【YOLOV5-5.x 源码解读】datasets.py
目录
- 前言
- 0、导入需要的包和基本配置
- 1、相机设置
- 2、create_dataloader
- 3、自定义DataLoader
- 4、LoadImagesAndLabels
-
- 4.1、__init__
- 4.2、cache_labels
- 4.3、__len__
- 4.4.、__getitem__
- 4.5、collate_fn
- 4.6、collate_fn4
- 5、img2label_paths
- 6、verify_image_label
- 7、load_image
- 8、augment_hsv
- 9、load_mosaic、load_mosaic9
-
- 9.1、load_mosaic
- 9.2、load_mosaic9
- 10、random_perspective
- 11、box_candidates
- 12、replicate
- 13、letterbox
- 14、cutout
- 15、mixup
- 16、LoadImages、LoadStreams、LoadWebcam
- 17、hist_equalize
- 18、create_folder
- 19、flatten_recursive
- 20、extract_boxes
- 21、autosplit
- 22、dataset_stats
- 总结
前言
源码: YOLOv5源码.
导航: 【YOLOV5-5.x 源码讲解】整体项目文件导航.
注释版全部项目文件已上传至GitHub: yolov5-5.x-annotations.
这个文件主要是进行数据增强操作。
0、导入需要的包和基本配置
import glob # python自己带的一个文件操作相关模块 查找符合自己目的的文件(如模糊匹配)
import hashlib # 哈希模块 提供了多种安全方便的hash方法
import json # json文件操作模块
import logging # 日志模块
import math # 数学公式模块
import os # 与操作系统进行交互的模块 包含文件路径操作和解析
import random # 生成随机数模块
import shutil # 文件夹、压缩包处理模块
import time # 时间模块 更底层
from itertools import repeat # 复制模块
from multiprocessing.pool import ThreadPool, Pool # 多线程模块 线程池
from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块
from threading import Thread # 多线程操作模块
import cv2 # opencv模块
import numpy as np # numpy矩阵操作模块
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt # matplotlib画图模块
import torch # PyTorch深度学习模块
import torch.nn.functional as F # PyTorch函数接口 封装了很多卷积、池化等函数
import yaml # yaml文件操作模块
from PIL import Image, ExifTags # 图片、相机操作模块
from torch.utils.data import Dataset # 自定义数据集模块
from tqdm import tqdm # 进度条模块
from utils.general import check_requirements, check_file, check_dataset, xywh2xyxy, xywhn2xyxy, xyxy2xywhn, \
xyn2xy, segment2box, segments2boxes, resample_segments, clean_str
from utils.torch_utils import torch_distributed_zero_first
# Parameters
help_url = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
img_formats = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp', 'mpo'] # acceptable image suffixes
vid_formats = ['mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'] # acceptable video suffixes
num_threads = min(8, os.cpu_count()) # 定义多线程个数
logger = logging.getLogger(__name__) # 初始化日志
1、相机设置
\qquad 这部分是相机相关设置,当使用相机采样时才会使用。
# 相机设置
# Get orientation exif tag
# 专门为数码相机的照片而设定 可以记录数码照片的属性信息和拍摄数据
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
def get_hash(paths):
# 返回文件列表的hash值
# Returns a single hash value of a list of paths (files or dirs)
size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
h = hashlib.md5(str(size).encode()) # hash sizes
h.update(''.join(paths).encode()) # hash paths
return h.hexdigest() # return hash
def exif_size(img):
# 获取数码相机的图片宽高信息 并且判断是否需要旋转(数码相机可以多角度拍摄)
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]
if rotation == 6: # rotation 270
s = (s[1], s[0])
elif rotation == 8: # rotation 90
s = (s[1], s[0])
except:
pass
return s
2、create_dataloader
\qquad 自定义dataloader函数: 调用LoadImagesAndLabels获取数据集dataset(包括数据增强) + 调用分布式采样器DistributedSampler + 自定义InfiniteDataLoader 进行永久持续的采样数据 + 获取dataloader。关键核心是LoadImagesAndLabels(),这个文件的后面所有代码都是围绕这个模块进行的。
create_dataloader模块代码:
def create_dataloader(path, imgsz, batch_size, stride, single_cls=False,
hyp=None, augment=False, cache=False, pad=0.0, rect=False,
rank=-1, workers=8, image_weights=False, quad=False, prefix=''):
"""在train.py中被调用,用于生成Trainloader, dataset,testloader
自定义dataloader函数: 调用LoadImagesAndLabels获取数据集(包括数据增强) + 调用分布式采样器DistributedSampler +
自定义InfiniteDataLoader 进行永久持续的采样数据
:param path: 图片数据加载路径 train/test 如: ../datasets/VOC/images/train2007
:param imgsz: train/test图片尺寸(数据增强后大小) 640
:param batch_size: batch size 大小 8/16/32
:param stride: 模型最大stride=32 [32 16 8]
:param single_cls: 数据集是否是单类别 默认False
:param hyp: 超参列表dict 网络训练时的一些超参数,包括学习率等,这里主要用到里面一些关于数据增强(旋转、平移等)的系数
:param augment: 是否要进行数据增强 True
:param cache: 是否cache_images False
:param pad: 设置矩形训练的shape时进行的填充 默认0.0
:param rect: 是否开启矩形train/test 默认训练集关闭 验证集开启
:param rank: 多卡训练时的进程编号 rank为进程编号 -1且gpu=1时不进行分布式 -1且多块gpu使用DataParallel模式 默认-1
:param workers: dataloader的numworks 加载数据时的cpu进程数
:param image_weights: 训练时是否根据图片样本真实框分布权重来选择图片 默认False
:param quad: dataloader取数据时, 是否使用collate_fn4代替collate_fn 默认False
:param prefix: 显示信息 一个标志,多为train/val,处理标签时保存cache文件会用到
"""
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache
# 主进程实现数据的预读取并缓存,然后其它子进程则从缓存中读取数据并进行一系列运算。
# 为了完成数据的正常同步, yolov5基于torch.distributed.barrier()函数实现了上下文管理器
with torch_distributed_zero_first(rank):
# 载入文件数据(增强数据集)
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
batch_size = min(batch_size, len(dataset)) # bs
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, workers]) # number of workers
# 分布式采样器DistributedSampler
sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
# 使用InfiniteDataLoader和_RepeatSampler来对DataLoader进行封装, 代替原D先的DataLoader, 能够永久持续的采样数据
loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
return dataloader, dataset
\qquad 这个函数会在train.py中被调用,用于生成Trainloader, dataset,testloader:
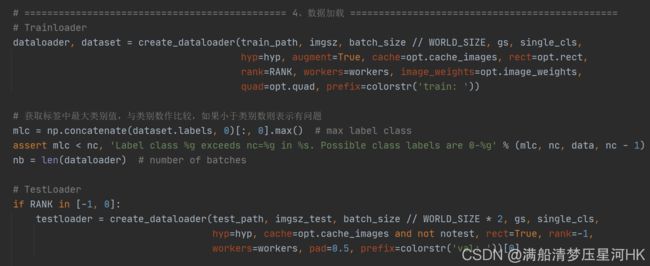
3、自定义DataLoader
\qquad 当image_weights=False时(不根据图片样本真实框分布权重来选择图片)就会调用这两个函数 进行自定义DataLoader,进行持续性采样。在上面的create_dataloader模块中被调用。
class InfiniteDataLoader(torch.utils.data.dataloader.DataLoader):
""" Dataloader that reuses workers
当image_weights=False时就会调用这两个函数 进行自定义DataLoader
https://github.com/ultralytics/yolov5/pull/876
使用InfiniteDataLoader和_RepeatSampler来对DataLoader进行封装, 代替原先的DataLoader, 能够永久持续的采样数据
Uses same syntax as vanilla DataLoader
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 调用_RepeatSampler进行持续采样
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
return len(self.batch_sampler.sampler)
def __iter__(self):
for i in range(len(self)):
yield next(self.iterator)
class _RepeatSampler(object):
""" Sampler that repeats forever
这部分是进行持续采样
Args:
sampler (Sampler)
"""
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
yield from iter(self.sampler)
4、LoadImagesAndLabels
\qquad 这个部分是数据载入(数据增强)部分,也就是自定义数据集部分,继承自Dataset,需要重写__init__,__getitem()__等抽象方法,另外目标检测一般还需要重写collate_fn函数。所以,理解这三个函数是理解数据增强(数据载入)的重中之重。
4.1、init
这个函数的入口是上面的create_dataloader函数:

\qquad 其实初始化过程并没有什么实质性的操作,更多是一个定义参数的过程(self参数),以便在__getitem()__中进行数据增强操作,所以这部分代码只需要抓住self中的各个变量的含义就算差不多了。
重点掌握以下红色部分代表什么意思
self.img_files: {list: N} 存放着整个数据集图片的相对路径
self.label_files: {list: N} 存放着整个数据集图片的相对路径
self.labels: 所有图片的所有gt框的信息
self.shapes: 所有图片的shape
self.segments: 所有图片的所有的多边形gt信息
self.batch: 记载着每张图片属于哪个batch
self.n: 数据集中所有图片的数量
self.indices: 记载着所有图片的index
self.rect=True时self.batch_shapes记载每个batch的shape(同一个batch的图片shape相同),在矩形训练时有用
__init__主要干了一下几件事:
- 赋值一些基础的self变量 用于后面在__getitem__中调用
- 得到path路径下的所有图片的路径self.img_files
- 根据imgs路径找到labels的路径self.label_files
- cache label
- Read cache 生成self.labels、self.shapes、self.img_files、self.label_files、self.batch、self.n、self.indices等变量
- 为Rectangular Training作准备: 生成self.batch_shapes
- 是否需要cache image(一般不需要,太大了)
__init__函数代码:
class LoadImagesAndLabels(Dataset):
# for training/testing
def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False,
image_weights=False, cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
"""
初始化过程并没有什么实质性的操作,更多是一个定义参数的过程(self参数),以便在__getitem()__中进行数据增强操作,所以这部分代码只需要抓住self中的各个变量的含义就算差不多了
self.img_files: {list: N} 存放着整个数据集图片的相对路径
self.label_files: {list: N} 存放着整个数据集图片的相对路径
cache label -> verify_image_label
self.labels: 如果数据集所有图片中没有一个多边形label labels存储的label就都是原始label(都是正常的矩形label)
否则将所有图片正常gt的label存入labels 不正常gt(存在一个多边形)经过segments2boxes转换为正常的矩形label
self.shapes: 所有图片的shape
self.segments: 如果数据集所有图片中没有一个多边形label self.segments=None
否则存储数据集中所有存在多边形gt的图片的所有原始label(肯定有多边形label 也可能有矩形正常label 未知数)
self.batch: 记载着每张图片属于哪个batch
self.n: 数据集中所有图片的数量
self.indices: 记载着所有图片的index
self.rect=True时self.batch_shapes记载每个batch的shape(同一个batch的图片shape相同)
"""
# 1、赋值一些基础的self变量 用于后面在__getitem__中调用
self.img_size = img_size # 经过数据增强后的数据图片的大小
self.augment = augment # 是否启动数据增强 一般训练时打开 验证时关闭
self.hyp = hyp # 超参列表
# 图片按权重采样 True就可以根据类别频率(频率高的权重小,反正大)来进行采样 默认False: 不作类别区分
self.image_weights = image_weights
self.rect = False if image_weights else rect # 是否启动矩形训练 一般训练时关闭 验证时打开 可以加速
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
# mosaic增强的边界值 [-320, -320]
self.mosaic_border = [-img_size // 2, -img_size // 2]
self.stride = stride # 最大下采样率 32
self.path = path # 图片路径
# 2、得到path路径下的所有图片的路径self.img_files 这里需要自己debug一下 不会太难
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
# 获取数据集路径path,包含图片路径的txt文件或者包含图片的文件夹路径
# 使用pathlib.Path生成与操作系统无关的路径,因为不同操作系统路径的‘/’会有所不同
p = Path(p) # os-agnostic
# 如果路径path为包含图片的文件夹路径
if p.is_dir(): # dir
# glob.glab: 返回所有匹配的文件路径列表 递归获取p路径下所有文件
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('**/*.*')) # pathlib
# 如果路径path为包含图片路径的txt文件
elif p.is_file(): # file
with open(p, 'r') as t:
t = t.read().strip().splitlines() # 获取图片路径,更换相对路径
# 获取数据集路径的上级父目录 os.sep为路径里的分隔符(不同路径的分隔符不同,os.sep可以根据系统自适应)
parent = str(p.parent) + os.sep
f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
else:
raise Exception(f'{
prefix}{
p} does not exist')
# 破折号替换为os.sep,os.path.splitext(x)将文件名与扩展名分开并返回一个列表
# 筛选f中所有的图片文件
self.img_files = sorted([x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in img_formats])
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in img_formats]) # pathlib
assert self.img_files, f'{
prefix}No images found'
except Exception as e:
raise Exception(f'{
prefix}Error loading data from {
path}: {
e}\nSee {
help_url}')
# 3、根据imgs路径找到labels的路径self.label_files
self.label_files = img2label_paths(self.img_files) # labels
# 4、cache label 下次运行这个脚本的时候直接从cache中取label而不是去文件中取label 速度更快
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache') # cached labels path
# Check cache
if cache_path.is_file():
# 如果有cache文件,直接加载 exists=True: 是否已从cache文件中读出了nf, nm, ne, nc, n等信息
cache, exists = torch.load(cache_path), True # load
# 如果图片版本信息或者文件列表的hash值对不上号 说明本地数据集图片和label可能发生了变化 就重新cache label文件
if cache.get('version') != 0.3 or cache.get('hash') != get_hash(self.label_files + self.img_files):
cache, exists = self.cache_labels(cache_path, prefix), False # re-cache
else:
# 否则调用cache_labels缓存标签及标签相关信息
cache, exists = self.cache_labels(cache_path, prefix), False # cache
# 打印cache的结果 nf nm ne nc n = 找到的标签数量,漏掉的标签数量,空的标签数量,损坏的标签数量,总的标签数量
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupted, total
# 如果已经从cache文件读出了nf nm ne nc n等信息,直接显示标签信息 msgs信息等
if exists:
d = f"Scanning '{
cache_path}' images and labels... {
nf} found, {
nm} missing, {
ne} empty, {
nc} corrupted"
tqdm(None, desc=prefix + d, total=n, initial=n) # display all cache results
if cache['msgs']:
logging.info('\n'.join(cache['msgs'])) # display all warnings msg
# 数据集没有标签信息 就发出警告并显示标签label下载地址help_url
assert nf > 0 or not augment, f'{
prefix}No labels in {
cache_path}. Can not train without labels. See {
help_url}'
# 5、Read cache 从cache中读出最新变量赋给self 方便给forward中使用
# cache中的键值对最初有: cache[img_file]=[l, shape, segments] cache[hash] cache[results] cache[msg] cache[version]
# 先从cache中去除cache文件中其他无关键值如:'hash', 'version', 'msgs'等都删除
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
# pop掉results、hash、version、msgs后只剩下cache[img_file]=[l, shape, segments]
# cache.values(): 取cache中所有值 对应所有l, shape, segments
# labels: 如果数据集所有图片中没有一个多边形label labels存储的label就都是原始label(都是正常的矩形label)
# 否则将所有图片正常gt的label存入labels 不正常gt(存在一个多边形)经过segments2boxes转换为正常的矩形label
# shapes: 所有图片的shape
# self.segments: 如果数据集所有图片中没有一个多边形label self.segments=None
# 否则存储数据集中所有存在多边形gt的图片的所有原始label(肯定有多边形label 也可能有矩形正常label 未知数)
# zip 是因为cache中所有labels、shapes、segments信息都是按每张img分开存储的, zip是将所有图片对应的信息叠在一起
labels, shapes, self.segments = zip(*cache.values()) # segments: 都是[]
self.labels = list(labels) # labels to list
self.shapes = np.array(shapes, dtype=np.float64) # image shapes to float64
self.img_files = list(cache.keys()) # 更新所有图片的img_files信息 update img_files from cache result
self.label_files = img2label_paths(cache.keys()) # 更新所有图片的label_files信息(因为img_files信息可能发生了变化)
if single_cls:
for x in self.labels:
x[:, 0] = 0
n = len(shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n # number of images
self.indices = range(n) # 所有图片的index
# 6、为Rectangular Training作准备
# 这里主要是注意shapes的生成 这一步很重要 因为如果采样矩形训练那么整个batch的形状要一样 就要计算这个符合整个batch的shape
# 而且还要对数据集按照高宽比进行排序 这样才能保证同一个batch的图片的形状差不多相同 再选则一个共同的shape代价也比较小
if self.rect:
# Sort by aspect ratio
s = self.shapes # wh
ar = s[:, 1] / s[:, 0] # aspect ratio
irect = ar.argsort() # 根据高宽比排序
self.img_files = [self.img_files[i] for i in irect] # 获取排序后的img_files
self.label_files = [self.label_files[i] for i in irect] # 获取排序后的label_files
self.labels = [self.labels[i] for i in irect] # 获取排序后的labels
self.shapes = s[irect] # 获取排序后的wh
ar = ar[irect] # 获取排序后的aspect ratio
# 计算每个batch采用的统一尺度 Set training image shapes
shapes = [[1, 1]] * nb # nb: number of batches
for i in range(nb):
ari = ar[bi == i] # bi: batch index
mini, maxi = ari.min(), ari.max() # 获取第i个batch中,最小和最大高宽比
# 如果高/宽小于1(w > h),将w设为img_size(保证原图像尺度不变进行缩放)
if maxi < 1:
shapes[i] = [maxi, 1] # maxi: h相对指定尺度的比例 1: w相对指定尺度的比例
# 如果高/宽大于1(w < h),将h设置为img_size(保证原图像尺度不变进行缩放)
elif mini > 1:
shapes[i] = [1, 1 / mini]
# 计算每个batch输入网络的shape值(向上设置为32的整数倍)
# 要求每个batch_shapes的高宽都是32的整数倍,所以要先除以32,取整再乘以32(不过img_size如果是32倍数这里就没必要了)
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
# 7、是否需要cache image 一般是False 因为RAM会不足 cache label还可以 但是cache image就太大了 所以一般不用
# Cache images into memory for faster training (WARNING: large datasets may exceed system RAM)
self.imgs = [None] * n
if cache_images:
gb = 0 # Gigabytes of cached images
self.img_hw0, self.img_hw = [None] * n, [None] * n
results = ThreadPool(num_threads).imap(lambda x: load_image(*x), zip(repeat(self), range(n)))
pbar = tqdm(enumerate(results), total=n)
for i, x in pbar:
self.imgs[i], self.img_hw0[i], self.img_hw[i] = x # img, hw_original, hw_resized = load_image(self, i)
gb += self.imgs[i].nbytes
pbar.desc = f'{
prefix}Caching images ({
gb / 1E9:.1f}GB)'
pbar.close()
4.2、cache_labels
\qquad 这个函数用于加载文件路径中的label信息生成cache文件。cache文件中包括的信息有:im_file, l, shape, segments, hash, results, msgs, version等,具体看代码注释。
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
"""用在__init__函数中 cache数据集label
加载label信息生成cache文件 Cache dataset labels, check images and read shapes
:params path: cache文件保存地址
:params prefix: 日志头部信息(彩打高亮部分)
:return x: cache中保存的字典
包括的信息有: x[im_file] = [l, shape, segments]
一张图片一个label相对应的保存到x, 最终x会保存所有图片的相对路径、gt框的信息、形状shape、所有的多边形gt信息
im_file: 当前这张图片的path相对路径
l: 当前这张图片的所有gt框的label信息(不包含segment多边形标签) [gt_num, cls+xywh(normalized)]
shape: 当前这张图片的形状 shape
segments: 当前这张图片所有gt的label信息(包含segment多边形标签) [gt_num, xy1...]
hash: 当前图片和label文件的hash值 1
results: 找到的label个数nf, 丢失label个数nm, 空label个数ne, 破损label个数nc, 总img/label个数len(self.img_files)
msgs: 所有数据集的msgs信息
version: 当前cache version
"""
x = {
} # 初始化最终cache中保存的字典dict
# 初始化number missing, found, empty, corrupt, messages
# 初始化整个数据集: 漏掉的标签(label)总数量, 找到的标签(label)总数量, 空的标签(label)总数量, 错误标签(label)总数量, 所有错误信息
nm, nf, ne, nc, msgs = 0, 0, 0, 0, []
desc = f"{
prefix}Scanning '{
path.parent / path.stem}' images and labels..." # 日志
# 多进程调用verify_image_label函数
with Pool(num_threads) as pool:
# 定义pbar进度条
# pool.imap_unordered: 对大量数据遍历多进程计算 返回一个迭代器
# 把self.img_files, self.label_files, repeat(prefix) list中的值作为参数依次送入(一次送一个)verify_image_label函数
pbar = tqdm(pool.imap_unordered(verify_image_label, zip(self.img_files, self.label_files, repeat(prefix))),
desc=desc, total=len(self.img_files))
# im_file: 当前这张图片的path相对路径
# l: [gt_num, cls+xywh(normalized)]
# 如果这张图片没有一个segment多边形标签 l就存储原label(全部是正常矩形标签)
# 如果这张图片有一个segment多边形标签 l就存储经过segments2boxes处理好的标签(正常矩形标签不处理 多边形标签转化为矩形标签)
# shape: 当前这张图片的形状 shape
# segments: 如果这张图片没有一个segment多边形标签 存储None
# 如果这张图片有一个segment多边形标签 就把这张图片的所有label存储到segments中(若干个正常gt 若干个多边形标签) [gt_num, xy1...]
# nm_f(nm): number missing 当前这张图片的label是否丢失 丢失=1 存在=0
# nf_f(nf): number found 当前这张图片的label是否存在 存在=1 丢失=0
# ne_f(ne): number empty 当前这张图片的label是否是空的 空的=1 没空=0
# nc_f(nc): number corrupt 当前这张图片的label文件是否是破损的 破损的=1 没破损=0
# msg: 返回的msg信息 label文件完好=‘’ label文件破损=warning信息
for im_file, l, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f # 累加总number missing label
nf += nf_f # 累加总number found label
ne += ne_f # 累加总number empty label
nc += nc_f # 累加总number corrupt label
if im_file:
x[im_file] = [l, shape, segments] # 信息存入字典 key=im_file value=[l, shape, segments]
if msg:
msgs.append(msg) # 将msg加入总msg
pbar.desc = f"{
desc}{
nf} found, {
nm} missing, {
ne} empty, {
nc} corrupted" # 日志
pbar.close() # 关闭进度条
# 日志打印所有msg信息
if msgs:
logging.info('\n'.join(msgs))
# 一张label都没找到 日志打印help_url下载地址
if nf == 0:
logging.info(f'{
prefix}WARNING: No labels found in {
path}. See {
help_url}')
x['hash'] = get_hash(self.label_files + self.img_files) # 将当前图片和label文件的hash值存入最终字典dist
x['results'] = nf, nm, ne, nc, len(self.img_files) # 将nf, nm, ne, nc, len(self.img_files)存入最终字典dist
x['msgs'] = msgs # 将所有数据集的msgs信息存入最终字典dist
x['version'] = 0.3 # 将当前cache version存入最终字典dist
try:
torch.save(x, path) # save cache to path
logging.info(f'{
prefix}New cache created: {
path}')
except Exception as e:
logging.info(f'{
prefix}WARNING: Cache directory {
path.parent} is not writeable: {
e}') # path not writeable
return x
4.3、len
\qquad 这个函数是求数据集图片的数量。
def __len__(self):
return len(self.img_files)
4.4.、getitem
\qquad 这部分是数据增强函数,一般一次性执行batch_size次。
def __getitem__(self, index):
"""
这部分是数据增强函数,一般一次性执行batch_size次。
训练 数据增强: mosaic(random_perspective) + hsv + 上下左右翻转
测试 数据增强: letterbox
:return torch.from_numpy(img): 这个index的图片数据(增强后) [3, 640, 640]
:return labels_out: 这个index图片的gt label [6, 6] = [gt_num, 0+class+xywh(normalized)]
:return self.img_files[index]: 这个index图片的路径地址
:return shapes: 这个batch的图片的shapes 测试时(矩形训练)才有 验证时为None for COCO mAP rescaling
"""
# 这里可以通过三种形式获取要进行数据增强的图片index linear, shuffled, or image_weights
index = self.indices[index]
hyp = self.hyp # 超参 包含众多数据增强超参
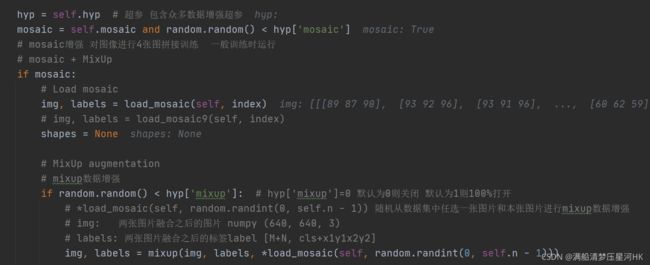
mosaic = self.mosaic and random.random() < hyp['mosaic']
# mosaic增强 对图像进行4张图拼接训练 一般训练时运行
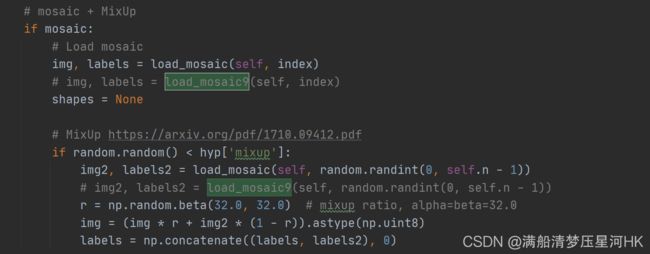
# mosaic + MixUp
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index)
# img, labels = load_mosaic9(self, index)
shapes = None
# MixUp augmentation
# mixup数据增强
if random.random() < hyp['mixup']: # hyp['mixup']=0 默认为0则关闭 默认为1则100%打开
# *load_mosaic(self, random.randint(0, self.n - 1)) 随机从数据集中任选一张图片和本张图片进行mixup数据增强
# img: 两张图片融合之后的图片 numpy (640, 640, 3)
# labels: 两张图片融合之后的标签label [M+N, cls+x1y1x2y2]
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
# 测试代码 测试MixUp效果
# cv2.imshow("MixUp", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
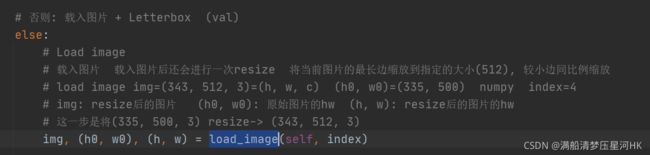
# 否则: 载入图片 + Letterbox (val)
else:
# Load image
# 载入图片 载入图片后还会进行一次resize 将当前图片的最长边缩放到指定的大小(512), 较小边同比例缩放
# load image img=(343, 512, 3)=(h, w, c) (h0, w0)=(335, 500) numpy index=4
# img: resize后的图片 (h0, w0): 原始图片的hw (h, w): resize后的图片的hw
# 这一步是将(335, 500, 3) resize-> (343, 512, 3)
img, (h0, w0), (h, w) = load_image(self, index)
# 测试代码 测试load_image效果
# cv2.imshow("load_image", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
# Letterbox
# letterbox之前确定这张当前图片letterbox之后的shape 如果不用self.rect矩形训练shape就是self.img_size
# 如果使用self.rect矩形训练shape就是当前batch的shape 因为矩形训练的话我们整个batch的shape必须统一(在__init__函数第6节内容)
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
# letterbox 这一步将第一步缩放得到的图片再缩放到当前batch所需要的尺度 (343, 512, 3) pad-> (384, 512, 3)
# (矩形推理需要一个batch的所有图片的shape必须相同,而这个shape在init函数中保持在self.batch_shapes中)
# 这里没有缩放操作,所以这里的ratio永远都是(1.0, 1.0) pad=(0.0, 20.5)
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
# 图片letterbox之后label的坐标也要相应变化 根据pad调整label坐标 并将归一化的xywh -> 未归一化的xyxy
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
# 测试代码 测试letterbox效果
# cv2.imshow("letterbox", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
if self.augment:
# Augment imagespace
if not mosaic:
# 不做mosaic的话就要做random_perspective增强 因为mosaic函数内部执行了random_perspective增强
# random_perspective增强: 随机对图片进行旋转,平移,缩放,裁剪,透视变换
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
# 色域空间增强Augment colorspace
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# 测试代码 测试augment_hsv效果
# cv2.imshow("augment_hsv", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
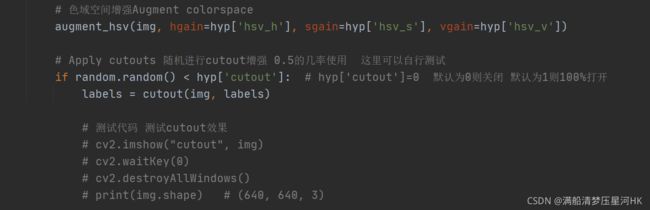
# Apply cutouts 随机进行cutout增强 0.5的几率使用 这里可以自行测试
if random.random() < hyp['cutout']: # hyp['cutout']=0 默认为0则关闭 默认为1则100%打开
labels = cutout(img, labels)
# 测试代码 测试cutout效果
# cv2.imshow("cutout", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
nL = len(labels) # number of labels
if nL:
# xyxy to xywh normalized
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0])
# 平移增强 随机左右翻转 + 随机上下翻转
if self.augment:
# 随机上下翻转 flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img) # np.flipud 将数组在上下方向翻转。
if nL:
labels[:, 2] = 1 - labels[:, 2] # 1 - y_center label也要映射
# 随机左右翻转 flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img) # np.fliplr 将数组在左右方向翻转
if nL:
labels[:, 1] = 1 - labels[:, 1] # 1 - x_center label也要映射
# 6个值的tensor 初始化标签框对应的图片序号, 配合下面的collate_fn使用
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels) # numpy to tensor
# Convert BGR->RGB HWC->CHW
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3 x img_height x img_width
img = np.ascontiguousarray(img) # img变成内存连续的数据 加快运算
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
4.5、collate_fn
\qquad 很多人以为写完 init 和 getitem 函数数据增强就做完了,我们在分类任务中的确写完这两个函数就可以了,因为系统中是给我们写好了一个collate_fn函数的,但是在目标检测中我们却需要重写collate_fn函数,下面我会仔细的讲解这样做的原因(代码中注释)。
这个函数会在create_dataloader中生成dataloader时调用:

@staticmethod
def collate_fn(batch):
"""这个函数会在create_dataloader中生成dataloader时调用:
整理函数 将image和label整合到一起
:return torch.stack(img, 0): 如[16, 3, 640, 640] 整个batch的图片
:return torch.cat(label, 0): 如[15, 6] [num_target, img_index+class_index+xywh(normalized)] 整个batch的label
:return path: 整个batch所有图片的路径
:return shapes: (h0, w0), ((h / h0, w / w0), pad) for COCO mAP rescaling
pytorch的DataLoader打包一个batch的数据集时要经过此函数进行打包 通过重写此函数实现标签与图片对应的划分,一个batch中哪些标签属于哪一张图片,形如
[[0, 6, 0.5, 0.5, 0.26, 0.35],
[0, 6, 0.5, 0.5, 0.26, 0.35],
[1, 6, 0.5, 0.5, 0.26, 0.35],
[2, 6, 0.5, 0.5, 0.26, 0.35],]
前两行标签属于第一张图片, 第三行属于第二张。。。
"""
# img: 一个tuple 由batch_size个tensor组成 整个batch中每个tensor表示一张图片
# label: 一个tuple 由batch_size个tensor组成 每个tensor存放一张图片的所有的target信息
# label[6, object_num] 6中的第一个数代表一个batch中的第几张图
# path: 一个tuple 由4个str组成, 每个str对应一张图片的地址信息
img, label, path, shapes = zip(*batch) # transposed
for i, l in enumerate(label):
l[:, 0] = i # add target image index for build_targets()
# 返回的img=[batch_size, 3, 736, 736]
# torch.stack(img, 0): 将batch_size个[3, 736, 736]的矩阵拼成一个[batch_size, 3, 736, 736]
# label=[target_sums, 6] 6:表示当前target属于哪一张图+class+x+y+w+h
# torch.cat(label, 0): 将[n1,6]、[n2,6]、[n3,6]...拼接成[n1+n2+n3+..., 6]
# 这里之所以拼接的方式不同是因为img拼接的时候它的每个部分的形状是相同的,都是[3, 736, 736]
# 而我label的每个部分的形状是不一定相同的,每张图的目标个数是不一定相同的(label肯定也希望用stack,更方便,但是不能那样拼)
# 如果每张图的目标个数是相同的,那我们就可能不需要重写collate_fn函数了
return torch.stack(img, 0), torch.cat(label, 0), path, shapes
注意:这个函数一般是当调用了batch_size次 getitem 函数后才会调用一次这个函数,对batch_size张图片和对应的label进行打包。 强烈建议这里大家debug试试这里return的数据是不是我说的这样定义的。
4.6、collate_fn4
\qquad 这里是yolo-v5作者实验性的一个代码 quad-collate function 当train.py的opt参数quad=True 则调用collate_fn4代替collate_fn。 作用:将4张mosaic图片[1, 3, 640, 640]合成一张大的mosaic图片[1, 3, 1280, 1280]。将一个batch的图片每四张处理, 0.5的概率将四张图片拼接到一张大图上训练, 0.5概率直接将某张图片上采样两倍训练。
同样在create_dataloader中生成dataloader时调用:
@staticmethod
def collate_fn4(batch):
"""同样在create_dataloader中生成dataloader时调用:
这里是yolo-v5作者实验性的一个代码 quad-collate function 当train.py的opt参数quad=True 则调用collate_fn4代替collate_fn
作用: 如之前用collate_fn可以返回图片[16, 3, 640, 640] 经过collate_fn4则返回图片[4, 3, 1280, 1280]
将4张mosaic图片[1, 3, 640, 640]合成一张大的mosaic图片[1, 3, 1280, 1280]
将一个batch的图片每四张处理, 0.5的概率将四张图片拼接到一张大图上训练, 0.5概率直接将某张图片上采样两倍训练
"""
# img: 整个batch的图片 [16, 3, 640, 640]
# label: 整个batch的label标签 [num_target, img_index+class_index+xywh(normalized)]
# path: 整个batch所有图片的路径
# shapes: (h0, w0), ((h / h0, w / w0), pad) for COCO mAP rescaling
img, label, path, shapes = zip(*batch) # transposed
n = len(shapes) // 4 # collate_fn4处理后这个batch中图片的个数
img4, label4, path4, shapes4 = [], [], path[:n], shapes[:n] # 初始化
ho = torch.tensor([[0., 0, 0, 1, 0, 0]])
wo = torch.tensor([[0., 0, 1, 0, 0, 0]])
s = torch.tensor([[1, 1, .5, .5, .5, .5]]) # scale
for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
i *= 4 # 采样 [0, 4, 8, 16]
if random.random() < 0.5:
# 随机数小于0.5就直接将某张图片上采样两倍训练
im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2., mode='bilinear', align_corners=False)[
0].type(img[i].type())
l = label[i]
else:
# 随机数大于0.5就将四张图片(mosaic后的)拼接到一张大图上训练
im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
l = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
img4.append(im)
label4.append(l)
# 后面返回的部分和collate_fn就差不多了 原因和解释都写在上一个函数了 自己debug看一下吧
for i, l in enumerate(label4):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img4, 0), torch.cat(label4, 0), path4, shapes4
5、img2label_paths
\qquad 这个文件是根据数据集中所有图片的路径找到数据集中所有labels对应的路径。用在LoadImagesAndLabels模块的__init__函数中。
def img2label_paths(img_paths):
"""用在LoadImagesAndLabels模块的__init__函数中
根据imgs图片的路径找到对应labels的路径
Define label paths as a function of image paths
:params img_paths: {list: 50} 整个数据集的图片相对路径 例如: '..\\datasets\\VOC\\images\\train2007\\000012.jpg'
=> '..\\datasets\\VOC\\labels\\train2007\\000012.jpg'
"""
# 因为python是跨平台的,在Windows上,文件的路径分隔符是'\',在Linux上是'/'
# 为了让代码在不同的平台上都能运行,那么路径应该写'\'还是'/'呢? os.sep根据你所处的平台, 自动采用相应的分隔符号
# sa: '\\images\\' sb: '\\labels\\'
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
# 把img_paths中所以图片路径中的images替换为labels
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
6、verify_image_label
\qquad 这个函数用于检查每一张图片和每一张label文件是否完好。
\qquad 图片文件: 检查内容、格式、大小、完整性
\qquad label文件: 检查每个gt必须是矩形(每行都得是5个数 class+xywh) + 标签是否全部>=0 + 标签坐标xywh是否归一化 + 标签中是否有重复的坐标
verify_image_label函数代码:
def verify_image_label(args):
"""用在cache_labels函数中
检测数据集中每张图片和每张laebl是否完好
图片文件: 内容、格式、大小、完整性
label文件: 每个gt必须是矩形(每行都得是5个数 class+xywh) + 标签是否全部>=0 + 标签坐标xywh是否归一化 + 标签中是否有重复的坐标
:params im_file: 数据集中一张图片的path相对路径
:params lb_file: 数据集中一张图片的label相对路径
:params prefix: 日志头部信息(彩打高亮部分)
:return im_file: 当前这张图片的path相对路径
:return l: [gt_num, cls+xywh(normalized)]
如果这张图片没有一个segment多边形标签 l就存储原label(全部是正常矩形标签)
如果这张图片有一个segment多边形标签 l就存储经过segments2boxes处理好的标签(正常矩形标签不处理 多边形标签转化为矩形标签)
:return shape: 当前这张图片的形状 shape
:return segments: 如果这张图片没有一个segment多边形标签 存储None
如果这张图片有一个segment多边形标签 就把这张图片的所有label存储到segments中(若干个正常gt 若干个多边形标签) [gt_num, xy1...]
:return nm: number missing 当前这张图片的label是否丢失 丢失=1 存在=0
:return nf: number found 当前这张图片的label是否存在 存在=1 丢失=0
:return ne: number empty 当前这张图片的label是否是空的 空的=1 没空=0
:return nc: number corrupt 当前这张图片的label文件是否是破损的 破损的=1 没破损=0
:return msg: 返回的msg信息 label文件完好=‘’ label文件破损=warning信息
"""
im_file, lb_file, prefix = args
nm, nf, ne, nc = 0, 0, 0, 0 # number missing, found, empty, corrupt label
try:
# 检查这张图片(内容、格式、大小、完整性) verify images
im = Image.open(im_file) # 打开图片文件
im.verify() # PIL verify 检查图片内容和格式是否正常
shape = exif_size(im) # 当前图片的大小 image size
assert (shape[0] > 9) & (shape[1] > 9), f'image size {
shape} <10 pixels' # 图片大小必须大于9个pixels
assert im.format.lower() in img_formats, f'invalid image format {
im.format}' # 图片格式必须在img_format中
if im.format.lower() in ('jpg', 'jpeg'): # 检查jpg格式文件
with open(im_file, 'rb') as f:
# f.seek: -2 偏移量 向文件头方向中移动的字节数 2 相对位置 从文件尾开始偏移
f.seek(-2, 2)
# f.read(): 读取图片文件 指令: \xff\xd9 检测整张图片是否完整 如果不完整就返回corrupted JPEG
assert f.read() == b'\xff\xd9', 'corrupted JPEG'
# verify labels
segments = [] # 存放这张图所有gt框的信息(包含segments多边形: label某一列数大于8)
if os.path.isfile(lb_file): # 如果这个label路径存在
nf = 1 # label found
with open(lb_file, 'r') as f: # 读取label文件
# 读取当前label文件的每一行: 每一行都是当前图片的一个gt
l = [x.split() for x in f.read().strip().splitlines() if len(x)]
# any() 函数用于判断给定的可迭代参数 是否全部为False,则返回 False; 如果有一个为 True,则返回True
# 如果当前图片的label文件某一列数大于8, 则认为label是存在segment的polygon点(多边形) 就不是矩阵 则将label信息存入segment中
if any([len(x) > 8 for x in l]): # is segment
# 当前图片中所有gt框的类别
classes = np.array([x[0] for x in l], dtype=np.float32)
# 获得这张图中所有gt框的label信息(包含segment多边形标签)
# 因为segment标签可以是不同长度,所以这里segments是一个列表 [gt_num, xy1...(normalized)]
segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in l]
# 获得这张图中所有gt框的label信息(不包含segment多边形标签)
# segments(多边形) -> bbox(正方形), 得到新标签 [gt_num, cls+xywh(normalized)]
l = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1)
l = np.array(l, dtype=np.float32) # l: to float32
if len(l):
# 判断标签是否有五列
assert l.shape[1] == 5, 'labels require 5 columns each'
# 判断标签是否全部>=0
assert (l >= 0).all(), 'negative labels'
# 判断标签坐标x y w h是否归一化
assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels'
# 判断标签中是否有重复的坐标
assert np.unique(l, axis=0).shape[0] == l.shape[0], 'duplicate labels'
else:
ne = 1 # label empty l.shape[0] == 0则为空的标签,ne=1
l = np.zeros((0, 5), dtype=np.float32)
else:
nm = 1 # label missing 不存在标签文件,则nm = 1
l = np.zeros((0, 5), dtype=np.float32)
return im_file, l, shape, segments, nm, nf, ne, nc, ''
except Exception as e:
nc = 1
msg = f'{
prefix}WARNING: Ignoring corrupted image and/or label {
im_file}: {
e}'
return [None, None, None, None, nm, nf, ne, nc, msg]
7、load_image
\qquad 这个函数是根据图片index,从self或者从对应图片路径中载入对应index的图片 并将原图中hw中较大者扩展到self.img_size, 较小者同比例扩展。会被用在LoadImagesAndLabels模块的__getitem__函数和load_mosaic模块中载入对应index的图片:
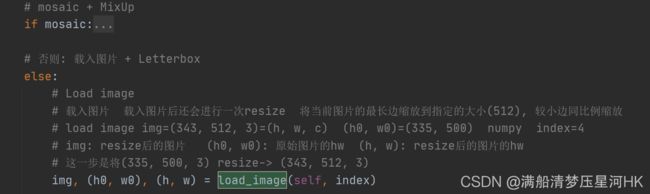
load_image函数代码:
def load_image(self, index):
"""用在LoadImagesAndLabels模块的__getitem__函数和load_mosaic模块中
从self或者从对应图片路径中载入对应index的图片 并将原图中hw中较大者扩展到self.img_size, 较小者同比例扩展
loads 1 image from dataset, returns img, original hw, resized hw
:params self: 一般是导入LoadImagesAndLabels中的self
:param index: 当前图片的index
:return: img: resize后的图片
(h0, w0): hw_original 原图的hw
img.shape[:2]: hw_resized resize后的图片hw(hw中较大者扩展到self.img_size, 较小者同比例扩展)
"""
# 按index从self.imgs中载入当前图片, 但是由于缓存的内容一般会不够, 所以我们一般不会用self.imgs(cache)保存所有的图片
img = self.imgs[index]
# 图片是空的话, 就从对应文件路径读出这张图片
if img is None: # not cached 一般都不会使用cache缓存到self.imgs中
path = self.img_files[index] # 图片路径
img = cv2.imread(path) # 读出BGR图片 (335, 500, 3) HWC
assert img is not None, 'Image Not Found ' + path
h0, w0 = img.shape[:2] # orig img hw
# img_size 设置的是预处理后输出的图片尺寸 r=缩放比例
r = self.img_size / max(h0, w0) # ratio aspect
if r != 1: # if sizes are not equal
# cv2.INTER_AREA: 基于区域像素关系的一种重采样或者插值方式.该方法是图像抽取的首选方法, 它可以产生更少的波纹
# cv2.INTER_LINEAR: 双线性插值,默认情况下使用该方式进行插值 根据ratio选择不同的插值方式
# 将原图中hw中较大者扩展到self.img_size, 较小者同比例扩展
img = cv2.resize(img, (int(w0 * r), int(h0 * r)),
interpolation=cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR)
return img, (h0, w0), img.shape[:2] # img, hw_original, hw_resized
else:
return self.imgs[index], self.img_hw0[index], self.img_hw[index] # img, hw_original, hw_resized
用在LoadImagesAndLabels模块的__getitem__函数和load_mosaic模块中:
执行效果:

8、augment_hsv
\qquad 这个函数是关于图片的色域增强模块,图片并不发生移动,所有不需要改变label,只需要 img 增强即可。
augment_hsv模块代码:
def augment_hsv(img, hgain=0.5, sgain=0.5, vgain=0.5):
"""用在LoadImagesAndLabels模块的__getitem__函数
hsv色域增强 处理图像hsv,不对label进行任何处理
:param img: 待处理图片 BGR [736, 736]
:param hgain: h通道色域参数 用于生成新的h通道
:param sgain: h通道色域参数 用于生成新的s通道
:param vgain: h通道色域参数 用于生成新的v通道
:return: 返回hsv增强后的图片 img
"""
if hgain or sgain or vgain:
# 随机取-1到1三个实数,乘以hyp中的hsv三通道的系数 用于生成新的hsv通道
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV)) # 图像的通道拆分 h s v
dtype = img.dtype # uint8
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype) # 生成新的h通道
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype) # 生成新的s通道
lut_val = np.clip(x * r[2], 0, 255).astype(dtype) # 生成新的v通道
# 图像的通道合并 img_hsv=h+s+v 随机调整hsv之后重新组合hsv通道
# cv2.LUT(hue, lut_hue) 通道色域变换 输入变换前通道hue 和变换后通道lut_hue
img_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
# no return needed dst:输出图像
cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed hsv->bgr
\qquad 还要注意的是这个hsv增强是随机生成各个色域参数的,所以每次增强的效果都是不同的:
第一次:变亮
第二次:变暗
这个函数用在LoadImagesAndLabels模块的__getitem__函数中:

另外,这里涉及到的三个变量来自hyp.yaml超参文件:

9、load_mosaic、load_mosaic9
\qquad 这两个函数都是mosaic数据增强,只不过load_mosaic函数是拼接四张图,而load_mosaic9函数是拼接九张图。
9.1、load_mosaic
\qquad 这个模块就是很有名的mosaic增强模块,几乎训练的时候都会用它,可以显著的提高小样本的mAP。代码是数据增强里面最难的, 也是最有价值的,mosaic是非常非常有用的数据增强trick, 一定要熟练掌握。
load_mosaic模块代码:
def load_mosaic(self, index):
"""用在LoadImagesAndLabels模块的__getitem__函数 进行mosaic数据增强
将四张图片拼接在一张马赛克图像中 loads images in a 4-mosaic
:param index: 需要获取的图像索引
:return: img4: mosaic和随机透视变换后的一张图片 numpy(640, 640, 3)
labels4: img4对应的target [M, cls+x1y1x2y2]
"""
# labels4: 用于存放拼接图像(4张图拼成一张)的label信息(不包含segments多边形)
# segments4: 用于存放拼接图像(4张图拼成一张)的label信息(包含segments多边形)
labels4, segments4 = [], []
s = self.img_size # 一般的图片大小
# 随机初始化拼接图像的中心点坐标 [0, s*2]之间随机取2个数作为拼接图像的中心坐标
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y
# 从dataset中随机寻找额外的三张图像进行拼接 [14, 26, 2, 16] 再随机选三张图片的index
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
# 遍历四张图像进行拼接 4张不同大小的图像 => 1张[1472, 1472, 3]的图像
for i, index in enumerate(indices):
# load image 每次拿一张图片 并将这张图片resize到self.size(h,w)
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left 原图[375, 500, 3] load_image->[552, 736, 3] hwc
# 创建马赛克图像 [1472, 1472, 3]=[h, w, c]
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中) w=736 h = 552 马赛克图像:(x1a,y1a)左上角 (x2a,y2a)右下角
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# 计算截取的图像区域信息(以xc,yc为第一张图像的右下角坐标填充到马赛克图像中,丢弃越界的区域) 图像:(x1b,y1b)左上角 (x2b,y2b)右下角
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
# 计算截取的图像区域信息(以xc,yc为第二张图像的左下角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
# 计算截取的图像区域信息(以xc,yc为第三张图像的右上角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
# 计算截取的图像区域信息(以xc,yc为第四张图像的左上角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
# 将截取的图像区域填充到马赛克图像的相应位置 img4[h, w, c]
# 将图像img的【(x1b,y1b)左上角 (x2b,y2b)右下角】区域截取出来填充到马赛克图像的【(x1a,y1a)左上角 (x2a,y2a)右下角】区域
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# 计算pad(当前图像边界与马赛克边界的距离,越界的情况padw/padh为负值) 用于后面的label映射
padw = x1a - x1b # 当前图像与马赛克图像在w维度上相差多少
padh = y1a - y1b # 当前图像与马赛克图像在h维度上相差多少
# labels: 获取对应拼接图像的所有正常label信息(如果有segments多边形会被转化为矩形label)
# segments: 获取对应拼接图像的所有不正常label信息(包含segments多边形也包含正常gt)
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
# normalized xywh normalized to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh)
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels) # 更新labels4
segments4.extend(segments) # 更新segments4
# Concat/clip labels4 把labels4([(2, 5), (1, 5), (3, 5), (1, 5)] => (7, 5))压缩到一起
labels4 = np.concatenate(labels4, 0)
# 防止越界 label[:, 1:]中的所有元素的值(位置信息)必须在[0, 2*s]之间,小于0就令其等于0,大于2*s就等于2*s out: 返回
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# 测试代码 测试前面的mosaic效果
# cv2.imshow("mosaic", img4)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img4.shape) # (1280, 1280, 3)
# 随机偏移标签中心,生成新的标签与原标签结合 replicate
# img4, labels4 = replicate(img4, labels4)
#
# # 测试代码 测试replicate效果
# cv2.imshow("replicate", img4)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img4.shape) # (1280, 1280, 3)
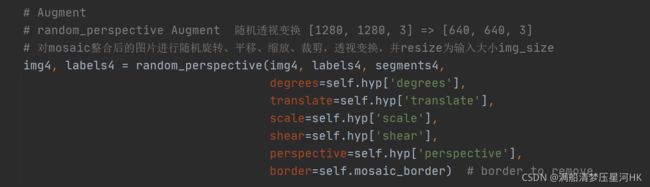
# Augment
# random_perspective Augment 随机透视变换 [1280, 1280, 3] => [640, 640, 3]
# 对mosaic整合后的图片进行随机旋转、平移、缩放、裁剪,透视变换,并resize为输入大小img_size
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
# 测试代码 测试mosaic + random_perspective随机仿射变换效果
# cv2.imshow("random_perspective", img4)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img4.shape) # (640, 640, 3)
return img4, labels4
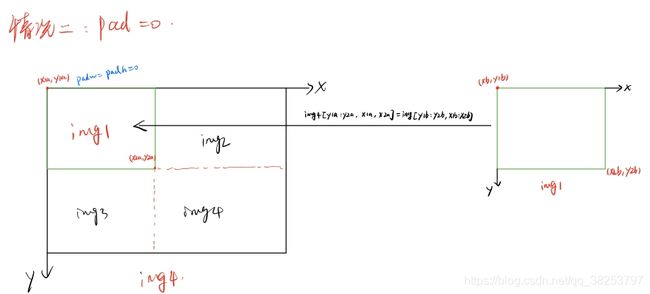
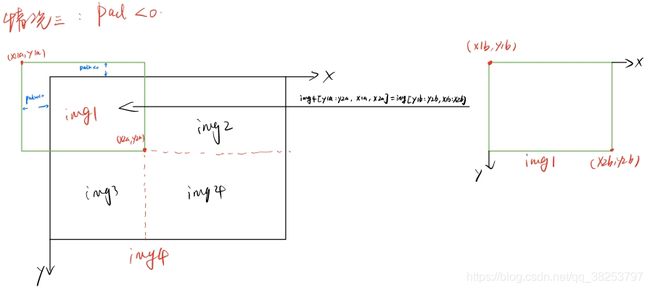
mosaic算法步骤:
1、在 [img_size x 0.5 : img_size x 1.5] 之间随机选择一个拼接中心的坐标(xc, yc)。需要注意的是这里的img_size是我们需要的图片的大小, 而mosaic初步增强得到的图片的shape应该是2倍的img_size.
2、从 [0, len(label)-1] 之间随机选择3张图片的index, 与传入的图片index共同组成4张照片的集合indices.
-------------------------------------------------------------开始剪切img4---------------------------------------------------------------------
3、for 4张图片:
3.0)、如果是第一张图片,就初始化mosaic图片img4
3.1)、 得到mosaic图片的坐标信息(这个坐标区域是用来填充图像的):左上角(x1a, y1a), (x2a, y2a)右下角
3.2)、得到截取的图像区域的坐标信息:(x1b,y1b)左上角 (x2b,y2b)右下角
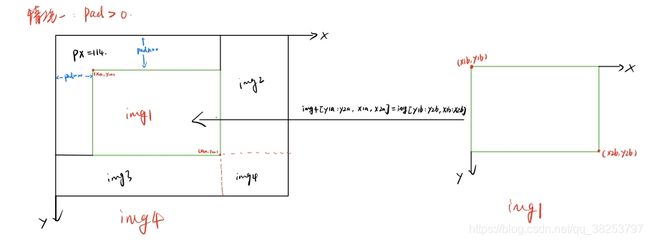
3.3)、将图像img的【(x1b,y1b)左上角 (x2b,y2b)右下角】区域截取出来填充到马赛克图像的【(x1a,y1a)左上角 (x2a,y2a)右下角】 注:这里的填充有三种可能的情况,后面会仔细的讨论。
3.4)、计算当前图像边界与马赛克边界的距离,用于后面的label映射
3.5)、拼接4张图像的labels信息为一张labels4
--------------------------------------------到这里就得到了img4[2 x img_size, 2 x img_size, 3]--------------------------------------
4、Concat labels4
5、clip labels4, 防止越界
-------------------------------------------到这里又得到了labels4(相对img4的)---------------------------------------------------------
6、random_perspective随机透视变换(random_perspective Augment),将img4[2 x img_size, 2 x img_size, 3]=>img4 [img_size, img_size, 3]. 这里我就不仔细的介绍随机透视变换了,下一节会详细介绍的。
--------------------------------------------------到这里就得到了img4[img_size, img_size, 3]--------------------------------------------
7、最后retrun img4[img_size, img_size, 3] 和 labels4(相对img4的)
4张图片进行拼接的时候,通常会出现如下三种情况:
效果显示1:mosaic
shape = (1280, 1280, 3)
效果显示2:mosaic + random_perspective
shape = (640, 640, 3)
9.2、load_mosaic9
\qquad 这个模块是作者的实验模块,将九张图片拼接在一张马赛克图像中。总体代码流程和load_mosaic4几乎一样,看懂了load_mosaic4再看这个就很简单了、
load_mosaic9模块代码:
def load_mosaic9(self, index):
"""用在LoadImagesAndLabels模块的__getitem__函数 替换mosaic数据增强
将九张图片拼接在一张马赛克图像中 loads images in a 9-mosaic
:param self:
:param index: 需要获取的图像索引
:return: img9: mosaic和仿射增强后的一张图片
labels9: img9对应的target
"""
# labels9: 用于存放拼接图像(9张图拼成一张)的label信息(不包含segments多边形)
# segments9: 用于存放拼接图像(9张图拼成一张)的label信息(包含segments多边形)
labels9, segments9 = [], []
s = self.img_size # 一般的图片大小(也是最终输出的图片大小)
# 从dataset中随机寻找额外的三张图像进行拼接 [14, 26, 2, 16] 再随机选三张图片的index
indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
for i, index in enumerate(indices):
# Load image 每次拿一张图片 并将这张图片resize到self.size(h,w)
img, _, (h, w) = load_image(self, index)
# 这里和上面load_mosaic函数的操作类似 就是将取出的img图片嵌到img9中(不是真的嵌入 而是找到对应的位置)
# place img in img9
if i == 0: # center
img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
h0, w0 = h, w
c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
elif i == 1: # top
c = s, s - h, s + w, s
elif i == 2: # top right
c = s + wp, s - h, s + wp + w, s
elif i == 3: # right
c = s + w0, s, s + w0 + w, s + h
elif i == 4: # bottom right
c = s + w0, s + hp, s + w0 + w, s + hp + h
elif i == 5: # bottom
c = s + w0 - w, s + h0, s + w0, s + h0 + h
elif i == 6: # bottom left
c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
elif i == 7: # left
c = s - w, s + h0 - h, s, s + h0
elif i == 8: # top left
c = s - w, s + h0 - hp - h, s, s + h0 - hp
padx, pady = c[:2]
x1, y1, x2, y2 = [max(x, 0) for x in c] # allocate coords
# 和上面load_mosaic函数的操作类似 找到mosaic9增强后的labels9和segments9
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
labels9.append(labels)
segments9.extend(segments)
# 生成对应的img9图片(将对应位置的图片嵌入img9中)
img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
hp, wp = h, w # height, width previous
# Offset
yc, xc = [int(random.uniform(0, s)) for _ in self.mosaic_border] # mosaic center x, y
img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
# Concat/clip labels
labels9 = np.concatenate(labels9, 0)
labels9[:, [1, 3]] -= xc
labels9[:, [2, 4]] -= yc
c = np.array([xc, yc]) # centers
segments9 = [x - c for x in segments9]
for x in (labels9[:, 1:], *segments9):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment 同样进行 随机透视变换
img9, labels9 = random_perspective(img9, labels9, segments9,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img9, labels9
用法和mosaic一样,直接替换即可:
感兴趣的朋友可以试试,不过用的好像并不是很多,效果没mosaic好。
10、random_perspective
\qquad 这个函数是进行随机透视变换,对mosaic整合后的图片进行随机旋转、缩放、平移、裁剪,透视变换,并resize为输入大小img_size。
random_perspective函数代码:
def random_perspective(img, targets=(), segments=(), degrees=10, translate=.1,
scale=.1, shear=10, perspective=0.0, border=(0, 0)):
"""这个函数会用于load_mosaic中用在mosaic操作之后
随机透视变换 对mosaic整合后的图片进行随机旋转、缩放、平移、裁剪,透视变换,并resize为输入大小img_size
:params img: mosaic整合后的图片img4 [2*img_size, 2*img_size]
如果mosaic后的图片没有一个多边形标签就使用targets, segments为空 如果有一个多边形标签就使用segments, targets不为空
:params targets: mosaic整合后图片的所有正常label标签labels4(不正常的会通过segments2boxes将多边形标签转化为正常标签) [N, cls+xyxy]
:params segments: mosaic整合后图片的所有不正常label信息(包含segments多边形也包含正常gt) [m, x1y1....]
:params degrees: 旋转和缩放矩阵参数
:params translate: 平移矩阵参数
:params scale: 缩放矩阵参数
:params shear: 剪切矩阵参数
:params perspective: 透视变换参数
:params border: 用于确定最后输出的图片大小 一般等于[-img_size, -img_size] 那么最后输出的图片大小为 [img_size, img_size]
:return img: 通过透视变换/仿射变换后的img [img_size, img_size]
:return targets: 通过透视变换/仿射变换后的img对应的标签 [n, cls+x1y1x2y2] (通过筛选后的)
"""
# 设定输出图片的 H W
# border=-s // 2 所以最后图片的大小直接减半 [img_size, img_size, 3]
height = img.shape[0] + border[0] * 2 # # 最终输出图像的H
width = img.shape[1] + border[1] * 2 # 最终输出图像的W
# ============================ 开始变换 =============================
# 需要注意的是,其实opencv是实现了仿射变换的, 不过我们要先生成仿射变换矩阵M
# Center 设置中心平移矩阵
C = np.eye(3)
C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
# Perspective 设置透视变换矩阵
P = np.eye(3)
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
# Rotation and Scale 设置旋转和缩放矩阵
R = np.eye(3) # 初始化R = [[1,0,0], [0,1,0], [0,0,1]] (3, 3)
# a: 随机生成旋转角度 范围在(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
a = random.uniform(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
# s: 随机生成旋转后图像的缩放比例 范围在(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
s = random.uniform(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
# cv2.getRotationMatrix2D: 二维旋转缩放函数
# 参数 angle:旋转角度 center: 旋转中心(默认就是图像的中心) scale: 旋转后图像的缩放比例
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear 设置剪切矩阵
S = np.eye(3) # 初始化T = [[1,0,0], [0,1,0], [0,0,1]]
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Translation 设置平移矩阵
T = np.eye(3) # 初始化T = [[1,0,0], [0,1,0], [0,0,1]] (3, 3)
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
# Combined rotation matrix @ 表示矩阵乘法 生成仿射变换矩阵M
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
# 将仿射变换矩阵M作用在图片上
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if perspective:
# 透视变换函数 实现旋转平移缩放变换后的平行线不再平行
# 参数和下面warpAffine类似
img = cv2.warpPerspective(img, M, dsize=(width, height), borderValue=(114, 114, 114))
else:
# 仿射变换函数 实现旋转平移缩放变换后的平行线依旧平行
# image changed img [1472, 1472, 3] => [736, 736, 3]
# cv2.warpAffine: opencv实现的仿射变换函数
# 参数: img: 需要变化的图像 M: 变换矩阵 dsize: 输出图像的大小 flags: 插值方法的组合(int 类型!)
# borderValue: (重点!)边界填充值 默认情况下,它为0。
img = cv2.warpAffine(img, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
# Visualize 可视化
# import matplotlib.pyplot as plt
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
# ax[0].imshow(img[:, :, ::-1]) # base
# ax[1].imshow(img2[:, :, ::-1]) # warped
# Transform label coordinates
# 同样需要调整标签信息
n = len(targets)
if n:
# 判断是否可以使用segment标签: 只有segments不为空时即数据集中有多边形gt也有正常gt时才能使用segment标签 use_segments=True
# 否则如果只有正常gt时segments为空 use_segments=False
use_segments = any(x.any() for x in segments)
new = np.zeros((n, 4)) # [n, 0+0+0+0]
# 如果使用的是segments标签(标签中含有多边形gt)
if use_segments: # warp segments
# 先对segment标签进行重采样
# 比如说segment坐标只有100个,通过interp函数将其采样为n个(默认1000)
# [n, x1y2...x99y100] 扩增坐标-> [n, 500, 2]
# 由于有旋转,透视变换等操作,所以需要对多边形所有角点都进行变换
segments = resample_segments(segments)
for i, segment in enumerate(segments): # segment: [500, 2] 多边形的500个点坐标xy
xy = np.ones((len(segment), 3)) # [1, 1+1+1]
xy[:, :2] = segment # [500, 2]
# 对该标签多边形的所有顶点坐标进行透视/仿射变换
xy = xy @ M.T # transform
xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
# 根据segment的坐标,取xy坐标的最大最小值,得到边框的坐标 clip
new[i] = segment2box(xy, width, height) # xy [500, 2]
# 不使用segments标签 使用正常的矩形的标签targets
else: # warp boxes
# 直接对box透视/仿射变换
# 由于有旋转,透视变换等操作,所以需要对四个角点都进行变换
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform 每个角点的坐标
xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip 去除太小的target(target大部分跑到图外去了)
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
# filter candidates 过滤target 筛选box
# 长和宽必须大于wh_thr个像素 裁剪过小的框(面积小于裁剪前的area_thr) 长宽比范围在(1/ar_thr, ar_thr)之间的限制
# 筛选结果 [n] 全是True或False 使用比如: box1[i]即可得到i中所有等于True的矩形框 False的矩形框全部删除
i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
# 得到所有满足条件的targets
targets = targets[i]
targets[:, 1:5] = new[i]
return img, targets
这个函数会用于load_mosaic中用在mosaic操作之后进行透视变换/仿射变换:
这个函数的参数来自hyp中的5个参数:

效果显示1:mosaic
shape = (1280, 1280, 3)
效果显示2:mosaic + random_perspective
shape = (640, 640, 3)
11、box_candidates
\qquad 这个函数用在random_perspective中,是对透视变换后的图片label进行筛选,去除被裁剪过小的框(面积小于裁剪前的area_thr) 还有长和宽必须大于wh_thr个像素,且长宽比范围在(1/ar_thr, ar_thr)之间的限制。
box_candidates模块代码:
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.1, eps=1e-16):
"""用在random_perspective中 对透视变换后的图片label进行筛选
去除被裁剪过小的框(面积小于裁剪前的area_thr) 还有长和宽必须大于wh_thr个像素,且长宽比范围在(1/ar_thr, ar_thr)之间的限制
Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
:params box1: [4, n]
:params box2: [4, n]
:params wh_thr: 筛选条件 宽高阈值
:params ar_thr: 筛选条件 宽高比、高宽比最大值阈值
:params area_thr: 筛选条件 面积阈值
:params eps: 1e-16 接近0的数 防止分母为0
:return i: 筛选结果 [n] 全是True或False 使用比如: box1[i]即可得到i中所有等于True的矩形框 False的矩形框全部删除
"""
w1, h1 = box1[2] - box1[0], box1[3] - box1[1] # 求出所有box1矩形框的宽和高 [n] [n]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1] # 求出所有box2矩形框的宽和高 [n] [n]
ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # 求出所有box2矩形框的宽高比和高宽比的较大者 [n, 1]
# 筛选条件: 增强后w、h要大于2 增强后图像与增强前图像面积比值大于area_thr 宽高比大于ar_thr
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
12、replicate
\qquad 这个函数是随机偏移标签中心,生成新的标签与原标签结合。可以用在load_mosaic里在mosaic操作之后 random_perspective操作之前, 作者默认是关闭的, 自己可以实验一下效果。
replicate模块代码:
def replicate(img, labels):
"""可以用在load_mosaic里在mosaic操作之后 random_perspective操作之前 作者默认是关闭的 自己可以实验一下效果
随机偏移标签中心,生成新的标签与原标签结合 Replicate labels
:params img: img4 因为是用在mosaic操作之后 所以size=[2*img_size, 2*img_size]
:params labels: mosaic整合后图片的所有正常label标签labels4(不正常的会通过segments2boxes将多边形标签转化为正常标签) [N, cls+xyxy]
:return img: img4 size=[2*img_size, 2*img_size] 不过图片中多了一半的较小gt个数
:params labels: labels4 不过另外增加了一半的较小label [3/2N, cls+xyxy]
"""
h, w = img.shape[:2] # 得到图片的高和宽
boxes = labels[:, 1:].astype(int) # 得到所有gt框的矩形坐标 xyxy [N, xyxy]
x1, y1, x2, y2 = boxes.T # 左上角: x1 y1 右下角: x2 y2 [N]
s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels) [N] 得到N个gt的 (w+h)/2 用来衡量gt框的大小
# 生成原标签个数一半的新标签 s.size返回ndarray的元素数量
for i in s.argsort()[:round(s.size * 0.5)]: # 返回较小(s较小)的一半gt框的index信息
x1b, y1b, x2b, y2b = boxes[i] # 得到这一般较小gt框的坐标信息 左上角x1b y1b 右下角x2b y2b
bh, bw = y2b - y1b, x2b - x1b # 得到这一般较小gt框的高宽信息
# 随机偏移标签中心点 y范围在[0, 图片高-gt框高] x范围在[0, 图片宽-gt框宽]
yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
# 重新生成这一半的gt框坐标信息(偏移后)
x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
# 将图片中真实的gt框偏移到对应生成的坐标(一半较小的偏移 较大的不偏移)
img[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# append 原来的labels标签 + 偏移了的标签
labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
return img, labels
会用在load_mosaicload_mosaic里在mosaic操作之后 random_perspective操作之前(一般会关闭 具体还要看个人实验):
执行效果
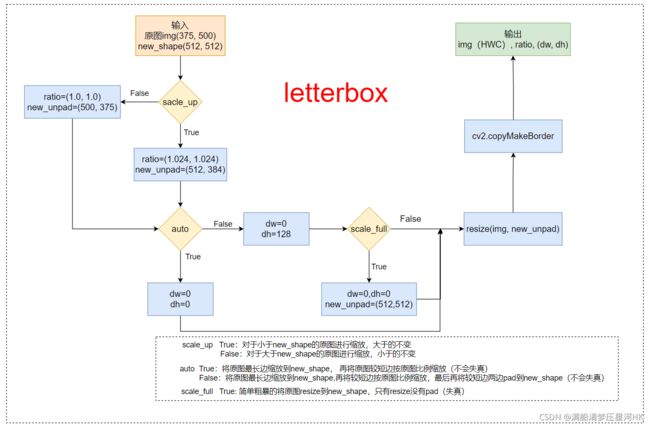
13、letterbox
letterbox 的img转换部分
\qquad 此时:auto=False(需要pad), scale_fill=False, scale_up=False。
\qquad 显然,这部分需要缩放,因为在这之前的load_image部分已经缩放过了(最长边等于指定大小,较短边等比例缩放),那么在letterbox只需要计算出较小边需要填充的pad, 再将较小边两边pad到相应大小(每个batch需要每张图片的大小,这个大小是不相同的)即可。
也可以结合我画的流程图来理解下面的letterbox代码:
letterbox模块代码:
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
"""用在LoadImagesAndLabels模块的__getitem__函数 只在val时才会使用
将图片缩放调整到指定大小
Resize and pad image while meeting stride-multiple constraints
https://github.com/ultralytics/yolov3/issues/232
:param img: 原图 hwc
:param new_shape: 缩放后的最长边大小
:param color: pad的颜色
:param auto: True 保证缩放后的图片保持原图的比例 即 将原图最长边缩放到指定大小,再将原图较短边按原图比例缩放(不会失真)
False 将原图最长边缩放到指定大小,再将原图较短边按原图比例缩放,最后将较短边两边pad操作缩放到最长边大小(不会失真)
:param scale_fill: True 简单粗暴的将原图resize到指定的大小 相当于就是resize 没有pad操作(失真)
:param scale_up: True 对于小于new_shape的原图进行缩放,大于的不变
False 对于大于new_shape的原图进行缩放,小于的不变
:return: img: letterbox后的图片 HWC
ratio: wh ratios
(dw, dh): w和h的pad
"""
shape = img.shape[:2] # 第一层resize后图片大小[h, w] = [343, 512]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape) # (512, 512)
# scale ratio (new / old) 1.024 new_shape=(384, 512)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # r=1
# 只进行下采样 因为上采样会让图片模糊
# (for better test mAP) scale_up = False 对于大于new_shape(r<1)的原图进行缩放,小于new_shape(r>1)的不变
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios (1, 1)
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # wh(512, 343) 保证缩放后图像比例不变
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding dw=0 dh=41
if auto: # minimum rectangle 保证原图比例不变,将图像最大边缩放到指定大小
# 这里的取余操作可以保证padding后的图片是32的整数倍(416x416),如果是(512x512)可以保证是64的整数倍
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding dw=0 dh=0
elif scaleFill: # stretch 简单粗暴的将图片缩放到指定尺寸
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
# 在较小边的两侧进行pad, 而不是在一侧pad
dw /= 2 # divide padding into 2 sides 将padding分到上下,左右两侧 dw=0
dh /= 2 # dh=20.5
# shape:[h, w] new_unpad:[w, h]
if shape[::-1] != new_unpad: # resize 将原图resize到new_unpad(长边相同,比例相同的新图)
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) # 计算上下两侧的padding # top=20 bottom=21
left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) # 计算左右两侧的padding # left=0 right=0
# add border/pad
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
# img: (384, 512, 3) ratio=(1.0,1.0) 这里没有缩放操作 (dw,dh)=(0.0, 20.5)
return img, ratio, (dw, dh)
__getitem__中letterbox 的label转换部分
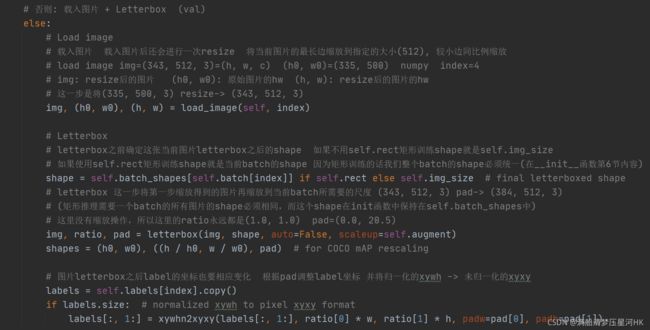
总结下在val时这里主要是做了三件事:
- load_image将图片从文件中加载出来,并resize到相应的尺寸(最长边等于我们需要的尺寸,最短边等比例缩放);
- letterbox将之前resize后的图片再pad到我们所需要的放到dataloader中(collate_fn函数)的尺寸(矩形训练要求同一个batch中的图片的尺寸必须保持一致);
- 将label从相对原图尺寸(原文件中图片尺寸)缩放到相对letterbox pad后的图片尺寸。因为前两部分的图片尺寸发生了变化,同样的我们的label也需要发生相应的变化。
执行效果
14、cutout
\qquad cutout数据增强,给图片随机添加随机大小的方块噪声 ,目的是提高泛化能力和鲁棒性。来自论文: https://arxiv.org/abs/1708.04552。
\qquad 更多原理细节请看博客:【YOLO v4】【trick 8】Data augmentation: MixUp、Random Erasing、CutOut、CutMix、Mosic。
\qquad 具体要不要使用,概率是多少可以自己实验。
cutout模块代码:
def cutout(image, labels):
"""用在LoadImagesAndLabels模块中的__getitem__函数进行cutout增强 v5源码作者默认是没用用这个的 感兴趣的可以测试一下
cutout数据增强, 给图片随机添加随机大小的方块噪声 目的是提高泛化能力和鲁棒性
实现:随机选择一个固定大小的正方形区域,然后采用全0填充就OK了,当然为了避免填充0值对训练的影响,应该要对数据进行中心归一化操作,norm到0。
论文: https://arxiv.org/abs/1708.04552
:params image: 一张图片 [640, 640, 3] numpy
:params labels: 这张图片的标签 [N, 5]=[N, cls+x1y1x2y2]
:return labels: 筛选后的这张图片的标签 [M, 5]=[M, cls+x1y1x2y2] M
h, w = image.shape[:2] # 获取图片高和宽
def bbox_ioa(box1, box2):
"""用在cutout中
计算box1和box2相交面积与box2面积的比例
Returns the intersection over box2 area given box1, box2. box1 is 4, box2 is nx4. boxes are x1y1x2y2
:params box1: 传入随机生成噪声 box [4] = [x1y1x2y2]
:params box2: 传入图片原始的label信息 [n, 4] = [n, x1y1x2y2]
:return [n, 1] 返回一个生成的噪声box与n个原始label的相交面积与b原始label的比值
"""
box2 = box2.transpose()
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
# 求box1和box2的相交面积
inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
(np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
# box面积
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + 1e-16
# 返回box1和box2相交面积 与 box2面积之比
return inter_area / box2_area
# 设置cutout添加噪声的scale create random masks
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
for s in scales:
# 随机生成噪声 宽高
mask_h = random.randint(1, int(h * s))
mask_w = random.randint(1, int(w * s))
# 随机生成噪声 box
xmin = max(0, random.randint(0, w) - mask_w // 2)
ymin = max(0, random.randint(0, h) - mask_h // 2)
xmax = min(w, xmin + mask_w)
ymax = min(h, ymin + mask_h)
# 添加随机颜色的噪声 apply random color mask
image[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
# 返回没有噪声的label return unobscured labels
if len(labels) and s > 0.03:
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32) # 随机生成的噪声box
# 计算生成的一个噪声box与这张图片中所有gt的box做计算 inter_area/label_area [n, 1]
ioa = bbox_ioa(box, labels[:, 1:5])
# remove>60% obscured labels 不能切的太大 ioa < 0.60 保留cutout噪声遮挡小于60%的标签
labels = labels[ioa < 0.60]
return labels
在LoadImagesAndLabels模块中的__getitem__函数进行cutout增强:
执行效果:

mixup增强由超参hyp[‘mixup’]控制,0则关闭 默认为1则100%打开(自己实验判断):
![]()
15、mixup
\qquad 这个函数是进行mixup数据增强:按比例融合两张图片。论文:https://arxiv.org/pdf/1710.09412.pdf。
\qquad 更多原理细节请看博客:【YOLO v4】【trick 8】Data augmentation: MixUp、Random Erasing、CutOut、CutMix、Mosic。
\qquad 具体要不要使用,概率是多少可以自己实验。
mixup模块代码:
def mixup(im, labels, im2, labels2):
"""用在LoadImagesAndLabels模块中的__getitem__函数进行mixup增强
mixup数据增强, 按比例融合两张图片 Applies MixUp augmentation
论文: https://arxiv.org/pdf/1710.09412.pdf
:params im:图片1 numpy (640, 640, 3)
:params labels:[N, 5]=[N, cls+x1y1x2y2]
:params im2:图片2 (640, 640, 3)
:params labels2:[M, 5]=[M, cls+x1y1x2y2]
:return img: 两张图片mixup增强后的图片 (640, 640, 3)
:return labels: 两张图片mixup增强后的label标签 [M+N, cls+x1y1x2y2]
"""
# 随机从beta分布中获取比例,range[0, 1]
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
# 按照比例融合两张图片
im = (im * r + im2 * (1 - r)).astype(np.uint8)
# 将两张图片标签拼接到一起
labels = np.concatenate((labels, labels2), 0)
return im, labels
在LoadImagesAndLabels模块中的__getitem__函数进行mixup增强:
执行效果:

mixup增强由超参hyp[‘mixup’]控制,0则关闭 默认为1则100%打开(自己实验判断):
![]()
16、LoadImages、LoadStreams、LoadWebcam
\qquad load 文件夹中的图片/视频 + 用到很少 load web网页中的数据。
全部代码:
class LoadImages: # for inference
"""在detect.py中使用
load 文件夹中的图片/视频
定义迭代器 用于detect.py
"""
def __init__(self, path, img_size=640, stride=32):
p = str(Path(path).absolute()) # os-agnostic absolute path
# glob.glab: 返回所有匹配的文件路径列表 files: 提取图片所有路径
if '*' in p:
# 如果p是采样正则化表达式提取图片/视频, 可以使用glob获取文件路径
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
# 如果p是一个文件夹,使用glob获取全部文件路径
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p):
# 如果p是文件则直接获取
files = [p] # files
else:
raise Exception(f'ERROR: {
p} does not exist')
# images: 目录下所有图片的图片名 videos: 目录下所有视频的视频名
images = [x for x in files if x.split('.')[-1].lower() in img_formats]
videos = [x for x in files if x.split('.')[-1].lower() in vid_formats]
# 图片与视频数量
ni, nv = len(images), len(videos)
self.img_size = img_size
self.stride = stride # 最大的下采样率
self.files = images + videos # 整合图片和视频路径到一个列表
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv # 是不是video
self.mode = 'image' # 默认是读image模式
if any(videos):
# 判断有没有video文件 如果包含video文件,则初始化opencv中的视频模块,cap=cv2.VideoCapture等
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {
p}. ' \
f'Supported formats are:\nimages: {
img_formats}\nvideos: {
vid_formats}'
def __iter__(self):
"""迭代器"""
self.count = 0
return self
def __next__(self):
"""与iter一起用?"""
if self.count == self.nf: # 数据读完了
raise StopIteration
path = self.files[self.count] # 读取当前文件路径
if self.video_flag[self.count]: # 判断当前文件是否是视频
# Read video
self.mode = 'video'
# 获取当前帧画面,ret_val为一个bool变量,直到视频读取完毕之前都为True
ret_val, img0 = self.cap.read()
# 如果当前视频读取结束,则读取下一个视频
if not ret_val:
self.count += 1
self.cap.release()
# self.count == self.nf表示视频已经读取完了
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1 # 当前读取视频的帧数
print(f'video {
self.count + 1}/{
self.nf} ({
self.frame}/{
self.frames}) {
path}: ', end='')
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'Image Not Found ' + path
print(f'image {
self.count}/{
self.nf} {
path}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB and HWC to CHW
img = np.ascontiguousarray(img)
# 返回路径, resize+pad的图片, 原始图片, 视频对象
return path, img, img0, self.cap
def new_video(self, path):
# 记录帧数
self.frame = 0
# 初始化视频对象
self.cap = cv2.VideoCapture(path)
# 得到视频文件中的总帧数
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
def __len__(self):
return self.nf # number of files
class LoadStreams:
"""
load 文件夹中视频流
multiple IP or RTSP cameras
定义迭代器 用于detect.py
"""
def __init__(self, sources='streams.txt', img_size=640, stride=32):
self.mode = 'stream' # 初始化mode为images
self.img_size = img_size
self.stride = stride # 最大下采样步长
# 如果sources为一个保存了多个视频流的文件 获取每一个视频流,保存为一个列表
if os.path.isfile(sources):
with open(sources, 'r') as f:
sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
else:
# 反之,只有一个视频流文件就直接保存
sources = [sources]
n = len(sources) # 视频流个数
# 初始化图片 fps 总帧数 线程数
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
self.sources = [clean_str(x) for x in sources] # clean source names for later
# 遍历每一个视频流
for i, s in enumerate(sources): # index, source
# Start thread to read frames from video stream
# 打印当前视频index/总视频数/视频流地址
print(f'{
i + 1}/{
n}: {
s}... ', end='')
if 'youtube.com/' in s or 'youtu.be/' in s: # if source is YouTube video
check_requirements(('pafy', 'youtube_dl'))
import pafy
s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam 本地摄像头
# s='0'打开本地摄像头,否则打开视频流地址
cap = cv2.VideoCapture(s)
assert cap.isOpened(), f'Failed to open {
s}'
# 获取视频的宽和长
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 获取视频的帧率
self.fps[i] = max(cap.get(cv2.CAP_PROP_FPS) % 100, 0) or 30.0 # 30 FPS fallback
# 帧数
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
# 读取当前画面
_, self.imgs[i] = cap.read() # guarantee first frame
# 创建多线程读取视频流,daemon表示主线程结束时子线程也结束
self.threads[i] = Thread(target=self.update, args=([i, cap]), daemon=True)
print(f" success ({
self.frames[i]} frames {
w}x{
h} at {
self.fps[i]:.2f} FPS)")
self.threads[i].start()
print('') # newline
# check for common shapes
# 获取进行resize+pad之后的shape,letterbox函数默认(参数auto=True)是按照矩形推理进行填充
s = np.stack([letterbox(x, self.img_size, stride=self.stride)[0].shape for x in self.imgs], 0) # shapes
self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
if not self.rect:
print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.')
def update(self, i, cap):
# Read stream `i` frames in daemon thread
n, f = 0, self.frames[i]
while cap.isOpened() and n < f:
n += 1
# _, self.imgs[index] = cap.read()
cap.grab()
# 每4帧读取一次
if n % 4: # read every 4th frame
success, im = cap.retrieve()
self.imgs[i] = im if success else self.imgs[i] * 0
time.sleep(1 / self.fps[i]) # wait time
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
cv2.destroyAllWindows()
raise StopIteration
# Letterbox
img0 = self.imgs.copy()
img = [letterbox(x, self.img_size, auto=self.rect, stride=self.stride)[0] for x in img0]
# Stack 将读取的图片拼接到一起
img = np.stack(img, 0)
# Convert
img = img[:, :, :, ::-1].transpose(0, 3, 1, 2) # BGR to RGB and BHWC to BCHW
img = np.ascontiguousarray(img)
return self.sources, img, img0, None
def __len__(self):
return 0 # 1E12 frames = 32 streams at 30 FPS for 30 years
class LoadWebcam: # for inference
"""用到很少 load web网页中的数据"""
def __init__(self, pipe='0', img_size=640, stride=32):
self.img_size = img_size
self.stride = stride
if pipe.isnumeric():
pipe = eval(pipe) # local camera
# pipe = 'rtsp://192.168.1.64/1' # IP camera
# pipe = 'rtsp://username:[email protected]/1' # IP camera with login
# pipe = 'http://wmccpinetop.axiscam.net/mjpg/video.mjpg' # IP golf camera
self.pipe = pipe
self.cap = cv2.VideoCapture(pipe) # video capture object
self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if cv2.waitKey(1) == ord('q'): # q to quit
self.cap.release()
cv2.destroyAllWindows()
raise StopIteration
# Read frame
if self.pipe == 0: # local camera
ret_val, img0 = self.cap.read()
img0 = cv2.flip(img0, 1) # flip left-right
else: # IP camera
n = 0
while True:
n += 1
self.cap.grab()
if n % 30 == 0: # skip frames
ret_val, img0 = self.cap.retrieve()
if ret_val:
break
# Print
assert ret_val, f'Camera Error {
self.pipe}'
img_path = 'webcam.jpg'
print(f'webcam {
self.count}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB and HWC to CHW
img = np.ascontiguousarray(img)
return img_path, img, img0, None
def __len__(self):
return 0
在detect.py中使用:
17、hist_equalize
\qquad 这个函数是用于对图片进行直方图均衡化处理,但是在yolov5中并没有用到按这个函数,学习了解下就好,不是重点。
hist_equalize模块代码:
def hist_equalize(img, clahe=True, bgr=False):
"""yolov5并没有使用直方图均衡化的增强操作 可以自己试试
直方图均衡化增强操作 Equalize histogram on BGR image 'img' with img.shape(n,m,3) and range 0-255
:params img: 要进行直方图均衡化的原图
:params clahe: 是否要生成自适应均衡化图片 默认True 如果是False就生成全局均衡化图片
:params bgr: 传入的img图像是否是bgr图片 默认False
:return img: 均衡化之后的图片 大小不变 格式RGB
"""
# 图片BGR/RGB格式 -> YUV格式
yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
if clahe:
# cv2.createCLAHE生成自适应均衡化图像
c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
yuv[:, :, 0] = c.apply(yuv[:, :, 0])
else:
# 全局均衡化
yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
自行实验:
if __name__ == '__main__':
img1 = cv2.imread("F:\yolo_v5\datasets\coco128\images\\train2017\\000000000036.jpg")
img2 = hist_equalize(img1)
cv2.imshow("hist_equalize_before", img1)
cv2.imshow("hist_equalize_after", img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
实验结果:
18、create_folder
\qquad create_folder函数用于创建一个新的文件夹。会用在下面的flatten_recursive函数中。
create_folder函数代码:
def create_folder(path='./new'):
"""用在flatten_recursive函数中
创建文件夹 Create folder
"""
# 如果path存在文件夹,则移除
if os.path.exists(path):
shutil.rmtree(path) # delete output folder
# 再从新新建这个文件夹
os.makedirs(path) # make new output folder
19、flatten_recursive
\qquad 这个模块是将一个文件路径中的所有文件复制到另一个文件夹中 即将image文件和label文件放到一个新文件夹中。
flatten_recursive模块代码:
def flatten_recursive(path='../../datasets/coco128'):
"""没用到 不是很重要 自己有用就用
将一个文件路径中的所有文件复制到另一个文件夹中 即将image文件和label文件放到一个新文件夹中
Flatten a recursive directory by bringing all files to top level
"""
new_path = Path(path + '_flat') # '..\datasets\coco128_flat'
create_folder(new_path)
for file in tqdm(glob.glob(str(Path(path)) + '/**/*.*', recursive=True)):
# shutil.copyfile: 复制文件到另一个文件夹中
shutil.copyfile(file, new_path / Path(file).name)
自己用:
if __name__ == '__main__':
flatten_recursive()
效果:

20、extract_boxes
\qquad 这个模块是将目标检测数据集转化为分类数据集 ,集体做法: 把目标检测数据集中的每一个gt拆解开 分类别存储到对应的文件当中。
def extract_boxes(path='../../datasets/coco128'):
"""自行使用 生成分类数据集
将目标检测数据集转化为分类数据集 集体做法: 把目标检测数据集中的每一个gt拆解开 分类别存储到对应的文件当中
Convert detection dataset into classification dataset, with one directory per class
使用: from utils.datasets import *; extract_boxes()
:params path: 数据集地址
"""
path = Path(path) # images dir 数据集文件目录 默认'..\datasets\coco128'
# remove existing path / 'classifier' 文件夹
shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None
files = list(path.rglob('*.*')) # 递归遍历path文件下的'*.*'文件
n = len(files) # number of files
for im_file in tqdm(files, total=n):
if im_file.suffix[1:] in img_formats: # 必须得是图片文件
# image
im0 = cv2.imread(str(im_file)) # BGR
im = im0[..., ::-1] # BGR to RGB
h, w = im.shape[:2] # 得到这张图片h w
# labels 根据这张图片的路径找到这张图片的label路径
lb_file = Path(img2label_paths([str(im_file)])[0])
if Path(lb_file).exists():
with open(lb_file, 'r') as f:
lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # 读取label的各行: 对应各个gt坐标
for j, x in enumerate(lb): # 遍历每一个gt
c = int(x[0]) # class
# 生成新'file_name path\classifier\class_index\image_name'
# 如: 'F:\yolo_v5\datasets\coco128\images\train2017\classifier\45\train2017_000000000009_0.jpg'
f = (path / 'classifier') / f'{
c}' / f'{
path.stem}_{
im_file.stem}_{
j}.jpg' # new filename
# f.parent: 'F:\yolo_v5\datasets\coco128\images\train2017\classifier\45'
if not f.parent.is_dir():
# 每一个类别的第一张照片存进去之前 先创建对应类的文件夹
f.parent.mkdir(parents=True)
b = x[1:] * [w, h, w, h] # box normalized to 正常大小
# b[2:] = b[2:].max() pad: rectangle to square
b[2:] = b[2:] * 1.2 + 3 # pad
b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int) # xywh to xyxy
# 防止b出界 clip boxes outside of image
b[[0, 2]] = np.clip(b[[0, 2]], 0, w)
b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
assert cv2.imwrite(str(f), im0[b[1]:b[3], b[0]:b[2]]), f'box failure in {
f}'
自行使用:
if __name__ == '__main__':
extract_boxes()
生成结果:
![]()
分类数据集位置:
按类别划分好:
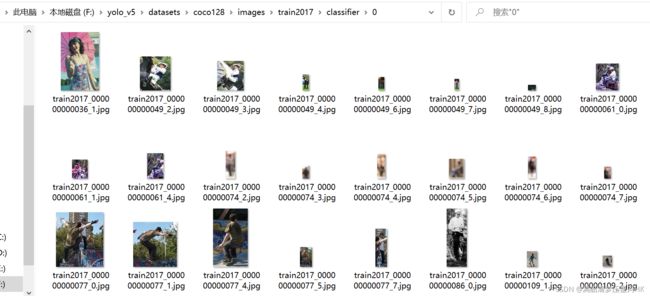
person类(0类):
21、autosplit
\qquad 这个模块是进行自动划分数据集。当使用自己数据集时,可以用这个模块进行自行划分数据集。
autosplit模块代码:
def autosplit(path='../../datasets/coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
"""自行使用 自行划分数据集
自动将数据集划分为train/val/test并保存 path/autosplit_*.txt files
Usage: from utils.datasets import *; autosplit()
:params path: 数据集image位置
:params weights: 划分权重 默认分别是(0.9, 0.1, 0.0) 对应(train, val, test)
:params annotated_only: Only use images with an annotated txt file
"""
path = Path(path) # images dir
# 获取images中所有的图片 image files only
files = sum([list(path.rglob(f"*.{
img_ext}")) for img_ext in img_formats], [])
n = len(files) # number of files
random.seed(0) # 随机数种子
# assign each image to a split 根据(train, val, test)权重划分原始图片数据集
# indices: [n] 0, 1, 2 分别表示数据集中每一张图片属于哪个数据集 分别对应着(train, val, test)
indices = random.choices([0, 1, 2], weights=weights, k=n) #
txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
[(path.parent / x).unlink(missing_ok=True) for x in txt] # remove existing txt
print(f'Autosplitting images from {
path}' + ', using *.txt labeled images only' * annotated_only)
for i, img in tqdm(zip(indices, files), total=n):
if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
with open(path.parent / txt[i], 'a') as f:
f.write('./' + img.relative_to(path.parent).as_posix() + '\n') # add image to txt file
自行使用:
if __name__ == '__main__':
autosplit()
划分结果:


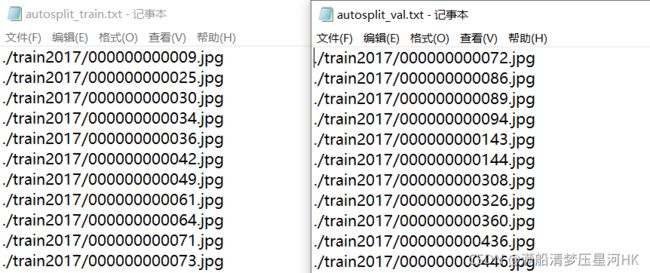
22、dataset_stats
\qquad 这个模块是统计数据集的信息返回状态字典。包含: 每个类别的图片数量 + 每个类别的实例数量。
dataset_stats模块代码:
def dataset_stats(path='../data/coco128.yaml', autodownload=False, verbose=False):
"""yolov5数据集没有用 自行使用
这个模块是统计数据集的信息返回状态字典 包含: 每个类别的图片数量 每个类别的实例数量
Return dataset statistics dictionary with images and instances counts per split per class
Usage: from utils.datasets import *; dataset_stats('coco128.yaml', verbose=True)
:params path: 数据集信息 data.yaml
:params autodownload: Attempt to download dataset if not found locally
:params verbose: print可视化打印
:return stats: 统计的数据集信息 详细介绍看后面
"""
def round_labels(labels):
# Update labels to integer class and 6 decimal place floats
return [[int(c), *[round(x, 6) for x in points]] for c, *points in labels]
with open(check_file(path), encoding='utf-8') as f:
data = yaml.safe_load(f) # data dict # coco.yaml数据字典
data['path'] = "../../datasets/coco128" # 数据集地址
check_dataset(data, autodownload) # 检查数据集是否存在 download dataset if missing
nc = data['nc'] # 数据集类别 number of classes
stats = {
'nc': nc, 'names': data['names']} # statistics dictionary
for split in 'train', 'val', 'test': # 分train、val、test统计数据集信息
if data.get(split) is None:
stats[split] = None # i.e. no test set
continue
x = []
dataset = LoadImagesAndLabels(data[split], augment=False, rect=True) # load dataset
if split == 'train': # 训练集直接读取对应位置的label.cache文件 直接就可以读出数据集信息
cache_path = Path(dataset.label_files[0]).parent.with_suffix('.cache') # *.cache path
# 统计数据集每个图片label中每个类别gt框的个数
# x: {list: img_num} 每个list[class_num] 每个图片的label中每个类别gt框的个数
for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics'):
x.append(np.bincount(label[:, 0].astype(int), minlength=nc))
x = np.array(x) # list to numpy矩阵 [img_num, class_num]
# 分别统计train、val、test三个数据集的数据信息
# 包括: 'image_stats': 字典dict 图片数量total 没有标签的文件个数unlabelled 数据集每个类别的gt个数[80]
# 'instance_stats': 字典dict 数据集中所有图片的所有gt个数total 数据集中每个类别的gt个数[80]
# 'labels': 字典dict key=数据集中每张图片的文件名 value=每张图片对应的label信息 [n, cls+xywh]
stats[split] = {
'instance_stats': {
'total': int(x.sum()), 'per_class': x.sum(0).tolist()},
'image_stats': {
'total': dataset.n, 'unlabelled': int(np.all(x == 0, 1).sum()),
'per_class': (x > 0).sum(0).tolist()},
'labels': [{
str(Path(k).name): round_labels(v.tolist())} for k, v in
zip(dataset.img_files, dataset.labels)]}
# Save, print and return 统计信息stats
with open(cache_path.with_suffix('.json'), 'w') as f:
json.dump(stats, f) # save stats *.json
if verbose: # print可视化
print(json.dumps(stats, indent=2, sort_keys=False))
# print(yaml.dump([stats], sort_keys=False, default_flow_style=False))
return stats
自行使用:
if __name__ == '__main__':
dataset_stats()
执行效果:


总结
\qquad 这个文件主要进行的是数据增强操作。其中1-7小节是和train.py相连的数据载入+数据增强操作;2-15是具体的数据增强实现函数;16节是数据载入模块,包括 load 文件夹中的图片/视频 + 用到很少 load web网页中的数据;最后一个部分是数据集的扩展功能。着重学习前面俩个部分,后面两个部分学习了解下即可。
–2021.08.28 21.54