背景
伴随得物社区、直播业务快速发展,用户体量也越来越大,服务的稳定性要求日益趋高。那如何快速的对监控告警进行归因、快速的解决问题,我想每个人都有自己的排查定位手段。对经验稍少的同学,可能大家都经历过相同的几个阶段,迷惑告警信息不知从何入手、排查思路容易走入误区、问题原因不知如何筛选。本文着眼于该知识的沉淀,通过互相学习、借鉴团队智慧、总结排查case,希望最终可以让大家受益,快速定位、及时止损。
一、直播监控告警归因实践
本文不涉及到具体的业务问题归因,而是如何将告警信息归因到某一方面。对于业务层次的代码问题,这需要完善的日志输出、全链路追踪信息、符合条件的问题上下文等去判断,思路也是相通的。
目前得物社区、直播业务使用go、处于k8s环境,监控指标使用grafana展示,天眼告警平台飞书通知。目前存在的告警规则有:RT异常、QPS异常、goroutine异常、panic异常、http状态异常、业务异常等。最近直播业务碰到一次某服务RT抖动,虽然扩容解决了相应抖动,但在归因定位过程中也走过一些弯路,下面是对整个排查过程的一个展示:
服务监控表现
告警信息反馈:服务RT异常上升、goroutine上升。通过grafana查看服务指标, 发现该时间点有出现流量尖刺,QPS上升明显
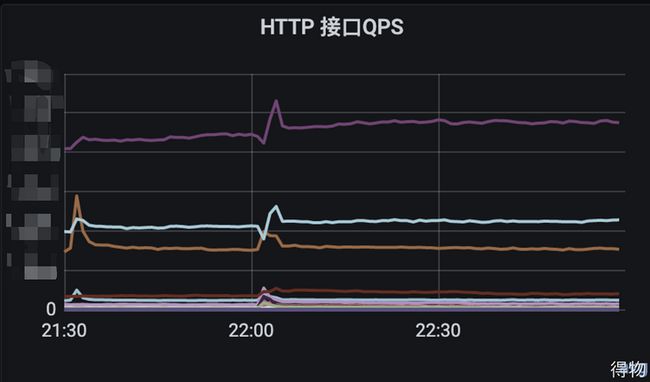
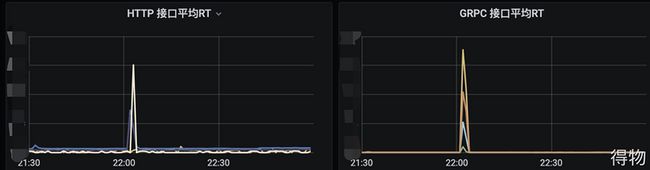
查看HTTP、GRPC指标,平均RT、99线明显上升
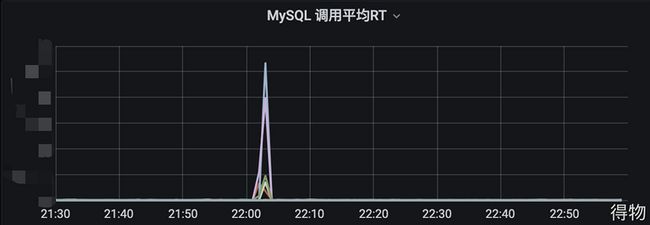
Mysql指标中RT上升明显,猜测可能是由于mysql有大批量查询或者慢查询,导致RT波动,从而导致告警
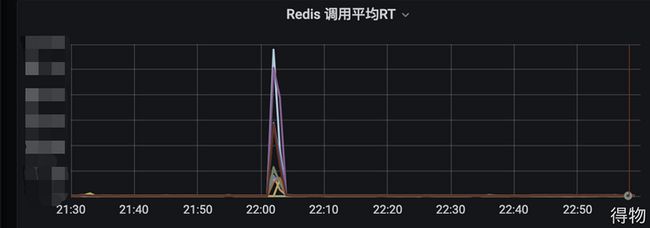
Reids指标中RT上升明显,猜测是由于redis抖动,导致RT上升,出现超时然后流量被打到了mysql上
甄选可能的原因
| 监控指标 | |||
|---|---|---|---|
| 外部HTTP | 全部接口RT上升 | QPS出现流量尖刺 | |
| Redis | 全部请求RT上升 | QPS随流量波动 | |
| Mysql | 全部请求RT上升 | QPS随流量波动 | |
| Goroutine | 全部Pod都上涨明显 | ||
| 三方依赖 | 全部请求RT上升 |
结合上述现象,我们首先能确定影响范围为服务级别。其次发现服务日志中出现redis timeout的错误日志,调用三方服务出现超时错误日志。
第一点考虑系统资源是否充足,通过查看cpu、memory指标,告警时间点系统资源不造成瓶颈。那么我们可以排除这二个原因导致的此次服务抖动。
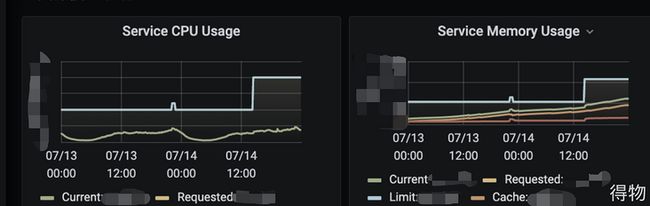
其次服务处于k8s环境中,由多个pod提供服务能力。且每个pod被调度在不同的node上,也就是不同的ecs上。同时该服务处于整体抖动状态,可以排除pod单机故障原因。
该服务整体受到影响,同k8s集群中其余服务正常,这可以排除网络故障的原因。总结下来所有的流量出入接口都受到影响,排除依赖服务故障的原因。那么接下来能考虑的就是服务的存储层(mysql、redis等) 存在故障,或者服务流量路径某个节点存在问题。
定位问题
通过阿里云的RDS,查看mysql、redis的性能趋势显示正常,并无慢查询日志,机器资源充足,网络带宽无异常,同时也不存在高可用切换。那么初步判断,存储层应该是没有问题的。
那么如何确定非存储层的问题呢?如果有使用同一存储层的另一服务,告警时段处于正常,那么就可以排除存储层故障。在直播微服务体系中,有另外一个服务使用相同的存储层,在告警时段服务处于正常状态,如此就可以确定排除此原因。
那么只剩下流量路径节点故障这一个原因,回顾一下整个链路, 服务使用k8s部署运维, 引入了istio做service mesh, 是不是该组件导致的问题呢?监控面板中也有istio的监控,如下:
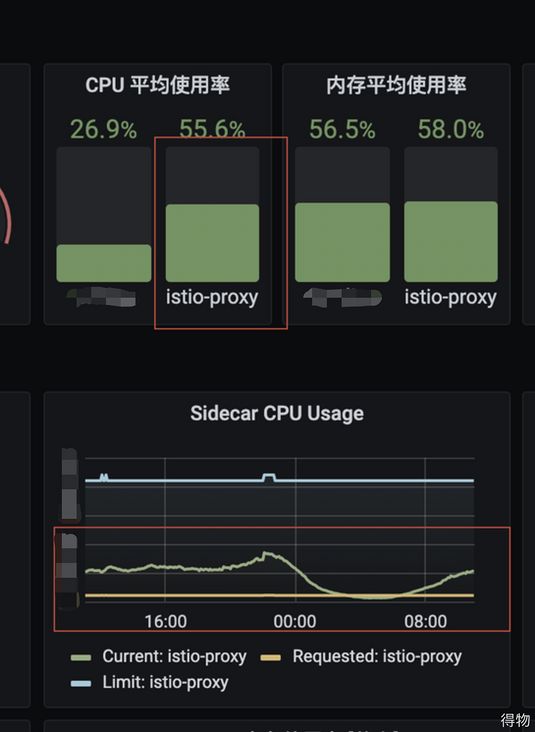
从监控中查看好像并没有问题,只是在告警时间点有波动。问题排查到这里,发现好像都没问题,那么原因到底是什么呢?回顾一下前面的分析,我们发现能确定性的排除其他原因,同时服务扩容后,RT抖动也恢复正常了。
所以还是将目光转向流量路径节点的问题,寻求运维侧的同学支持,希望实时查看下istio的状态。这时候,我发现运维侧同学反馈的istio负载和监控面板中不一致,这里也就是团队成员走弯路的地方,因为istio的负载指标显示错误,所以跳过了该原因。经过多方排查,最终发现监控面板收集数据存在异常,经过修复监控数据展示,最终istio的真实负载如下:
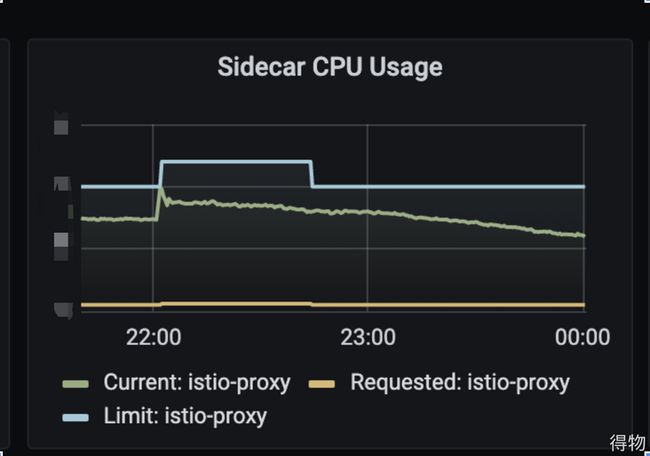
真实的istio的负载,明确的指明了此次告警的原因。最后,经确认,目前sidecar使用的资源为2c1g。服务初期使用的pod配置为1c512m, 随着业务发展pod数越来越多,所以选择了升级pod的资源配置为4c2g。并且经过服务拆分,该告警服务流量转发居多,导致istio的cpu负载过高,从而导致此次抖动。因为目前sidecar资源固定2c1g, 所以通过把服务配置降级为1c2g增加pod数量,pod数量与sidecar数量是1:1,从而增加了sidecar的资源池,避免后续出现此类抖动。
二、影响级别、可能的原因、参考思路
我们需要快速定位问题,那么首先要确定影响的范围级别,以及存在哪些可能的原因。经过直播服务抖动的归因实践,能发现是一系列的筛选过程,最终得到答案。 对于非社区、直播技术栈的业务而言,我想都能总结出一套适用于自身服务的条例。 对于直播服务技术栈,存在的范围级别,可能的原因如下所示:
| 异常表现 | cpu原因 | memory | 存储层 | 流量路径 | 三方依赖 | 网络故障 | |
|---|---|---|---|---|---|---|---|
| 接口级别 | 服务中某接口存在异常状态,其余接口正常 | 存在 | 存在 | ||||
| pod级别 | 某一pod存在异常状态,同服务其余pod正常 | 存在 | 存在 | 存在 | 存在 | 存在 | |
| 服务级别 | 某一服务所有pod都存在异常状态,同集群中其余服务正常 | 存在 | 存在 | ||||
| 集群级别 | 服务所在集群整体受影响,如前段时间测试环境ingress问题 | 存在 | 存在 | ||||
| IDC级别 | IDC范围内服务整体影响 | 存在 | 存在 |
- cpu方面:临时流量、代码问题、服务缩容、定时脚本
- 内存方面:临时流量、代码问题、服务缩容, (k8s中需要区分RSS和cache)
- mysql、redis:临时流量、慢查询、大批量查询、资源不足、高可用自动切换、手动切换
- 流量路径节点:南北向流量中ingress导致、东西向流量中istio导致
参考思路:
我们在收到告警信息时,首先需要判断受影响的范围,其次考虑可能存在的原因,再依据现有条件、现状,针对性的排除某些原因。问题的排查过程就如同一个漏斗,最终漏斗的最下一层就是问题的根因,如下所示:
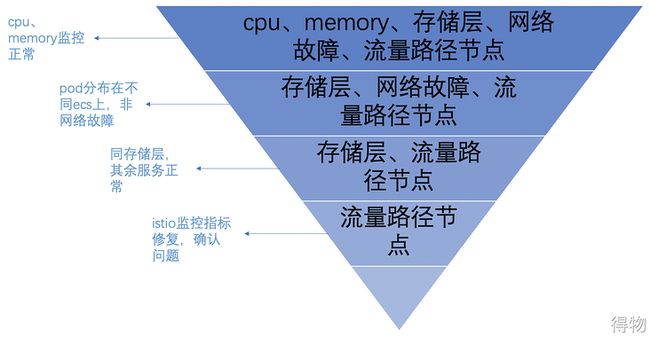
下面是一些快速排除原因的case:
- 同一存储层,其余服务正常,可以排除存储层故障
- 服务pod数量大于1,基本可以排除服务的网络故障,因为pod分布在不同的ecs上
- 并非所有的流量出入口都存在故障,那么可以排除流量路径节点问题
三、流量路径、存储层介绍
日常除却代码层面,我们也应该对服务的整个流量路径也要有所了解,对使用的基础设施架构要心中有数,这样在排查问题的时候,能快速的帮我们判断关键问题。下面介绍一下社区、直播业务的流量路径,以及基础设施高可用架构。
流量路径
南北向流量
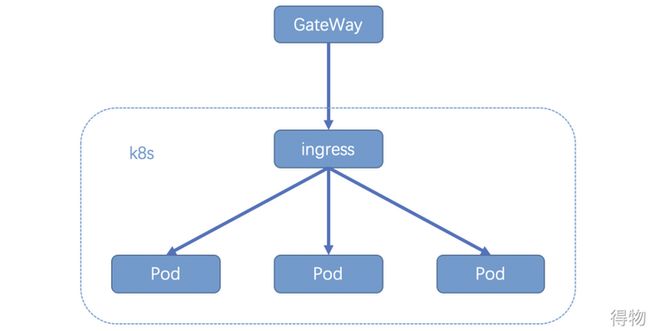
南北向流量路径中,ingress是核心路径,出现问题会导致整个k8s集群不可用。
东西向流量
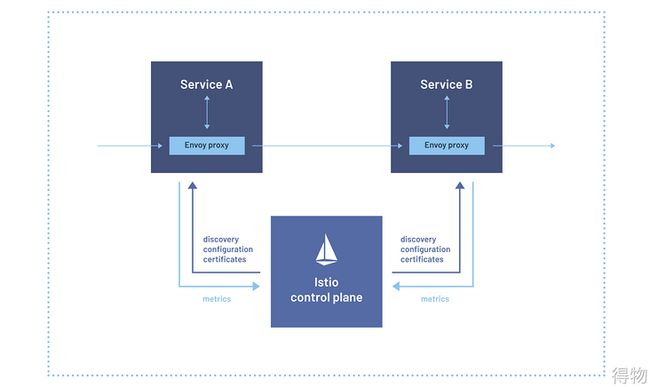
东西向流量路径中, Envoy proxy接管所有流量,proxy出现问题会导致服务pod受影响
存储层
mysql高可用架构
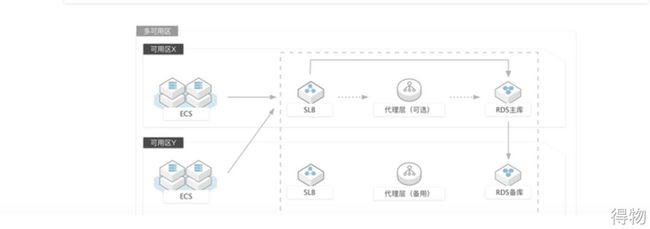
目前社区、直播业务使用的是mysql多可用区部署,在高可用自动切换的过程中,会导致服务抖动。
redis高可用架构
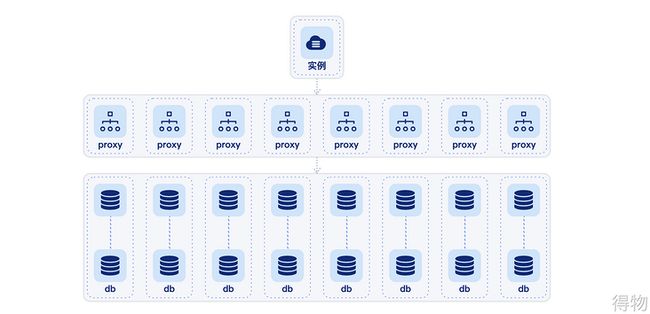
redis目前是通过代理实现集群模式,proxy和redis实例是1:N, 每个redis实例都是主从结构,当主从发生自动高可用切换、手动迁移、资源变动,也会导致服务抖动。
四、总结
回顾一下整个过程,如同抽丝剥茧,一步步揭开庐山真面目。快速的对告警归因,不仅要有正确的排查思路,也要求我们除了代码层面的掌握,还要对整个系统架构有所了解。
文/Tim
关注得物技术,做最潮技术人!