python必备知识点
目录:
- 字符串的格式化输出
- 切片(彻底搞懂)
- 列表生成式
- 生成器
- 异常与错误处理
- assert
字符串的格式化输出
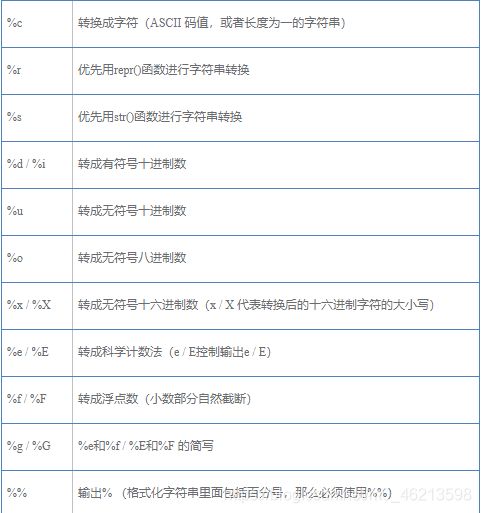
1.%
代码举例:
#例1:
accuracy = 80/123
print('模型正确率是%s!' % accuracy)
#例2(保留两位小数):
accuracy = 80/123
print('模型正确率是%.2f!' % accuracy)
#例3:
name = 'jack'
hight = 170.4
score_math = 95
score_english = 89
print('大家好!我叫%s,我的身高是%d cm, 数学成绩%.2f分,英语成绩%d分' % (name, hight, score_math, score_english))
结果:
#结果1:
模型正确率是0.6504065040650406!
#结果2:
模型正确率是0.65!
#结果3:
大家好!我叫jack,我的身高是170 cm, 数学成绩95.00分,英语成绩89分
2.format
注意:
指定了“: s ,则只能传字符串值,如果传其他类型值不会自动转换
当你不指定类型时,你传任何类型都能成功,如无特殊必要,可以不用指定类型
代码举例:
#例1:
print('大家好!我叫{},我的身高是{:d} cm, 数学成绩{:.2f}分,英语成绩{}分'.format(name, int(hight), score_math, score_english))
#例2:
设置顺序:
'Hello, {0}, 成绩提升了{1:.1f}分,百分比为 {2:.1f}%'\
.format('小明', 6, 17.523)#将按照传参的下标依次传入字符串中
#例3:
指定待传值名称:
'Hello, {name:}, 成绩提升了{score:.1f}分,百分比为 {percent:.1f}%'\
.format(name='小明',
score=6,
percent = 17.523)
结果:
#结果1:
大家好!我叫jack,我的身高是170 cm, 数学成绩95.00分,英语成绩89分
#结果2:
'Hello, 小明, 成绩提升了6.0分,百分比为 17.5%'
#结果3:
'Hello, 小明, 成绩提升了6.0分,百分比为 17.5%'
3.一种可读性更好的方法 f-string
python3.6版本新加入的形式
代码举例:
name = 'Jack'
hight = 170.4
score_math = 95
score_english = 89
print(f"大家好!我叫{
name},我的身高是{
hight:.3f} cm, 数学成绩{
score_math}分,英语成绩{
score_english}分")
结果:
大家好!我叫Jack,我的身高是170.400 cm, 数学成绩95分,英语成绩89分
2.切片(彻底搞懂)
利用python解决问题的过程中,经常会遇到从某个对象中抽取部分值的情况。“切片”操作正是专门用于实现这一目标的有力武器。理论上,只要条件表达式得当,可以通过单次或多次切片操作实现任意目标值切取。切片操作的基本语法比较简单,但如果不彻底搞清楚内在逻辑,也极容易产生错误,而且这种错误有时隐蔽得较深,难以察觉。本文通过详细例子总结归纳了切片操作的各种情形,下文均以list类型作为实验对象,其结论可推广至其他可切片对象。
切片包括:正索引和负索引两部分,如下图所示,以list对象a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]为例:
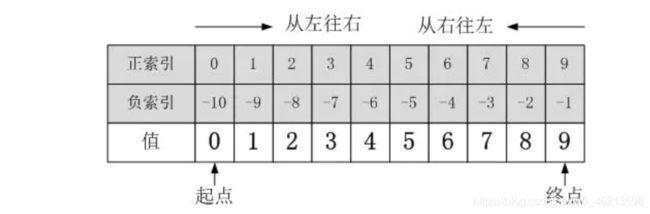
Python切片操作的一般方式
一个完整的切片表达式包含两个“:”,用于分隔三个参数(start_index、end_index、step)。当只有一个“:”时,默认第三个参数step=1;当一个“:”也没有时,start_index=end_index,表示切取start_index指定的那个元素。
切片操作基本表达式:object[start_index:end_index:step]
step:正负数均可,其绝对值大小决定了切取数据时的‘‘步长”,而正负号决定了“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以步长1取值。“切取方向非常重要!”“切取方向非常重要!”“切取方向非常重要!”,重要的事情说三遍!
start_index:表示起始索引(包含该索引对应值);该参数省略时,表示从对象“端点”开始取值,至于是从“起点”还是从“终点”开始,则由step参数的正负决定,step为正从“起点”开始,为负从“终点”开始。
end_index:表示终止索引(不包含该索引对应值);该参数省略时,表示一直取到数据“端点”,至于是到“起点”还是到“终点”,同样由step参数的正负决定,step为正时直到“终点”,为负时直到“起点”。
例子展示:
以下示例均以list对象a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]为例:
1. 切取单个元素
>>>a[0]
>>>0
>>>a[-4]
>>>6
当索引只有一个数时,表示切取某一个元素。
2. 切取完整对象
>>>a[:] #从左往右
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>a[::]#从左往右
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>a[::-1]#从右往左
>>> [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
3.start_index和end_index全为正(+)索引的情况
>>>a[1:6]
>>> [1, 2, 3, 4, 5]
step=1,从左往右取值,start_index=1到end_index=6同样表示从左往右取值。
>>>a[1:6:-1]
>>> []
输出为空列表,说明没取到数据。
step=-1,决定了从右往左取值,而start_index=1到end_index=6决定了从左往右取值,两者矛盾,所以为空。
>>>a[6:2]
>>> []
同样输出为空列表。
step=1,决定了从左往右取值,而start_index=6到end_index=2决定了从右往左取值,两者矛盾,所以为空。
>>>a[:6:-1]
>>> [9, 8, 7]
step=-1,从右往左取值,而start_index省略时,表示从端点开始,因此这里的端点是“终点”,即从“终点”值9开始一直取到end_index=6(该点不包括)。
>>>a[6::-1]
>>> [6, 5, 4, 3, 2, 1, 0]
step=-1,从右往左取值,从start_index=6开始,一直取到“起点”0。
4.start_index和end_index全为负(-)索引的情况
>>>a[-1:-6]
>>> []
step=1,从左往右取值,而start_index=-1到end_index=-6决定了从右往左取值,两者矛盾,所以为空。
索引-1在-6的右边
>>>a[-1:-6:-1]
>>> [9, 8, 7, 6, 5]
step=-1,从右往左取值,start_index=-1到end_index=-6同样是从右往左取值。
索引-1在6的右边
>>>a[-6:-1]
>>> [4, 5, 6, 7, 8]
step=1,从左往右取值,而start_index=-6到end_index=-1同样是从左往右取值。
索引-6在-1的左边
>>>a[:-6]
>>> [0, 1, 2, 3]
step=1,从左往右取值,从“起点”开始一直取到end_index=-6(该点不包括)。
5. start_index和end_index正(+)负(-)混合索引的情况
>>>a[1:-6]
>>> [1, 2, 3]
start_index=1在end_index=-6的左边,因此从左往右取值,而step=1同样决定了从左往右取值,因此结果正确
>>>a[1:-6:-1]
>>> []
start_index=1在end_index=-6的左边,因此从左往右取值,但step=-则决定了从右往左取值,两者矛盾,因此为空。
6. 多层切片操作
>>>a[:8][2:5][-1:]
>>> [4]
相当于:
a[:8]=[0, 1, 2, 3, 4, 5, 6, 7]
a[:8][2:5]= [2, 3, 4]
a[:8][2:5][-1:] = [4]
理论上可无限次多层切片操作,只要上一次返回的是非空可切片对象即可。
7. 切片操作的三个参数可以用表达式
>>>a[2+1:3*2:7%3]
>>> [3, 4, 5]
即:a[2+1:3*2:7%3] = a[3:6:1]
8. 其他对象的切片操作
前面的切片操作以list对象为例进行说明,但实际上可进行切片操作的数据类型还有很多,包括元组、字符串等等。
>>> (0, 1, 2, 3, 4, 5)[:3]
>>> (0, 1, 2)
元组的切片操作
>>>'ABCDEFG'[::2]
>>>'ACEG'
字符串的切片操作
>>>for i in range(1,100)[2::3][-5:]:
print(i)
>>>87
90
93
96
99
就是利用range()函数生成1-99的整数,然后从start_index=2(即3)开始以step=3取值,直到终点,再在新序列中取最后五个数。
9.常用切片操作:
1.取偶数位置
>>>b = a[::2]
[0, 2, 4, 6, 8]
2.取奇数位置
>>>b = a[1::2]
[1, 3, 5, 7, 9]
3.拷贝整个对象
>>>b = a[:] #
>>>print(b) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>print(id(a)) #41946376
>>>print(id(b)) #41921864
或
>>>b = a.copy()
>>>print(b) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>print(id(a)) #39783752
>>>print(id(b)) #39759176
注意:
需要注意的是:[:]和.copy()都属于“浅拷贝”,只拷贝最外层元素,内层嵌套元素则通过引用方式共享,而非独立分配内存
4.修改单个元素
>>>a[3] = ['A','B']
[0, 1, 2, ['A', 'B'], 4, 5, 6, 7, 8, 9]
5.在某个位置插入元素
>>a[3:3] = ['A','B','C']
[0, 1, 2, 'A', 'B', 'C', 3, 4, 5, 6, 7, 8, 9]
>>>a[0:0] = ['A','B']
['A', 'B', 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
6.替换一部分元素
>>>a[3:6] = ['A','B']
[0, 1, 2, 'A', 'B', 6, 7, 8, 9]
总结
(一)start_index、end_index、step三者可同为正、同为负,或正负混合。但必须遵循一个原则,即:当start_index表示的实际位置在end_index的左边时,从左往右取值,此时step必须是正数(同样表示从左往右);当start_index表示的实际位置在end_index的右边时,表示从右往左取值,此时step必须是负数(同样表示从右往左),即两者的取值顺序必须相同。
(二)当start_index或end_index省略时,取值的起始索引和终止索引由step的正负来决定,这种情况不会有取值方向矛盾(即不会返回空列表[]),但正和负取到的结果顺序是相反的,因为一个向左一个向右。
(三)step的正负是必须要考虑的,尤其是当step省略时。比如a[-1:],很容易就误认为是从“终点”开始一直取到“起点”,即a[-1:]= [9, 8, 7, 6, 5, 4, 3, 2, 1, 0],但实际上a[-1:]=[9](注意不是9),原因在于step省略时step=1表示从左往右取值,而起始索引start_index=-1本身就是对象的最右边元素了,再往右已经没数据了,因此结果只含有9一个元素。
(四)需要注意:“取单个元素(不带“:”)”时,返回的是对象的某个元素,其类型由元素本身的类型决定,而与母对象无关,如上面的a[0]=0、a[-4]=6,元素0和6都是“数值型”,而母对象a却是“list”型;“取连续切片(带“:”)”时,返回结果的类型与母对象相同,哪怕切取的连续切片只包含一个元素,如上面的a[-1:]=[9],返回的是一个只包含元素“9”的list,而非数值型“9”。
3.列表生成式
- 列表生成式:python内置非常简单却强大的可以用来创建list的生成式,列表生成式也可以叫做列表解析。
- 列表生成式的格式:[ expression for i in 序列 if …] == 表达式+循环+条件
- 运用列表生成式,可以写出非常简洁的代码。一般情况下循环太繁琐,而列表生成式则可以用一行语句代替多行循环生成列表。
代码举例:
例1:
# 1-10之间所有数的平方
l=[(n+1)**2 for n in range(10)]
print(l)
print(type(l))
例2:
# 1-10之间所有数的平方 构成的字符串列表
[str((n+1)**2) for n in range(10)]
例3:
list1 = ['a','b','a','d','a','f']
['app_%s'%n for n in range(10)]
例4:
list1 = ['a','b','a','d','a','f']
[f'app_{
n}' for n in range(10)]
例5:过滤偶数
list_1 = [1,2,3,4,5]
[n for n in list_1 if n%2==0]
例6:
# 字符串中所有以'sv'结尾的
list_2 = ['a','b','c_sv','d','e_sv']
[s for s in list_2 if s.endswith('sv')]
例7:
# 取两个list的交集
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]
[i for i in list_A if i in list_B]
例8:双重循环
[m + n for m in 'ABC' for n in 'XYZ']
结果:
结果1:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
<class 'list'>
结果2:
['1', '4', '9', '16', '25', '36', '49', '64', '81', '100']
结果3:
['app_0',
'app_1',
'app_2',
'app_3',
'app_4',
'app_5',
'app_6',
'app_7',
'app_8',
'app_9']
结果4:
['app_0',
'app_1',
'app_2',
'app_3',
'app_4',
'app_5',
'app_6',
'app_7',
'app_8',
'app_9']
结果5:
[2, 4]
结果6:
['c_sv', 'e_sv']
结果7:
[3, 6, 12]
结果8:
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
4.生成器
生成器定义
在Python中,一边循环一边计算的机制,称为生成器:generator。
为什么要有生成器?
列表所有数据都在内存中,如果有海量数据的话将会非常耗内存。
如:仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
如果列表元素按照某种算法推算出来,那我们就可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。
如何创建生成器?
方法1:
把一个列表生成式的[]改成(),就创建了一个generator:
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>
方法2:
如果一个函数中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。调用函数就是创建了一个生成器(generator)对象。
生成器工作原理:
(1)生成器(generator)能够迭代的关键是它有一个next()方法,
工作原理就是通过重复调用next()方法,直到捕获一个异常。
(2)带有 yield 的函数不再是一个普通函数,而是一个生成器generator。
可用next()调用生成器对象来取值。next 两种方式 t.next() | next(t)。
可用for 循环获取返回值(每执行一次,取生成器里面一个值)
(基本上不会用next()来获取下一个返回值,而是直接使用for循环来迭代)。
(3)yield相当于 return 返回一个值,并且记住这个返回的位置,下次迭代时,代码从yield的下一条语句开始执行。
(4).send() 和next()一样,都能让生成器继续往下走一步(下次遇到yield停),但send()能传一个值,这个值作为yield表达式整体的结果
——换句话说,就是send可以强行修改上一个yield表达式值。比如函数中有一个yield赋值,a = yield 5,第一次迭代到这里会返回5,a还没有赋值。第二次迭代时,使用.send(10),那么,就是强行修改yield 5表达式的值为10,本来是5的,那么a=10
代码举例:
def yield_test(n):
for i in range(n):
yield call(i)
print("i=",i)
print("Done.")
def call(i):
return i*2
for i in yield_test(5):
print(i,",")
结果:
0 ,
i= 0
2 ,
i= 1
4 ,
i= 2
6 ,
i= 3
8 ,
i= 4
Done.
5.异常与错误处理
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在 Python 无法正常处理程序时就会发生一个异常。
异常是 Python 对象,表示一个错误。
当 Python 脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
语法格式:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'名字'异常
except <名字>,<数据>:
<语句> #如果引发了'名字'异常,获得附加的数据
else:
<语句> #如果没有异常发生
finally:
<语句> #有没有异常都会执行
try 的工作原理是,当开始一个 try 语句后,Python 就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try 子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当 try 后的语句执行时发生异常,Python 就跳回到 try 并执行第一个匹配该异常的 except 子句,异常处理完毕,控制流就通过整个 try 语句(除非在处理异常时又引发新的异常)。
如果在 try 后的语句里发生了异常,却没有匹配的 except 子句,异常将被递交到上层的 try,或者到程序的最上层(这样将结束程序,并打印缺省的出错信息)。
代码举例:
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except:
print('有异常发生')
结果:
2
3
4
5
有异常发生
7
8
9
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print(i)
try:
list1[i]+=1
print(list1)
except IOError as e:
print(e)
print('输入输出异常')
except:
print('有错误发生')
else:
print('正确执行')
finally:
print('我总是会被执行')
结果:
0
[2, 2, 3, 4, '5', 6, 7, 8]
正确执行
我总是会被执行
1
[2, 3, 3, 4, '5', 6, 7, 8]
正确执行
我总是会被执行
2
[2, 3, 4, 4, '5', 6, 7, 8]
正确执行
我总是会被执行
3
[2, 3, 4, 5, '5', 6, 7, 8]
正确执行
我总是会被执行
4
有错误发生
我总是会被执行
5
[2, 3, 4, 5, '5', 7, 7, 8]
正确执行
我总是会被执行
6
[2, 3, 4, 5, '5', 7, 8, 8]
正确执行
我总是会被执行
7
[2, 3, 4, 5, '5', 7, 8, 9]
正确执行
我总是会被执行
异常的层层处理:
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数的定义和使用
return 10 / int(s)
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')
结果:
ZeroDivisionError Traceback (most recent call last)
<ipython-input-20-4a3f6c117995> in <module>
10 return group_leader(s)
11
---> 12 CTO('0')
<ipython-input-20-4a3f6c117995> in CTO(s)
8
9 def CTO(s):
---> 10 return group_leader(s)
11
12 CTO('0')
<ipython-input-20-4a3f6c117995> in group_leader(s)
5
6 def group_leader(s):
----> 7 return worker(s) * 2
8
9 def CTO(s):
<ipython-input-20-4a3f6c117995> in worker(s)
2 def worker(s):
3 # 这是一个函数 后面我们会详细介绍函数的定义和使用
----> 4 return 10 / int(s)
5
6 def group_leader(s):
ZeroDivisionError: division by zero
修改后的代码:
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数如何定义的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except ValueError as e:
print(e)
rst = '请修改输入'
return rst
def CTO(s):
return group_leader(s)
CTO('user')
结果:
invalid literal for int() with base 10: 'user'
'请修改输入'
6.assert
作用:检查程序,不符合条件即终止程序
Python assert(断言)用于判断一个表达式,在表达式条件为 False 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况。
语法格式:
assert expression
等价于:
if not expression:
raise AssertionError
assert后可跟参数:
assert expression[,assert_error_msg]
等价于:
if not expression:
raise AssertionError(assert_error_msg)
代码举例:
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
foo('0')
结果:
AssertionError: n is zero!