2021Java开发工程师必备知识,Java后端学习主流知识学习系列(一)(建议先收藏)
2021Java开发工程师必备知识,Java后端主流知识学习系列(一)(有用的客官建议三连!)
- 初 前言
- 一、Java基础
- 二、操作系统
- 三、计算机网络
- 四、数据结构
- 五、算法
- 六、数据库
- 七、热门框架技术
- 八、微服务分布式架构
- 九、服务器中间件
- 十、前沿技术
- 总结
初 前言
大家好,菜菜希望这个系列的文章能够帮助各位大佬和菜菜自己,文章内容包含Java基础+操作系统+计算机网络+数据结构+算法+数据库+热门框架技术+微服务分布式架构+服务器中间件+前沿技术等。内容涵盖较多,涉及知识面比较广。当然也可以点击目录直达想看的内容哈,初衷是希望日积月累,量变引发质变,培养好我们自己!您觉得有用的话三连支持一下,菜菜感激不尽!!!

一、Java基础
什么是JDK?
JDK 是 Java Development ToolKit 的简称,也就是 Java 开发工具包。JDK 是整个 Java 的核心,包括 Java 运行环境(Java Runtime Envirnment,简称 JRE),Java 工具(比如 javac、java、javap 等等),以及 Java 基础类库(比如 rt.jar)。
平时安装的JDK会有以下几部分(了解)
- bin:包含了最主要的是编译器(javac.exe)
- include:Java 和 JVM 交互用的头文件
- lib:类库
- jre:Java 运行环境
JDK的三种类型
- J2SE:Standard Edition,标准版,是我们通常用的一个版本,从 JDK 5.0 开始,改名为 Java SE。
- J2EE:Enterprise Edition,企业版,从 JDK 5.0 开始,改名为 Java EE。
- J2ME:Micro Edition,主要应用于移动设备、嵌入式设备,从 JDK 5.0 开始,改名为 Java ME
Java的三种技术架构
- JAVAEE:Java Platform Enterprise Edition,开发企业环境下的应用程序,主要针对web程序开发;
- JAVASE:Java Platform Standard Edition,完成桌面应用程序的开发,是其它两者的基础;
- JAVAME:Java Platform Micro Edition,开发电子消费产品和嵌入式设备,如手机中的程序;
什么是JRE?
Java Runtime Environment:是Sun的产品,java程序的运行环境,java运行的所需的类库+JVM(java虚拟机)。 是面向Java程序的使用者,而不是开发者。
如果安装了JDK,会发同你的电脑有两套JRE,一套位于 \jre 另外一套位于 C:\Program Files\Java\jre1.5.0_15 目录下,后面这套比前面那套少了Server端的Java虚拟机,不过直接将前面那套的Server端Java虚拟机复制过来就行了。而且在安装JDK可以选择是否安装这个位于 C:\Program Files\Java 目录下的JRE。如果你只安装JRE,而不是JDK,那么只会在 C:\Program Files\Java 目录下安装唯一的一套JRE。
Java 基本数据类型
变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。
内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。
八种基本类型(四个整数型+两个浮点型+字符类型+布尔型)
下表列出了 Java 各个类型的默认值
| 数据类型 | 字节 (1字节=8位) | 默认值 |
|---|---|---|
| byte | 8位 | 0 |
| short | 16 位 | 0 |
| int | 32位 | 0 |
| long | 64 位 | 0L |
| float | 32位 | 0.0f |
| double | 64 位 | 0.0d |
| char | 16 位 Unicode 字符 | ‘u0000’ |
| boolean | 一位 | false |
Java 引用数据类型
引用类型包括三种:
- 类 Class
- 接口 Interface
- 数组 Array
引用类型一般是通过new关键字来创建,比如Integer num = new Integer(3);它存放在内存的堆中,可以在运行时动态的分配内存大小,生存期也不必事先告诉编译器,当引用类型变量不被使用时,Java内部的垃圾回收器GC会自动回收走。引用变量中存放的不是变量的内容,而是存放变量内容的地址。
在参数传递时,基本类型都是传值,也就是传递的都是原变量的值得拷贝,改变这个值不会改变原变量,而引用类型传递的是地址,也就是参数与原变量指向的是同一个地址,所以如果改变参数的值,原变量的值也会改变。这点要注意。
在java中,8种基本类型在java中都有对应的封装类型,也就是引用类型:
- 整数类型 Byte、Short、Integer、Long
- 浮点数类型 Float、Double
- 字符型 Character
- 布尔类型 Boolean

二、操作系统
操作系统的四个特性
- 并发:同一段时间内多个程序执行(注意区别并行和并发,前者是同一时刻的多个事件,后者是同一时间段内的多个事件)
- 共享:系统中的资源可以被内存中多个并发执行的进线程共同使用
- 虚拟:通过时分复用(如分时系统)以及空分复用(如虚拟内存)技术实现把一个物理实体虚拟为多个
- 异步:系统中的进程是以走走停停的方式执行的,且以一种不可预知的速度推进
死锁定义
在两个或多个并发进程中,如果每个进程持有某种资源而又都等待别的进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗地讲,就是两个或多个进程被无限期地阻塞、相互等待的一种状态。
死锁产生条件(4个)
- 互斥条件:一个资源一次只能被一个进程使用
- 请求保持条件:一个进程因请求资源而阻塞时,对已经获得资源保持不放
- 不可抢占条件: 进程已获得的资源在未使用完之前不能强行剥夺
- 循环等待条件;若干进程之间形成一种头尾相接的循环等待资源的关系
死锁处理
- 预防死锁:破坏产生死锁的4个必要条件中的一个或者多个;实现起来比较简单,但是如果限制过于严格会降低系统资源利用率以及吞吐量
- 避免死锁:在资源的动态分配中,防止系统进入不安全状态(可能产生死锁的状态)-如银行家算法
- 检测死锁:允许系统运行过程中产生死锁,在死锁发生之后,采用一定的算法进行检测,并确定与死锁相关的资源和进程,采取相关方法清除检测到的死锁。实现难度大
- 解除死锁:与死锁检测配合,将系统从死锁中解脱出来(撤销进程或者剥夺资源)。对检测到的和死锁相关的进程以及资源,通过撤销或者挂起的方式,释放一些资源并将其分配给处于阻塞状态的进程,使其转变为就绪态。实现难度大
什么是银行家算法?
银行家算法(Banker’s Algorithm)是一个避免死锁(Deadlock)的著名算法,是由艾兹格·迪杰斯特拉在1965年为T.H.E系统设计的一种避免死锁产生的算法。它以银行借贷系统的分配策略为基础,判断并保证系统的安全运行。
银行家算法的实现思想:
- 允许进程动态地申请资源,系统在每次实施资源分配之前,先计算资源分配的安全性,若此次资源分配安全(即资源分配后,系统能按某种顺序来为每个进程分配其所需的资源,直至最大需求,使每个进程都可以顺利地完成),便将资源分配给进程,否则不分配资源,让进程等待。
操作系统分类
批处理操作系统、分时操作系统(Unix)、实时操作系统、网络操作系统、分布式操作系统、微机操作系统(Linux、Windows、IOS等)、嵌入式操作系统。

三、计算机网络
网络层次划分
为了使不同计算机厂家生产的计算机能够相互通信,以便在更大的范围内建立计算机网络,国际标准化组织(ISO)在1978年提出了"开放系统互联参考模型",即著名的OSI/RM模型(Open System Interconnection/Reference Model)。它将计算机网络体系结构的通信协议划分为七层,自下而上依次为:
- 物理层(Physics Layer)、数据链路层(Data Link Layer)、网络层(Network
Layer)、传输层(Transport Layer)、会话层(Session Layer)、表示层(Presentation
Layer)、应用层(Application Layer)。
其中第四层完成数据传送服务,上面三层面向用户。除了标准的OSI七层模型以外,常见的网络层次划分还有TCP/IP四层协议以及TCP/IP五层协议
TCP/IP协议
TCP/IP协议是Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。通俗而言:TCP负责发现传输的问题,一有问题就发出信号,要求重新传输,直到所有数据安全正确地传输到目的地。而IP是给因特网的每一台联网设备规定一个地址。
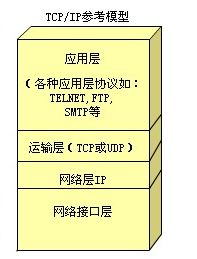
应用层:
- 向用户提供一组常用的应用程序,比如电子邮件、文件传输访问、远程登录等。远程登录TELNET使用TELNET协议提供在网络其它主机上注册的接口。TELNET会话提供了基于字符的虚拟终端。文件传输访问FTP使用FTP协议来提供网络内机器间的文件拷贝功能。
传输层:
- 提供应用程序间的通信。其功能包括:一、格式化信息流;二、提供可靠传输。为实现后者,传输层协议规定接收端必须发回确认,并且假如分组丢失,必须重新发送。
网络层 :
- 负责相邻计算机之间的通信。
网络接口层:
- 这是TCP/IP软件的最低层,负责接收IP数据报并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层。
IP地址
IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
首先出现的IP地址是IPV4,它只有4段数字,每一段最大不超过255。由于互联网的蓬勃发展,IP位址的需求量愈来愈大,使得IP位址的发放愈趋严格,各项资料显示全球IPv4位址可能在2005至2010年间全部发完(实际情况是在2019年11月25日IPv4位地址分配完毕)。地址空间的不足必将妨碍互联网的进一步发展。为了扩大地址空间,拟通过IPv6重新定义地址空间。IPv6采用128位地址长度。在IPv6的设计过程中除了一劳永逸地解决了地址短缺问题以外,还考虑了在IPv4中解决不好的其它问题。
DNS协议是什么?
DNS是域名系统(DomainNameSystem)的缩写,该系统用于命名组织到域层次结构中的计算机和网络服务,可以简单地理解为将URL转换为IP地址。域名是由圆点分开一串单词或缩写组成的,每一个域名都对应一个惟一的IP地址,在Internet上域名与IP地址之间是一一对应的,DNS就是进行域名解析的服务器。
DNS命名用于Internet等TCP/IP网络中,通过用户友好的名称查找计算机和服务。
NAT协议是什么?
NAT网络地址转换(Network Address Translation)属接入广域网(WAN)技术,是一种将私有(保留)地址转化为合法IP地址的转换技术,它被广泛应用于各种类型Internet接入方式和各种类型的网络中。
原因很简单,NAT不仅完美地解决了lP地址不足的问题,而且还能够有效地避免来自网络外部的攻击,隐藏并保护网络内部的计算机。
DHCP协议是什么?
DHCP动态主机设置协议(Dynamic Host Configuration Protocol)是一个局域网的网络协议。
使用UDP协议工作,主要有两个用途:
- 给内部网络或网络服务供应商自动分配IP地址
- 给用户或者内部网络管理员作为对所有计算机作中央管理的手段

四、数据结构
一些概念
数据
- 所有能被输入到计算机中,且能被计算机处理的符号的集合。是计算机操作的对象的总称。
数据元素
- 数据(集合)中的一个“个体”,数据及结构中讨论的基本单位
数据项
- 数据的不可分割的最小单位。一个数据元素可由若干个数据项组成。
数据类型
- 在一种程序设计语言中,变量所具有的数据种类。整型、浮点型、字符型等等
逻辑结构
- 数据之间的相互关系
算法五个特性
有穷性、确定性、可行性、输入、输出
算法设计要求
正确性、可读性、健壮性、高效率与低存储量需求。(好的算法)
时间复杂度
算法的执行时间与原操作执行次数之和成正比。时间复杂度有小到大:O(1)、O(logn)、O(n)、O(nlogn)、O(n2)、O(n3)。幂次时间复杂度有小到大O(2n)、O(n!)、O(nn)
空间复杂度
若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析除输入和程序之外的辅助变量所占额外空间。
物理结构/存储结构
数据在计算机中的表示。物理结构是描述数据具体在内存中的存储(如:顺序结构、链式结构、索引结构、哈希结构)等

五、算法
贪心算法
在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。每一步只考虑一个数据,他的选取应该满足局部优化的条件。若下一个数据和部分最优解连在一起不再是可行解时,就不把该数据添加到部分解中,直到把所有数据枚举完,或者不能再添加算法停止。
基本思路
- 建立数学模型来描述问题
- 把求解的问题分成若干个子问题
- 对每个子问题求解,得到子问题的局部最优解
- 把子问题的解局部最优解合成原来问题的一个解
存在的问题
- 不能保证求得的最后解是最佳的
- 不能用来求最大值或最小值的问题
- 只能求满足某些约束条件的可行解的范围
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。
实际上,贪心算法适用的情况很少。一般对一个问题分析是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可以做出判断。
贪心算法的实现框架
从问题的某一初始解出发;
while (能朝给定总目标前进一步)
{
利用可行的决策,求出可行解的一个解元素;
}
由所有解元素组合成问题的一个可行解;
例题:
[背包问题]
有一个背包,背包容量是M=150。有7个物品,物品可以分割成任意大小。 要求尽可能让装入背包中的物品总价值最大,但不能超过总容量。 物品
A B C D E F G 重量 35 30 60 50 40 10 25 价值 10 40 30 50 35 40 30
这个例子,可以说很经典。
分析:
目标函数: ∑pi最大
约束条件是装入的物品总重量不超过背包容量,即∑wi<=M( M=150)
(1)根据贪心的策略,每次挑选价值最大的物品装入背包,得到的结果是否最优?
(2)每次挑选所占重量最小的物品装入是否能得到最优解?
(3)每次选取单位重量价值最大的物品,成为解本题的策略?
贪心算法是很常见的算法之一,这是由于它简单易行,构造贪心策略简单。但是,它需要证明后才能真正运用到题目的算法中。一般来说,贪心算法的证明围绕着整个问题的最优解一定由在贪心策略中存在的子问题的最优解得来的。
对于本例题中的3种贪心策略,都无法成立,即无法被证明,解释如下:
(1)贪心策略:选取价值最大者。反例:
W=30
物品:A B C
重量:28 12 12
价值:30 20 20
根据策略,首先选取物品A,接下来就无法再选取了,可是,选取B、C则更好。
(2)贪心策略:选取重量最小。它的反例与第一种策略的反例差不多。
(3)贪心策略:选取单位重量价值最大的物品。反例:
W=30
物品:A B C
重量:28 20 10
价值:28 20 10
根据策略,三种物品单位重量价值一样,程序无法依据现有策略作出判断,如果选择A,则答案错误。
值得注意的是,贪心算法并不是完全不可以使用,贪心策略一旦经过证明成立后,它就是一种高效的算法。比如,求最小生成树的Prim算法和Kruskal算法都是漂亮的贪心算法。
[最大整数]
设有n个正整数,将它们连接成一排,组成一个最大的多位整数。
例如:n=3时,3个整数13,312,343,连成的最大整数为34331213。
又如:n=4时,4个整数7,13,4,246,连成的最大整数为7424613。 输入:n N个数 输出:连成的多位数
算法分析:
此题很容易想到使用贪心法,在考试时有很多同学把整数按从大到小的顺序连接起来,测试题目的例子也都符合,但最后测试的结果却不全对。按这种标准,我们很容易找到反例:12,121应该组成12121而非12112,那么是不是相互包含的时候就从小到大呢?也不一定,如12,123就是12312而非12123,这种情况就有很多种了。是不是此题不能用贪心法呢?
其实此题可以用贪心法来求解,只是刚才的标准不对,正确的标准是:先把整数转换成字符串,然后在比较a+b和b+a,如果a+b>=b+a,就把a排在b的前面,反之则把a排在b的后面。
@Test
public void testMaxNum() {
//有n个正整数,将它们连接成一排,组成一个最大的多位整数
//12112错误
//12121正解
// int[] nums = {
12, 121};
int[] nums = {
12, 123};
String result = maxNum(nums);
System.out.println("组成最大整数:" + result);
}
/**
* 根据给定的整数组成最大的多位数
* @param nums
*/
public String maxNum(int[] nums) {
String result = "";
for (int i = 0; i < nums.length; i++) {
String num1 = nums[i] + "";
for (int j = 1; j < nums.length; j++) {
String num2 = nums[j] + "";
if ((num1 + num2).compareTo(num2 + num1) < 0) {
int temp = nums[j];
nums[j] = nums[i];
nums[i] = temp;
}
}
}
for (int i = 0; i < nums.length; i++) {
result += nums[i];
}
return result;
}
【纸币找零问题】
假设1元、2元、5元、10元、20元、50元、100元的纸币,张数不限制,现在要用来支付K元,至少要多少张纸币?
代码如下
public static void greedyGiveMoney(int money) {
System.out.println("需要找零: " + money);
int[] moneyLevel = {
1, 5, 10, 20, 50, 100};
for (int i = moneyLevel.length - 1; i >= 0; i--) {
int num = money/ moneyLevel[i];
int mod = money % moneyLevel[i];
money = mod;
if (num > 0) {
System.out.println("需要" + num + "张" + moneyLevel[i] + "块的");
}
}
}
(1)如果不限制纸币的金额,那这种情况还适合用贪心算法么。比如1元,2元,3元,4元,8元,15元的纸币,用来支付K元,至少多少张纸币?
经我们分析,这种情况是不适合用贪心算法的,因为我们上面提供的贪心策略不是最优解。比如,纸币1元,5元,6元,要支付10元的话,按照上面的算法,至少需要1张6元的,4张1元的,而实际上最优的应该是2张5元的。
(2)如果限制纸币的张数,那这种情况还适合用贪心算法么。比如1元10张,2元20张,5元1张,用来支付K元,至少多少张纸币?
同样,仔细想一下,就知道这种情况也是不适合用贪心算法的。比如1元10张,20元5张,50元1张,那用来支付60元,按照上面的算法,至少需要1张50元,10张1元,而实际上使用3张20元的即可;
(3)所以贪心算法是一种在某种范围内,局部最优的算法。
六、数据库
什么是事务?
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
事务的结束有两种,当事务中的所以步骤全部成功执行时,事务提交。如果其中一个步骤失败,将发生回滚操作,撤消撤消之前到事务开始时的所以操作。
事务四大特性
原子性( Atomicity )、一致性( Consistency )、隔离性( Isolation )和持续性( Durability)
原子性,要么执行,要么不执行
隔离性,所有操作全部执行完以前其它会话不能看到过程
一致性,事务前后,数据总额一致
持久性,一旦事务提交,对数据的改变就是永久的
MySQL的四种隔离级别来源
读未提交
就是一个事务可以读取另一个未提交事务的数据。
事例:老板要给程序员发工资,程序员的工资是3.6万/月。但是发工资时老板不小心按错了数字,按成3.9万/月,该钱已经打到程序员的户口,但是事务还没有提交,就在这时,程序员去查看自己这个月的工资,发现比往常多了3千元,以为涨工资了非常高兴。但是老板及时发现了不对,马上回滚差点就提交了的事务,将数字改成3.6万再提交。
分析:实际程序员这个月的工资还是3.6万,但是程序员看到的是3.9万。他看到的是老板还没提交事务时的数据。这就是脏读。
读提交
就是一个事务要等另一个事务提交后才能读取数据。
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(程序员事务开启),收费系统事先检测到他的卡里有3.6万,就在这个时候!!程序员的妻子要把钱全部转出充当家用,并提交。当收费系统准备扣款时,再检测卡里的金额,发现已经没钱了(第二次检测金额当然要等待妻子转出金额事务提交完)。程序员就会很郁闷,明明卡里是有钱的…
分析:这就是读提交,若有事务对数据进行更新(UPDATE)操作时,读操作事务要等待这个更新操作事务提交后才能读取数据,可以解决脏读问题。但在这个事例中,出现了一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读。
重复读
就是在开始读取数据(事务开启)时,不再允许修改操作。
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他买单时(事务开启,不允许其他事务的UPDATE修改操作),收费系统事先检测到他的卡里有3.6万。这个时候他的妻子不能转出金额了。接下来收费系统就可以扣款了。
分析:重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
序列化
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
MySQL的索引
| 索引 | 区别 |
|---|---|
| Hash | hash索引,等值查询效率高,不能排序,不能进行范围查询 |
| B+ | 数据有序,范围查询 |
索引的优缺点
- 索引最大的好处是提高查询速度,
- 缺点是更新数据时效率低,因为要同时更新索引
- 对数据进行频繁查询进建立索引,如果要频繁更改数据不建议使用索引。
InnoDB索引和MyISAM索引的区别
- 一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
- 二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主

七、热门框架技术
Spring
到目前为止,Spring 仍然是最流行的 Java 开发框架,并且几乎应用在了所有地方 —— 从流媒体平台到在线购物。 它的设计目的是为 基于 Java EE 平台的 Java 应用程序创建后端。Spring 框架基于依赖注入的功能(控件反转 IOC 的一部分),它是在 Java 中构建业务应用程序的理想解决方案:微服务、复杂的数据处理系统、云应用程序或快速、安全且响应迅速的 Web 应用程序。 Spring 的特点是轻量级且易于实现和使用,生态非常活跃,因此完全可以预计 2021 年 Spring 将会更加普及,也会有更多强大的功能。对于 Java 开发者而言,Spring 仍然是不得不学的优秀框架。
Spring的初衷:
- 1、JAVA EE开发应该更加简单。
- 2、使用接口而不是使用类,是更好的编程习惯。Spring将使用接口的复杂度几乎降低到了零。
- 3、为JavaBean提供了一个更好的应用配置框架。
- 4、更多地强调面向对象的设计,而不是现行的技术如JAVA EE。
- 5、尽量减少不必要的异常捕捉。
- 6、使应用程序更加容易测试。
Spring的目标:
- 1、可以令人方便愉快的使用Spring。
- 2、应用程序代码并不依赖于Spring APIs。
- 3、Spring不和现有的解决方案竞争,而是致力于将它们融合在一起。
Spring的基本组成:
- 1、最完善的轻量级核心框架。
- 2、通用的事务管理抽象层。
- 3、JDBC抽象层。
- 4、集成了Toplink, Hibernate, JDO, and iBATIS SQL Maps。
- 5、AOP功能。
- 6、灵活的MVC Web应用框架。
八、微服务分布式架构
微服务的诞生
微服务是基于分而治之的思想演化出来的。过去传统的一个大型而又全面的系统,随着互联网的发展已经很难满足市场对技术的需求,于是我们从单独架构发展到分布式架构,又从分布式架构发展到 SOA 架构,服务不断的被拆分和分解,粒度也越来越小,直到微服务架构的诞生。
分布式事务
分布式事务顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合而成。
分布式事务场景如何设计系统架构及解决数据一致性问题,个人理解最终方案把握以下原则就可以了,那就是:大事务=小事务(原子事务)+异步(消息通知),解决分布式事务的最好办法其实就是不考虑分布式事务,将一个大的业务进行拆分,整个大的业务流程,转化成若干个小的业务流程,然后通过设计补偿流程从而考虑最终一致性。
九、服务器中间件
RocketMQ:
为什么使用mq?具体的使用场景是什么?
mq的作用很简单,削峰填谷。以电商交易下单的场景来说,正向交易的过程可能涉及到创建订单、扣减库存、扣减活动预算、扣减积分等等。每个接口的耗时如果是100ms,那么理论上整个下单的链路就需要耗费400ms,这个时间显然是太长了。
如果这些操作全部同步处理的话,首先调用链路太长影响接口性能,其次分布式事务的问题很难处理,这时候像扣减预算和积分这种对实时一致性要求没有那么高的请求,完全就可以通过mq异步的方式去处理了。同时,考虑到异步带来的不一致的问题,我们可以通过job去重试保证接口调用成功,而且一般公司都会有核对的平台,比如下单成功但是未扣减积分的这种问题可以通过核对作为兜底的处理方案。
使用mq之后我们的链路变简单了,同时异步发送消息我们的整个系统的抗压能力也上升了。
异步,解耦,消峰,MQ的三大主要应用场景。
异步处理
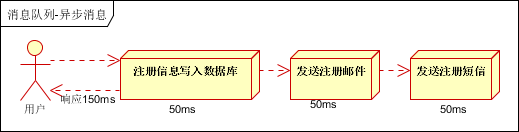
用户注册后,需要发送注册邮件和注册短信。传统的做法:
将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
引入消息队列(mq),异步处理。
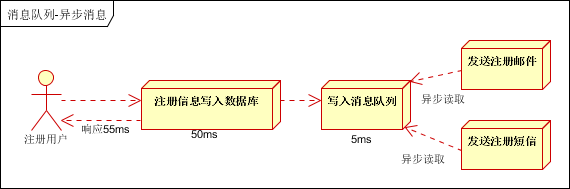
应用解耦
交易系统作为淘宝/天猫主站最核心的系统,每笔交易订单数据的产生会引起几百个下游业务系统的关注,包括物流、购物车、积分、流计算分析等等,整体业务系统庞大而且复杂,消息队列
MQ 可实现异步通信和应用解耦,确保主站业务的连续性。
削峰填谷
诸如秒杀、抢红包、企业开门红等大型活动时皆会带来较高的流量脉冲,或因没做相应的保护而导致系统超负荷甚至崩溃,或因限制太过导致请求大量失败而影响用户体验,消息队列 MQ 可提供削峰填谷的服务来解决该问题。
十、前沿技术
架构&云计算
2020 年,微服务领域出现了一个新词汇:“宏服务”(Macro Services)由Uber团队提出。宏服务其实并不是一个全新的架构,而是一种在单体和微服务间取得平衡的理念。
目前,微服务的发展增加了系统的复杂性,微服务日趋细化、复用率达到顶峰,服务之间的关系变得愈加复杂,维护成本增加。在这种情况下,技术人员提出了“宏服务”,它只是个整体式程序,其中所有业务服务都作为单个程序包部署在应用程序服务器中,并共享同一个数据库(物理上和逻辑上)。它不太复杂,服务之间奉行紧密耦合。
2021 年,化繁为简仍然会是微服务的重点课题。
脑机接口帮助人类超越生物学极限
链接

大数据&人工智能
随着 IT 基础设施加速往云上迁移,云原生正在成为新一代数据架构的主流标准。越来越多企业客户从 On-Premise 的数仓方案转向基于云(包含公有云和私有云)的解决方案,这种趋势在美国toB市场已经被广泛接受,在国内toB 市场也方兴未艾。新的一年大数据与云的融合还会继续加深,大数据领域将加速拥抱“融合”或“一体化”演进的新方向。
总结
俗话说是笨鸟先飞,我还得笨鸟多飞《活着》
