用Python爬取京东手机评论
用Python爬取京东手机评论
内容非原创,属于对视频和博客内容的学习笔记,后续会更新多线程爬取和根据爬取评论进行的情感分析。
1、所使用的浏览器为火狐浏览器
先随意点开一个手机商品
https://item.jd.com/100006788665.html
以华为手机为例,点进去后F12打开开发者工具,找到all,在过滤框内输入comment,找到productpagecomment.action
刚点进去还有许多信息加载不出来,需要多点几下其他地方,比如评论之类的。
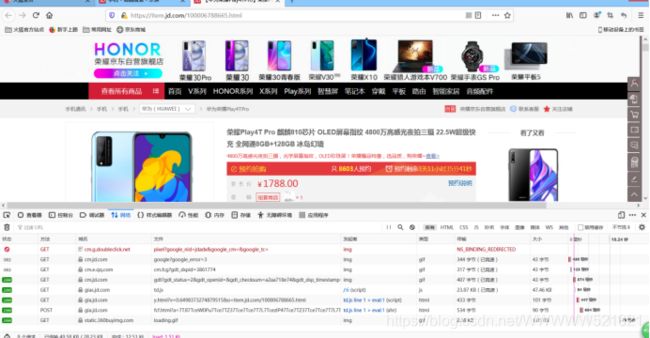
全部评论:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
好评:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=3&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
中评:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=2&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
差评:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=1&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
带图评论:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=4&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
追评:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=5&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
带视频评论:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006788665&score=7&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
可以看到这个url里都有以下几个参数:
callback=fetchJSON_comment98
应该是json文件的地址
productId=100007299121
产品id和网页中https://item.jd.com/100007299121.html的id是一样的
score=0
这里的score是评价的类型,0代表全部评论,差评是1,中评是2,好评是3,带图评论是4,追评是5,带视频评论是7,(6不知道去哪里了)
sortType=5
评论排序的类别,推荐排序是5,时间排序是6
page=0
评论的页数,第一页为0
pageSize=10
每一页的评论数
![]()
这里是评论的总结性信息:
{
“productCommentSummary”: {
“skuId”: 100006788665,
“averageScore”: 5,
“defaultGoodCount”: 685844,
“defaultGoodCountStr”: “68万+”,
“commentCount”: 863015,
“commentCountStr”: “86万+”,
“goodCount”: 172223,
“goodCountStr”: “17万+”,
"videoCount": 2638,
"videoCountStr": "2600+",
"afterCount": 4852,
"afterCountStr": "4800+",
"showCount": 24200,
"showCountStr": "2.4万+",
"productId": 100006788665,
"score1Count": 2600,
"score2Count": 592,
"score3Count": 1756,
"score4Count": 3499,
"score5Count": 168724
}
}
知道这几个参数的意思之后就可以根据自己想要的内容进行爬取,这里我选择爬取全部评论的前100页,因此只需要对page进行循环,score=0即可。
import requests
import pandas as pd
import json
import time
import csv
import re
#https://club.jd.com/comment/productPageComments.action?
#callback=fetchJSON_comment98&productId=100006788665
#&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
#requests请求地址
url = "https://club.jd.com/comment/productPageComments.action?"
#请求头
header = {
"User-Agent";"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.63 Safari/537.36"}
#多页评论
for i in range(100):
#请求参数
data = {
"callback":"fetchJSON_comment98",
"productId":100006788665,
"score":0,
"sortType":5,
"page":i,
"pageSize":10,
"isShadowSku":0,
"fold":1,
}
html = requests.get(url,params = data,headers = header)
这里有一点忘记说了,京东手机不通的产品有不同的productid,想要换不同的产品进行爬取,只需要换这个id就行了。
在用get请求网页内容时,有以下两种方式:
1、requests.get(url = “”)
url=https://club.jd.com/comment/productPageComments.action?
callback=fetchJSON_comment98&productId=100006788665
&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
2、requests.get(url = “”, params = data) 使用Params
url=https://club.jd.com/comment/productPageComments.action?
html_json = re.search("(?<=fetchJSON_comment98\().*(?=\))",html.text).group(0)
#(?<=fetchJSON_comment98().(?=)
(?<=fetchJSON_comment98()表示匹配以"fetchJSON_comment98(“为开头的字符串,并且捕获(存储)到分组中,
这里的(以(表示,许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义”,
即,将反斜杠字符\ 放在它们前面。
(?=)表示匹配以\结尾的字符串,并且捕获(存储)到分组中。
中间的.,其中.表示匹配除换行符 \n 之外的任何单字符,*表示匹配前面的子表达式零次或多次,两个加起来形成一个贪婪匹配,就是除了换行符之外,所有字符都匹配,并且匹配次数不限制。
#import re
a = “123abc456”
print re.search("([0-9])([a-z])([0-9])",a).group(0) #123abc456,返回整体
print re.search("([0-9])([a-z])([0-9])",a).group(1) #123
print re.search("([0-9])([a-z])([0-9])",a).group(2) #abc
print re.search("([0-9])([a-z])([0-9])",a).group(3) #456
正则表达式中的三组括号把匹配结果分成三组
group() 同group(0)就是匹配正则表达式整体结果
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
没有匹配成功的,re.search()返回None
‘’’
j = json.load(html_json)
#存储为字典
for jj in range(len(j["comments"])):
data1 = [(j["comments"][jj]["content"])]
#从j中找出"comments"中的"conent"
data2 = pd.DataFrame(data1)
data2.to_csv("C:/Users/01/Desktop/京东评论.csv",header = False,index = False,mode = "a+")
time.sleep(2)
print("page "+str(1+i)+"has done")
借鉴资料:
如何解决python爬虫中Response [200]返回值问题
正则 ?<= 和 ?= 用法
Python3 re.search()方法
Python——re.search().group()
Request–get请求的用法
源代码学习视频
完整代码:
import requests
import pandas as pd
import json
import time
import csv
import re
url = "https://club.jd.com/comment/productPageComments.action?"
#请求头
header = {
"User-Agent";"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.63 Safari/537.36"}
#多页评论
for i in range(100):
#请求参数
data = {
"callback":"fetchJSON_comment98",
"productId":100006788665,
"score":0,
"sortType":5,
"page":i,
"pageSize":10,
"isShadowSku":0,
"fold":1,
}
html = requests.get(url,params = data,headers = header)
html_json = re.search("(?<=fetchJSON_comment98\().*(?=\))",html.text).group(0)
j = json.load(html_json)
#存储为字典
for jj in range(len(j["comments"])):
data1 = [(j["comments"][jj]["content"])]
#从j中找出"comments"中的"conent"
data2 = pd.DataFrame(data1)
data2.to_csv("C:/Users/01/Desktop/京东评论.csv",header = False,index = False,mode = "a+")
time.sleep(2)
print("page "+str(1+i)+"has done")