Python爬取小说网站
感觉好像蛮久没用更新博客了,这不准备成人高考了嘛,作为中专毕业的我来说,觉得大专证还是会有一点用处滴,所以花了点时间看书,可惜每次看书,看着看着就找周先生聊天去了,哎,不知有没有大佬教下我怎么提高看书的兴趣,鄙人感激不尽…
闲话就说到这里,今天的目标:新笔趣阁,然后我们进入搜索页面:http://www.xbiquge.la/modules/article/waps.php
今天爬点小说,说到看书,我也就在看小说的时候不瞌睡,哈哈。。
单纯的爬小说其实蛮简单的,不过今天咱们给自己增加点难度,使用requests的POST来抓取小说
requests的GET,就是字面意思了,而POST也是字面意思,与GET稍微不一样的是需要携带数据,而数据在哪呢,在网站里面,比如搜索一个本人比较喜欢的小说:间客
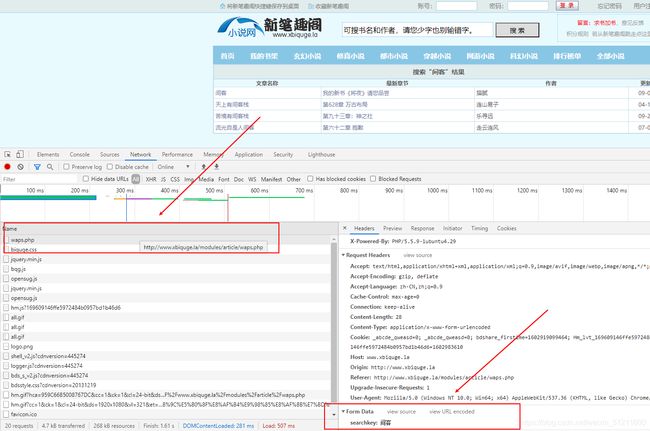
右下角的Form Data里面的数据就是我们要携带给requests一起解析的:
import requests
import parsel
import re
def get_url(headers,keyword):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36',
}
url = 'http://www.xbiquge.la/modules/article/waps.php'
data = {
'searchkey': keyword,
}
res = requests.post(url,data=data,headers=headers)
res.encoding = 'utf-8'
sreach = parsel.Selector(res.text)
n = 0
href = []
for each in sreach.xpath('//div[@id="content"]/form/table/tr')[1:]:
href.append(each.xpath('./td/a/@href').get()) # 书籍地址
title = each.xpath('./td/a/text()').get() # 书籍名称
author= each.xpath('./td[3]/text()').get() # 作者
n += 1
print(str(n) +": "+ title,author)
if n == 4:
break
if bool(href) == False: # 判断是否有该书籍,如果没有,则返回main继续从头开始
print(f"未找到{keyword},请重新输入!!")
main()
while True:
choice = int(input("请按序号选择你要下载的书籍:"))
if choice == 1:
return href[0]
elif choice == 2:
return href[1]
elif choice == 3:
return href[2]
elif choice == 4:
return href[3]
else:
print("输入错误!请重新输入!")
def main():
keyword = input("请输入您要查找的书籍/作者名称(最多显示四本):")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36',
}
get_url(headers,keyword)
if __name__ == "__main__":
main()
结果如下:

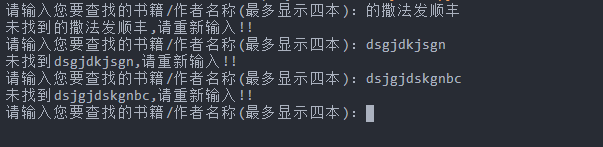
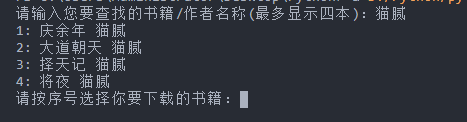
多增加了一些功能,可以查找书籍或者作者,最多显示四本,所以请尽量把书籍名称写全来,当然你也可以改,把if == 4 的这个4 改成你想要显示的书籍数量即可,当然后面的判断也得增加一点
既然我们拿到这些东西,那后面的其实就简单了,直接上代码:
import requests
import parsel
import re
def get_url(headers,keyword):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36',
}
url = 'http://www.xbiquge.la/modules/article/waps.php'
data = {
'searchkey': keyword,
}
res = requests.post(url,data=data,headers=headers)
res.encoding = 'utf-8'
sreach = parsel.Selector(res.text)
n = 0
href = []
for each in sreach.xpath('//div[@id="content"]/form/table/tr')[1:]:
href.append(each.xpath('./td/a/@href').get()) # 书籍地址
title = each.xpath('./td/a/text()').get() # 书籍名称
author= each.xpath('./td[3]/text()').get() # 作者
n += 1
print(str(n) +": "+ title,author)
if n == 4:
break
if bool(href) == False: # 判断是否有该书籍,如果没有,则返回main继续从头开始
print(f"未找到{keyword},请重新输入!!")
main()
while True:
choice = int(input("请按序号选择你要下载的书籍:"))
if choice == 1:
return href[0]
elif choice == 2:
return href[1]
elif choice == 3:
return href[2]
elif choice == 4:
return href[3]
else:
print("输入错误!请重新输入!")
def get_list(url,headers):
res = requests.get(url,headers=headers)
res.encoding = "utf-8"
list_url = parsel.Selector(res.text)
book_name = list_url.xpath('//div[@id="info"]/h1/text()').get() # 书籍名称
print("开始下载:",book_name)
for lis in list_url.xpath('//div[@id="list"]/dl/dd'):
list_url = 'http://www.xbiquge.la' + lis.xpath('./a/@href').get() # 内容页 URL
chap = lis.xpath('./a/text()').get() # 章节标题
print(chap)
content = requests.get(list_url,headers=headers)
content.encoding = "utf-8"
content_url = parsel.Selector(content.text)
con_text = ""
all_content = content_url.xpath('//div[@id="content"]/text()').getall()
for ac in all_content:
re.sub("[\xa0]"," ",ac) # 替换文本里面的乱码
con_text += ac
# print(con_text)
with open("./images/" + book_name+".txt","a+",encoding="utf-8") as f:
f.write(chap)
f.write("\n")
f.write(con_text)
f.write('\n')
def main():
keyword = input("请输入您要查找的书籍/作者名称(最多显示四本):")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36',
}
url = get_url(headers,keyword)
get_list(url,headers)
if __name__ == "__main__":
main()
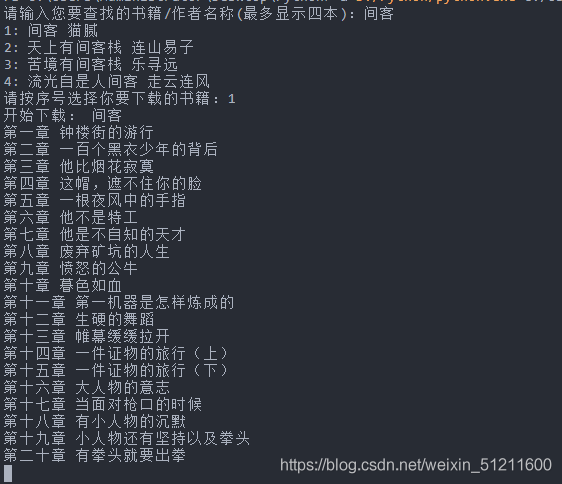

搞定!欢迎各位大佬一起交流,我要去看书啦!
2020/10/25 修正!!
突然想到了一个点子,新加进来,代码也就改了一点点,增加了一个进度条,这样就好看多了,新代码:
import requests
import parsel
import re
from tqdm import tqdm
def get_url(headers,keyword):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36',
}
url = 'http://www.xbiquge.la/modules/article/waps.php'
data = {
'searchkey': keyword,
}
res = requests.post(url,data=data,headers=headers)
res.encoding = 'utf-8'
sreach = parsel.Selector(res.text)
n = 0
href = []
for each in sreach.xpath('//div[@id="content"]/form/table/tr')[1:]:
href.append(each.xpath('./td/a/@href').get()) # 书籍地址
title = each.xpath('./td/a/text()').get() # 书籍名称
author= each.xpath('./td[3]/text()').get() # 作者
n += 1
print(str(n) +": "+ title,author)
if n == 4:
break
if bool(href) == False: # 判断是否有该书籍,如果没有,则返回main继续从头开始
print(f"未找到{keyword},请重新输入!!")
main()
while True:
choice = int(input("请按序号选择你要下载的书籍( 按 0 退出 ):"))
if choice == 1:
return href[0]
elif choice == 2:
return href[1]
elif choice == 3:
return href[2]
elif choice == 4:
return href[3]
elif choice == 0:
exit()
else:
print("输入错误!请重新输入!")
def get_list(url,headers):
res = requests.get(url,headers=headers)
res.encoding = "utf-8"
list_url = parsel.Selector(res.text)
book_name = list_url.xpath('//div[@id="info"]/h1/text()').get() # 书籍名称
books = "开始下载:"+ book_name
for lis in tqdm(list_url.xpath('//div[@id="list"]/dl/dd'), desc=books, ncols=100,unit="MB"):
list_url = 'http://www.xbiquge.la' + lis.xpath('./a/@href').get() # 内容页 URL
chap = lis.xpath('./a/text()').get() # 章节标题
# print(chap)
content = requests.get(list_url,headers=headers)
content.encoding = "utf-8"
content_url = parsel.Selector(content.text)
con_text = ""
all_content = content_url.xpath('//div[@id="content"]/text()').getall()
for ac in all_content:
re.sub("[\xa0]"," ",ac) # 替换文本里面的乱码
con_text += ac
# print(con_text)
with open("./images/" + book_name+".txt","a+",encoding="utf-8") as f:
f.write(chap)
f.write("\n")
f.write(con_text)
f.write('\n')
def main():
keyword = input("请输入您要查找的书籍/作者名称(最多显示四本):")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36',
}
url = get_url(headers,keyword)
get_list(url,headers)
if __name__ == "__main__":
main()
看终端显示:
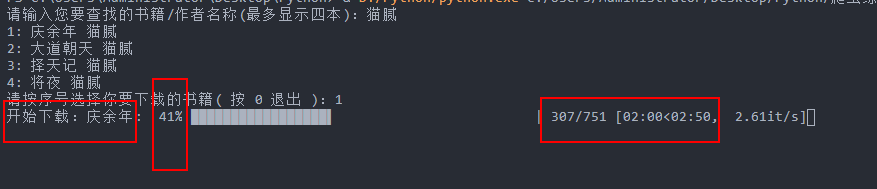
有要下载的书籍名称,还有下载进度,以及章节数和大概所需要的时间,基本都有了,这就是最终版了,不改啦!^ _ ^