前言
Spark是目前主流的大数据计算引擎,功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。作为一种内存计算框架,Spark运算速度快,并能够满足UDF、大小表Join、多路输出等多样化的数据计算和处理需求。
作为国内专业的数据智能服务商,个推从早期的1.3版本便引入Spark,并基于Spark建设数仓,进行大规模数据的离线和实时计算。由于Spark 在2.x版本之前的优化重心在计算引擎方面,而在元数据管理方面并未做重大改进和升级。因此个推仍然使用Hive进行元数据管理,采用Hive元数据管理+ Spark计算引擎的大数据架构,以支撑自身大数据业务发展。个推还将Spark广泛应用到报表分析、机器学习等场景中,为行业客户和政府部门提供实时人口洞察、群体画像构建等服务。

▲个推在实际业务场景中,分别使用SparkSQL 和 HiveSQL对一份3T数据进行了计算,上图展示了跑数速度。数据显示:在锁死队列(120G内存,<50core)前提下, SparkSQL2.3 的计算速度是Hive1.2 的5-10倍。
对企业来讲,效率和成本始终是其进行海量数据处理和计算时所必须关注的问题。如何充分发挥Spark的优势,在进行大数据作业时真正实现降本增效呢?个推将多年积累的Spark性能调优妙招进行了总结,与大家分享。
Spark性能调优-基础篇
众所周知,正确的参数配置对提升Spark的使用效率具有极大助力。因此,针对 不了解底层原理的Spark使用者,我们提供了可以直接抄作业的参数配置模板,帮助相关数据开发、分析人员更高效地使用Spark进行离线批处理和SQL报表分析等作业。
推荐参数配置模板如下:
Spark-submit 提交方式脚本
/xxx/spark23/xxx/spark-submit --master yarn-cluster \
--name ${mainClassName} \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC \
--driver-memory 2g \
--conf spark.sql.shuffle.partitions=1000 \
--conf hive.metastore.schema.verification=false \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.warehouse.dir=${warehouse} \
--conf spark.sql.hive.manageFilesourcePartitions=false \
--conf hive.metastore.try.direct.sql=true \
--conf spark.executor.memoryOverhead=512M \
--conf spark.yarn.executor.memoryOverhead=512 \
--executor-cores 2 \
--executor-memory 4g \
--num-executors 50 \
--class 启动类 \
${jarPath} \
-M ${mainClassName} spark-sql 提交方式脚本
option=/xxx/spark23/xxx/spark-sql
export SPARK_MAJOR_VERSION=2
${option} --master yarn-client \
--driver-memory 1G \
--executor-memory 4G \
--executor-cores 2 \
--num-executors 50 \
--conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties" \
--conf spark.sql.hive.caseSensitiveInferenceMode=NEVER_INFER \
--conf spark.sql.auto.repartition=true \
--conf spark.sql.autoBroadcastJoinThreshold=104857600 \
--conf "spark.sql.hive.metastore.try.direct.sql=true" \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=1 \
--conf spark.dynamicAllocation.maxExecutors=200 \
--conf spark.dynamicAllocation.executorIdleTimeout=10m \
--conf spark.port.maxRetries=300 \
--conf spark.executor.memoryOverhead=512M \
--conf spark.yarn.executor.memoryOverhead=512 \
--conf spark.sql.shuffle.partitions=10000 \
--conf spark.sql.adaptive.enabled=true \
--conf spark.sql.adaptive.shuffle.targetPostShuffleInputSize=134217728 \
--conf spark.sql.parquet.compression.codec=gzip \
--conf spark.sql.orc.compression.codec=zlib \
--conf spark.ui.showConsoleProgress=true
-f pro.sql
pro.sql 为业务逻辑脚本Spark性能调优-进阶篇
针对有意愿了解Spark底层原理的读者,本文梳理了standalone、Yarn-client、Yarn-cluster等3种常见任务提交方式的交互图,以帮助相关使用者更直观地理解Spark的核心技术原理、为阅读接下来的进阶篇内容打好基础。
standalone
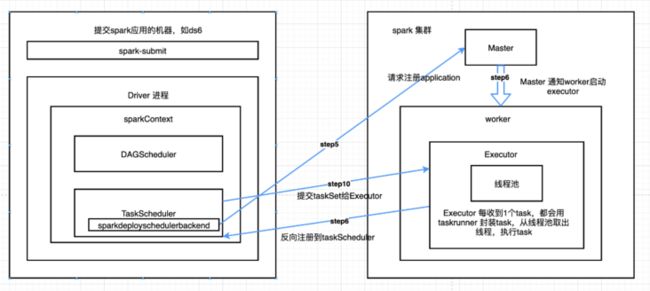
1) spark-submit 提交,通过反射的方式构造出1个DriverActor 进程;
2) Driver进程执行编写的application,构造sparkConf,构造sparkContext;
3) SparkContext在初始化时,构造DAGScheduler、TaskScheduler,jetty启动webui;
4) TaskScheduler 有sparkdeployschedulebackend 进程,去和Master通信,请求注册Application;
5) Master 接受通信后,注册Application,使用资源调度算法,通知Worker,让worker启动Executor;
6) worker会为该application 启动executor,executor 启动后,会反向注册到TaskScheduler;
7) 所有Executor 反向注册到TaskScheduler 后,Driver 结束sparkContext 的初始化;
8) Driver继续往下执行编写的application,每执行到1个action,就会创建1个job;
9) job 会被提交给DAGScheduler,DAGScheduler 会对job 划分为多个stage(stage划分算法),每个stage创建1个taskSet;
10) taskScheduler会把taskSet里每1个task 都提交到executor 上执行(task 分配算法);
11) Executor 每接受到1个task,都会用taskRunner来封装task,之后从executor 的线程池中取出1个线程,来执行这个taskRunner。(task runner:把编写的代码/算子/函数拷贝,反序列化,然后执行task)。
Yarn-client
1) 发送请求到ResourceManager(RM),请求启动ApplicationMaster(AM);
2) RM 分配container 在某个NodeManager(NM)上,启动AM,实际是个ExecutorLauncher;
3) AM向RM 申请container;
4) RM给AM 分配container;
5) AM 请求NM 来启动相应的Executor;
6) executor 启动后,反向注册到Driver进程;
7) 后序划分stage,提交taskset 和standalone 模式类似。
Yarn-cluster
1) 发送请求到ResourceManager(RM),请求启动ApplicationMaster(AM);
2) RM 分配container 在某个NodeManager(NM)上,启动AM;
3) AM向RM 申请container;
4) RM给AM 分配container;
5) AM 请求NM 来启动相应的Executor;
6) executor 启动后,反向注册到AM;
7) 后序划分stage,提交taskset 和standalone 模式类似。
理解了以上3种常见任务的底层交互后,接下来本文从存储格式、数据倾斜、参数配置等3个方面来展开,为大家分享个推进行Spark性能调优的进阶姿势。
存储格式(文件格式、压缩算法)
众所周知,不同的SQL引擎在不同的存储格式上,其优化方式也不同,比如Hive更倾向于orc,Spark则更倾向于parquet。同时,在进行大数据作业时,点查、宽表查询、大表join操作相对频繁,这就要求文件格式最好采用列式存储,并且可分割。因此我们推荐以parquet、orc 为主的列式存储文件格式和以gzip、snappy、zlib 为主的压缩算法。在组合方式上,我们建议使用parquet+gzip、orc+zlib的组合方式,这样的组合方式兼顾了列式存储与可分割的情况,相比txt+gz 这种行式存储且不可分割的组合方式更能够适应以上大数据场景的需求。
个推以线上500G左右的数据为例,在不同的集群环境与SQL引擎下,对不同的存储文件格式和算法组合进行了性能测试。测试数据表明:相同资源条件下,parquet+gz 存储格式较text+gz存储格式在多值查询、多表join上提速至少在60%以上。
结合测试结果,我们对不同的集群环境与SQL引擎下所推荐使用的存储格式进行了梳理,如下表:

同时,我们也对parquet+gz、orc+zlib的内存消耗进行了测试。以某表的单个历史分区数据为例,parquet+gz、orc+zlib比txt+gz 分别节省26%和49%的存储空间。
完整测试结果如下表:
可见,parquet+gz、orc+zlib确实在降本提效方面效果显著。那么,如何使用这两种存储格式呢?步骤如下:
➤hive 与 spark 开启指定文件格式的压缩算法
spark:
set spark.sql.parquet.compression.codec=gzip;
set spark.sql.orc.compression.codec=zlib;
hive:
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec;➤建表时指定文件格式
parquet 文件格式(序列化,输入输出类)
CREATE EXTERNAL TABLE `test`(rand_num double)
PARTITIONED BY (`day` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
;
orc 文件格式(序列化,输入输出类)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
;➤线上表调
ALTER TABLE db1.table1_std SET TBLPROPERTIES ('parquet.compression'='gzip');
ALTER TABLE db2.table2_std SET TBLPROPERTIES ('orc.compression'='ZLIB');➤ctas 建表
create table tablename stored as parquet as select ……;
create table tablename stored as orc TBLPROPERTIES ('orc.compress'='ZLIB') as select ……;
数据倾斜
数据倾斜分为map倾斜和reduce倾斜两种情况。本文着重介绍reduce 倾斜,如SQL 中常见的group by、join 等都可能是其重灾区。数据倾斜发生时,一般表现为:部分task 显著慢于同批task,task 数据量显著大于其他task,部分taskOOM、spark shuffle 文件丢失等。如下图示例,在duration 列和shuffleReadSize/Records列,我们能明显发现部分task 处理数据量显著升高,耗时变长,造成了数据倾斜:

如何解决数据倾斜?
我们总结了7种数据倾斜解决方案,能够帮助大家解决常见的数据倾斜问题:
解决方案一:使用 Hive ETL预处理数据
即在数据血缘关系中,把倾斜问题前移处理,从而使下游使用方无需再考虑数据倾斜问题。
⁕该方案适用于下游交互性强的业务,如秒级/分钟级别提数查询。
解决方案二:过滤少数导致倾斜的key
即剔除倾斜的大key,该方案一般结合百分位点使用,如99.99%的id 记录数为100条以内,那么100条以外的id 就可考虑予以剔除。
⁕该方案在统计型场景下较为实用,而在明细场景下,需要看过滤的大key 是否为业务所侧重和关注。
解决方案三:提高shuffle操作的并行度
即对spark.sql.shuffle.partitions参数进行动态调整,通过增加shuffle write task写出的partition数量,来达到key的均匀分配。SparkSQL2.3 在默认情况下,该值为200。开发人员可以在启动脚本增加如下参数,对该值进行动态调整:
conf spark.sql.shuffle.partitions=10000
conf spark.sql.adaptive.enabled=true
conf spark.sql.adaptive.shuffle.targetPostShuffleInputSize=134217728 ⁕该方案非常简单,但是对于key的均匀分配却能起到较好的优化作用。比如,原本10个key,每个50条记录,只有1个partition,那么后续的task需要处理500条记录。通过增加partition 数量,可以使每个task 都处理50条记录,10个task 并行跑数,耗时只需要原来1个task 的1/10。但是该方案对于大key较难优化,比如,某个大key记录数有百万条,那么大key 还是会被分配到1个task 中去。
解决方案四:将reducejoin转为mapjoin
指的是在map端join,不走shuffle过程。以Spark为例,可以通过广播变量的形式,将小RDD的数据下发到各个Worker节点上(Yarn 模式下是NM),在各个Worker节点上进行join。
⁕该方案适用于小表join大表场景(百G以上的数据体量)。此处的小表默认阈值为10M,低于此阈值的小表,可分发到worker节点。具体可调整的上限需要小于container分配的内存。
解决方案五:采样倾斜key并分拆join操作
如下图示例:A表 join B表,A表有大key、B表无大key,其中大key的id为1,有3条记录。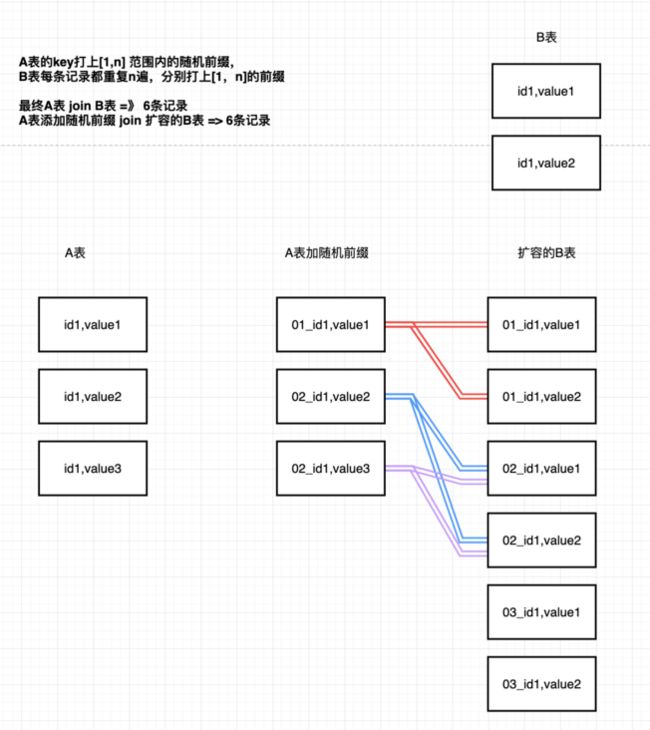
如何进行分拆join操作呢?
首先将A表、B表中id1单独拆分出来,剔除大key的A' 和 B' 先join,达到非倾斜的速度;
针对A表大key添加随机前缀,B表扩容N倍,单独join;join后剔除随机前缀即可;
再对以上2部分union。
⁕该方案的本质还是减少单个task 处理过多数据时所引发的数据倾斜风险,适用于大key较少的情况。
解决方案六:使用随机前缀和扩容RDD进行join
比如,A 表 join B表,以A表有大key、B表无大key为例:
对A表每条记录打上[1,n] 的随机前缀,B表扩容N倍,join。
join完成后剔除随机前缀。
⁕该方案适用于大key较多的情况,但也会增加资源消耗。
解决方案七:combiner
即在map端做combiner操作,减少shuffle 拉取的数据量。
⁕该方案适合累加求和等场景。
在实际场景中,建议相关开发人员具体情况具体分析,针对复杂问题也可将以上方法进行组合使用。
Spark 参数配置
针对无数据倾斜的情况,我们梳理总结了参数配置参照表帮助大家进行Spark性能调优,这些参数的设置适用于2T左右数据的洞察与应用,基本满足大多数场景下的调优需求。
总结
目前,Spark已经发展到了Spark3.x,最新版本为Spark 3.1.2 released (Jun 01, 2021)。Spark3.x的许多新特性,如动态分区修剪、Pandas API的重大改进、增强嵌套列的裁剪和下推等亮点功能,为进一步实现降本增效提供了好思路。未来,个推也将继续保持对Spark演进的关注,并持续展开实践和分享。