flyway整合SpringBoot实战详细教程(干货!)

文章目录
- 1、简介
- 2、为什么要迁移数据库?
- 3、Flyway的工作原理
- 4、整合SpringBoot
-
- 4.1maven依赖
- 4.2配置文件
- 4.3脚本规范
- 4.4项目使用
- 4.5启动项目
- 4.6缺点
-
- 4.6.1创建数据库配置
1、简介
Flyway 是一个开源的数据库迁移工具。它强烈支持简单性和约定而不是配置。迁移可以用SQL (支持特定于数据库的语法(例如 PL/SQL、T-SQL 等))或Java (用于高级数据转换或处理 LOB)编写。
它有一个命令行客户端。如果您使用的是 JVM,我们建议您使用Java API(也适用于 Android)在应用程序启动时迁移数据库。或者,您也可以使用Maven 插件 或Gradle 插件。
如果这还不够,还有 适用于 Spring Boot、Dropwizard、Grails、Play、SBT、Ant、Griffon、Grunt、Ninja 等的插件!
支持的数据库有 Oracle、 SQL Server(包括 Amazon RDS 和 Azure SQL 数据库)、 Azure Synapse(原数据仓库)、 DB2、 MySQL(包括 Amazon RDS、Azure 数据库和 Google Cloud SQL)、 Aurora MySQL、 MariaDB、 Percona XtraDB Cluster、 TestContainers、 PostgreSQL(包括 Amazon RDS、Azure 数据库、Google Cloud SQL、TimescaleDB、YugabyteDB 和 Heroku)、 Aurora PostgreSQL、 Redshift、 CockroachDB、 SAP HANA、 Sybase ASE、 Informix、 H2、 HSQLDB、 Derby、 Snowflake、 SQLite和 Firebird。
2、为什么要迁移数据库?
首先,让我们从头开始,假设我们有一个名为_Shiny_的项目,它的主要交付物是一个名为_Shiny Soft 的软件_,它连接到名为_Shiny DB 的数据库_。
表示这一点的最简单图表可能如下所示:

我们有我们的软件和我们的数据库。伟大的。这很可能就是您所需要的。
但在大多数项目中,这种简单的世界观很快就会转化为:

我们现在不仅要处理我们环境的一个副本,还要处理多个副本。这提出了许多挑战。
我们非常擅长在代码方面解决这些问题。
- 版本控制现在变得普遍,每天都有更好的工具。
- 我们有可重复的构建和持续集成。
- 我们有明确定义的发布和部署流程。
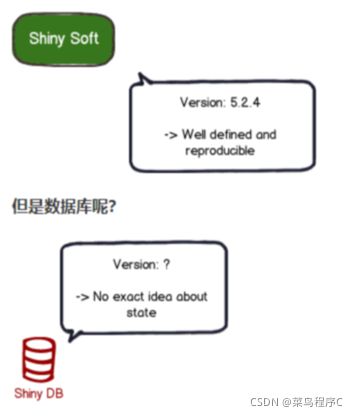
不幸的是,我们在那里做得并不好。许多项目仍然依赖于手动应用的 sql 脚本。有时甚至不是(这里或那里的快速 sql 语句来解决问题)。很快就会出现很多问题:
- 这台机器上的数据库处于什么状态?
- 此脚本是否已应用?
- 生产中的快速修复是否在之后的测试中应用?
- 你如何设置一个新的数据库实例?
通常,这些问题的答案是:我们不知道。
数据库迁移是重新控制这种混乱局面的好方法。
它们允许您:
- 从头开始重新创建数据库
- 随时清楚数据库处于什么状态
- 以确定性的方式从当前版本的数据库迁移到更新的版本
3、Flyway的工作原理
最简单的情况是当您将Flyway指向一个空数据库时。

它将尝试定位其架构历史记录表。由于数据库是空的,Flyway 不会找到它,而是会 创建它。
您现在有一个数据库, 默认情况下有一个名为_flyway_schema_history_的空表:

该表将用于跟踪数据库的状态。
紧接着 Flyway 将开始扫描文件系统或应用程序的类路径以进行迁移。它们可以用 Sql 或 Java 编写。
然后根据版本号对迁移进行排序并按顺序应用:
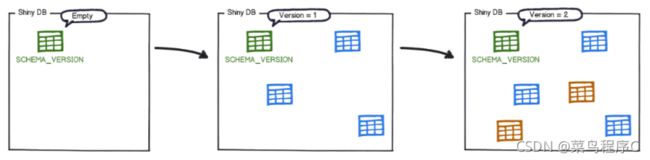
随着每次迁移的应用,架构历史记录表会相应地更新:
flyway_schema_history
| installed_rank | version | description | type | script | checksum | installed_by | installed_on | execution_time | success |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | Initial Setup | SQL | V1__Initial_Setup.sql | 1996767037 | axel | 2016-02-04 22:23:00.0 | 546 | true |
| 2 | 2 | First Changes | SQL | V2__First_Changes.sql | 1279644856 | axel | 2016-02-06 09:18:00.0 | 127 | true |
有了元数据和初始状态,我们现在可以讨论迁移到更新的版本。
Flyway 将再次扫描文件系统或应用程序的类路径以进行迁移。根据架构历史记录表检查迁移。如果它们的版本号低于或等于标记为当前的版本之一,则它们将被忽略。
剩余的迁移是待处理的迁移:可用,但未应用。
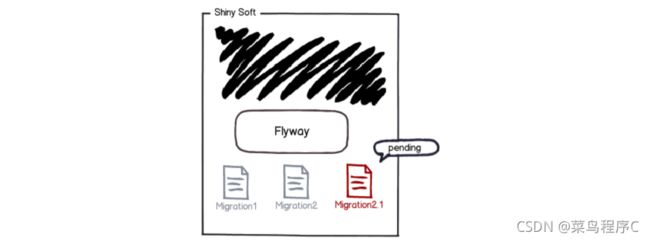
然后它们按版本号排序并按顺序执行:
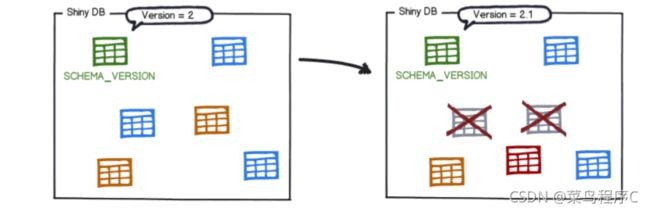
该模式历史表的更新因此:
flyway_schema_history
| installed_rank | version | description | type | script | checksum | installed_by | installed_on | execution_time | success |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | Initial Setup | SQL | V1__Initial_Setup.sql | 1996767037 | axel | 2016-02-04 22:23:00.0 | 546 | true |
| 2 | 2 | First Changes | SQL | V2__First_Changes.sql | 1279644856 | axel | 2016-02-06 09:18:00.0 | 127 | true |
| 3 | 2.1 | Refactoring | JDBC | V2_1__Refactoring | axel | 2016-02-10 17:45:05.4 | 251 | true |
就是这样每次需要演化数据库时,无论是结构 (DDL) 还是参考数据 (DML),只需创建一个版本号高于当前版本号的新迁移。下次 Flyway 启动时,它会找到它并相应地升级数据库。
4、整合SpringBoot
4.1maven依赖
<dependency>
<groupId>org.flywaydbgroupId>
<artifactId>flyway-coreartifactId>
<version>5.2.4version>
dependency>
4.2配置文件
flyway:
#开启
enabled: true
#当迁移时发现目标schema非空,而且带有没有元数据的表时,是否自动执行基准迁移,默认false.
baseline-on-migrate: true
# 检测迁移脚本的路径是否存在,如不存在,则抛出异常
check-location: true
#sql脚本位置
locations: classpath:db/migration
#是否允许无序的迁移,默认false
out-of-order: false
#编码
encoding: UTF-8
# flyway.baseline-description对执行迁移时基准版本的描述.
# flyway.baseline-on-migrate当迁移时发现目标schema非空,而且带有没有元数据的表时,是否自动执行基准迁移,默认false.
# flyway.baseline-version开始执行基准迁移时对现有的schema的版本打标签,默认值为1.
# flyway.check-location检查迁移脚本的位置是否存在,默认false.
# flyway.clean-on-validation-error当发现校验错误时是否自动调用clean,默认false.
# flyway.enabled是否开启flywary,默认true.
# flyway.encoding设置迁移时的编码,默认UTF-8.
# flyway.ignore-failed-future-migration当读取元数据表时是否忽略错误的迁移,默认false.
# flyway.init-sqls当初始化好连接时要执行的SQL.
# flyway.locations迁移脚本的位置,默认db/migration.
# flyway.out-of-order是否允许无序的迁移,默认false.
# flyway.password目标数据库的密码.
# flyway.placeholder-prefix设置每个placeholder的前缀,默认${.
# flyway.placeholder-replacementplaceholders是否要被替换,默认true.
# flyway.placeholder-suffix设置每个placeholder的后缀,默认}.
# flyway.placeholders.[placeholder name]设置placeholder的value
# flyway.schemas设定需要flywary迁移的schema,大小写敏感,默认为连接默认的schema.
# flyway.sql-migration-prefix迁移文件的前缀,默认为V.
# flyway.sql-migration-separator迁移脚本的文件名分隔符,默认__
# flyway.sql-migration-suffix迁移脚本的后缀,默认为.sql
# flyway.tableflyway使用的元数据表名,默认为schema_version
# flyway.target迁移时使用的目标版本,默认为latest version
# flyway.url迁移时使用的JDBC URL,如果没有指定的话,将使用配置的主数据源
# flyway.user迁移数据库的用户名
# flyway.validate-on-migrate迁移时是否校验,默认为true.
4.3脚本规范
示例:
V1.1.__description.sql
R__description.sql
prefix:可配置,前缀标识,默认值 V 表示 Versioned,R 表示 Repeatable;
Version:标识版本号,由一个或多个数字构成,数字之间的分隔符可用点.或单下划线_;
separator:分隔符,默认是双下划线;
description:描述信息,文字之间可以用单下划线或空格分隔
suffix:可配置,后续标识,后续标识,默认为 .sql;
Versioned migration 用于版本升级,每个版本都有唯一的版本号并只能 apply 依次。(也就是V开头的)
Repeatable migration 是指可重复加载的 migration,可以重复修改内容使用一旦脚本的 checkksum 有变动,flyway 就会重新应用该脚本,它并不用于版本更新,这类的 migration 总是在 versioned migration 执行之后才被执行(R开头的)
4.4项目使用

V1.0__schema.sql是初始化表结构脚本
V1.1__data.sql 是初始化数据脚本
V1.2__user.sql 是增加了一张user表里面有部分数据
R__user.sql 是对user表增加数据
以上这几个脚本只有R__user.sql可以对脚本进行重复修改使用,其他都不可以只能在下面依次添加版本号使用如V1.2__test.sql或V2.0__test.sql等等只能大不能小
4.5启动项目
在启动项目的时候会发现数据库会执行对应的脚本,以及会增加一张表flyway_schema_history记录执行脚本信息

4.6缺点
缺点就是不能自动创建数据库,如果我们指定了数据源配置数据脚本,但是我们没有手动去创建数据库的话也会出现错误,还需要额外添加配置来创建数据库这样才能完成自动化脚本处理!
也可以在配置文件中增加一个配置开关product.initdb.enable=true,然后在DataSourceConfig 判断一下是否需要创建数据库
4.6.1创建数据库配置
@Configuration
@Primary //在同样的DataSource中,首先使用被标注的DataSource
public class DataSourceConfig {
private Logger log = LoggerFactory.getLogger(DataSourceConfig.class);
@Value("${spring.datasource.url}")
//jdbc:mysql://127.0.0.1:3306/insight?useUnicode=true&characterEncoding=utf8&failOverReadOnly=false&allowMultiQueries=true
private String datasourceUrl;
@Value("${spring.datasource.driver-class-name}")
private String driverClassName;
@Value("${spring.datasource.username}")
private String username;
@Value("${spring.datasource.password}")
private String password;
@Bean
public DataSource dataSource(){
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(datasourceUrl);
datasource.setUsername(username);
datasource.setPassword(password);
datasource.setDriverClassName(driverClassName);
try {
Class.forName(driverClassName);
String url01 = datasourceUrl.substring(0,datasourceUrl.indexOf("?"));
String url02 = url01.substring(0,url01.lastIndexOf("/"));
String datasourceName = url01.substring(url01.lastIndexOf("/")+1);
// 连接已经存在的数据库,如:mysql
Connection connection = DriverManager.getConnection(url02, username, password);
Statement statement = connection.createStatement();
// 创建数据库
statement.executeUpdate("create database if not exists `" + datasourceName + "` default character set utf8 COLLATE utf8_general_ci");
statement.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
return datasource;
}
}
非常的简单实用方便,还不是美滋滋~~~点个赞吧!