企业内部存储架构的发展和演进,是个长期延续的过程, IT规划人员有可能将人工智能(AI)视为未来几年才需要投入的改造工程。然而,AI大浪到来比想象中更快,越来越多行业将使用AI推动业务的变革。另一方面,AI工作的负载不同于以往任何处理过的IT负载。AI工作负载具有全新的特点,它面对的是海量的非结构化数据集,需要极高的随机访问性能,极低延时以及大规模存储容量。
AI不仅会创造全新的行业,而且还将从根本上改变现有组织业务开展的方式。IT规划人员需要立即开始着眼关注其存储基础架构是否已经为即将到来的AI浪潮做好了准备。
AI对存储提出了怎样的要求?
在回答现在有什么面向AI的存储解决方案时,我们需要先了解一下,人工智能下的数据到底有哪些特征,基于这些数据,到底需要一个什么样的存储?我们通过逐层分析,将最终过滤出AI业务对存储的综合诉求。
海量非结构化数据存储
AI业务中除了个别业务场景主要针对结构化数据进行分析外(例如消费记录、交易记录等风险控制、趋势预测场景),大多数场景需要处理的是非结构化数据,例如图像识别、语音识别、自动驾驶等,这些场景通常使用的是深度学习的算法,必须依赖海量图片、语音、视频的输入。
数据共享访问
多个AI计算节点需要共享访问数据。由于AI架构需要使用到大规模的计算集群(GPU服务器),集群中的服务器访问的数据来自一个统一的数据源,即一个共享的存储空间。这种共享访问的数据有诸多好处,它可以保证不同服务器上访问数据的一致性,减少不同服务器上分别保留数据带来的数据冗余等。
那么哪种接口能提供共享访问?
块存储,需要依赖上层的应用(例如Oracle RAC)实现协同、锁、会话的切换等机制,才能实现在多节点间共享块存储设备,因此不适合直接用于AI应用。
能实现共享访问的通常有对象存储和文件存储,从数据访问的接口层面看,好像都能实现数据共享。但哪个接口更方便,我们需要深入地看一下AI的上层应用框架如何使用存储。我们以AI生态中非常流行的PyTorch为例,PyTorch在加载图片数据时,通常会调用以下程序:
from torchvision import datasets, transforms
dataset = datasets.ImageFolder('path/to/data', transform=transforms)
那么torchvision的datasets.ImageFolder如何加载图片呢?我们来看看ImageFolder的构造函数,这里面会有一个默认的default_loader:

默认的default_loader会是什么行为呢?我们再来看,通常情况下,default_loader会调用pil_loader方法:
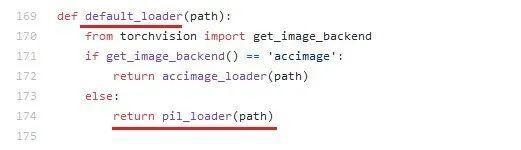
那pil_loader怎么读数据的呢?谜底即将揭晓:

这就是最典型的Python直接访问文件系统文件的open方法,所以很明显,PyTorch会默认通过文件接口访问数据。如果需要通过其它存储接口调用ImageFolder,还需要为其编写特定的loader,这就增加了额外不必要的开发工作量。
因此,从AI应用框架的角度看,文件接口是最友好的存储访问方式。
读多写少
AI数据特点是读多写少,要求高吞吐、低延时。深度学习过程训练中,需要对数据进行训练,以视觉识别为例,它需要加载数千万张,甚至上亿张图片,针对图片使用卷积神经网络、ResNet等算法,生成识别的模型。完成一轮训练后,为了减少图片输入顺序的相关性对训练结果带来的影响,会将文件次序打乱之后,重新加载,训练多个轮次(每个轮次称之为epoch)。这就意味着每个epoch都需要根据新的顺序加载数千万、上亿张图片。图片的读取速度,即延时,对完成训练过程的时间长短会造成很大影响。
前面提到,对象存储和文件存储都可以为GPU集群提供共享的数据访问,那么哪个存储接口能提供更低的延时呢?业界领先的国际水准的高性能对象存储,读延时约为9ms,而高性能文件系统延时通常为2-3ms,考虑到数亿张图片的n次加载,这个差距会被放大到严重影响AI训练效率。
从文件加载的角度看,高性能文件系统在延时特性上,也成为AI的首选。
IO Pattern复杂
大文件、小文件,顺序读、随机读混合场景。不同的业务类型所对应的数据具有不同特点,例如视觉识别,通常处理的是100KB以下的小文件;语音识别,大多数1MB以上的大文件,对这些独立的文件,采用的是顺序读。而有的算法工程师,会将几十万、甚至千万个小文件聚合成一个数百GB,甚至TB级别的大文件,在每个epoch中,根据框架随机生成的序列,对这些大文件进行随机读。
在无法预测文件大小、IO类型的背景下,对复杂IO特征的高性能支持,也是AI业务对存储的需求。
AI业务容器化
AI应用业务逐步向Kubernetes容器平台迁移,数据访问自然要让AI业务在容器平台中最方便地使用。理解这一点非常容易,在业务单机运行的时代,数据放在直通到服务器的磁盘上,称之为DAS模式。到了业务运行在多物理机组成的集群时代,为了统一管理和方便使用数据,数据存放在SAN阵列上。到云时代,数据跟着放到了云上,放到了适合云访问的分布式存储、对象存储里。由此可见,数据总是需要通过业务访问最方便的方式进行存放和管理。那么到了容器时代、云原生时代,数据自然应该放到云原生应用访问和管理最方便的存储上。
运行平台向公有云发展
公有云成为AI业务更青睐或首选的运行平台,而公有云原生的存储方案更面向通用型应用,针对AI业务的高吞吐、低延时、大容量需求,存在一定欠缺。AI业务大多具有一定的潮汐性,公有云弹性和按需付费的特性,再加上公有云高性能GPU服务器产品的成熟及使用,使公有云的计算资源成为了AI业务降本增效的首选。而与AI业务相配套,具有前面所述特点的公有云存储方案,却仍然缺失。近年来,我们看到一些国外的存储厂商(例如NetApp、Qumulo、ElastiFile等),将其产品发布并运行在了公有云上,是公有云的原生存储产品和方案距离用户特定业务应用诉求存在缺失的的印证和解读。同样,适合AI应用的存储方案在公有云上的落地,是解决AI在公有云进一步落地的最后一公里问题。
现有哪些AI存储方案,能满足以上AI大规模应用的需求吗?
DAS方式
数据直接存入GPU服务器的SSD,即DAS方式。这种方式能保证数据读取的高带宽、低延时,然而相较而言,缺点更为明显,即数据容量非常有限,与此同时,SSD或NVMe磁盘的性能无法被充分发挥(通常情况下,高性能NVMe的性能利用率不足50%),不同服务器间的SSD形成孤岛,数据冗余现象非常严重。因此,这种方式在真正的AI业务实践中,极少被使用。
传统阵列
共享的向上扩展(Scale-Up)的存储阵列是可用的共享解决方案中最常见的,也可能是最熟悉的方案。与DAS一样,共享的存储阵列也存在类似的缺点,相对于传统的工作负载,AI的工作负载实际上会将这些缺点暴露得更快。最明显的是系统可以存储多少总数据?大多数传统阵列系统每个系统几乎只能增长到1 PB的存储,并且由于大多数AI大规模工作负载将需要数十PB的存储量,因此企业只能不断采购新的存储阵列,导致数据孤岛的产生。即使克服了容量挑战,传统阵列存储也会造成性能问题。这些系统通常只能支持有限数量的存储控制器,最常见的是两个控制器,而典型的AI工作负载是高度并行的,它很容易使小型控制器不堪重负。
普通分布式文件系统
用户通常使用的是GlusterFS、CephFS、Lustre,开源分布式文件系统的首要问题是管理和运维的复杂度。其次,GlusterFS、CephFS对海量小文件,及大规模、大容量背景下的性能难以保证。考虑到高昂的GPU价格,如果在数据访问上不能给予足够的支撑,GPU的投入产出比将大幅降低,这是AI应用的管理者们最不希望看到的。
对象存储
在对象存储上搭建文件访问接口网关。首先对象存储对随机写或追加写存在天然劣势,会导致AI业务中出现写操作时,不能很好支持。其次,对象存储在读延时上的劣势,经过文件访问接口网关后,再一次被放大。虽然通过预读或缓存的方式,可以将一部分数据加载到前端的SSD设备上,但这会带来以下几个问题:1)导致上层AI框架需要针对底层的特殊架构进行适配,对框架具有入侵性,例如执行预读程序;2)会带来数据加载速度不均,在数据加载过程中,或前端SSD缓存不命中时,GPU利用率下降50%-70% 。
以上这些方案,仅从数据规模的可扩展性、访问性能、AI平台的通用性上分析来看,都不是理想的面向AI的存储方案。
YRCloudFile——面向AI场景的存储产品
YRCloudFile具备的几大特性非常契合AI应用的综合需求。
首先,这是一款可共享访问的分布式文件存储,可供GPU集群共享访问。提供的是文件访问接口,最适合对接AI的上层平台。
支持高性能访问海量的非结构化数据。通过YRCloudFile客户端,上层GPU服务器可对存储集群内的不同节点实现并发访问,通过IO500测试,以及AI业界头部企业验证,性能处于业界一流水平。在海量文件的场景下,能保持性能的持续稳定输出。YRCloudFile在元数据和数据服务的设计和实现上所做的大量优化,确保了AI业务复杂IO类型对数据访问的性能要求。
通过Kubernetes平台,可无缝调度和使用YRCloudFile提供的存储能力。YRCloudFile除了提供标准的CSI接口外,还提供了RWX读写、PV配额、PVC resize、PVC QoS等企业级功能,可以有力支撑在Kubernetes上运行的AI业务对数据访问的需要。
支持公有云部署。YRCloudFile目前已经可以在AWS、阿里云、腾讯云上快速部署,弥补了公有云对AI特定场景所需要的性能、可扩展性、运营和维护上提出的特殊要求。
总结
通过分析,我们希望能够给AI业务的规划人员提供关于AI业务对存储实际需求的观察和洞见,帮助客户在AI业务落地,提供AI存储产品的优化方案。AI将成为信息化工业革命后,再次改变世界的技术和方向,AI浪潮已经在不经意间来到我们的身边,是时候考虑面向AI的新型存储了。
参考资料
1.https://necromuralist.github....
2.https://github.com/pytorch/py...
3.https://github.com/pytorch/vi...
4.https://www.openio.io/blog/wh...
5.https://blog.architecting.it/...