python基于selenium的UI自动化测试
python基于selenium的UI自动化测试(selenium+webdriver)
目录
-
- python基于selenium的UI自动化测试(selenium+webdriver)
-
- 一、一个简单了解selenium+webdriver的自动化脚本
- 二、web和selenium相关知识和操作技巧
-
- 2.1 html标签(了解即可)
- 2.2 如何精准定位你要操作的元素——八大元素定位
- 2.3 javascript
- 2.4iframe切换
- 2.5窗口句柄切换
- 2.6selenium高级操作:ActionChains
- 2.7冻结界面
- 三、关键字驱动
- 四、Excel数据驱动
- 五、UnitTest
- 六、yaml数据驱动
- 七、测试用例的设计和自动化测试(关键字驱动+excel数据驱动)
-
- 7.1 一个简单基础的自动化测试例子
- 7.2基于POM设计模式下的webUI自动化测试
- 7.3基于POM模式设计的一套webUI自动化测试框架实战(具体详见GitHUb)
-
- 1.0版
一、一个简单了解selenium+webdriver的自动化脚本
from selenium import webdriver
from time import sleep
#创建一个driver
driver1 =webdriver.Chrome()
#打开网页
driver1.get('http://baidu.com')
#输入
driver1.find_element_by_id('kw').send_keys('测试')
#点击搜索
driver1.find_element_by_id('su').click()
#等待
sleep(3)
#点击
driver1.find_element_by_xpath('//*[@id="1"]/h3/a').click()
二、web和selenium相关知识和操作技巧
2.1 html标签(了解即可)
基本格式:
常用标签:
a:超链接
img:图片
input:输入框
button:按钮
实际系统中,元素的标签类型不是由表象决定的,是通过css样式表来决定的
2.2 如何精准定位你要操作的元素——八大元素定位
2.2.1 id,基于元素中属性id的值来定位(类似身份证,不会重复)
如:driver.find_element('id','kw')或driver.find_element_by_id('kw')
2.2.2 name,基于元素中属性name的值来定位(类似名字,可能重复)
如:driver.find_element('name','theme-color')
2.2.3 link text,主要用于定位超链接标签(a href这一行中的文本)
如:driver.find_element_by_link_text('学术')
2.2.4 partial link text, link text的模糊查询版本,类似于数据库中like%
如:driver.find_element_by_partial_link_text('学术')
element不加s默认返回找到的的第一个
想要定位某一个:driver.find_elements_by_partial_link_text('百度')[1]
2.2.5 classname
2.2.6 tagname
2.2.7 cssselector
2.2.8 xpath,基于页面结构来进行的定位
绝对路径:右键copy
相对路径:基于匹配制度来查找元素
如://*[@id="kw"]
//表示从根路径下开始查找
* 任意元素
[ ] 表示筛选条件(查找函数)
@ 表示基于属性来筛选
如果要基于text来定位元素,在[ ]中添加text()="文本内容"进行查找,如//@[text()="登录"]
- 确认xpath路径是否正确:
1.开发者工具ctrl+f查找判断
2.console输入$x(“xpath路径”)进行校验 - 遇到动态元素无法精准定位:(采用模糊定位)
driver.find_element_by_xpath("//div[contains(@id, 'xxx')]")
driver.find_element_by_xpath("//div[starts-with(@id, 'xxx')]")
driver.find_element_by_xpath("//div[ends-with(@id, 'xxx')]")
contains(a, b) 如果a中含有字符串b,则返回true,否则返回false
starts-with(a, b) 如果a是以字符串b开头,返回true,否则返回false
ends-with(a, b) 如果a是以字符串b结尾,返回true,否则返回false
2.3 javascript
简介:
javascript是web的编程语言,可用于HTML和web开发,让静态HTML页面上添加一些动态效果
javascript是可插入HTML页面的编程代码,插入后由浏览器执行
web网页的组成
HTNL定义了网页的内容
CSS描述了网页的布局
JavaScript实现了网页的行为
HTML中的脚本必须位于标签之间。脚本可被放置在HTML页面的和部分中
浏览器对象
window - 不但充当全局作用域,而且表示浏览器窗口
open(url):打开一个新页面
location - 表示当前页面的URL信息
location.herf:获取url的值
location.assign(url):加载一个新页面
location.reload(url):重新加载当前页面
document: - 表示当前页面。由于HTML在浏览器中以DOM形式表示为树型结构,document就是整个DOM树的根节点
click方法操作元素
value属性赋值实现关键字输入,相当于sendkeys
readOnly
textContent获取文本值
获取元素属性赋值,直接更改属性值
2.4iframe切换
如果要操作被嵌入html文档中的元素 ,就必须切换操作范围到被嵌入的文档中。
driver=webdriver.Chrome()
切入iframe
driver.switch_to.frame(frame_reference)frame_reference可以是iframe的属性name或id或者之前定位到的元素对象,总之是要能确定iframe的位置。
切出iframe
driver.switch_to.default_content()
2.5窗口句柄切换
driver.switch_to_.window(handle)
实际应用:
mainWindow =driver.current_window_handle#提前保存句柄,方便返回
for handle in driver.window_handles:
driver.switch_to_.window(handle)
if "预期窗口上的文本"in driver.title
break
2.6selenium高级操作:ActionChains
ActionChains是一个类,使用前要实例化
使用ActionChains可以做到很多复杂操作,如鼠标右键点击,双击,移动鼠标到某个元素,鼠标拖拽等
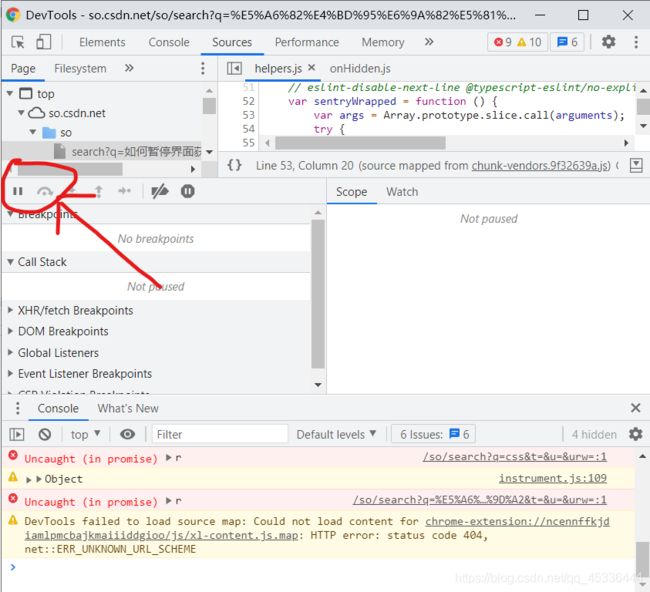
2.7冻结界面
在定位元素html时,可能会有出现后迅速消失的情况,需要冻结界面观察
1.定时冻结
在console中输入js代码
setTimeout(function(){debugger},5000定时5s后冻结
2.实时冻结
开发者工具切换到sources页直接点
三、关键字驱动
3.1 初识关键字驱动模块(底层模块+测试流程)
关键字驱动类:将selenium中常用的操作行为,封装成自定义的函数,以便于直接调用
操作步骤:selenium中常用的所有关键字,结合自身需要,将其提取并二次封装,保存至自定义类中。在调用selenium执行自动化时,直接调用自定义类即可
一共两个python文件,一个作为工具库,一个作为测试代码
工具库
'''
底层逻辑代码模块:
提供所有的底层支持,便于在测试中被应用执行
'''
from selenium import webdriver
from time import sleep
#创建浏览器对象:可能是chrome,firefox,ie,safari
def open_browser(browser_type):
try:
drver = getattr(webdriver,browser_type)()
except Exception as e:
print(e)
drver = webdriver.Chrome()
return drver
#关键字驱动类
class webUIDemo:
'''
webUI中,核心的自动化测试操作是:
1.元素定位
2.输入
3.点击
4.访问
5.关闭
6.等待
'''
#构造函数
def __init__(self,browser_type):
self.driver =open_browser(browser_type)
#元素定位
def locator(self,name,value):
return self.driver.find_element(name,value)
#输入
def input(self,name,value,txt):
self.locator(name,value).send_keys(txt)
#点击
def click(self,name,value):
self.locator(name,value).click()
#访问url
def visit(self,url):
self.driver.get(url)
#关闭浏览器
def quit(self):
self.driver.quit()
#等待
def sleep(self,time):
sleep(time)
测试代码
'''
定义测试流程,引用关键字模块实现测试流程的执行
'''
from study.test_case.toolwarehouse import webUIDemo
#用例1:百度搜索流程的实现
webdriver = webUIDemo('Chrome')
webdriver.visit('http://www.baidu.com')
webdriver.input('id','kw','如何学习自动化测试')
webdriver.click('id','su')
webdriver.sleep(3)
webdriver.quit()
四、Excel数据驱动
4.1 excel数据驱动实现逻辑
1.进入文件
2.读取数据
3.放入测试代码中
import openpyxl
'''
excel文件的读取流程:
1.打开excel
2.获取指定sheet页
3.读取当前指定sheet页中的内容
'''
#打开excel,读取工作簿
excel = openpyxl.load_workbook(r'E:\PyCharm 2021.1.2\project\study\excel_test\excel_cases\testcase.xlsx')
#指定需要的sheet页
sheets =excel.sheetnames
for i in sheets:
sheet =excel[i]
for values in sheet.values:
print(values)
五、UnitTest
Python中比较流行的自动化测试框架,最早用于单元测试,随着自动化更新,能完整结合Selenium、Appium、Requests等实现UI自动化和接口自动化
六、yaml数据驱动
yaml:通过空格和缩进管理的一种数据文件(要注意缩进的作用,不能省)
可以完美结合ddt实现数据的传送
列表形式书写,
-代表列表,进行列表嵌套时需要在上一层加一个-
yaml内为

输出为
![]()
字典形式书写
yaml内

输出为
{'user1': {'user': 'tester1', 'password': 123456}, 'user2': {'user': 'tester2', 'password': 'abcdef'}}
七、测试用例的设计和自动化测试(关键字驱动+excel数据驱动)
7.1 一个简单基础的自动化测试例子
工具库
'''
关键字驱动类
'''
from selenium import webdriver
from time import sleep
#打开浏览器
def browser(type_):
try:
driver =getattr(webdriver,type_)()#getattr(object,name)和object.name是一样的功能.只不过这里可以把name作为一个变量去处理
except Exception as e:
print(e)
print('出现异常,使用chrome浏览器')
driver =webdriver.Chrome()
return driver
class webdemo:
#实例化
def __init__(self,type_):
self.driver =browser(type_)
#打开url
def open(self,url):
self.driver.get(url)
#定位元素
def locator(self, method, value):
return self.driver.find_element(method, value)
#输入内容
def input(self, method, value, txt):
self.locator(method, value).send_keys(txt)
#点击
def click(self,method,value):
self.locator(method,value).click()
#设置等待时长
def wait(self,time):
sleep(time)
#退出
def quit(self):
self.driver.quit()
测试用例
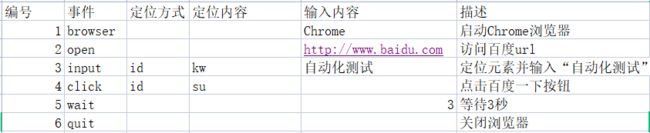
测试过程
'''
测试过程
'''
from study.autotest1.webui import webdemo
import openpyxl
excel =openpyxl.load_workbook('test_case.xlsx')#打开excel,读取工作簿
sheet =excel['Sheet1']#指定工作页
for line_values in sheet.values:#按行读取
#获取excel中参数内容
method =line_values[2]
value=line_values[3]
txt =line_values[4]
#结合文件进行判断
if type(line_values[0]) is int:#如果这行的第1项为数字序号才会继续判断第2项
if line_values[1] == 'browser':
wd = webdemo(txt)#进行实例化,运行了browser
elif line_values[1] == 'open':
wd.open(txt)#运行open
elif line_values[1] == 'input':
wd.input(method,value,txt)
elif line_values[1] == 'click':
wd.click(method,value)
elif line_values[1] == 'wait':
wd.wait(txt)
elif line_values[1] == 'quit':
wd.quit()
else:
pass
利用getattr()反射和**解包方法以及**kwargs关键字参数优化,精简测试流程
base
'''
关键字驱动类
'''
from selenium import webdriver
from time import sleep
def browser(type_):
try:
driver =getattr(webdriver,type_)()#getattr(object,name)和object.name是一样的功能.只不过这里可以把name作为一个变量去处理
except Exception as e:
print(e)
print('出现异常,使用chrome浏览器')
driver =webdriver.Chrome()
return driver
class webdemo:
def __init__(self,type_):
self.driver =browser(type_)
def open(self,**kwargs):
self.driver.get(kwargs['txt'])
def locator(self,kwargs):
return self.driver.find_element(kwargs['method'],kwargs['value'])
def input(self, **kwargs):
self.locator(kwargs).send_keys(kwargs['txt'])
def click(self,**kwargs):
self.locator(kwargs).click()
def quit(self,**kwargs):
self.driver.quit()
def wait(self,**kwargs):
sleep(kwargs['txt'])
测试流程
'''
测试过程
'''
from study.autotest1.webui import webdemo
import openpyxl
excel =openpyxl.load_workbook('test_case.xlsx')
sheet =excel['Sheet1']
for line_values in sheet.values:
#获取excel中参数内容
params ={
}
params['method'] =line_values[2]
params['value']=line_values[3]
params['txt'] =line_values[4]
#结合文件进行判断
if type(line_values[0]) is int:#如果这行的第1项为数字序号才会继续判断第2项
if line_values[1] == 'browser':
wd = webdemo(params['txt'])#进行实例化,运行了browser
else:
getattr(wd,line_values[1])(**params)
else:
pass
7.2基于POM设计模式下的webUI自动化测试
POM:页面对象模型,将系统中所有核心业务流所关联的页面,都生成对应的页面对象,通过调用页面对象,实现流程自动化
在POM体系下,全程都是基于页面来考虑这个流程的执行连贯性,中间会关联多少页面,每个页面分别会执行哪些内容。
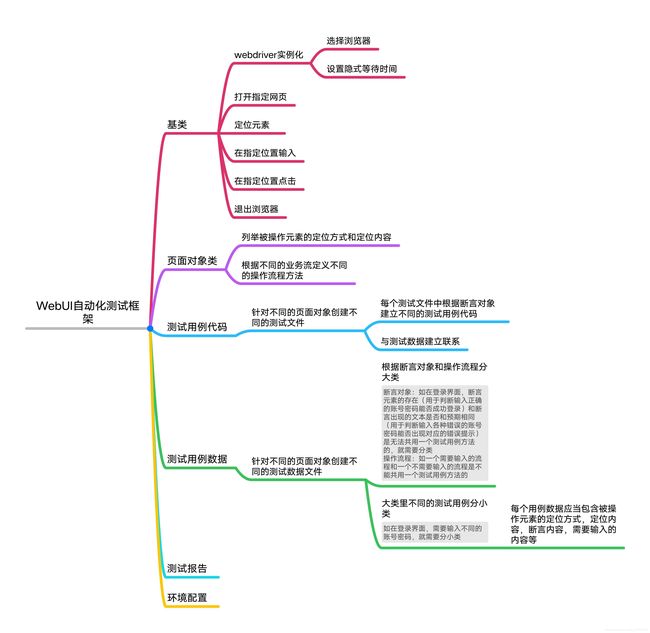
结构设计:
1.基类:工具类,用于提供各个页面对象所要进行的操作行为,将其封装成各种类型的各种类型的函数便于页面对象调用。
2.页面对象类:基于系统的所有提取的能自动化测试执行的页面,来实现的一个页面对象类文件
3.测试用例:所泛指测试代码,可以基于py直接实现,也可以通过unitTest或PyTest来实现
4.测试数据:包含所有的用例在执行时所需要关联的数据内容
关联技术
1.核心技术:webUI–selenium, AppUI–Appium
2.用例:Py, UnitTest, PyTest
3.测试数据:yaml, py, json, excel
一套完整的自动化框架的搭建需要什么
1.核心逻辑
2.测试代码
3.测试数据管理
4.日志管理
5.用例管理
6.报告管理
7.持续集成
8.配置管理
9…
7.3基于POM模式设计的一套webUI自动化测试框架实战(具体详见GitHUb)
因后续更新改动较大和复杂,CSDN的模式不再适合记录,已转至github持续更新
GitHub链接:https://github.com/codemother/POMmode_AutoTest_WebUI-byPython
1.0版
框架思维导图
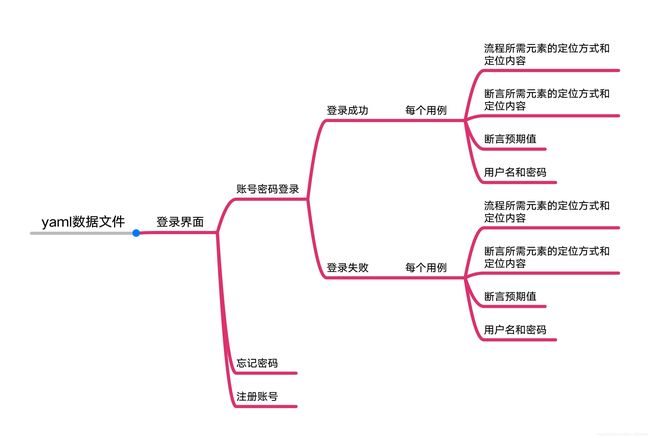
测试用例的结构设计导图
基类:
'''
base_class,工具类,用于提供各个页面对象所要进行的操作行为,将其封装成各种类型的各种类型的函数便于页面对象调用。这里的args需要输入元组型参数
'''
from selenium import webdriver
from time import sleep
#选择浏览器
def browser(type_):
try:
driver =getattr(webdriver,type_)()
except Exception as e:
print(e)
driver =webdriver.Chrome()
return driver
class base_class:
#实例化webdriver
def __init__(self,type_):
self.driver =browser(type_)
#打开网址
def open(self,url):
self.driver.get(url)
#定位元素
def locate(self,args):
return self.driver.find_element(*args)#将定位方式和定位元素的值组成的元组解包,达到合适格式
#输入
def input(self,args,txt):
self.locate(args).send_keys(txt)
#点击
def click(self,args):
self.locate(args).click()
#等待
def wait(self,time_):
sleep(time_)
#退出
def quit(self):
self.driver.close()
页面对象类
有多个页面对象要测试就需要创建多个类,建议每个类创建一个.py文件,便于管理
'''
login_page,登录页面对象类,用于实现系统的登录业务操作
'''
from pom.base.base_class import base_class
class login_page(base_class):
#页面的url
url ='https://demo.shopxo.net/login.html'
#页面中关联的元素对象
user =('name','accounts')
password =('name','pwd')
button =('xpath','/html/body/div[7]/div/div[2]/div[2]/div/div/div[1]/form/div[4]/button')
#基于元素实现的业务流
def login(self,account_txt,password_txt):
self.open(self.url)
self.input(self.user,account_txt)
self.input(self.password,password_txt)
self.click(self.button)
测试用例
如果同一个页面有多个不同类型(不是简单的更改参数)的测试用例需要测试,可以直接再在testdemo里定义一个新的方法,如def test_02_xxx
import unittest
from pom.page_object.login_page import login_page
from ddt import ddt,file_data
@ddt
class testdemo(unittest.TestCase):
#login_page测试用例实现
@file_data('E:\PyCharm 2021.1.2\project\pom\data\login.yaml')
def test_01_login(self,browser_type,account,password):
test1 = login_page(browser_type)
test1.login(account, password)
if __name__ == '__main__':
unittest.main
测试数据
此处为yaml文件的数据,本测试利用的是yaml的数据驱动
-
browser_type: chrome
account: account01
password: 123456
-
browser_type: chrome
account: account02
password: 123456