如果您对分表有以下痛点那么不妨试试我这边开源的框架sharding-core ,是否需要无感知使用分表组件,是否需要支持abp,是否需要支持自定义分表规则,是否需要支持自定义分表键,是否需要支持特定的efcore版本,是否希望框架不带任何三方框架干净,是否需要支持读写分离,是否需要动态添加表,是否需要支持join,group等操作,是否需要支持追踪特性,是否想在不修改原先代码的基础上扩展分表功能,如果一起上几个条件任意组合且你在市面上没办法找到可替代的框架可以试试本框架。如何使用代码具体可以参考github 将代码下载下来如果本地装了sqlserver直接运行单元测试或者Sample.SqlServer程序会自动在本地新建数据库新建数据库表结构,目前初始化数据为用户信息和用户对应的月薪信息表,用户表以用户id取模,用户月薪表以月份分表。
首先需要了解本框架的一个版本号不然将对您的使用产生一定的分期,目前框架分为3个版本分别是2.x,3.x,5.x3个版本,分别对应efcore 2.x efcore 3.x efcore 5.x,有人要问为什么不支持6.x呢(小弟刚刚在上周完成对本框架的开发重构,目前还未对efcore 6.x进行着手不过将在不远的将来即将支持(目测1-2个星期内))。
目前efcore生态下有着许许多多的分表、分库的解决方案,但是目前来讲都有其不足点,比如需要手动设置分表后缀、需要大量替换现有代码、不支持事务等等一系列问题,所以在这个大前提下我之前开源了sharding-core 分表组件,这个分表组件是目前来说个人认为比较“完美”的分表组件,这个分表组件目前是参考了sharding-jdbc来实现的,但是比sharding-jdbc更加强大(因为C#的表达式)。首先我们来看下目前市面上有的分表组件的缺点我们来针对其缺点进行痛点解决。
efcore支持情况
| efcore版本 | 是否支持 |
|---|---|
| 2.x | 支持 |
| 3.x | 支持 |
| 5.x | 支持 |
| 6.x | 即将支持 |
数据库支持情况
| 数据库 | 理论是否支持 |
|---|---|
| SqlServer | 支持 |
| MySql | 支持 |
| PostgreSql | 支持 |
| SQLite | 支持 |
| Oracle | 支持 |
| 其他 | 支持(只要efcore支持) |
理论上只要是efcore对应版本支持的数据库,sharding-core都将支持。
如何开始使用
1.创建一个数据库对象继承IShardingTable并且在对应的分表字段上进行[ShardingTableKey]特性的标注
////// 用户表 /// public class SysUserMod : IShardingTable { ////// 用户Id用于分表 /// [ShardingTableKey(TailPrefix = "_")] public string Id { get; set; } ////// 用户名称 /// public string Name { get; set; } ////// 用户姓名 /// public int Age { get; set; } }
2.创建对应的实体表对应配置 推荐 fluent api
public class SysTestMap:IEntityTypeConfiguration{ public void Configure(EntityTypeBuilder builder) { builder.HasKey(o => o.Id); builder.Property(o => o.Id).IsRequired().HasMaxLength(128); builder.Property(o => o.UserId).IsRequired().HasMaxLength(128); builder.ToTable(nameof(SysTest)); } }
3.创建对应的分表规则 取模分表,参数2代表后缀2位就是00-99最多100张表,3表示模3== key.hashcode() %3
public class SysUserModVirtualTableRoute : AbstractSimpleShardingModKeyStringVirtualTableRoute
{
public SysUserModVirtualTableRoute() : base(2,3)
{
}
}
4.创建对应执行的dbcontext 这一步除了继承IShardingTableDbContext外其他和普通dbcontext一样
public class DefaultTableDbContext: DbContext,IShardingTableDbContext
{
public DefaultTableDbContext(DbContextOptions options) :base(options)
{
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.ApplyConfiguration(new SysUserModMap());
}
public IRouteTail RouteTail { get; set; }
}
5.添加分表dbcontext
public class DefaultShardingDbContext:AbstractShardingDbContext
{
public DefaultShardingDbContext(DbContextOptions options) : base(options)
{
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.ApplyConfiguration(new SysUserModMap());
}
public override Type ShardingDbContextType => this.GetType();
}
6.添加配置
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
//原先的dbcontext可以用也可以不用如果原先的dbcontext还在用就继续
//services.AddDbContext(o => o.UseSqlServer("Data Source=localhost;Initial Catalog=ShardingCoreDBxx3;Integrated Security=True"));
services.AddShardingDbContext(
o => o.UseSqlServer("Data Source=localhost;Initial Catalog=ShardingCoreDBxx2;Integrated Security=True;")
, op =>
{
op.EnsureCreatedWithOutShardingTable = true;
op.CreateShardingTableOnStart = true;
op.UseShardingOptionsBuilder(
(connection, builder) => builder.UseSqlServer(connection).UseLoggerFactory(efLogger),//使用dbconnection创建dbcontext支持事务
(conStr,builder) => builder.UseSqlServer(conStr).UseLoggerFactory(efLogger));//使用链接字符串创建dbcontext
op.AddShardingTableRoute();
});
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
...
//添加启动项
app.UseShardingCore();
...
}
public static class ShardingCoreExtension{
public static IApplicationBuilder UseShardingCore(this IApplicationBuilder app)
{
var shardingBootstrapper = app.ApplicationServices.GetRequiredService();
shardingBootstrapper.Start();
return app;
}
}
7.控制器使用
private readonly DefaultShardingDbContext _defaultTableDbContext;
public ValuesController(DefaultShardingDbContext defaultTableDbContext)
{
_defaultTableDbContext = defaultTableDbContext;
}
[HttpGet]
public async Task Get()
{
var resultx11231 = await _defaultTableDbContext.Set().Where(o => o.Age == 198198).Select(o=>o.Id).ContainsAsync("1981");
var resultx1121 = await _defaultTableDbContext.Set().Where(o => o.Id == "198").SumAsync(o=>o.Age);
var resultx111 = await _defaultTableDbContext.Set().FirstOrDefaultAsync(o => o.Id == "198");
var resultx2 = await _defaultTableDbContext.Set().CountAsync(o => o.Age<=10);
var resultx = await _defaultTableDbContext.Set().Where(o => o.Id == "198").FirstOrDefaultAsync();
var resultx33 = await _defaultTableDbContext.Set().Where(o => o.Id == "198").Select(o=>o.Id).FirstOrDefaultAsync();
var resulxxt = await _defaultTableDbContext.Set().Where(o => o.Id == "198").ToListAsync();
var result = await _defaultTableDbContext.Set().ToListAsync();
var sysUserMod98 = result.FirstOrDefault(o => o.Id == "98");
_defaultTableDbContext.Attach(sysUserMod98);
sysUserMod98.Name = "name_update"+new Random().Next(1,99)+"_98";
await _defaultTableDbContext.SaveChangesAsync();
return Ok(result);
}
自定义分表键,自定义分表规则
目前市面上有的框架要么对分表字段有限制比如仅支持DateTime类型或者int等,要么对分表规则有限制:仅支持按天、按月、取模...等等,但是基于分表规则和分表字段是业务规则所以本框架遵循将其由业务系统自己定义,最大化来实现分表库的适用性,基本上满足一切分表规则,且sharding-core目前默认提供一些常用的分表规则可以快速集成。
默认路由
| 抽象abstract | 路由规则 | tail | 索引 |
|---|---|---|---|
| AbstractSimpleShardingModKeyIntVirtualTableRoute | 取模 | 0,1,2... | = |
| AbstractSimpleShardingModKeyStringVirtualTableRoute | 取模 | 0,1,2... | = |
| AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute | 按时间 | yyyyMMdd | >,>=,<,<=,=,contains |
| AbstractSimpleShardingDayKeyLongVirtualTableRoute | 按时间戳 | yyyyMMdd | >,>=,<,<=,=,contains |
| AbstractSimpleShardingWeekKeyDateTimeVirtualTableRoute | 按时间 | yyyyMMdd_dd | >,>=,<,<=,=,contains |
| AbstractSimpleShardingWeekKeyLongVirtualTableRoute | 按时间戳 | yyyyMMdd_dd | >,>=,<,<=,=,contains |
| AbstractSimpleShardingMonthKeyDateTimeVirtualTableRoute | 按时间 | yyyyMM | >,>=,<,<=,=,contains |
| AbstractSimpleShardingMonthKeyLongVirtualTableRoute | 按时间戳 | yyyyMM | >,>=,<,<=,=,contains |
| AbstractSimpleShardingYearKeyDateTimeVirtualTableRoute | 按时间 | yyyy | >,>=,<,<=,=,contains |
| AbstractSimpleShardingYearKeyLongVirtualTableRoute | 按时间戳 | yyyy | >,>=,<,<=,=,contains |
所谓的索引就是通过改对应的条件操作符可以缩小减少指定表的范围,加快程序的执行
如果以上默认分表无法满足您的需求您还可以自定义分表,如何分表可以通过继承 AbstractShardingOperatorVirtualTableRoute
动态添加分表信息
很多分表组件默认不带动态分表信息导致很多分表没办法根据业务系统来进行动态创建,sharding-core默认提供动态建表接口可以支持动态按时间,按租户等不需要数据做迁移的动态分表信息,
如果需要请参考Samples.AutoByDate.SqlServer
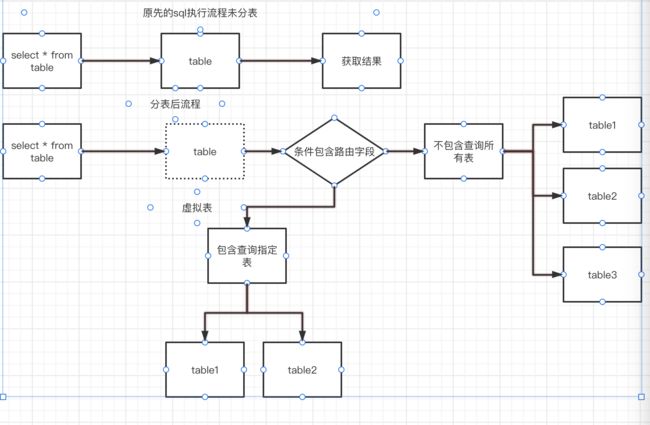
支持select,join,group by等连表聚合函数
目前sharding-core支持select按需查询,join分表连表查询,group by聚合查询,虽然本框架支持但是出于性能原因本框架还是不建议使用join操作符来操作,因为过多的表路由会导致笛卡尔积,会导致需要查询的表集合增长对数据库连接比较考验。
以下代码来自github的单元测试中,SysUserMod表示用户表,SysUserSalary表示用户月薪表用户表按id取模,用户月薪表按月分表
//join查询 var list = await (from u in _virtualDbContext.Set() join salary in _virtualDbContext.Set () on u.Id equals salary.UserId select new { u.Id, u.Age, Salary = salary.Salary, DateOfMonth = salary.DateOfMonth, Name = u.Name }).ToListAsync(); //group聚合查询 var ids = new[] {"200", "300"}; var dateOfMonths = new[] {202111, 202110}; var group = await (from u in _virtualDbContext.Set () .Where(o => ids.Contains(o.UserId) && dateOfMonths.Contains(o.DateOfMonth)) group u by new { UId = u.UserId } into g select new { GroupUserId = g.Key.UId, Count = g.Count(), TotalSalary = g.Sum(o => o.Salary), AvgSalary = g.Average(o => o.Salary), AvgSalaryDecimal = g.Average(o => o.SalaryDecimal), MinSalary = g.Min(o => o.Salary), MaxSalary = g.Max(o => o.Salary) }).ToListAsync();
分页
我们常说的分页是分表的难点也是最考验分表组件的
1我们首先来看普通的分表组件如何分页
首先我们定义一组组数据比如是1-100的连续数字,然后分成两张表按奇偶分表
| 表名 | 数据 |
|---|---|
| table1 | 1,3,5,7,9... |
| table2 | 2,4,6,8,10... |
select * from table limit 2,2理论上结果3,4
如果本次查询会做落到table1 和table2那么会改写成 2句sql
第一句 select * from table1 limit 4 ---> 1,3,5,7
第二句 select * from table2 limit 4 ---> 2,4,6,8
将8条数据放入内存然后排序
1,2,3,4,5,6,7,8
获取第3到4条数据 结果[3,4]
这个情况是我们常见的也是最简单的分页,但是这个情况仅仅适用于数据量小的时候,如果用户不小心点到了分页的最后一页那么结果将是灾难性的这是毋庸置疑的
那么sharding-core是如何处理的呢
select * from table limit 2,2
首先还是一样对数据库语句进行改性并且生成对应的sql
第一句 select * from table1 limit 4
第二句 select * from table2 limit 4
因为ado.net默认DataReader是流式获取,只要连接不关闭那么可以一直实现next获取到内存
创建一个优先级队列一个可以具有排序功能的队列
因为DataReader的特性我们分别对sql1和sql2进行一次next获取到2个数组一个是[1,.....] A和数组[2......] B
获取到两个数组我们只知道头部第一个对象因为没有进行后续的next所以无法知晓剩下的数据但是有一点可以知道后面的数据都是按sql的指定顺序的所以都不会比当前头大或者小
先将1和2放入优先级队列可以知道如果asc那么数组A放在队列头 数组B放在队列尾部,然后对优先级队列进行poll弹出,并且对A进行next这个时候A变成了[3,....]再将A放入优先级队列
这时候优先级队列就是B在前A在后依次操作,然后对分页的进行过滤因为要跳过2个对象所以只需要空执行2次那么指针就会指向A数组的3和B数组的4,剩下的只要获取2个数据就可以了,
这样做可以保证内存最小化,然后分页不会成为程序的灾难。
无感知使用
目前的分表框架很少有做到无感知使用的,你在使用的时候好一点的框架不依赖三方,一般一点的不但要依赖很多三方框架并且在使用的时候还有一大堆限制,必须使用他的东西还没办法做到和dbcontext原生的使用方法。
sharding-core目前使用的是一种类似dbcontext的wrap模式,用一个新的dbcontext来包装真实的dbcontext,这个包装的dbcontext我们成为shardingdbcontext,shardingDbContext因为本身也是集成于DbContext所以它的使用方法和原生dbcontext没有差别。并且仅需少量改动即可支持abp和abp.next
读写分离的支持
目前sharding-core已经支持单node节点的读写分离操作,将在不久的未来(1-2)天内支持多节点的读写分离
services.AddShardingDbContext(o => o.UseSqlServer(hostBuilderContext.Configuration.GetSection("SqlServer")["ConnectionString"])
,op =>
{
op.EnsureCreatedWithOutShardingTable = true;
op.CreateShardingTableOnStart = true;
op.UseShardingOptionsBuilder((connection, builder) => builder.UseSqlServer(connection).UseLoggerFactory(efLogger),
(conStr,builder)=> builder.UseSqlServer("read db connection string").UseLoggerFactory(efLogger));
op.AddShardingTableRoute();
op.AddShardingTableRoute();
});
未来计划将支持分库,支持强制路由,显示路由等...
最后具体如何使用且使用方式可以参考github(https://github.com/xuejmnet/sharding-core)
到此这篇关于efcore-ShardingCore呈现“完美”分表的文章就介绍到这了,更多相关ShardingCore“完美”分表内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!