An image is worth 16x16 words: Transformers for image recognition at scale 论文学习
论文地址:https://arxiv.org/pdf/2010.11929.pdf
Abstract
尽管 Transformer 结构已经成为 NLP 领域的一个事实上的标准方法,它在计算机视觉领域中的应用仍受限制。在视觉领域,注意力要么与卷积网络搭配使用,要么替换掉卷积网络中的特定组成,保留其整体结构。作者证明我们并不是一定要依赖 CNN,直接用 Transformer 对图像块序列做预测也能在图像分类任务上取得不错的表现。当我们在大规模数据集上预训练,然后再在多个中等规模或小规模数据集(ImageNet、CIFAR-100、VTAB 等)上做迁移学习,ViT 所取得的表现和 SOTA 卷积网络相比非常优异,但所需的训练资源要明显地少。
1. Introduction
基于自注意力的结构,如 Transformer 已经成为 NLP 领域的不二选择。在大规模文本语料库上预训练,然后在小规模、特定任务的数据集上微调。因为 Transformer 在计算效率和规模性方面都很优秀,我们就有可以去训练超大规模的模型,比如超过一千亿个参数。随着模型和数据集增大,它也没有出现任何饱和的现象。
但在计算机视觉领域,卷积网络仍然主导。受到 NLP 的启发,不少工作开始尝试在 CNN 结构中结合使用自注意力机制,有些完全替换掉了卷积层。尽管后来的模型在理论上要高效,但因为特殊设计的注意力模式,无法在目前的硬件加速器上呈规模使用。因此,在大规模图像识别领域,经典的 ResNet 结构仍然是 SOTA 的。
受到 NLP 领域中 Transformer 的启发,作者直接将一个标准的 Transformer 应用到图像上去,修改尽可能地少。作者将图像分割为图像块,将这些图像块的线性 embeddings 序列作为 Transformer 的输入。这些图像块的处理方式就类似于 NLP 中的 tokens(words)。作者以监督的方式,在图像分类数据集上训练该模型。
当我们在中等规模的数据集(如 ImageNet)上训练模型时,这些模型的准确率要比 ResNets 低一些。这种结果是可以预料到的:Transformer 缺乏 CNN 中的一些归纳偏置,如平移不变性和定位,因此当训练数据不够时,泛化能力就不强。
但是如果我们在更大规模的数据集(1400万张-3000万张图像)上训练,结果就不一样了。作者发现,大规模的训练可以战胜归纳偏置。当我们在大规模数据集上预训练,然后迁移到中小规模的数据集上时,ViT 可以取得优异的表现。当我们在 ImageNet-21k 数据集或 JFT-300M 数据集上预训练,ViT 在多个基准上的表现就接近于现有的 SOTA 方法。在 ImageNet 上,最佳的模型取得了 88.55 % 88.55\% 88.55% 的准确率,在 ImageNet-ReaL 上,取得了 90.72 % 90.72\% 90.72%的准确率,在 Cifar-100 上,取得了 94.55 % 94.55\% 94.55% 的准确率,在 VTAB 上取得了 77.63 77.63 77.63 的准确率。
2. Related Work
Transformer 是 Vaswani 等人于 2017 年提出来的,用于机器翻译。自提出以来,已经成为 NLP 任务的 SOTA 方法。基于 Transformer 的模型通常在大规模语料库上预训练,然后对手头任务进行微调:BERT 使用了一个去噪的自监督预训练任务,而 GPT 则将语言建模作为预训练任务使用。
对图像简单地使用自注意力,需要每个像素点都能关注到其它像素点。因为像素点的个数是平方的,这就无法用于实际的输入大小。因此,为了将 Transformer 用于图像处理任务,人们尝试了多个近似方法:Parmar 等人只在局部邻近区域而非全局,对每个 query 像素点使用自注意力。该局部 multi-head 点积自注意力模块能够完全代替卷积操作。Sparse Transformers 使用类似于全局自注意力的操作,应用在图像领域。另一个替代方案就是在大小变动的模块内使用注意力,在极端案例中只沿着单个轴来使用。这些特殊设计的注意力结构证明,我们可以在计算机视觉任务上使用注意力机制,但是实现起来非常复杂,才能应用在硬件加速器上。
我们不清楚 Transformer 之前的应用,如何使用全局自注意力机制对全尺寸图像做处理。与本文模型最接近的就是 iGPT,它首先降低图像的分辨率和色彩空间,然后使用 Transformer 对图像像素点做处理。它以非监督的方式、作为生成模型来训练,然后可以对输出的表示做微调,在 ImageNet 上得到的最高准确率是 72 % 72\% 72%。
本文探索了如何在更大规模数据集(超过 ImageNet)上进行图像识别。由于使用了额外的数据资源,本文方法在标准基准上得到了 SOTA 结果。而且,Sun 等人研究了 CNN 的性能与数据集规模的关系,Kolesnikov 等人和 Djolonga 等人则探索了 CNN 在大规模数据集上的迁移学习,如 ImageNet-21k 和 JFT-300M。作者也使用了这两个数据集,但用的是 Transformer 模型,而非 ResNet 模型。
3. 方法
在模型设计方面,作者尽可能地依照 Transformer 的设计。这样做的一个好处就是,NLP 领域中可扩展的 Transformer 结构及其实现都是现成的。
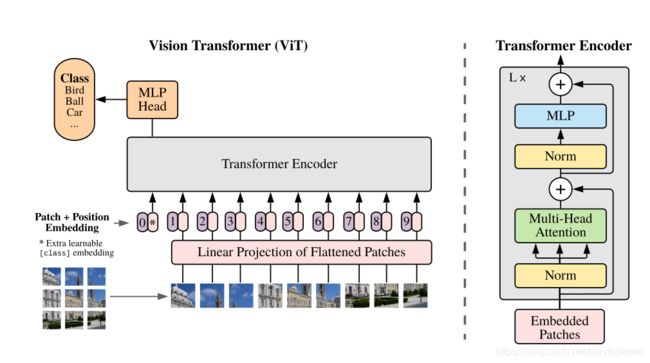
图1. 模型概览。我们将一张图片切分为固定大小的图像块,线性地嵌入每个图像块和位置 embeddings,将得到的向量序列输入进标准的 Transformer 编码器。我们在序列中增加一个额外的可学习的“分类 token”,来进行分类任务。Transformer 编码器来自于 Vaswani 等人 2017 年提出的方法。
3.1 视觉 Transformer (ViT)
图1 展示了 ViT 模型的结构。标准 Transformer 将一个一维的 token embeddings 序列作为输入。为了处理二维图像,作者重新调整图像 x ∈ R H × W × C x\in \mathbb{R}^{H\times W\times C} x∈RH×W×C的形状,得到一个二维图像块 x p ∈ R N × ( P 2 ⋅ C ) x_p\in \mathbb{R}^{N\times (P^2\cdot C)} xp∈RN×(P2⋅C)的序列,其中 ( H , W ) (H,W) (H,W)是原始图像的分辨率, C C C是通道数, ( P , P ) (P,P) (P,P)是每个图像块的分辨率, N = H W / P 2 N=HW/P^2 N=HW/P2是图像块的个数,作为 Transformer 的有效输入序列长度。Transformer 在所有的层中使用一个隐藏向量大小 D D D,它是一个常量,所以我们就压平这些图像块,通过一个可训练的线性映射将其映射到 D D D 维。
与 BERT 的 [class] token 相似,作者在嵌入的图像块( z 0 0 = x c l a s s z_0^0=x_{class} z00=xclass)序列前添加了一个可学习的 embedding,它在 Transformer 编码器 ( z L 0 ) (z_L^0) (zL0)输出位置的状态作为图像表示 y y y(等式4)使用。在预训练和微调时,在 z L 0 z_L^0 zL0上面有一个分类 head。分类 head 是通过 MLP 实现的,在预训练时通过一个隐藏层实现,在微调时通过一个简单的线性层实现。
在图像块 embeddings 中也加入了位置 embeddings,从而保留位置信息。作者使用标准的可学习的 1D 位置 embeddings,因为使用2D 位置 embeddings,没有得到著的性能提升。Embedding 向量序列会作为编码器的输入。
Transformer 编码器由 multiheaded 自注意力 (MSA) 机制和 MLP 模块组成。在每个模块之前使用层归一化(LN),在每个模块后使用残差连接。MLP 包括2层和 GELU 非线性函数。

混合架构。输入序列也可以用 CNN 的特征图来代替。在这个混合模型中,我们对 CNN 特征图中提取的图像块进行图块 embedding 映射 E E E。举个例子,图块的空间大小可以是 1 × 1 1\times 1 1×1,我们通过简单地将特征图的空间维度压平并映射到 Transformer 维度,得到输入序列。然后加入分类输入 embedding 和位置 embeddings。
3.2 微调和更高的分辨率
通常,作者在大规模数据集上预训练 ViT 模型,然后在较小的数据集和任务上进行微调。为此,作者去除了预训练的预测 head,加入了一个初始值为0的 D × K D\times K D×K的前向层,其中 K K K是类别个数。在更高分辨率的图像上进行微调,通常是有帮助的。当输入高分辨率图像时,保持图块的大小是一样的,这样就得到一个更长的有效序列长度。Vision Transformer 能够处理任意长度的序列(取决于内存大小),但是预训练的位置 embeddings 可能就不再有用了。因此,作者对 2D 位置 embeddings 做了 2D 插值,根据它们在原始图像中的位置。注意,这个分辨率调整和图块提取是唯一的一处,往 Vision Transformer 中人为注入关于图像 2D 结构的归纳偏置的地方。