为何要调优
如果说,引入一个技术需要兴趣和冲劲,那么,让这个技术上线需要的是坚持和执着。 Cloud Native 如是, Istio 如是。
在上线前的性能测试中,Istio 的使用提供了可观察性、运维上的便利,同时也引入了痛苦:增加了服务响应延时。如何让痛苦减到最低,成了当下之急。
表现:之前 9ms 的 SERVICE-A,现在要 14 ms 了。SERVICE-A 依赖于 SERVICE-B。
分析之路
脚下有两条路:
- 直接调整一些认为可疑的配置,禁用一些功能。再压测看结果。
- 对 sidecar 做 cpu profile,定位可疑的地方。进行相对有根据的调优
我选择了 2。
Sidecar CPU Profile(照肺)
Istio 作为一个比较成熟的开源产品,有其官方的 benchmark 项目:
https://github.com/istio/tool...
我参考了:https://github.com/istio/tool... 。
安装 perf
在 container 中运行 linux 的 perf 工具来对 sidecar 作 profile。其中有一些难点,如 Istio-proxy container 默认全文件系统只读,我修改了为可写。需要以 root 身份进入 container。如果觉得麻烦,自行基于原 image 制作定制 Image 也可。具体方法不是本文重点,不说了。之后可以用包工具(如 apt)来安装 perf了。
这是一个 istio-proxy container 配置的例子:
spec:
containers:
- name: istio-proxy
image: xyz
securityContext:
allowPrivilegeEscalation: true
capabilities:
add:
- ALL
privileged: true
readOnlyRootFilesystem: false
runAsGroup: 1337
runAsNonRoot: false
runAsUser: 1337执行 profile 、生成 Flame Graph
以 root 身份进入 istio-proxy container(是的,root可以省点事)
perf record -g -F 19 -p `pgrep envoy` -o perf.data -- sleep 120
perf script --header -i perf.data > perf.stacksperf.stacks 复制到开发机后,生成 Flame Graph。是的,需要用到一个 perl 脚本:https://github.com/brendangre... (由我的偶像 Brendan Gregg 荣誉出品)
export FlameGraph=/xyz/FlameGraph
$FlameGraph/stackcollapse-perf.pl < perf.stacks | $FlameGraph/flamegraph.pl --hash > perf.svg最终生成了 perf.svg :
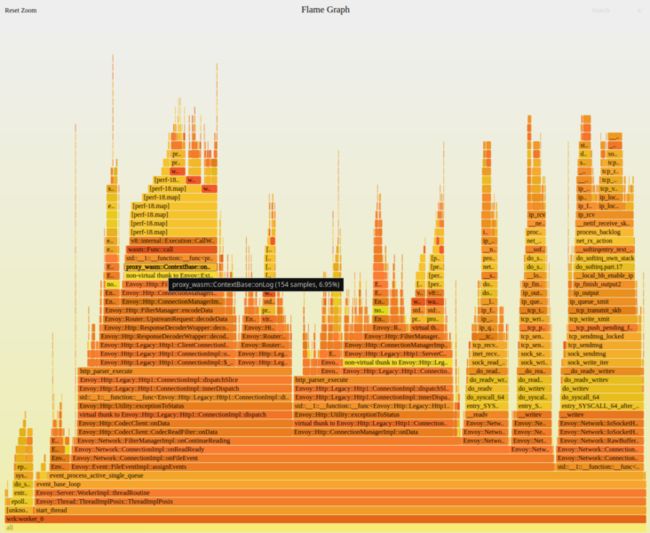
上图只是一个 envoy worker线程,还有一个线程与之类似。所以上面的 proxy_wasm::ContextBase::onLog 使用了全进程的 14% CPU。从上图看出,这大概是一个 Envoy 扩展 Filter。问题来了,这是什么 Filter,为何有部分 stack 信息会获取不到(上图中的 perf-18.map)。
Envoy Filter - wasm 的乌托邦
我知道的是,wasm 是一个 vm 引擎(类比 jvm 吧)。Envoy 支持 Native 方式实现扩展,也支持 wasm 方式实现扩展。当然了,vm 擎和 Native 相比一定有性能损耗了。
还好,某哥搜索带我找到这文档:
https://istio.io/v1.8/docs/op...
其中一个图,与一段话给予了我提示:

baselineClient pod directly calls the server pod, no sidecars are present.none_bothIstio proxy with no Istio specific filters configured.v2-stats-wasm_bothClient and server sidecars are present with telemetry v2v8configured.v2-stats-nullvm_bothClient and server sidecars are present with telemetry v2nullvmconfigured by default.v2-sd-full-nullvm_bothExport Stackdriver metrics, access logs and edges with telemetry v2nullvmconfigured.v2-sd-nologging-nullvm_bothSame as above, but does not export access logs.
好地地(现在流行粤语)一个性能测试,整那么多条线干什么?翻译成接地气的是:
baseline不使用 sidecarsnone_both不使用 Istio 的 Filterv2-stats-wasm_both使用 wasm 实现的 filterv2-stats-nullvm_both使用 Native 实现的 Filter
这几句话想说什么?老外有时还是比较含蓄的,接地气地说,就是我们想推广使用 wasm 技术,所以默认就使用这个了。如果你介意那 1ms 的延时,和那么一点点CPU 。还请用回 Native 技术吧。好吧,我承认,我介意。
注:后来我发现,官方标准版本的 Istio 1.8 使用的是 Native 的 Filter。而我们的环境中是个内部定制版本,默认使用了 wasm Filter(或者也是基于安全、隔离性、可移植性大于性能的乌托邦)。所以,可能对于你来说,Native Filter 已经是默认配置。
累坏的 Worker Thread 与 袖手旁观的 core
下面是 enovy 进程的线程级 top 监控。是的,pthread说了,线程命名,不是 Java 世界的专利。COMMAND 一列是线程名字。
top -p `pgrep envoy` -H -b
top - 01:13:52 up 42 days, 14:01, 0 users, load average: 17.79, 14.09, 10.73
Threads: 28 total, 2 running, 26 sleeping, 0 stopped, 0 zombie
%Cpu(s): 42.0 us, 7.3 sy, 0.0 ni, 46.9 id, 0.0 wa, 0.0 hi, 3.7 si, 0.1 st
MiB Mem : 94629.32+total, 67159.44+free, 13834.21+used, 13635.66+buff/cache
MiB Swap: 0.000 total, 0.000 free, 0.000 used. 80094.03+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
42 istio-p+ 20 0 0.274t 221108 43012 R 60.47 0.228 174:48.28 wrk:worker_1
41 istio-p+ 20 0 0.274t 221108 43012 R 55.81 0.228 149:33.37 wrk:worker_0
18 istio-p+ 20 0 0.274t 221108 43012 S 0.332 0.228 2:22.48 envoy同时发现, client 的并发压力提高,并不能明显提高这个 2 worker thread 的 envoy 的间线程 CPU 使用到 100%。民间一直流传的 超线程 CPU core 不能达到 core * 2 性能的情况来了。怎么办?加 worker 试试啦。
一个字:调
Istio 通过 EnvoyFilter 可以定制 Filter,所以我这样玩了:
kubectl apply -f - <<"EOF"
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
...
name: stats-filter-1.8
spec:
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_OUTBOUND
listener:
filterChain:
filter:
name: envoy.http_connection_manager
subFilter:
name: envoy.router
proxy:
proxyVersion: ^1\.8.*
patch:
operation: INSERT_BEFORE
value:
name: istio.stats
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm
value:
config:
configuration:
'@type': type.googleapis.com/google.protobuf.StringValue
value: |
{
}
root_id: stats_outbound
vm_config:
allow_precompiled: true
code:
local:
inline_string: envoy.wasm.stats
runtime: envoy.wasm.runtime.null
vm_id: stats_outbound
...
EOFkubectl apply -f - <<"EOF"
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: metadata-exchange-1.8
spec:
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: envoy.http_connection_manager
proxy:
proxyVersion: ^1\.8.*
patch:
operation: INSERT_BEFORE
value:
name: istio.metadata_exchange
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm
value:
config:
configuration:
'@type': type.googleapis.com/google.protobuf.StringValue
value: |
{}
vm_config:
allow_precompiled: true
code:
local:
inline_string: envoy.wasm.metadata_exchange
runtime: envoy.wasm.runtime.null
...
EOF
注:后来我发现,官方标准版本的 Istio 1.8 使用的是 Native 的 Filter,即 envoy.wasm.runtime.null。而我们的环境中是个内部定制版本,默认使用了 wasm Filter(或者也是基于安全、隔离性、可移植性大于性能的乌托邦)。所以,上面的的优化,可能对于你来说,是默认配置已经完成了。即,你可以忽略……
下面是修改 envoy 的线程数:
kubectl edit deployments.apps my-service-deployment
spec:
template:
metadata:
annotations:
proxy.istio.io/config: 'concurrency: 4'Sidecar CPU Profile(再照肺)
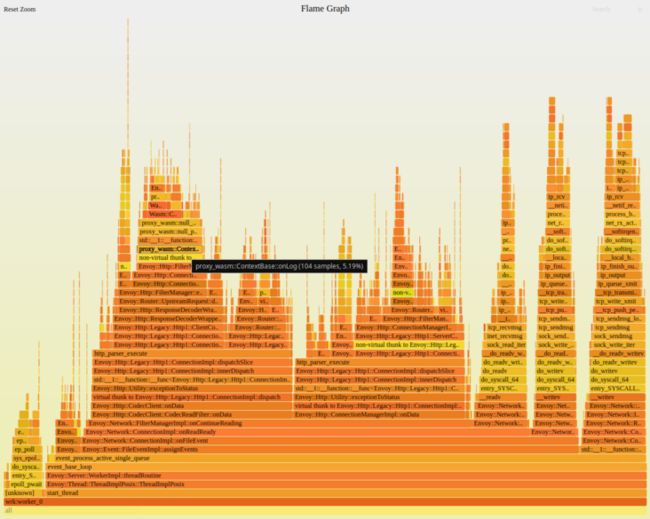
由于用 native envoy filter 代替了 wasm filter。上图可见,stack 丢失情况没了。实测 CPU 使用率下降约 8%,延迟减少了 1ms。
总结
与其谴责坑爹的定制版本的默认 wasm envoy filter 配置、线程配置,不如想想自己为何付出数天的代价,才定位到这个问题。当我们很兴奋地坐上某新技术船上时,除了记得带上救生圈,还不能忘记:你是船长,除了会驾驶,你更应该了解船的工作原理和维修技术,才可以应对突发,不负所托。
原文:https://blog.mygraphql.com/zh/posts/cloud/istio/istio-tunning/istio-filter-tunning-thread/