Python机器学习库SKLearn:监督学习之广义线性模型
以下是用于回归的一组方法,其中预期目标值为输入变量的线性组合,在数学概念中,假设{y^}是预测值。
其中,向量 w = (w_1,..., w_p) 作为一个 coef_ (系数)and w_0 作为 intercept_(截距)。
1.1.1 普通最小二乘法(Ordinary Least Squares)
LinearRegression是具有系数w =(w_1,...,w_p)的以最小化数据集中的观察到的值与通过线性近似预测的值之间的平方和的残差的线性模型。 数学上的形式如下:

1.1.2 岭回归(Ridge Regression)
Ridge回归通过对系数大小施加惩罚来解决普通最小二乘法的一些问题。 脊系数最小化受惩罚的残差平方和,
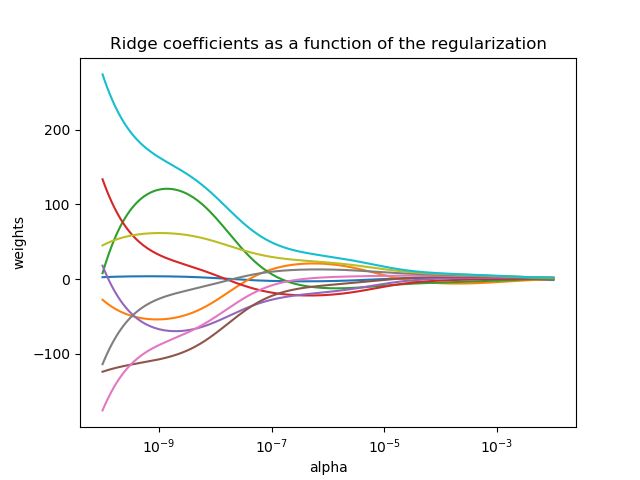
1.1.2.2 设置正则化参数:generalized交叉验证
RidgeCV使用内置的alpha参数的交叉验证实现脊回归。 该对象以与GridSearchCV相同的方式工作,除了它默认为广义交叉验证(GCV),一种高效形式的留一交叉验证:
Lasso是一个估计稀疏系数的线性模型。 它在一些上下文中是有用的,因为其倾向于优选具有较少参数值的解,有效地减少给定解所依赖的变量的数量。 为此,Lasso及其变体对于压缩感测领域是基础。 在某些条件下,它可以恢复非零权重的确切集合(见压缩感知:用L1 prior(Lasso)进行断层重建)。
数学上,它包括一个用 先验作为正则化训练的线性模型。 最小化的目标函数是:
因此, Lasso估计解决了添加了 的最小二乘惩罚的最小化,其中\α是常数, 是参数向量的范数。
1.1.3.1 设置正则化参数
α参数控制估计的系数的稀疏程度。
1.1.3.1.1 使用交叉验证
scikit-learn通过交叉验证显示设置Lasso alpha参数的对象:LassoCV和LassoLarsCV。 LassoLarsCV基于下面解释的最小角度回归算法。
对于具有许多共线回归的高维数据集,LassoCV是最常用的。 然而,LassoLarsCV具有探索更相关的α参数值的优点,并且如果样本的数量与观察的数量相比非常小,则通常比LassoCV更快。
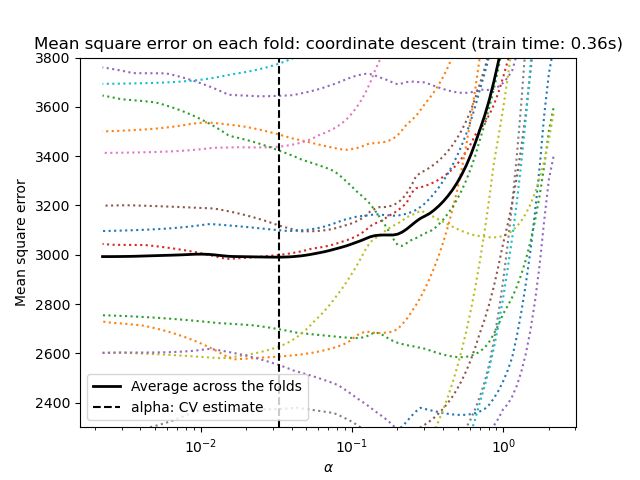
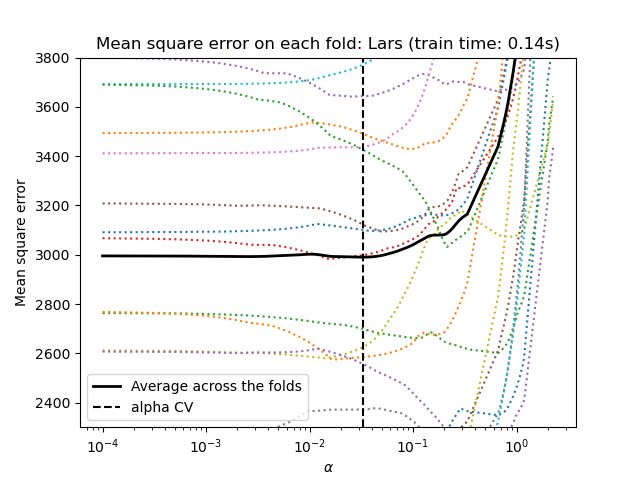
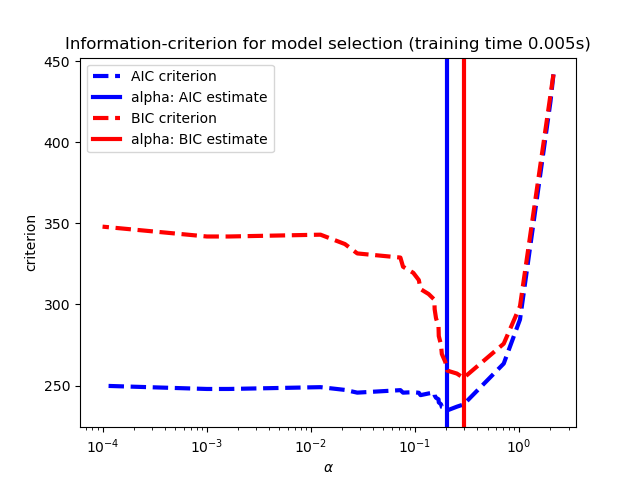
1.1.3.1.2 基于信息标准的模型选择
或者,估计器LassoLarsIC建议使用Akaike信息准则(AIC)和Bayes信息准则(BIC)。 当使用k折交叉验证时,正则化路径仅计算一次而不是k + 1次,这是计算上更便宜的替代方法来找到α的最佳值。 然而,这样的标准需要对解的自由度的适当估计,针对大样本(渐近结果)导出并且假设模型是正确的,即数据实际上由该模型生成。 当问题严重失调(比特征更多的特征)时,它们也倾向于断裂。
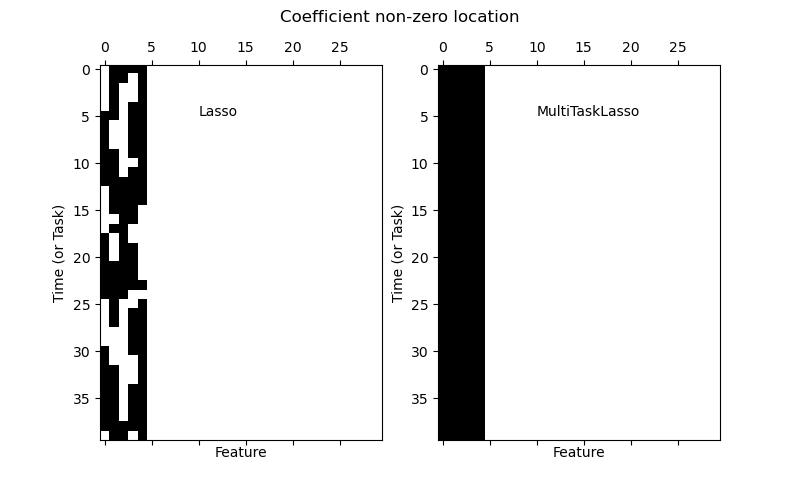
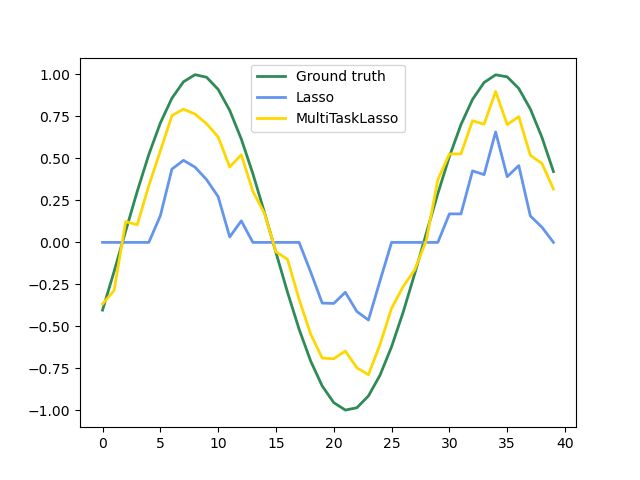
1.1.4. Multi-task Lasso
MultiTaskLasso是一个线性模型,用于联合估计多个回归问题的稀疏系数:y是形状的二维数组(n_samples,n_tasks)。 约束是所选的特征对于所有回归问题都相同,也称为任务。
下图比较了用简单Lasso或MultiTaskLasso获得的W中非零的位置。 Lasso估计产生分散的非零,而MultiTaskLasso的非零是完整列。
1.1.8. LARS Lasso
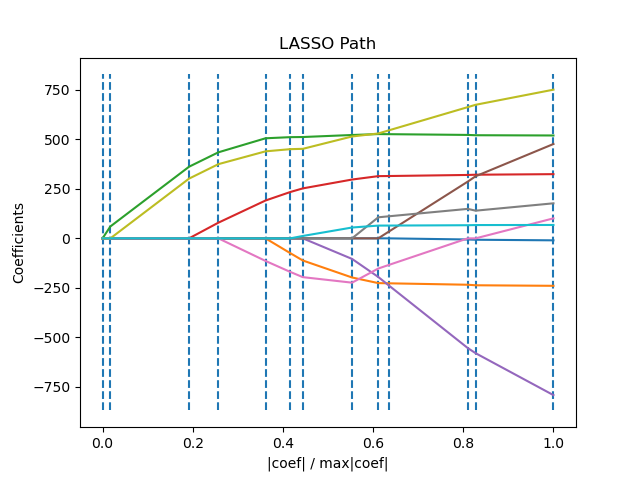
LassoLars是一个使用LARS算法实现的套索模型,与基于coordinate_descent的实现不同,这产生了精确的解,它是作为其系数范数的函数的分段线性。
1.1.10. Bayesian Regression 贝叶斯回归
1.1.10.1. Bayesian Ridge Regression
贝叶斯岭回归用于回归:
在拟合之后,该模型可以用于预测新值:
模型的权重w可以获得:
逻辑回归从名字上看起来像回归模型,但是逻辑回归是一个分类的线性分类模型而不是一个回归模型。 逻辑回归在文献中也称为logit回归,最大熵分类(MaxEnt)或对数线性分类器。 在这个模型中,描述单个试验的可能结果的概率使用逻辑函数建模。
scikit-learn中逻辑回归的实现可以从LogisticRegression类访问。 此实现可以适用于二元,可选的L2或L1正则化的One-vs- Rest或多项Logistic回归。
作为优化问题,二元类L2惩罚逻辑回归使以下成本函数最小化:
类似地,L1正则逻辑回归解决以下优化问题:
在LogisticRegression类中实现的解算器是“liblinear”,“newton-cg”,“lbfgs”和“sag”:
求解器“liblinear”使用坐标下降(CD)算法,并依赖于优秀的C ++ LIBLINEAR库,它随scikit-learn一起提供。然而,在liblinear中实现的CD算法不能学习真正的多项式(多类)模型;相反,优化问题以“一对一”的方式分解,因此为所有类训练单独的二进制分类器。这发生在引擎盖下,因此使用此解算器的LogisticRegression实例表现为多类分类器。对于L1惩罚,sklearn.svm.l1_min_c允许计算C的下限,以便得到非“零”(所有特征权重为零)模型。
“lbfgs”,“sag”和“newton-cg”求解器仅支持L2惩罚,并且发现对于一些高维数据更快地收敛。使用这些求解器将multi_class设置为“多项”学习一个真正的多项Logistic回归模型[5],这意味着其概率估计应该比默认的“一个vs休息”设置更好地校准。 “lbfgs”,“sag”和“newton-cg”求解器不能优化L1惩罚模型,因此“多项式”设置不学习稀疏模型。
求解器“sag”使用随机平均梯度下降[6]。对于大型数据集,当样本数和特征数都很大时,它比其他求解器更快。
简而言之,可以选择具有以下规则的求解器:
| Case | Solver |
|---|---|
| Small dataset or L1 penalty | “liblinear” |
| Multinomial loss or large dataset | “lbfgs”, “sag” or “newton-cg” |
| Very Large dataset | “sag” |