简介
OpenMLDB是针对AI场景优化的开源数据库项目,实现了数据与计算一致性的离线MPP场景和在线OLTP场景计算引擎。MPP引擎可基于Spark实现,并通过拓展Spark源码实现数倍性能提升。本文主要解释OpenMLDB如何基于Spark来解决窗口数据的倾斜问题。
背景
数据倾斜是在大数据处理场景下常见的一种现象,它由某一分区数据量过大造成。数据倾斜会导致倾斜分区与其他分区的运算时间产生巨大差距,换句话说就是倾斜数据分区的计算任务与其cpu资源严重不匹配。最终会造成多等一的情况——多个小数据量的分区计算完毕后等待倾斜的大数据量分区,只有倾斜分区计算完毕才能输出结果。这对效率来说是巨大的灾难。
在机器学习的特征计算中,涉及到很多的窗口计算。在窗口计算下,如果出现单一key数据量过大,也会导致某一分区数据过多,从而产生数据倾斜问题。而传统数据倾斜中分区优化的方案,如:数据加前缀再分区,是不适合窗口计算场景的。它会导致窗口计算场景下最终计算结果错误。因此OpenMLDB提出了一种基于Spark的窗口数据倾斜分区优化方案——在扩充窗口数据后,再根据分区键以及时间片对倾斜数据进行再分区。
数据倾斜介绍
SELECT sum(Amount) OVER w AS sum,
FROM input
WINDOW w as (PARTITION By Gender Order By Time ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
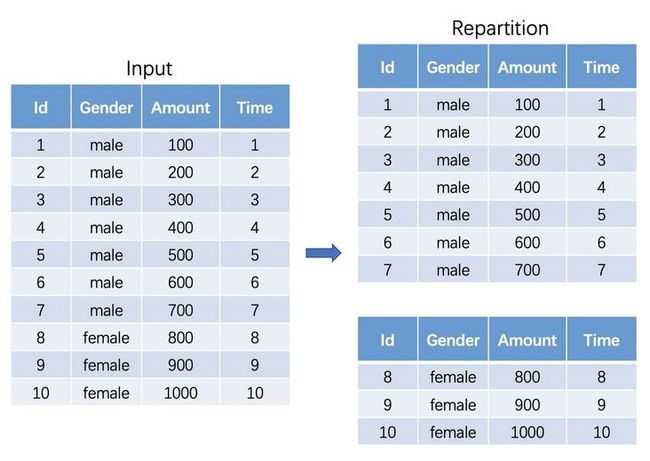
在上图的数据中,因为主键“Gender”只有两个值,离线计算最好情况下只能将数据划分到两个partition,即并行度只有2。此时同样的分区资源,计算任务的数据量差距却很大。在后续的计算中,“male”所在的分区计算的时间必然比“female”所在分区计算的时间大。当倾斜分区数据量变大的时候,这个时间差距还会被不断拉大。且由于spark的底层执行里每个partition只有一个thread,这使得整个stage周期里只有两个thread在工作,还有很多其他的thread一直处于空闲状态,这也会导致严重的性能浪费。
传统数据倾斜解决方案
对于倾斜数据的优化,解决根本问题的方法就是对倾斜数据进行再分区,把原本一个倾斜分区内庞大的数据块,分散成多个小的数据分区。以此来达到对大数据进行拆分从而提高计算效率的目的。
在常见的数据再分区策略中,有通过分区键加上不同前缀从而进行再分区的策略,也有通过多加几列作为分区键进行再分区的策略。但是这些简单的再分区方案,在窗口计算中,都会造成计算错误。
如果采用数据加前缀再分区的简单分区优化方案,原本同一个partition下的数据会被拆分到不同的partition。而窗口计算涉及到数据之间滑动取值的情况,因此如果只是简单的将分区内的数据再拆分,窗口计算将无法取到原本相邻的数据,这会导致最终计算结果的错误。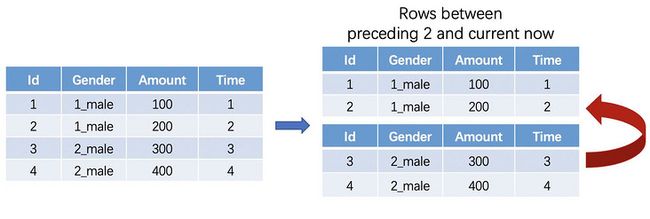
OpenMLDB窗口倾斜优化方案
整体思路
我们的方案总体思路是在上述倾斜数据再分区的基础上,进一步保证各个再分区的数据块在窗口计算时结果正确。方案里采用的方式是在每个再分区的数据块中,根据窗口需要滑动的数据条数,进行一定的窗口数据扩充。
在优化中,总体上采用的就是再分区+窗口补充的repartition策略来对数据进行分区。思路是采用空间换时间的策略,优点是计算时间短性能高,缺点是补充的窗口数据会造成一定的数据冗余,导致占用更多内存。
下面详细介绍本方案的技术细节,倾斜优化方案具体的实现主要分为五步,以下面SQL为例。
SELECT SUM(Amount) OVER W1 AS sum
FROM InputTable
WINDOW W1 AS (PARTITION BY Gender ORDER BY Time ROWS PRECEDING 2 AND CURRENT ROW)第一步:数据评估——统计窗口分区键的数据分布
这一步需要对总体的数据做一个评估,统计出一些相关的指标,比如数据划分的分界线,以及partition内数据的条数等。参数介绍如下。
| 参数名 | 解释 |
|---|---|
| Quantile | 对于数据的拆分是通过传入的“Quantile”参数来确定的,并且我们采用的是n等分的机制,Quantile = 4代表了四等分(不一定能保证严格四等分)。根据“Quantile”参数,我们就可以划分出来不同值的分界线“percentile_i”,根据数据相对于分界线的值可以划分出不同的数据块。 |
| PRECENTILE | 根据(“Time“)列(SQL中窗口里Order By的值)划分数据块的分界线,PERCENTILE_i为第i条分界线,(”Time“)列符合(PERCENTILE_i,PERCENTILE_i+1] 的数据为第i个数据块。特殊情况:第一个数据块为(0,PERCENTILE_1],最后一块为(PERCENTILE_n,无穷大) |
总体来说,第一步的数据评估是对数据各项指标进行统计和计算,并在统计后,对数据进行判断以及处理,但由于涉及到全量数据的遍历,会比较耗时。对此我们也有一个额外的优化,我们支持通过读取提前预处理好的distribution表来跳过第一步中统计的部分。这样就可以在凌晨或者不需要处理业务时,执行统计任务,将数据结果统计完成,来避免用户需要执行处理逻辑时,在第一步等待时间太久。
// Use skew config
val distributionDf = ctx.getSparkSession.read.parquet(ctx.getConf.windowSkewOptConfig)
logger.info("Load distribution dataframe")第二步:数据标记——标记重新分区的编号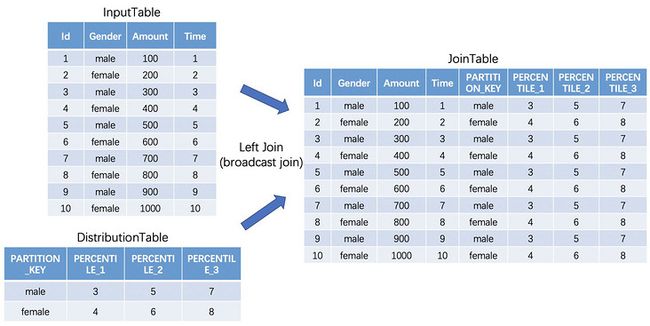
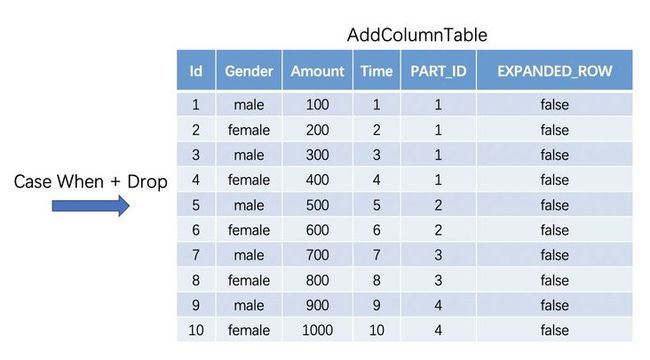
这一步根据Distribution Table中对数据的统计结果,来对数据进行划分,并对划分后的数据打上(“PART_ID”)和(“EXPANDED_ROW"),作为不同数据块重分区后的分区标号以及是否为扩充数据的标记。
在最开始的Join中,我们采用了Broadcast Join,来提升Join时的效率。Broadcast Join是Spark中一种可以避免shuffle的Join,一般一张大表和一张小表进行Join时可以使用Broadcast Join,它是通过将小表的数据广播到每个Executor计算节点上,再通过map聚合的方式,来避免了数据的shuffle。在我们的表中,Distribution Table比Input Table小很多,因此刚好可以采用Broadcast Join。
在Join之后,可以得到数据分界线,且当PERCENTILE_i为第i条分界线时,符合(PERCENTILE_i,PERCENTILE_i+1] 的数据就为第i个数据块,采用固定策略划分完结果之后。就可以根据划分结果,生成新的分区标号——“PART_ID”。表数据介绍如下。
| 列名 | 解释 |
|---|---|
| PART_ID | 代表了再分区的ID,在AddColumnTable中,“PART_ID”+分区键相同的行,就同属于一个新的partition,如Id = 1和Id = 3这两行同属于一个分区。 |
| EXPANDED_ROW | 代表了当前行是否是扩充的窗口数据,默认值为false。在下述步 |
第三步:数据扩充——对不同分块的数据进行窗口数据的扩充
对窗口数据进行扩充是OpenMLDB关于窗口倾斜优化中,比较核心的部分。由于数据较多,为了便于理解,下面只展示“male”部分数据。
具体实现时,我们对每个需要扩充的数据块进行全体窗口数据的扩充,即通过遍历,对每个需要扩充数据的重分区数据块都扩充到第一条数据。过程图解如下,深色代表当前遍历的分区,浅色代表当前分区需要补充的窗口数据。
1.过滤出需要扩充的数据
对于Time为1和3,“PART_ID" = 1的第一个重分区数据块,由于是时间最先的数据块,上面已经没有数据可以给他们补充了,因此会跳过。
对于Time为5,“PART_ID" = 2的第二个重分区数据块,会将所有时间比当前数据块前的数据都取出来,也就是“PART_ID" = 1的数据块。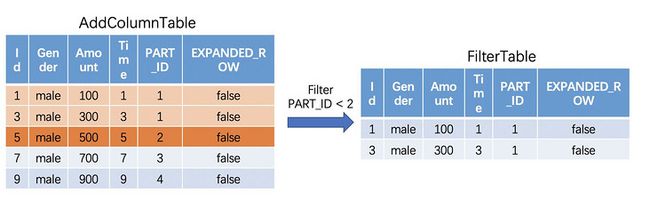
对于Time为7,“PART_ID" = 3的第三个重分区数据块同理,将所有时间比当前数据块前的数据都取出来,也就是取第一个和第二个数据块作为扩充的窗口数据。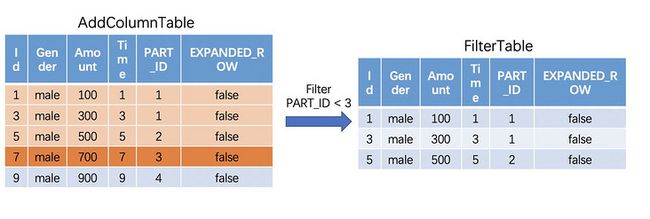
后续第四个重分区数据块也同上,将所有需要的数据取出,因此不再赘述。
2.更改过滤数据的ID并进行Union
将数据取出来之后,我们还需要将(“EXPANDED_ROW")改成true,代表是扩充的窗口数据。改完(“EXPANDED_ROW")之后,只需要不断的和原来的AddColumn Table进行Union,我们就完成了一个数据块的窗口数据扩充。以第二块数据块为例子,下图Union Table中,不同颜色代表不同的重分区数据块,可以看到经过filter和union,第二块数据块已经扩充好了数据。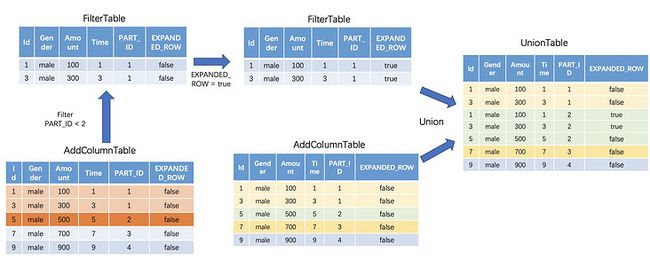
对于其他数据块窗口扩充的方式和第二块数据块方式的思路一样,在过滤以及扩充完后,再和之前的Union表进行Unoin即可。
下面展示最终第四块数据块扩充完窗口上数据后得到的最终Union Table。
第四步:数据分区——根据再分区键进行重新分区
虽然之前我们通过不同色块来标记不同的再分区数据,但实际上,到了第四步,我们才真正的对数据进行了重分区,底层我们依赖了Spark中的repartition函数进行数据重分区。在第三步后,我们可以得到最终的Union Table,此时只需要根据分区键(“Gender”)和(“PART_ID")进行repartition,就可以将数据拆分到不同的executor上。
第五步:数据计算——对分区后的数据进行计算
在第三步中,我们知道那些"EXPANDED_ROW" = false的数据列是新补充进来的窗口数据,而且在实际计算中,他们是不需要参与计算的。因此只需要对"EXPANDED_ROW" = true的数据进行窗口计算,最终便可得到计算结果。
值得特别说明的是,由于OpenMLDB底层处理引擎是自主研发设计的,因此窗口计算的内部逻辑也是由OpenMLDB实现的。下面贴出相关代码进行讲解。
repartitionDf.rdd.mapPartitionsWithIndex {
case (partitionIndex, iter) =>
val computer = WindowAggPlanUtil.createComputer(partitionIndex, hadoopConf, sparkFeConfig, windowAggConfig)
windowAggIter(computer, iter, sparkFeConfig, windowAggConfig)
}对于第四步生成的repartitionDf,我们在外层调用了Spark的mapPartitionsWithIndex方法。之后对于每个分区,OpenMLDB都构建一个computer计算单元,用来处理接下来的窗口计算。之后则是正式进行窗口计算,调用windowAggIter方法。
InputIter.flatMap(row => {
if (lastRow != null) {
computer.checkPartition(row, lastRow)
}
lastRow = row
val orderKey = computer.extractKey(row)
val expandedFlag = row.getBoolean(config.expandedFlagIdx)
if (!isValidOrder(orderKey)) {
None
} else if (!expandedFlag) {
Some(computer.compute(row, orderKey, config.keepIndexColumn, config.unionFlagIdx))
} else {
computer.bufferRowOnly(row, orderKey)
None
}
})在windowAggIter方法里,我们对传进来的迭代器InputIter进行了flatMap操作,之后再检查是否分区内数据有没有分错,如果有分错的row,则会对window进行重新设置。接下来检查orderKey没有问题后,会对expandedFlag也就是上图中的(“EXPANDED_ROW")作判断,如果为true,则证明当前row是扩充的数据,因此computer计算单元只进行buffeRowOnly操作,缓存扩充的窗口数据进内存,为之后真实需要计算的数据使用。如果为false,此时expandedFlag也为false,computer计算单元就进行真正的计算compute,在compute方法里会读取之前缓存的数据并进行计算,之后会返回处理完成的row。compute方法内部是由c实现的,有兴趣的同学可以去查看OpenMLDB里相关源码。
性能对比测试
Benchmark性能测试使用Kaggle公开数据集,也就是New York City Taxi Trip Duration竞赛的数据集,使用测试的SQL语句如下:
SELECT
sum(vendor_id) over w as w_sum_vendor_id,
max(vendor_id) over w as w_max_vendor_id,
min(vendor_id) over w as w_min_vendor_id,
avg(vendor_id) over w as w_avg_vendor_id,
sum(pickup_longitude) over w as w_sum_pickup_longitude,
max(pickup_longitude) over w as w_max_pickup_longitude,
min(pickup_longitude) over w as w_min_pickup_longitude,
avg(pickup_longitude) over w as w_avg_pickup_longitude
FROM taxi_skew_all
WINDOW w as (partition by vendor_id order by pickup_datetime ROWS BETWEEN 10000 PRECEDING AND CURRENT ROW)对比开源版本SparkSQL以及开源版本OpenMLDB进行测试,测试结果如下。
| 计算引擎 | 计算耗时 |
|---|---|
| SparkSQL(Spark 3.0.0) | 950.98s |
| OpenMLDB,未开启倾斜优化 | 224.76s |
| OpenMLDB,开启倾斜优化,倾斜分区数2 | 140.74s |
| OpenMLDB,开启倾斜优化,倾斜分区数4 | 94.44s |
可以看到,OpenMLDB引擎即使在不开启倾斜优化的情况下,在不同的倾斜比例中,相对于Spark引擎,仍然有4倍以上的性能提升,这种性能提升主要是通过OpenMLDB底层高效的引擎实现来保证的。而OpenMLDB在开启了窗口倾斜优化之后,通过调整不同的再分区数,相比OpenMLDB不开启倾斜优化也还能提升大约60%~140%的性能。
总结
OpenMLDB通过扩充窗口数据加上数据再分区的策略,实现了窗口计算下数据倾斜的优化。策略总体上采用了空间换时间的思想,即将原本集中在一个分区中的倾斜数据,在存储空间上进行窗口数据的扩充,之后再将数据分散至多个分区并行计算,从而增加计算的并行度,来换取更短的计算时间,并在最终实现了效率的大幅提升。此外在数据测试中,我们发现越在极端的倾斜分布下,OpenMLDB越有更好的表现。总的来说,对于窗口计算下的数据倾斜场景,OpenMLDB实现的数据倾斜优化有着不错的效果。
本文介绍了常见的滑动窗口数据倾斜问题,并且剖析了OpenMLDB解决数据倾斜的实现方案以及展示最终的性能优化结果。如果你对Spark优化、大规模特征计算、OpenMLDB数据库等感兴趣,我们会分享更多类似的技术文章,欢迎大家继续关注 OpenMLDB专栏 。