原文链接:http://tecdat.cn/?p=23717
Logistic回归,也称为Logit模型,用于对二元结果变量进行建模。在Logit模型中,结果的对数概率被建模为预测变量的线性组合。
例子
例子1. 假设我们对影响一个政治候选人是否赢得选举的因素感兴趣。结果(因)变量是二元的(0/1);赢或输。我们感兴趣的预测变量是花在竞选上的钱,花在竞选上的时间,以及候选人是否是现任者。
例2. 一个研究者对GRE(研究生入学考试成绩)、GPA(平均分)和本科院校的声望等变量如何影响研究生院的录取感兴趣。因变量,录取/不录取,是一个二元变量。
数据的描述
对于我们下面的数据分析,我们将在例2的基础上展开关于进入研究生院的分析。我们生成了假设的数据,这些数据可以在R中从我们的网站上获得。请注意,R在指定文件位置时需要正斜杠(/)而不是反斜杠(),该文件在你的硬盘上。
##查看数据的前几行
head(mydata)
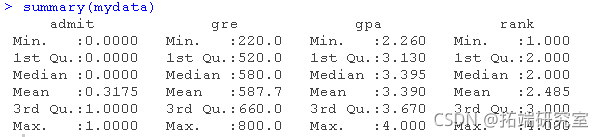
这个数据集有一个二元因(结果,因果)变量,叫做录取。有三个预测变量:gre、gpa和rank。我们将把gre和gpa这两个变量视为连续变量。变量rank的值为1到4。排名为1的院校有最高的声望,而排名为4的院校有最低的声望。我们可以通过使用总结来获得整个数据集的基本描述。为了得到标准差,我们使用sapply对数据集中的每个变量应用sd函数。
你可能考虑的分析方法
以下是你可能遇到过的一些分析方法的清单。所列的一些方法是相当合理的,而其他的方法可能有局限性。
- Logistic回归,是本文的重点。
- Probit回归。Probit分析会产生类似Logistic回归的结果。选择probit还是logit,主要取决于个人的偏好。
- OLS回归。当与二元因变量一起使用时,这个模型被称为线性概率模型,可以作为描述条件概率的一种方式。然而,线性概率模型的误差(即残差)违反了OLS回归的同方差和误差的正态性假设,导致标准误差和假设检验无效。
- 双组判别函数分析。一种用于二分结果变量的多变量方法。
使用logit模型
下面的代码使用glm(广义线性模型)函数估计一个逻辑回归模型。首先,我们将等级转换为一个因子变量,以表明等级应被视为一个分类变量。
mydata$rank <- factor(mydata$rank)
mylogit <- glm(admit ~ gre + gpa + rank, data = mydata, family = "binomial")由于我们给我们的模型起了个名字(mylogit),R不会从我们的回归中产生任何输出。为了得到结果,我们使用summary命令。

- 在上面的输出中,我们首先看到的是调用,这是R提醒我们所运行的模型是什么,我们指定了哪些选项,等等。
- 接下来我们看到偏差残差,这是衡量模型拟合度的一个指标。这部分输出显示了模型中使用的各个案例的偏差残差的分布。下面我们讨论如何使用偏差统计的摘要来评估模型的拟合度。
- 输出的下一部分显示了系数、它们的标准误差、z统计量(有时称为Wald z统计量)以及相关的p值。gre和gpa都有统计学意义,三个等级项也是如此。逻辑回归系数给出了预测变量增加一个单位时结果的对数几率变化。
- gre每增加一个单位,录取(与未录取)的对数几率增加0.002。
- gpa增加一个单位,被研究生院录取的对数几率就会增加0.804。
- 级别的指标变量有一个稍微不同的解释。例如,就读于排名为2的本科院校与排名为1的院校相比,被录取的对数几率会改变为-0.675。
- 系数表下面是拟合指数,包括无效和偏差残差以及AIC。稍后我们将展示一个例子,说明如何使用这些值来帮助评估模型的拟合。
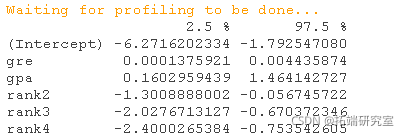
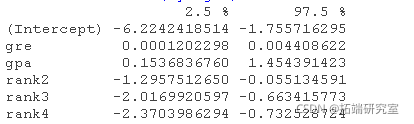
我们可以使用confint函数来获得系数估计值的置信区间。注意,对于logistic模型,置信区间是基于剖析的对数似然函数。我们也可以通过使用默认的方法,只根据标准误差来获得CI。
我们可以用wald.test函数来检验等级的整体效应。系数表中系数的顺序与模型中项的顺序相同。这一点很重要,因为wald.test函数是按照系数在模型中的顺序来参考的。我们使用wald.test函数。b提供了系数,而Sigma提供了误差项的方差协方差矩阵,最后Terms告诉R模型中哪些项要被测试,在本例中,4、5、6项是等级水平的三个项。
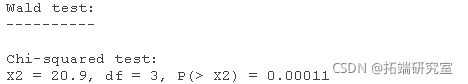
卡方检验统计量为20.9,有三个自由度,P值为0.00011,表明等级的总体影响在统计上是显著的。
我们还可以检验关于不同等级的系数差异的其他假设。下面我们测试等级=2的系数是否等于等级=3的系数。下面的第一行代码创建了一个向量l,定义了我们要执行的测试。在这种情况下,我们要测试等级=2的项和等级=3的项(即模型中的第4和第5项)的差异(减法)。为了对比这两个项,我们把其中一个项乘以1,另一个项乘以-1。下面的第二行代码使用L=l来告诉R,我们希望以向量l为基础进行测试(而不是像上面那样使用Terms选项)。
wald.test(b , Sigma , L = l)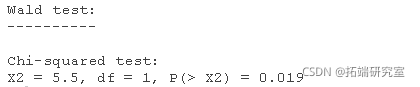
1个自由度的卡方检验统计量为5.5,P值为0.019,表明等级=2的系数和等级=3的系数之间的差异具有统计学意义。
你也可以对系数进行指数化,并将其解释为概率。为了得到指数化的系数,你要告诉R你要进行指数化(exp),你要指数化的对象叫做coefficients,它是mylogit的一部分(coef(mylogit))。我们可以使用同样的逻辑,通过对之前的置信区间进行指数化,得到概率及其置信区间。为了把这些都放在一个表中,我们用cbind把系数和置信区间按列绑定起来。
## 概率比
##概率和95%CI![]()
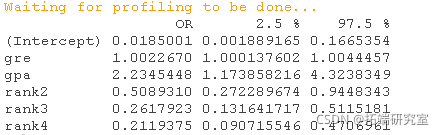
现在我们可以说,gpa增加一个单位,被研究生院录取(与未被录取)的几率就会增加2.23倍。请注意,截距的几率一般不会被解释。
你也可以使用预测概率来帮助你理解模型。预测概率可以针对分类和连续预测变量进行计算。为了创建预测的概率,我们首先需要创建一个新的数据框架,其中包含我们希望自变量采取的数值,来创建我们的预测。
我们将首先计算每个等级值的预测录取概率,保持gre和gpa的平均值。首先,我们创建并查看数据框架。
data.frame(mean(gre), mean(gpa), factor(1:4))
## 查看数据框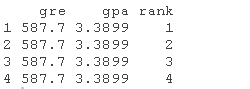
这些对象的名称必须与上述逻辑回归中的变量相同(例如,在本例中,gre的平均值必须被命名为gre)。 现在我们有了要用来计算预测概率的数据框,我们可以告诉R来创建预测概率。下面的第一行代码非常紧凑,我们将把它拆开来讨论各个部分的作用。newdata1$rankP告诉R,我们要在数据集(数据框)newdata1中创建一个名为rankP的新变量,命令的其余部分告诉R,rankP的值应该是使用predict( )函数进行的预测。括号内的选项告诉R,预测应该基于mylogit分析,预测变量的值来自newdata1,预测的类型是预测的概率(type="response")。代码的第二行列出数据框newdata1中的值。这是预测概率的表格。
predict(mylogit, newdata, type)
在上面的输出中,我们看到,在保持gre和gpa的平均值的情况下,来自最高声望的本科院校(排名=1)的学生被研究生课程录取的预测概率为0.52,而来自排名最低的院校(排名=4)的学生为0.18。我们可以做一些非常类似的事情,创建一个预测概率的表格,改变gre和排名的值。我们将绘制这些图表,因此我们将在每个等级值(即1、2、3和4)上创建100个200至800的gre值。
gre = rep(seq(from = 200, to = 800, length.out = 100),
4), mean(gpa), factor(rep(1:4, each = 100))生成预测概率的代码(下面第一行)与之前的相同,只是我们还要提供标准误差,这样我们就可以绘制一个置信区间。我们在链接标度上得到估计值,并将预测值和置信区间都反过来转化为概率。
PredictedProb
LL <- plogis(fit - (1.96 * se.fit))
UL <- plogis(fit + (1.96 * se.fit))
##查看最终数据集的前几行
使用预测概率的图表来理解和/或展示模型也是有帮助的。我们将使用ggplot2软件包来绘制图表。下面我们用预测的概率和95%的置信区间做一个图。
ggplot( aes(x = gre, y = Predicted))
我们也可能希望看到我们的模型拟合程度的方法。在比较相互比较的模型时,这可能特别有用。summary(mylogit)产生的输出包括拟合指数(显示在系数下面),包括无效和偏差残差以及AIC。衡量模型拟合度的一个指标是整个模型的显著性。这个测试问的是有预测因子的模型是否比只有截距的模型(即空模型)明显更适合。检验统计量是带有预测因子的模型与无效模型的残差。检验统计量是分布式的卡方,自由度等于当前模型和无效模型之间的自由度差异(即模型中预测变量的数量)。为了找到两个模型的偏差差异(即检验统计量),我们可以使用以下命令。
with(mylogit, null.deviance - deviance)
## \[1\] 41.5两个模型之间差异的自由度等于模式中预测变量的数量,可以用以下方法得到。
with(mylogit, df.null - df.residual)
## \[1\] 5最后,可以用P值得到。
## \[1\] 7.58e-085个自由度的卡方为41.46,相关的P值小于0.001,这告诉我们,我们的模型作为一个整体的拟合度明显好于一个空模型。这有时被称为似然比检验(偏差残差为-2*对数似然)。要查看模型的对数似然,我们可以输入。
logLik(mylogit)
## 'log Lik.' -229 (df=6)需要考虑的事项
- 空单元格或小单元格。你应该通过分类预测因子和结果变量之间的交叉分析来检查空单元或小单元。如果一个单元的案例很少(小单元),模型可能会变得不稳定或根本无法运行。
- 样本量。logit和probit模型都需要比OLS回归更多的案例,因为它们使用最大似然估计技术。在只有少量案例的数据集中,有时可以用精确的Logistic回归来估计二元结果的模型。同样重要的是要记住,当结果是罕见的,即使整个数据集很大,也很难估计出一个Logit模型。
- 伪R平方。存在许多不同的伪R平方的测量方法。它们都试图提供类似于OLS回归中R平方所提供的信息;然而,它们都不能完全按照OLS回归中R平方的解释来解释。
- 诊断法。逻辑回归的诊断方法与OLS回归的诊断方法不同,对逻辑回归的诊断与对probit回归的诊断相似。
参考文献
Hosmer, D. & Lemeshow, S. (2000). Applied Logistic Regression (Second Edition). New York: John Wiley & Sons, Inc.
Long, J. Scott (1997). Regression Models for Categorical and Limited Dependent Variables. Thousand Oaks, CA: Sage Publications.

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验