1、请你简述一下 Java 内存结构(运行时数据区)
如图所示:
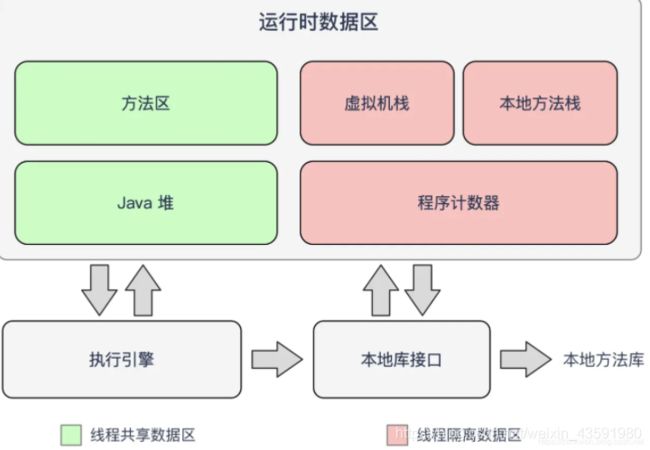
① 程序计数器
- 程序计数器:线程私有。一块较小的内存空间,程序计数器用于保存 JVM 中下一条所要执行的字节码指令的地址!如果正在执行的是 Native 方法,则这个计数器值则为空。程序计数器在硬件层面是通过 寄存器 实现的!
Java指令执行流程:
- java代码源文件经过编译为.class 二进制字节码文件。
- class 文件中的每一条二进制字节码指令(JVM指令) 通过 解释器 转换成 机器码 然后就可以被 CPU 执行了!
- 当 解释器 将一条 jvm 指令转换成 机器码 后,同时会向程序计数器 递交下一条 jvm 指令的执行地址!
如图所示:

② 虚拟机栈
- 虚拟机栈:线程私有,它的生命周期与线程相同。虚拟机栈是Java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
- 每个栈由多个栈帧(Frame) 组成,对应着每个方法运行时所占用的内存。
- 个线程只能有一个活动栈帧,对应着当前正在执行的方法,当方法执行时压入栈,方法执行完毕后弹出栈。
- 方法体中的引用变量和基本类型的变量都在栈上,其他都在堆上。
实例代码:
/**
* @Auther: csp1999
* @Date: 2020/11/10/11:36
* @Description: 演示栈帧
*/
public class Demo01 {
public static void main(String[] args) {
methodA();
}
private static void methodA() {
methodB(1, 2);
}
private static int methodB(int a, int b) {
int c = a + b;
return c;
}
}
流程分析:
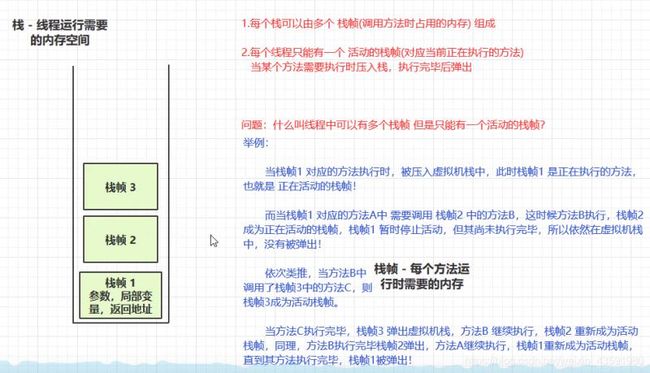
我们打断点来Debug 一下看一下方法执行的流程:
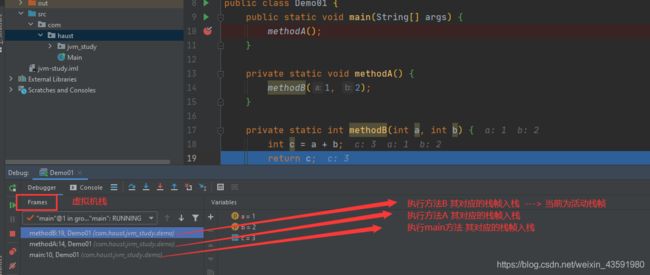
接这往下走,使方法B执行完毕:
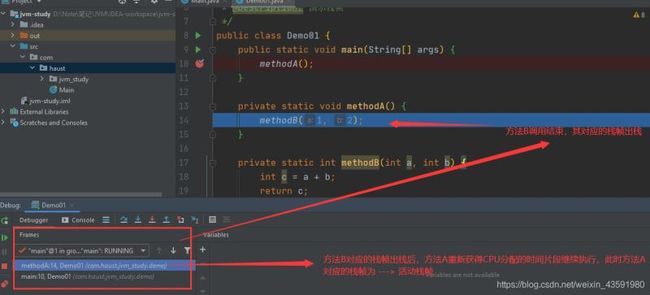
然后方法A 执行完毕,其对应的栈帧出栈,main 方法对应的栈帧为活动栈帧;最后main执行完毕,栈帧出栈,虚拟机栈为空,代码运行结束!
③ 本地方法栈
本地方法栈:线程私有。本地方法栈与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
一些带有native 关键字修饰的方法就是需要JAVA去调用本地的C或者C++方法,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法!
④ 堆
堆:线程共享。Java堆是Java虚拟机所管理的内存中最大的一块,是被所有线程共享的一块内存区域,在虚拟机启动时创建。Java堆的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。 通过new关键字创建的对象都会被放在堆内存。方法体中的引用变量和基本类型的变量都在栈上,其他都在堆上。Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”(Garbage)。-Xmx -Xms:JVM初始分配的堆内存由-Xms指定,默认是物理内存的1/64。
⑤ 方法区
方法区:线程共享。方法区用于存储已被虚拟机加载的 *类信息(构造方法、接口定义)、常量、静态变量、即时编译器编译后的代码(字节码)*等数据。 方法区在 JVM 启动的时候被创建,并且它的实际的物理内存空间和 Java堆一样都可以是不连续的, 关闭 Jvm 就会释放这个区域的内存。方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出,虚拟机同样会抛出内存溢出错误:(java.lang.OutOfMemoryError:PermGen space、java.lang.OutOfMemoryError:Metaspace)。 注意:方法区时一种规范,而永久代和元空间是它的2种实现方式。
方法区的演进:
1.6 版本方法区是由 永久代 实现(使用堆内存的一部分作为方法区),且由JVM 管理。由Class、ClassLoader、常量池(包括StringTable) 组成。

Jdk 1.7 版本仍有永久代,但已经逐步 " 去永久代 ",StringTable、静态变量从永久代移除,保存在堆中。
1.8 版本后,方法区交给本地内存管理,而脱离了JVM,由元空间实现(元空间不再使用堆的内存,而是使用本地内存,即操作系统的内存),由Class、ClassLoader、常量池(StringTable 被移到了堆中管理) 组成。
⑥ 运行时常量池
常量池:可以看做是一张表,虚拟机指令根据这张常量表找到要执行的 类名,方法名,参数类型、字面量 等信息。
常量池是*.class文件中的,当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实内存地址。
运行时常量池:是方法区的一部分。
String str = new String("hello");
上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而hello这个字面量是放在堆中。
2、请问jvm垃圾回收是否涉及栈内存?
不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
3、虚拟机栈内存的分配越大越好吗?
- 不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
我们来看一张图:
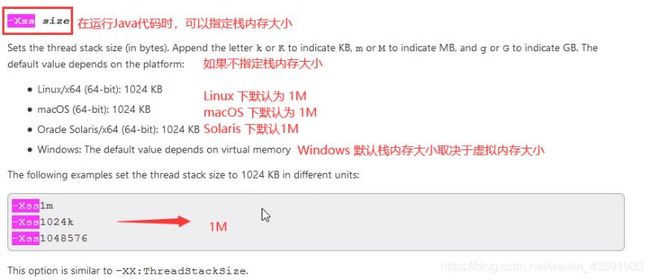
举例:如果物理内存是500M(假设),如果一个线程所能分配的栈内存为2M的话,那么可以有250个线程。而如果一个线程分配栈内存占5M的话,那么最多只能有100 个线程同时执行!
4、从JVM的角度分析,方法内的局部变量是否是线程安全的?
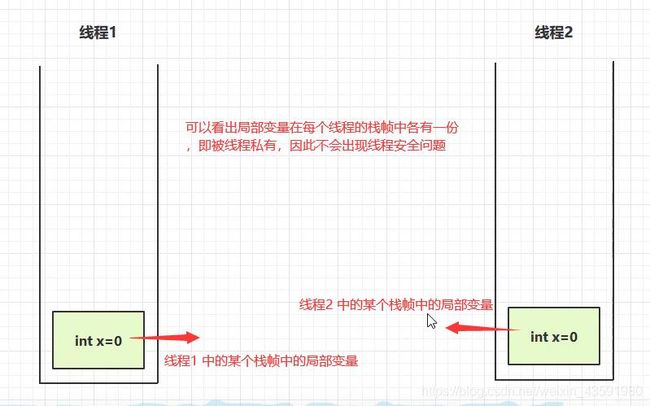
我们通过两张图去分析一下:
情况一:
情况二:
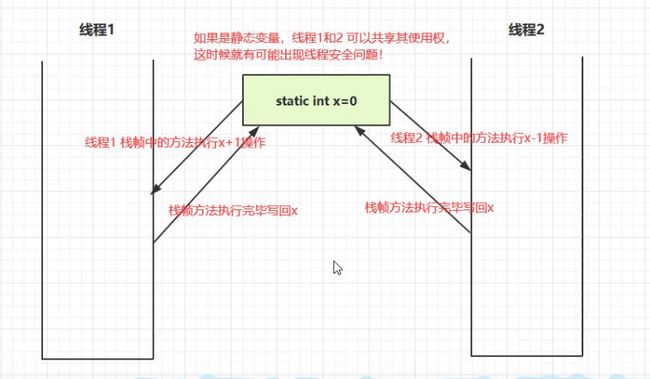
从图中得出:局部变量如果是静态的可以被多个线程共享,那么就存在线程安全问题。如果是非静态的只存在于某个方法作用范围内,被线程私有,那么就是线程安全的!
再来看一个案例:
/**
* 局部变量的线程安全问题
*/
public class Demo02 {
public static void main(String[] args) {// main 函数主线程
StringBuilder sb = new StringBuilder();
sb.append(4);
sb.append(5);
sb.append(6);
new Thread(() -> {// Thread新创建的线程
m2(sb);
}).start();
}
public static void m1() {
// sb 作为方法m1()内部的局部变量,是线程私有的 ---> 线程安全
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static void m2(StringBuilder sb) {
// sb 作为方法m2()外部的传递来的参数,sb 不在方法m2()的作用范围内
// 不是线程私有的 ---> 非线程安全
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static StringBuilder m3() {
// sb 作为方法m3()内部的局部变量,是线程私有的
StringBuilder sb = new StringBuilder();// sb 为引用类型的变量
sb.append(1);
sb.append(2);
sb.append(3);
return sb;// 然而方法m3()将sb返回,sb逃离了方法m3()的作用范围,且sb是引用类型的变量
// 其他线程也可以拿到该变量的 ---> 非线程安全
// 如果sb是非引用类型,即基本类型(int/char/float...)变量的话,逃离m3()作用范围后,则不会存在线程安全
}
}
所以,该面试题答案是:
如果方法内局部变量没有逃离方法的作用范围,则是线程安全的。如果局部变量引用了对象,并逃离了方法的作用范围,则需要考虑线程安全问题。
5、虚拟机栈内存溢出的情况有哪些?
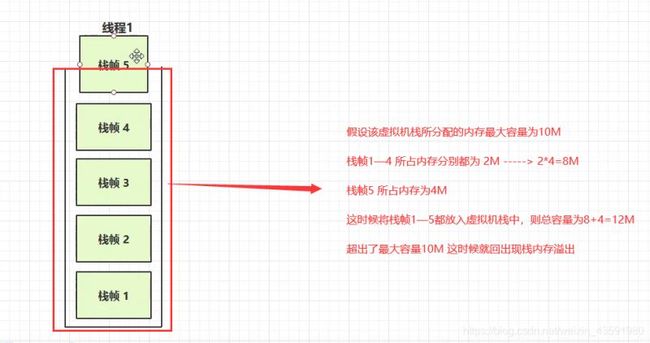
- 1.虚拟机栈中,栈帧过多(方法无限递归)导致栈内存溢出,这种情况比较常见!
- 2.每个栈帧所占用内存过大(某个/某几个栈帧内存直接超过虚拟机栈最大内存),这种情况比较少见!
如图所示,就是栈中栈帧过多的情况:
6、请你说一下JVM运行时数据区方法区的演进?
- 1.6 版本方法区是由永久代实现(使用堆内存的一部分作为方法区),且由JVM 管理。由Class、ClassLoader、常量池(包括StringTable) 组成。
- 静态变量就存放在永久代(方法区)上。
- Jdk 1.7 版本仍有永久代,但已经逐步 " 去永久代 ",StringTable、静态变量从永久代移除,保存在堆中。
- 1.8 版本后,方法区交给本地内存管理,而脱离了JVM,由元空间实现(元空间不再使用堆的内存,而是使用本地内存,即操作系统的内存),由Class、ClassLoader、常量池(StringTable 被移到了堆中管理) 组成。
- 静态变量、StringTable 存放在堆中!

为什么要用元空间取代永久代?
因为永久代有以下几个弊端:
① 字符串常量池存在于永久代中,在大量使用字符串的情况下,非常容易出现OOM的异常。
② JVM加载的class的总数,方法的大小等都很难确定,因此对永久代大小的指定难以确定。太小的永久代容易导致永久代内存溢出,太大的永久代则容易导致虚拟机内存紧张,空间浪费。
③ 永久代进行调优很困难:方法区的垃圾收集主要回收两部分,常量池中废弃的常量和不再使用的类。而不再使用的类或类的加载器回收比较复杂,FULL GC 的时间长。
7、请问Java虚拟机中有哪些类加载器?
以 JDK 8 为例:
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
| Bootstrap ClassLoader(启动类加载器) | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader(扩展类加载器) | JAVA_HOME/jre/lib/ext | 上级为 Bootstrap,显示为 null |
| Application ClassLoader(应用程序类加载器) | classpath | 上级为 Extension |
| 自定义类加载器 | 自定义 | 上级为 Application |
类加载器的优先级(由高到低):启动类加载器 -> 扩展类加载器 -> 应用程序类加载器 -> 自定义类加载器。
- **启动类加载器(Bootstrap ClassLoader):**这个类加载器负责将存放在 JAVA_HOME/jre/lib 目录中的,或者被-Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。
- **扩展类加载器(Extension ClassLoader):**这个加载器由 sun.misc.Launcher$ExtClassLoader 实现,它负责加载JAVA_HOME/jre/lib/ext目录中的,或者被 java.ext.dirs 系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
- **应用程序类加载器(Application ClassLoader):**这个类加载器由 sun.misc.Launcher$AppClassLoader 实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
- **自定义类加载器:**用户自定义的类加载器。
8、请你说一下类的加载的过程?
类加载的过程包括:加载、验证、准备、解析、初始化。其中验证、准备、解析统称为连接。
- 加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的java.lang.Class对象。
- 验证:确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
- 准备:为静态变量分配内存并设置静态变量初始值,这里所说的初始值“通常情况”下是数据类型的零值。
- 解析:将常量池内的符号引用替换为直接引用。
- 初始化:到了初始化阶段,才真正开始执行类中定义的 Java 初始化程序代码。主要是静态变量赋值动作和静态语句块(static{})中的语句。
9、请你说一下什么是双亲委派模型?
如图所示:
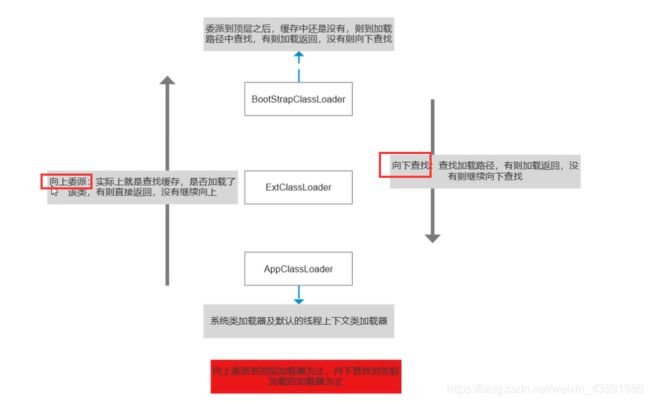
什么是双亲委派模型?
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
为什么要使用双亲委派模型呢?(好处)
避免重复加载 + 避免核心类篡改
- 采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父加载器已经加载了该类时,就没有必要子加载器再加载一次。
- 其次是考虑到安全因素,java 核心 api 中定义类型不会被随意替换,假设通过网络传递一个名为 java.lang.Integer 的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的 java.lang.Integer,而直接返回已加载过的 Integer.class,这样便可以防止核心API库被随意篡改。
10、说一下虚拟机栈和堆的区别?
① 物理地址方面的区别:
- 堆 的物理地址分配对对象是不连续的。因此性能慢些。
- 虚拟机栈 使用的是数据结构中的栈,先进后出的原则,物理地址分配是连续的。所以性能快。
② 内存分配方面的区别:
- 堆 因为是不连续的,所以分配的内存是在运行期确认的,因此大小不固定。一般堆大小远远大于虚拟机栈。
- 虚拟机栈 是连续的,所以分配的内存大小要在编译期就确认,大小是固定的。
③ 存放的内容方面的区别:
- 堆 存放的是对象的实例和数组。因此该区更关注的是数据的存储。
- 虚拟机栈 存放的是局部变量,操作数栈,返回结果。该区更关注的是程序方法的执行。
注:静态变量放在方法区,而静态的对象还是放在堆。
④ 线程共享方面的区别:
- 堆 对于整个应用程序都是共享、可见的。
- 虚拟机栈 只对于线程是可见的。所以也是线程私有。他的生命周期和线程相同。
总结
文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,后续会亿点点的更新!也希望大家关注脚本之家其他文章!