效果。
2.2原理介绍
代码埋点的实现原理比较简单,主要是初始化 SDK 之后,在某个事件发生时调用 - track: 或 - track:withProperties: 等相关接口,将触发的事件和属性保存到数据模型中(SDK 中使用的是 NSDictionary 类型的数据模型)。并将数据模型转化为 JSON 串,存储到本地数据库中。然后,按照发送策略将数据发送到指定的服务端。例如:我们想统计 App 里面某个按钮的点击次数,可以在这个按钮对应的点击方法里面调用 SDK 提供的接口来采集事件。
三、具体实现
在神策分析中,我们使用事件模型(Event)来描述用户在产品上的各种行为,这也是神策分析中所有接口和功能设计的核心依据。简单来说,一个 Event 就是描述了一个用户在某个时间点、某个地方、以某种方式完成了某个具体的事情。可以看出,一个完整的 Event,包含如下的几个关键因素:
Who:参与事件的用户是谁;
When:事件发生的实际时间;
Where:事件发生的地点;
How:用户从事事件的方式;
What:描述用户所做事件的具体内容。
对于 SDK 来说,记录用户行为数据的接口主要考虑的就是上面这五个因素。不难看出,接口的主要功能是:在业务特定时机被调用,传入事件名与想要记录的属性或者其他必要参数,然后将事件记录下来。
3.1 接口设计
一个设计良好的接口,应该在输入一组合理的数据时,能够在有限的运行时间内得到正确的结果;对不合理的数据输入,有足够的反应和处理能力。参照这个思想,我们来设计记录用户行为数据的接口。
首先考虑接口暴露的部分。开发者在使用一个接口的时候,主要会注意以下几点:
接口名:接口名要足够精确,能用言简意赅的语言描绘出该接口的功能。针对要实现的功能,我们把这个接口命名为 - track:withProperties: ;
参数列表:通过上述的介绍可以知道,方法调用时机可以作为事件(Event)的发生时间(When),此外我们仍需外界提供的是事件具体内容(What)与从事方式(How),即事件名(参数 event 表示)与事件属性(参数 properties 表示);
返回值:通过该接口记录的用户行为数据最终需要上报到指定的服务端,所以该方法的返回值应符合指定的服务端所要求的格式。一般来说,数据为 JSON 格式,物理上对应一条数据,逻辑上对应一个描述了用户行为的事件。
基于上述三点,我们的接口定义如下:
Plain Text
1
(NSString )track:(NSString )event withProperties:(NSDictionary *)properties;
3.2 事件模型的关键因素
通过上述的介绍可以知道,事件模型(Event)中包含五个关键因素,下面就详细介绍下在代码埋点中如何获取这五个关键因素。
3.2.1 用户标识
用户的唯一标识,这里用 distinct_id 表示。简单来说,在用户未登录的情况下,SDK 会选取设备 ID 作为唯一标识,而登录状态下会选取登录 ID 作为唯一标识,即一个用户既有设备 ID(亦称作 “匿名 ID”)又有登录 ID,通过 “用户关联” 可以将同一个用户的设备 ID 和登录 ID 关联到一起。这样,不管用户是匿名状态还是登录状态发生的行为,我们都能准确识别到是同一个用户,这是目前为止较为通用且准确的用户标识方式。
1.设备 ID
大部分情况下,一个用户只有一台设备,因此可以获取其设备的 ID 来作为用户标识。具体到 iOS,我们可用的是 IDFA、IDFV 或者 UUID。
IDFA:英文全称是 Identifier For Advertising,是广告标识符的缩写,主要用于广告推广、换量等跨应用的设备追踪等。在同一个 iOS 设备上,同一时刻,所有的应用程序获取到的 IDFA 都是相同的。在 iOS 10 之后,若用户限制了广告追踪(【设置】→ 【隐私】→【广告】→【限制广告追踪】),我们获取到的 IDFA 将是固定的一串零:00000000-0000-0000-0000-000000000000;
IDFV:英文全称是 Identifier For Vendor,是应用开发商标识符的缩写,是给应用开发商标识用户使用的,主要适用于分析用户在同一应用开发商不同应用间的行为等。在重启设备之后和解锁设备之前,可能获取不到此值;
UUID:英文全称是 Universally Unique Identifier,是通用唯一标识符的缩写,能让你在任何一个时刻,在不借助任何服务器的情况下生成唯一标识符。也就是说,UUID 在某一特定的时空下是全球唯一的。若 IDFA 和 IDFV 都获取不到,则我们会生成一个 UUID,作为该设备的 ID。
结合实际情况来看,对于常规数据分析中的设备 ID,可按照 IDFA → IDFV → UUID 优先级顺序获取,基本上能满足我们的业务需求。
另外,为了防止限制广告追踪、卸载重装等可能导致设备 ID 改变的情况,SDK 会将设备 ID 存储到 KeyChain 和沙盒中,在一定程度上避免这个问题。因此,获取设备 ID 的流程如图 3-1 所示:

图 3-1 获取设备 ID 的流程图
2.登录 ID
一般情况下,在业务后台系统中会使用登录 ID 来标识用户,它识别用户非常准确,但是无法识别未登录状态的用户。
在 SDK 中,通过调用 - login: 接口并传入登录 ID,即可完成 “用户关联”,将同一个用户的设备 ID 和登录 ID 关联到一起。
3.唯一标识
在 SDK 中,我们将设备 ID 定义为 anonymousId,登录 ID 定义为 loginId,用户唯一标识定义为 distinctId。 获取 distinctId 的逻辑如下:
若 loginId 不为空且长度不为 0,则返回 loginId;
若 loginId 为空,则返回 anonymousId。
3.2.2 触发时间
在 SDK 的埋点相关接口中,使用 time 字段来记录事件发生的时间(单位是毫秒)。若传入的 properties 中不包含 time 字段的话,则会自动获取当前时间作为 time 字段的值,如下面代码所示:
Plain Text
1
NSNumber timeStamp = @([[NSDate date] timeIntervalSince1970] 1000);
3.2.3 触发地点
可以从三个方面来采集位置信息:
神策系统会自动根据请求的 ip 来解析相应的省份($province)和城市($city),因此 SDK 并不需要处理这两个属性;
SDK 可通过 CoreLocation 框架自动采集经度($longitude)和纬度($latitude),可以在初始化 SDK 后调用 - enableTrackGPSLocation: 方法进行开启;
开发者也可以设置一些其它地域相关的字段。例如:国家(country)、社区(HousingEstate)等。
3.2.4 从事方式
用户从事这个事件的方式。这个概念比较宽泛,包括用户使用的设备、浏览器、App 版本、操作系统版本、进入的渠道、跳转过来时的 referer 等。目前,神策分析预置了部分字段用来描述这类信息,称为预置属性。同时,开发者也可以根据自己的需要来增加相应的自定义字段。
3.2.5 事件内容
描述用户所做事件的具体内容。主要是使用事件名称(event),来对用户所做的内容进行初步的分类。除了 event 这个至关重要的字段以外,我们并没有设置太多预置字段,需要开发者根据每个产品以及每个事件的实际情况和分析的需求,来进行具体的设置。
3.3 事件属性
事件触发时除了传入的自定义属性以外,还有一些特殊的属性,可由 SDK 预先采集。例如:页面标题($title)、屏幕宽高($screen_height、$screen_width )等,我们称之为预置属性。由于这些属性是由 SDK 自动采集的,不需要开发者增加代码,因此极大地增加了数据采集的范围和便利性。而采集的预置属性本身,是数据分析中涉及到的重要分析纬度,极大降低了开发和采集的成本,是可以拿来即用的部分。
另外,如果所有事件中都需要某些相同的属性,则可以把这些属性注册为公共属性。
以上两种特殊的事件属性,都可以在一定程度上节约埋点成本。接下来我们将介绍这两个属性的实现方案。
3.3.1 预置属性
考虑到 SDK 的活跃期基本上可确定为 “初始化” 与 “事件触发” 这两个时机,所以预置属性也根据采集时机,大致分为两类:
SDK 初始化时采集:初始化时即可确定该属性的值,随后在本次 App 生命周期中不会再改变;
事件触发时采集:调用 - track:withProperties: 时才可确定的属性。
1.初始化时采集的属性
最容易想到的,也是最优的方案:在 SDK 初始化时创建一个存储属性的模型(可以使用 NSDictionary 类型),命名为 automaticProperties,采集相应属性置入其中,并由 SDK 持有该模型。随后,在每次事件触发时,将该模型中的值添加入属性中即可。采集的预置属性如表 3-1 所示:
表 3-1 初始化时采集的预置属性列表
2.触发事件时采集的属性
由于一些预置属性,在 App 的整个生命周期中可能发生变化,更强调实时性,因此需要在事件触发时采集,典型代表就是之前已介绍的事件触发时间(When)与地点(Where)。事件触发时采集的预置属性如表 3-2 所示:
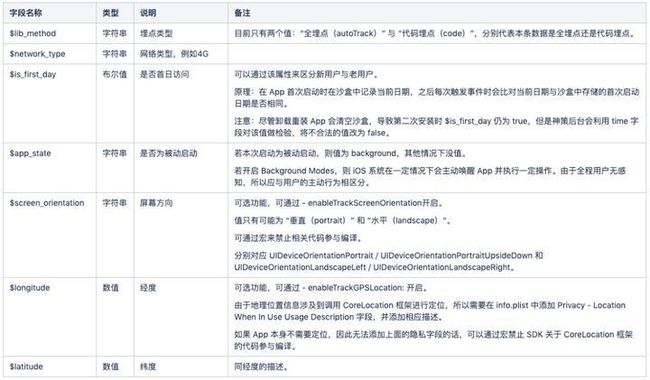
表 3-2 事件触发时采集的预置属性列表
3.3.2 公共属性
有些属性是我们希望每个事件都带上,但不属于预置属性,相当于公共的自定义属性。对于这些属性,SDK 提供了两种不同的方式来设置,即 “静态” 与 “动态” 公共属性。
静态公共属性在一次 App 生命周期中一般都是固定的;而动态公共属性则相反,只有事件触发的那一刻采集到的值才有意义。这实际上也对应了预置属性的两个采集时机。例如:
应用名称,在一次 App 生命周期中一般都是固定的,因此可以设置为静态公共属性;
当前游戏等级、最新金币余额。显然每次采集时这些值都是变化的,但仍然属于公共属性的范畴。这时候就可以使用动态公共属性。
1.静态公共属性
根据上面的分析,静态公共属性可以这样实现:对外提供一个注册静态公共属性的接口,开发者在 SDK 初始化时通过该接口注册静态公共属性,之后在事件触发时,将静态公共属性添加进去。
根据 “在一次 App 生命周期中一般都是固定的” 这个特点,静态公共属性存储到内存中即可。但是在实践中,有些静态公共属性在 SDK 初始化时并不能确定,需要经过网络请求或者其他操作后才能被注册。这样也就导致在注册静态公共属性之前的那部分事件,是没有静态公共属性的。如果每次 App 启动后都要重复一遍上述操作,会导致有大量的事件带不上静态公共属性,这显然是有问题的。因此 SDK 也将注册的静态公共属性持久化,并在 SDK 初始化时取出持久化的这部分静态公共属性,提前了静态公共属性的注册时间,解决了大部分问题。不过,删除静态公共属性时也需要同步清除本地持久化的内容。
注册静态公共属性的代码如下:
Plain Text
1
[[SensorsAnalyticsSDK sharedInstance] registerSuperProperties:@{@"superKey":@"superValue"}];
2.动态公共属性
动态公共属性会在每次事件触发时采集,适用于会经常发生变化的属性。因此,在 SDK 中动态公共属性是通过回调(block)来实现的。完整的流程如下:
在 SDK 初始化时,或者其他符合业务的时机,注册回调;
回调中实现属性的采集逻辑,并返回采集的属性;
在事件触发时,调用该回调方法,并将其返回的属性添加到事件属性中。
由于动态公共属性的回调方法在每次事件触发时都会被调用,因此不建议在该回调方法中添加过多的业务逻辑。注册动态公共属性的代码如下:
[[SensorsAnalyticsSDK sharedInstance] registerDynamicSuperProperties:^NSDictionary
3.4 数据校验
数据校验的内容分为:
参数是否为空、类型是否正确等;
参数是否符合神策的数据格式要求。神策使用统一的数据格式,因此任何自定义内容都应经过校验来保证输出的 JSON 是符合要求的。具体而言,是对事件名、自定义属性、静态公共属性、动态公共属性等做校验。
数据校验的时机分为:
静态公共属性应在被注册的时候检查;
动态公共属性与自定义属性应在事件触发时检查。
3.4.1 基本限制
事件名(event 的值)和 属性名(properties 中 key 的取值)都需是合法的变量名,即不能以数字开头,同时只能包含:大小写字母、数字、下划线和 $。另外,事件名和属性名最大长度都为 100。上述限制条件在 SDK 中是通过正则表达式来实现的。
SDK 预留了部分字段作为预置事件与属性名,自定义事件与属性都需要避免相同,判断事件名和属性名是否合法的代码如下所示:
Plain Text
1
(BOOL)isValidName:(NSString *)name {
2
// 保留字段通过字符串直接比较,效率更高
3
NSSet *reservedProperties = [NSSet setWithObjects:@"date", @"datetime", @"distinct_id", @"event", @"events", @"first_id", @"id", @"original_id", @"device_id", @"properties", @"second_id", @"time", @"user_id", @"users", nil];
4
for (NSString *reservedProperty in reservedProperties) {
5if ([reservedProperty caseInsensitiveCompare:name] == NSOrderedSame) {6
return NO;7
}8
}
9
10
// 属性名通过正则表达式匹配,比使用谓词效率更高11
NSString *namePattern = @"^([a-zA-Z_$][a-zA-Z\\d_$]{0,99})$";12
NSRegularExpression *propertiesRegex = [NSRegularExpression regularExpressionWithPattern:namePattern options:NSRegularExpressionCaseInsensitive error:nil];13
NSRange range = NSMakeRange(0, name.length);14
return ([propertiesRegex numberOfMatchesInString:name options:0 range:range] > 0);15
}
3.4.2 类型限制
SDK 的数据类型目前支持五种:数值型、布尔值、字符串、字符串数组、日期时间,对应到代码中即是 NSNumber、NSString、NSSet、NSArray、NSDate,其它类型的数据将会被拒绝。这里需要注意的是:
在 SDK 中,布尔型与数值型一样使用的是 NSNumber 类型。在转为 JSON 后,布尔型的 NSNumber 会被转为 true 或 false,而数值型的 NSNumber 会被转为实际的数值;
NSSet 与 NSArray 都代表数据集合,只是无序与有序的区别。因此,这两种类型都可代表字符串数组;
NSNull 类型会被单独处理,它不会导致整条数据被丢弃,只会丢弃该键值对。
对于不同类型的属性值,也会有各自单独的校验,如下所示:
NSString:对于字符串,需检查其长度是否大于最大长度 8191。如果大于最大长度,会删掉超出长度的部分,并拼接 $ 代表后续内容已截断。其中,App 崩溃事件(AppCrashed)的崩溃原因属性( app_crashed_reason)其值为崩溃的堆栈,通常都比较长,故其长度限制设定为常规值的两倍;
NSSet 与 NSArray:代表字符串数组,会遍历每个对象,检查是否都为 NSString 类型,不是的话会删掉该对象;
NSDate:由于 SDK 数据格式支持的日期时间实际为 JSON 中固定格式的字符串,所以对于 NSDate,会使用 NSDateFormatter 将其按格式序列化为字符串。
四、使用场景
要了解代码埋点的使用场景,先来看下代码埋点的优缺点,尽量扬长避短。
优点:
原理简单,学习成本较低;
使用较为灵活,能够根据业务特性自定义时机、属性、事件,定制化获取数据。
缺点:
埋点成本高,每一个控件的埋点都需要添加相应的代码,不仅工作量大,而且限定了必须是技术人员才能完成;
版本更新前后,容易发生数据紊乱;
需要企业长期且稳定地完善埋点,并不断根据业务来更新。
根据上述的优缺点可以知道:代码埋点使用较为灵活,但是成本较高。因此,最好在全埋点、可视化全埋点等埋点方案无法解决问题时,或者更强调自定义的场景时来使用。例如:
App 的整体日活,App 元素点击的每日次数,可使用全埋点;
App 某个指定按钮的点击事件,某个特定页面的页面浏览事件,可使用可视化全埋点;
若对于业务统计要求非常准确,安全性要求比较高的用户数据,例如注册、支付成功,可使用服务器埋点;
以上方案解决不了,或者自定义的内容较多,例如加入购物车、提交订单等,可使用代码埋点。
五、总结
代码埋点是整个神策分析 iOS SDK 的基础与核心,它足够丰富稳定,可以让我们在使用全埋点与存储上报等功能时无后顾之忧。希望大家通过这篇文章,能够对神策分析 iOS SDK 的代码埋点有一个全面的了解。
文章来源:公众号神策技术社区