【图像Transformer论文理解】AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
0. 前言
本文是谷歌在2020年11月份发表的一篇关于Transformer的论文,目前文章的状态显示的还是Under review,也就是正在处理稿件的状态中。文章使用单纯的Transformer结构而抛弃CNN结构来进行图像识别。论文传送门
1. Abstract
Transformer已经被广泛地运用在NLP(自然语言处理)中。然而,在CV任务中的运用还十分有限。许多Attention方法还是运用在CNN中的,本质上还是离不开CNN,也可以说仅仅是对CNN的增强。本文作者认为Attention机制对CNN的这种依赖是没有必要的,一个完全的Transformer(Attention)结构就可以很好地完成图像分类任务,完全不需要CNN。本文作者就是基于这样一种想法,构建了Vision Transformer 结构,把图像分成小块组成图像序列作为输入,并且对它在几个常用的数据集上进行了训练。结果表明,完全的Transformer结构不仅准确度超过了传统的CNN,而且在计算效率上也优于CNN。
2. Introduction
Transformer有两个优点:计算效率高、可扩展性。Transformer运用在NLP时,可以先在大语料(text corpus,可以理解为NLP的训练集)上进行训练,然后通过微调来使其能够完成特定的NLP任务,这就是Transformer的优点之一——可扩展性。由于Transformer结构的计算效率高,可以让训练超过100亿参数的结构成为可能。随着参数和数据集的数量不断增多,训练出来的结构的性能也就越高,目前这个提高性能的方向还没有达到饱和,也就是说还能通过简单粗暴地增加参数的方式来提升网络的性能。
受NLP的启发,在Vision领域中,许多工作开始给CNN添加Attention结构,并且开始尝试使用Self-attention结构代替整个CNN,但是性能始终没有超过传统的CNN(如ResNet等)结构。
本文作者在较小的训练集上进行训练时,训练出来的VIT的性能低于ResNet。然而在较大的数据集上表现出的性能却很高。这说明Vision Transformer在面对大数据集时才能发挥出最好的性能。
3. Related work
这部分介绍了一些关于Transformer和一些注意力机制与CNN结合运用的有关工作,这里不做详细讨论。
4. Method
本文作者在构建模型时,直接使用了原始的NLP Transformer的结构(看样子有可能是直接用了Transformer的代码),因为它工作得非常好。
原始的Transformer论文链接:Attention Is All You Need
先看下整体的模型结构,如下图所示:
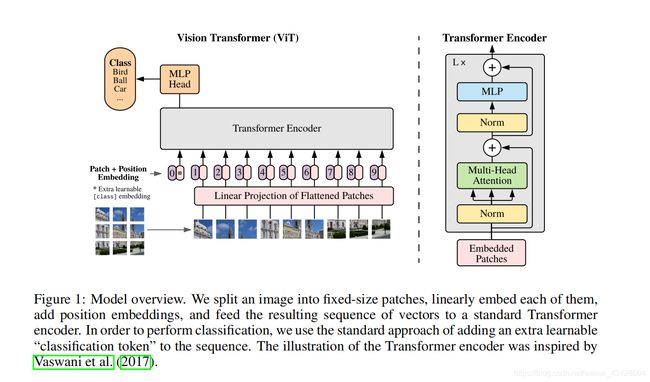
模型结构的整体组成其实没有太多需要解释的地方,在这个图里已经展示的非常简单清晰。图像被分成多个块经过Linear Projection of Flattened Patches变成了Patch Embeddings直接输入到原始的Transformer编码器中,最后经过MLP Head这样一个结构输出分类结果。
结构图不难理解,但是论文接着给出的四个公式确是很难理解(对我本人来说),公式如下:
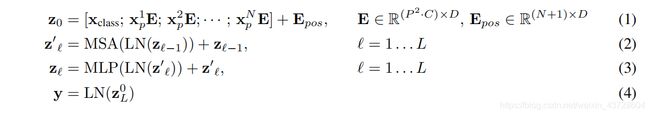
4.1 理解公式(1)
先来解释一下公式(1),其实公式(1)表示的就是Linear Projection of Flattened Patches模块以及后面增加Position Embedding的过程,也就是将图像块变成Patch Embeddings的过程。在图中对应的是下面的这个部分:
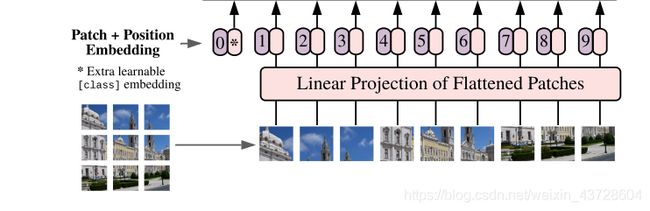
要理解公式(1),首先我们要知道实际上 z 0 z_0 z0是一个矩阵,矩阵的尺寸为 ( N + 1 ) ∗ D (N+1)*D (N+1)∗D,其中 N N N为Patch的个数,也就是图片总共分成的块数,而 D D D为隐藏向量(原文为constant latent vector)的维数, E E E也就是那个隐藏向量,Transformer正是利用这个隐藏向量将一维的Patch映射到 D D D维(一维的Patch是由二维的Patch展开而成,原文为flatten而成)。当然,对于这个隐藏向量,我始终还是不能很好地理解,就只能简单地把它看做是一个将图像Patch转换成Patch Embeddings的一种工具,并且从原文中来看,这个工具是可以被学习得到的(Learnable)。
公式(1)中的 E p o s E_{pos} Epos对应的就是图中所标的Position Embedding,也就是紫色小椭圆标号的0~9 。 在这里我感觉这个图其实有种误导,就是看着像是Patch Embedding 和 Position Embedding是Cat到一起的,但在公式中其实是相加的关系。实际上,最后输入给Transformer的序列是 N + 1 N+1 N+1个 D D D维的列向量。
公式(1)中的 x p k x_p^k xpk对应的就是第k个Patch,经过与 E E E相乘,就变成了Patch Embedding。感觉这个有图像块转成图像Embedding有些强行转换的意思,强行转换成类似于NLP中的Embedding(由于我本人主要研究Vision方向,对NLP中Embedding这个概念不是很理解,所以没办法给出一个很严谨的解释),这个转换看起来有些牵强,不过最后实现效果还是好的,所以可能这个转换还是有一定的道理。
公式(1)中的 x c l a s s x_{class} xclass对应图中的Extra learnable [class] embedding,文中说这个参数类似于NLP中的BERT’s(词向量) [class] token,对这个参数我也不是很能理解,不过看样子它也是可以通过学习来改变的,而且是与分类任务相关。
4.2 理解公式(2)(3)(4)
经过公式(1)的一系列神奇操作之后,我们就把一幅图像切分出来的几个块,变成了可以输入到Transformer中的Patch Embedding.
公式(2)(3)特别好理解,就是对应Transformer Encoder中的操作。公式中得 L N LN LN代表的是Layernorm操作,也就是图中的Norm层。LN操作其实是类似于BN的一种归一化操作,一般来说在CNN中我们使用LN,在RNN或者Transformer这样处理序列的网络中我们使用LN,关于LN的详细讲解大家可以参看知乎的一篇文章:模型优化之Layer Normalization。
公式(2)(3)中的MSA就对应图中的Multi-Head Attention模块,MLP对应图中的MLP模块,加号就是图中的残差结构,每个Patch Embedding都要经过 L L L个Transformer Encoder, z l z_l zl代表第 l l l个Encoder的输出。
关于公式(4), z l 0 z_l^0 zl0是 x c l a s s + E p o s x_{class}+E_{pos} xclass+Epos经过Encoder的输出,再经过Norm层就得到了 y y y。原文中只说了这个 y y y是一个图像表示,具体的作用我猜想可能是对后面的分类结果给出指导(因为它也输入了最后的MLP Head中)。
4.3 混合模型
这种VIT结构也可以与CNN结合变为一种混合模型。这种情况下,Patch Embedding是由CNN得到的特征图所映射而来。在一种更为特殊的情况下,Patch的尺寸可以为1*1.
4.4 预训练之后微调以适应其他的分类任务
本文提出的Vision Transformer经过预训练后,可以进行细微地调整以适应不同的分类任务。具体的做法就是直接移除原来的MLP-Head的结构,重新添加一个尺寸DxK的前向层,本质上来说就是一个初始值为0的新的MLP-Head,然后再对整体重新训练,就可以得到一个可以解决这个区分K类的新的分类任务。文中还说在进行微调时,新的样本集的图像如果分辨率越高,最后的分类效果就会越好。在图像分辨率提高时,相应的Position Embedding也要进行插值操作,这样才能够加到一起。
5.结语
由于本人对这篇论文的复现兴趣不大,所以就不在此说明有关的实验过程以及结果,有兴趣的同学可以直接查看原文。论文传送门。
总体来说这篇论文提出的新模型结构十分清晰,但是如果不了解Transformer的原始模型以及一些NLP的知识还是比较难理解,也会比较难复现。